用于关联存储器中的长加法和长乘法的系统和方法与流程
本发明总体上涉及关联存储器设备,并且具体地涉及关联存储器设备中的算术运算。
背景技术:
在现有的计算设备中,可以使用专用电子电路来使两个二进制数相乘。在乘法电子电路中,数字乘法器可以用各种技术实现;其中大部分涉及计算部分乘积的集合,然后将部分乘积一起求和。这个过程类似于教给小学生对十进制数进行长乘法的方法。
在十进制数的乘法过程的每个步骤中,部分乘积表示被乘数与乘数的不同数位之间的乘法结果。众所周知,最右边的数位表示数字的“1”(100)的数量,下一个数位表示“十”(101)的数量,依此类推,其余的数位表示百(102)、千(103)等。因此,第一部分乘积表示最终结果中的“一”的数量,第二部分乘积表示最终结果中的“十”的数量,其余的部分乘积依此类推。由于每个部分乘积表示10的不同次幂,每个新的部分乘积相对于先前的部分乘积向左移位一个位置。
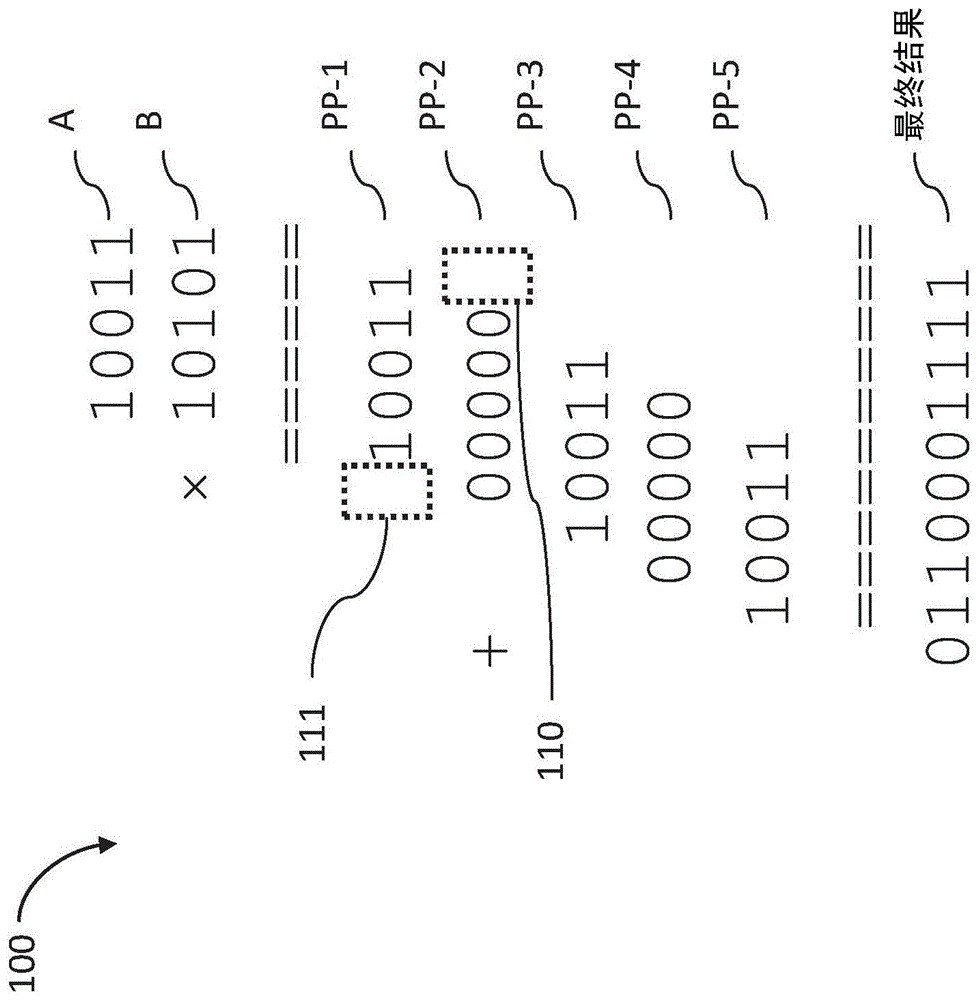
采用类似的过程来使多比特二进制数相乘,如现在参考的图1所示。多比特乘法100是这样的示例:其中在两个5比特二进制数之间的乘法运算中,a是被乘数并且b是乘数。在每个步骤中,被乘数a乘以乘数b的一个比特,从b的最左侧比特开始,并且每个步骤的结果是部分乘积(pp)。通过将乘数b的比特k乘以a并且乘以(2k)来计算第k个部分乘积的值。第一个部分乘积表示乘数b的比特0乘以a并且乘以(20)的值。下一个pp表示乘数b的比特1乘以a并且乘以(21)的值。下一个pp表示乘数b比特2乘以a并且乘以22的值,依此类推。乘以2k等于向左移位k次。
第一部分乘积pp-1是乘以b的比特0的结果并且不移位。第二部分乘积pp-2是乘以b的比特1的结果,因此pp-2相对于pp-1向左移位一个位置。通过在pp-2的最低有效比特(lsb)位置的左移创建空白空间110,并且可以在pp-1的最高有效比特(msb)位置感知空白空间111。关于b的第三个、第四个和第五个数位进行类似的过程,提供pp-3、pp-4和pp-5,各自相对于前一部分乘积向左移位一个位置,即,各自乘以2的相关次幂。
可以认识到,空白空间110和111的值是0,在lsb位置和msb位置中的乘法期间创建的所有部分乘积的所有其他空白空间的值也是如此。
可以认识到,乘数b的比特的值可以是0或1;因此,每个部分乘积的值可以是0或a:如果b的比特的值是0,则结果部分乘积的值可以是0,并且如果b的比特的值是1,则结果部分乘积的值是a。
在处理了b的所有比特之后,计算所有部分乘积的总和。部分乘积的数量是b中的比特的数量,并且可以通过在任何两个部分乘积之间重复使用具有进位传播的标准多比特加法器(图中未示出)提供最终结果来计算总和。可以注意到,部分乘积的最右侧比特中的“空白”位置实际上具有值“0”,使得例如由数字10011表示的pp-3的值向左移位两个位置实际上是1001100。
可以认识到,所有部分乘积的求和是通过在每对部分乘积之间执行加法运算来完成的,每次一个比特,以使进位从lsb传播到msb。这可以为每个求和运算提供o(n)的复杂度。部分乘积的数量是n;因此,完全乘法运算的复杂度可以是o(n2),即部分乘积的数量——n(其为乘数的比特的数量,其定义加法运算的数量)乘以每个部分乘积的比特的数量——n(参与每个加法运算的被乘数的比特的数量)。
由两个n比特数之间的乘法运算产生的比特的数量可以是2n-1或2n。
可以认识到,在转让给本发明的共同受让人且通过引用并入本文的、题为“concurrentmulti-bitadder”的美国专利申请15/690,301中定义的并发多比特加法器可以通过对比特的组并发地操作来改进加法运算的复杂度,但是可能不对所有比特提供并发操作,并且如果比特的组>1则可以提供与数量成比例的复杂度。
