利用实时计算用于逐分块数据组织和放置的方法和系统与流程
本公开一般地涉及数据存储的领域。更具体地,本公开涉及利用实时计算用于逐分块数据组织和放置的方法和系统。
背景技术:
因特网和电子商务的激增继续产生大量的数字内容。已经创建了分布式存储系统来访问并存储这种数字内容。分布式存储系统可包括多个存储服务器,其中存储服务器可包括多个驱动器,诸如固态驱动器(ssd)和硬盘驱动器(hdd)。存储在驱动器上的数据通常是基于文件系统和闪存转换层(ftl)来组织的,所述ftl将数据的逻辑块地址(lba)映射到驱动器的物理块地址(pba)。然而,在逻辑块的大小与物理块的大小之间可能存在显著不一致。例如,ssd/传统文件系统可使用512b单元或4096b(~4kb)单元作为逻辑块大小,但是可使用16kb单元作为物理块大小(例如,作为物理页面的一部分)。作为将lba映射到pba的一部分,ftl维护查找表,其中每一4kblba被指派了一个条目,所述条目它本身具有4b的近似大小。在具有16tb容量的ssd中,此ftl查找表可具有40亿个条目(即,16tb/4kb=4e+9)。假如每个条目是4b,则ftl查找表可以和16gb(即,4e+9x4=16e+9)一样大。
这个大16gbftl查找表可以导致若干问题。该表可以被存储在非易失性存储器(例如,nand闪存)中以确保内容的完整性,但是在给驱动器加电的同时加载这种大