可以认识到,乘数的比特的数量不一定与被乘数的比特的数量相同。当大小为n和m时,乘法的复杂度可以是o(mn)。
技术实现要素:
根据本发明的优选实施例,提供了一种用于关联存储器设备的方法。该方法包括用存储在关联存储器设备中的两个多比特二进制数x和y来替换同样存储在关联存储器设备中的三个多比特二进制数p、q和r的集合,其中,二进制数p、q和r的总和等于二进制数x和y的总和。
此外,根据本发明的优选实施例,该方法还包括:具有三个多比特二进制数pi、qi和ri的多个集合i,以及并发地对多个集合i执行替换。
此外,根据本发明的优选实施例,替换包括:对于二进制数p、q和r的每个位置j,并发地将第一比特放置在二进制数x的位置j中,并且将第二比特放置在二进制数y的位置k中。根据全加器真值表,第一比特是总和比特并且第二比特是进位比特,并且位置k表示比位置j中的值大二的幂的值。
更进一步地,根据本发明的优选实施例,该方法还包括具有n个多比特二进制加数。该方法包括:对多比特二进制加数中的三个多比特二进制加数的集合重复地执行替换,直到只剩下两个最终多比特二进制加数,以及对最终两个多比特二进制加数执行标准多比特加法运算,提供n个多比特二进制加数的总和。
另外,根据本发明的优选实施例,该方法还包括使两个多比特二进制数相乘。为此,该方法包括:初始地将两个多比特二进制数的第一部分乘积的比特放入二进制数p中,并且将第二部分乘积的比特放入二进制数q中。该方法包括:将下一部分乘积的比特放置在二进制数r中,执行替换,将多比特二进制数x的比特放入多比特二进制数p,并且将多比特二进制数y的比特放入多比特二进制数q中。该方法包括:重复放置、执行和放入,直到下一部分乘积是最后的部分乘积,以及对多比特二进制数p和q执行标准多比特加法运算,从而提供两个多比特二进制数之间的乘法运算的结果。
此外,根据本发明的优选实施例,第一次执行包括:将多比特二进制数r的最高有效比特(msb)放置在关联存储器设备中的临时位置中,将多比特二进制数p的最低有效比特(lsb)存储在所述结果的第一空闲位置中,从结果的lsb开始,以及从临时位置放置作为多比特二进制数p的msb的比特,从而在多比特二进制数p、q和r中的每个多比特二进制数中保持恒定数量的比特。
根据本发明的优选实施例,提供了一种系统,该系统包括以行和列布置的关联存储器阵列和3to2替换器。关联存储器阵列在关联存储器阵列的每列中存储三个原始多比特二进制数p、q和r。3to2替换器在所有列中并行地用两个替换多比特二进制数x和y并发地替换原始多比特二进制数p、q和r。原始多比特二进制数p、q和r的总和等于替换多比特二进制数x和y的总和。
另外,根据本发明的优选实施例,对于存储在每列中的多比特二进制数p、q和r的每个比特j并发地,3to2替换器将第一比特放置在多比特二进制数x的位置j中,并且将第二比特放置在多比特二进制数y的位置k中。根据全加器真值表,第一比特是总和比特并且第二比特是进位比特,并且位置k存储比位置j中存储的值大二的幂的值。
此外,根据本发明的优选实施例,关联存储器阵列存储多个多比特二进制加数,并且该系统还包括变量缩减器和多比特加法器。变量缩减器对三个多比特二进制数的组重复地激活3to2替换器,直到只剩下两个最终多比特二进制加数,其中,每个组包括来自多个多比特二进制加数的第一多比特二进制加数、第二多比特二进制加数和第三多比特二进制加数。多比特加法器计算最终两个多比特二进制加数的总和,从而提供多个多比特二进制加数的总和。
更进一步地,根据本发明的优选实施例,关联存储器阵列存储要相乘的多比特二进制数的对,并且该系统还包括多比特乘法器。多比特乘法器生成该对的部分乘积,对部分乘积激活变量缩减器,并且激活多比特加法器以提供该对之间的乘法结果。
根据本发明的优选实施例,提供了一种系统,该系统包括具有行和列的关联存储器阵列和多比特乘法器。阵列的每列存储要相乘的两个多比特二进制数。多比特乘法器通过并发地处理由乘法器生成的部分乘积的所有比特来并行地使每列的两个多比特二进制数相乘。乘法器执行处理而在将除最后两个部分乘积之外的所有部分乘积相加时没有任何进位传播延迟。
根据本发明的优选实施例,提供了一种方法,该方法包括并行地使存储在关联存储器阵列的列中的多比特二进制数的对相乘。相乘包括生成该对的部分乘积,以及重复地执行对部分乘积的3to2替换。
附图说明
在说明书的结论部分中特别指出并清楚地要求保护被视为本发明的主题。然而,当结合附图阅读时,通过参考以下详细描述,可以关于组织和操作方法以及其目的、特征和优点最好地理解本发明,其中:
图1是两个5比特二进制数之间的示例性多比特乘法的图示;
图2是使用标准全加器真值表在根据本发明的优选实施例操作的单个步骤中进行的3to2替代的示意图;
图3是原始3个多比特数和替换2个多比特数之间的求和运算的结果的图示;
图4、图5和图6是在图1的乘法运算期间执行的3to2替换步骤的结果的示意图;
图7是根据本发明的实施例构造和操作的乘法系统的示意图;
图8是图7的乘法系统的关联存储器阵列中的乘法变量的布置的示意图;
图9是描述由图7的乘法系统执行的乘法步骤的流程图;
图10、图11、图12和图13是根据本发明的优选实施例的在保持操作数大小恒定的计算的每个步骤中由变量缩减器和3to2替换器执行的操作的示意图;
图14、图15和图16是采用在图1的多比特乘法的示例中关于图10、图11、图12和图13描述的操作的示意图;
图17是对最后累积的部分乘积执行的求和运算的示意图;
图18是用于存储乘法的结果的存储器布置的示意图;以及
图19是描述使用图18的恒定数量的区段的乘法步骤的流程图。
应当认识到,为了说明的简单和清楚,附图中所示的元素不一定按比例绘制。例如,为了清楚起见,元素中的一些元素的尺寸可能相对于其他元素被夸大。此外,在认为适当的情况下,可以在附图中重复附图标记以指示对应或类似的元素。
具体实施方式
在以下详细描述中,阐述了许多具体细节以便提供对本发明的透彻理解。然而,本领域技术人员将理解,可以在没有这些具体细节的情况下实践本发明。在其他实例中,没有详细描述公知的方法、过程和组件,以免模糊本发明。
申请人已经意识到,多用途关联存储器设备可以这样来改进整体乘法处理的复杂度:通过当在最终步骤中将部分乘积的所有比特相加时并发地处理部分乘积的所有比特,从而避免在将除了最后两个部分乘积之外的所有部分乘积相加时的进位传播延迟。
在以下文献中描述了可以使用的多用途关联存储器设备:2012年8月7日发布的美国专利第8,238,173号(题为“usingstoragecellstoperformcomputation”);2015年5月14日公布的美国专利公开2015/0131383(题为“non-volatilein-memorycomputingdevice”);2016年8月16日发布的美国专利第9,418,719号(题为“in-memorycomputationaldevice”);2017年1月31日发布的美国专利第9,558,812号(题为“srammulti-celloperations”)以及2017年7月16日提交并且现在作为美国专利第10,153,042号于2018年12月11日发布的美国专利申请15/650,935(题为“in-memorycomputationaldevicewithbitlineprocessors”),所有这些通过引用并入本文并转让给本发明的共同受让人。
申请人还意识到,对于要加在一起的每三个比特(即,三个加数),使用如图2描述的标准全加器真值表在单个步骤中用两个加数替代这三个比特是可能的,现在参考图2。表250是描述当将三个比特p、q和r加在一起时的结果比特x和y的真值表,其中x是单位或“1”(20)的数量并且y是二(21)的数量。练习200是在将三个二进制数相加以提供可以产生相同结果的两个替代二进制数x和y时如何可以使用真值表250的示例。
在练习200中,三个多比特数p、q和r一个在另一个之下地布置,如将被布置用于长加法运算的。在每列中,三个二进制比特(一个比特来自p,一个比特来自q,并且一个比特来自r(被椭圆围绕))可以用两个新的二进制比特x和y(再次被围绕椭圆)替换(用箭头标记),其中x表示1的值,并且y表示2的值,因此,y的值可以向左移位一个位置。
例如,由椭圆207围绕的列中的p、q和r的比特分别是1、1和1,并且对于椭圆207的值,x和y的适用值是匹配表250的行258的值。由箭头209标记的替换可以提供由椭圆208围绕的x和y的值。可以认识到,比特y的值相对于替换208的x的值向左移位一个位置,因为y提供二(21)位置的值。
另一示例可以是由椭圆203围绕的p、q和r的比特,其分别是1、0和1,并且x和y的适用值是匹配表250的行256的值。
可以认识到,p、q和r的总和与x和y的总和相同,如在现在参考的图3中示意性地示出的,因此可以自由地利用该替换。因此,如果p是0110101,q是0101011并且r是1011101,如图2和图3所示,则结果10111101与将x(1000011)的值加到y(0111101)的值时相同,其中y向左移位一个位置。
用适用的两个其他多比特二进制数替换三个多比特二进制数的操作在本文中称为三到二替换或3to2替换。
可以认识到,可以在关联存储器设备中并发地完成针对任何三个多比特二进制数的所有列对x和y的创建。可以认识到,3to2替换的复杂度是o(1)。
如上文已经提到的,二进制乘法包括将几个部分乘积加在一起。申请人已经意识到可以在乘法中使用3to2替换以改进乘法的整体复杂度。当使两个多比特二进制数a和b相乘时,每个部分乘积的值可以是a或0,并且每个相关的部分乘积可以用于乘法的相关步骤中。
返回图1,a和b是乘法运算中的两个5比特二进制数。使用3to2替换,求和运算的数量可以从四减少到一,如现在参考的图4、图5和图6中所示的。
在图4所示的第一步骤中,可以对前三个部分乘积pp-1、pp-2和pp-3执行3to2替换操作,从而创建两个新的多比特累积部分乘积(app)app-1和app-2。由400a中的编号的椭圆围绕的每三个比特可以被400b中由相关联的编号的椭圆围绕的2个比特替换。在图5所示的第二步骤中,可以对app-1、app-2和下一个部分乘积pp-4执行3to2替换操作,从而创建app-3和app-4。可以认识到,由400b中的移位操作创建的所有空白空间可以在500a中由值0替换。例如,由图4的400b中的椭圆1围绕的app-2的空白空间可以被由图5的500a中的app-2中的椭圆1围绕的0替换。
现在参考的图6是该示例的第三步骤的示意图。在该步骤中,可以对最后的部分乘积pp-5和app-3以及app-4执行3to2替换操作以创建app-5和app-6。
可以认识到,3to2替换操作的这种重复可以对任何大小的二进制数完成,例如,16比特、32比特等。当使n比特被乘数乘以m比特乘数时,可以执行3到2替换操作m-2次。在第一轮中,三个二进制数可以是前三个部分乘积。在每个下一轮中,可以对来自前一轮的两个累积的部分乘积和下一部分乘积执行3to2替换,直到处理最后的部分乘积,剩余两个最后累积的部分乘积。在最后一步中,可以使用具有进位传播的任何相加过程来计算最后两个累积的部分乘积的总和app-5+app-6。
现在参考的图7是根据本发明的实施例构造和操作的乘法系统700的示意图。乘法系统700包括关联存储器阵列710和多比特乘法器750。
关联存储器阵列710可以包括多个区段712,每个区段包括按行和列布置的单元,如上文提到的us8,238,173、us2015/0131383、us9,418,719或us9,558,812中详细描述的。
多比特乘法器750还包括多比特加法器760和变量缩减器770,变量缩减器770还包括3to2替换器775。
多比特乘法器750可以在存储器阵列710的列中写入n比特被乘数a和n比特乘数b,并且可以执行乘法处理,其中最终结果存储在乘法结果行790中。多比特乘法器750可以在乘法过程期间计算部分乘积,可以使用变量缩减器770将要在最终加法运算中相加的操作数的数量减少到两个,并且可以使用多比特加法器760使这两个变量相加,并且在乘法结果行790中提供被乘数a与乘数b之间的乘法运算的最终结果。
变量缩减器770可以重复使用3to2替换器775以将变量的数量从n个部分乘积减少到2个最终加数。如上面描述的,3to2替换器775可以用两个加数x和y替换三个加数p、q和r,加数x和y具有与原始的p、q和r相同的总和。可以认识到,p、q和r可以是部分乘积或累积的部分乘积。多比特加法器760可以是任何多比特加法器,例如,在通过引用并入本文的题为“concurrentmulti-bitadder”的美国专利申请15/690,301中描述的多比特加法器,或者任何其他多比特加法器。
现在参考的图8是关联存储器阵列710中的乘法变量的布置的示意图。多比特乘法器750可以存储要在关联存储器阵列710的相同列的多个区段中相乘的变量的对。变量a的比特j可以存储在区段j的行a中,而数字b的比特j可以存储在区段j的行b中。例如,要相乘的变量的第一对a和b可以存储在col-0中。被乘数a的比特0可以存储在列col-0中的区段0的行a中,被乘数a的比特1可以存储在列col-0的区段1的行a中,依此类推。类似地,被乘数b的比特0可以存储在列col-0中的区段0的行b中,被乘数b的比特1可以存储在列col-0中的区段1的行b中,依此类推。可以认识到,具有m列的关联存储器阵列710可以并发地执行m次乘法运算。
多比特乘法器750可以使用标题为v1、v2和v3的、每个区段中的三个附加行来存储三个数字以在计算的每个步骤中处理部分乘积(pp)和/或累积的部分乘积(app)。
现在参考的图9示出了描述乘法步骤的流程图900。最初,在步骤910中,多比特乘法器750可以将pp-1存储在行v1中并且将pp-2存储在行v2中。接下来在步骤920中,多比特乘法器750可以将下一pp存储在行v3中。
变量缩减器770可以在步骤930中使用3to2替换器775来对行v1、v2和v3执行3to2替换,并且可以将两个结果app存储回行v1和v2。在步骤940中,变量缩减器770可以检查是否已经处理了最后的pp。如果最后的pp尚未处理,则变量缩减器770可以返回到步骤920以生成下一pp。如果最后的pp已经被处理,则多比特乘法器750可以使用多比特加法器760将存储在行v1和v2中的值相加。本领域技术人员可以认识到,针对流程700示出的步骤并非旨在限制,并且该流程可以利用更多或更少的步骤或利用不同的步骤序列或其任何组合来实践。
可以认识到,两个n比特数相乘的结果是多达2n比特的数。每个计算出的pp的大小(比特的数量)比前一个pp大一比特(除了大小为n比特的第一pp)。因此,在第一步骤中(处理三个第一pp),3to2替换器775可以对n+2比特操作。在每次激活中,3to2替换器775需要处理更大的操作数(因为存储在行v1、v2和v3中的比特的数量增加)。
为了将两个5比特数相乘,例如,3to2替换器775应该首先处理7比特操作数,然后,3to2替换器775应该处理8比特操作数,并且在最后一次激活中,3to2替换器775应该处理9比特操作数,如可以在上文描述的图4、图5和图6中看到的。
申请人已经意识到由3to2替换器775创建的第一app(20的app)的lsb的值始终与行v1的lsb相同(因为行v2的lsb和行v3的lsb的值始终为0)。
申请人还意识到,由3to2替换器775创建的第二app(表示21的app)的msb的值始终与v3的msb的值相同(因为行v1的msb和行v2的msb的值始终为0)。
申请人已经意识到,由于第一app的lsb和第二app的msb从未被3to2替换器775改变,因此仅对三个变量的n个中间比特而没有行v1的lsb且没有行v3的msb使用3to2替换器775是可能的。
变量缩减器770可以将3to2替换器775的第一次激活的行v1的lsb存储为演进的最终结果的第一比特。在3to2替换器775的每个连续操作中,变量缩减器770可以将行v1的lsb级联到演进的最终结果的左侧(成为演进的最终结果的临时msb)。变量缩减器770可以临时存储行v3的msb,并且可以在3to2替换器775的下一操作中将其作为msb级联到行v1。
现在参考的图10、图11、图12和图13是在用于将由3to2替换器775处理的操作数的大小保持为仅n比特的计算的每个步骤中变量缩减器770和3to2替换器775的操作的示意图。在图10中,在msb附加操作1000中,变量缩减器770可以级联存储在临时msb存储库1010中的值作为行v1的msb。临时msb存储库1010可以初始化为0,用于3to2替换器775的第一次激活。在图11中,在lsb存储操作1100中,变量缩减器770可以将行v1的lsb存储在最终结果1110中。在图12中,在msb存储操作1200中,变量缩减器770可以将行v3的msb存储在临时msb存储库1010中以用于下一步骤,并且在图13中,在缩减操作1300中,变量缩减器770可以对由正方形1310围绕的行v1、v2和v3的“中间”n比特激活替换器775以执行3to2操作1330。如前面提到的,空白空间1320中的值实际上是0。
现在参考的图14、图15和图16是在图1的多比特乘法100的示例中采用上文关于图10、图11、图12和图13描述的msb附加1000、lsb存储1100、msb存储1200和减少1300的操作的示意图。
在图14中,前三个部分乘积pp-1、pp-2和pp-3可以分别存储在行v1、v2和v3中。在操作1000中,来自临时msb存储库1010a的值可以级联作为行v1的msb。在操作1100中,行v1的lsb可以存储在最终结果1110中。在操作1200中,行v3的msb可以存储在临时msb存储库1010b中,并且在操作1300中,可以对行v1、v2和v3的5个中间比特执行3to2缩减以创建app-1和app-2。可以认识到,msb存储库1010a和msb存储库1010b可以是随时间而存储不同值的相同存储库。在图15和图16中,第一结果app可以存储在行v1中,第二结果app可以存储在行v2中,下一pp可以存储在行v3中,并且可以以与图14中相同的次序执行相同的操作以产生接下来的app和结果的比特。
现在参考的图17是对最后累积的部分乘积app-5和app-6执行以提供最终结果的值的求和运算的示意图。可以重复操作1000,将来自临时msb存储库1010a的值级联作为行v1的msb,并且可以重复操作1100,将行v1的lsb存储在最终结果1110中。接下来,可以对v1和v2的“中间”5比特执行标准加法运算,并且总和可以存储为最终结果1110的msb。
可以认识到,最终结果1110可以占用2n比特。还应认识到,尽管在当前示例中,最终结果1110的msb的值是0,但是如果行v1和行v2的msb的值都是1,则最终结果1110的msb的值可以是1。
如上面已经提到的,当两个变量的大小都为n时,最终结果1110的大小可以是2n。如前面讨论的,变量a的比特j和变量b的比特j可以存储在关联存储器阵列710的区段j中。n比特变量可以存储在n个区段中,但是最终结果1110可能需要2n个区段以便于存储。申请人已经意识到,使用每个区段的2行来存储最终结果1110可以将存储最终结果1110所需的区段的数量从2n减少回n。前n个比特(0到n-1)可以存储在“lsb结果”行中,并且最后n个比特(n到2n-1)可以存储在“msb结果”行中,如现在参考的图18所示。可以认识到,关联存储器阵列710的区段中的行的数量可以是任何数量的行,并且区段中的每一行可以用于不同的目的,例如但不限于存储变量,存储中间结果,存储最终结果等。一些行可以用于计算的一部分,一些行可以用于其他部分,一些行可能根本不使用,等等。
现在参考的图19是仅使用n个区段来计算两个n比特数的相乘结果的流程图1900。
在步骤1910中,变量缩减器770可以计算前两个部分乘积pp-1和pp-2,并且可以将它们分别存储在临时变量temp1和temp2中。结果区段(即,可以存储最终结果1110的第一比特的位置)可以被初始化为阵列的第一区段。存储msb存储库1010的值的临时msb可以被初始化为0,并且pp的标识符id可以被初始化为3,因为已经计算了前两个pp。
在步骤1920中,变量缩减器770可以将temp1的lsb存储在结果区段(其为首次激活时的第一区段)的lsb结果行中。在存储lsb之后,变量缩减器770可以通过对temp1的比特执行右移来将temp1除以2。另外,变量缩减器770可以在由右移创建的空位中附加存储在临时msb1010中的值作为temp1的msb。然后,变量缩减器770可以将temp1的每个比特i存储在区段i的行v1中,并且将temp2的每个比特i存储在区段i的行v2中。
在步骤1930中,变量缩减器770可以检查是否已经处理了乘数b的所有比特。如果id高于b的比特的数量,则已经处理了所有比特,并且变量缩减器770可以继续到步骤1960,在步骤1960中变量缩减器770可以执行v1与v2之间的标准加法运算,并且可以将总和存储在相关联的区段的msb结果行中。如果id小于或等于b的比特的数量,则变量缩减器770可以继续到步骤1940以处理尚未处理的、b的下一比特。
在步骤1940中,变量缩减器770可以计算pp-id,pp-id是要处理的下一pp(在首次激活时,pp-id是pp-3)。变量缩减器770可以附加临时msb1010作为pp-id的msb,将pp-id乘以2并且将pp-id的每个比特i存储在区段i的行v3中。变量缩减器770可以将结果区段更新为下一区段,并且可以递增id以指示要处理的下一pp。
在步骤1950中,变量缩减器770可以对n个区段执行3to2替换,可以将第一结果app和第二结果app分别存储在temp1和temp2中,并且可以返回到步骤1920。
可以认识到,在执行右移操作之前,行v1的lsb存储在结果区段的lsb结果行中,因此,在该移位期间不会丢失数据。类似地,在执行左移操作之前,v3的msb的值存储在临时msb1010中,再次强调,在该移位操作期间不会丢失数据。
可以认识到,上文描述的乘法过程可以在单个步骤中将长加法中的多比特操作数的数量从三减少到二,同时并发处理操作数的所有比特而不必如在标准的多比特加法运算中那样等待进位传播。在本发明中使两个n比特数相乘的复杂度可以是o(2n),其实际上是o(n)(在计算的每个步骤中,生成结果的一个比特,即n个步骤,并且使用标准进位传播可能存在n个附加步骤用于将最后两个操作数相加),而标准乘法运算的复杂度为o(n2)。
虽然本文已经说明和描述了本发明的某些特征,但是本领域普通技术人员现在将想到许多修改、替代、改变和等同物。因此,应该理解,所附权利要求旨在覆盖落入本发明的真正精神内的所有这些修改和改变。
- 还没有人留言评论。精彩留言会获得点赞!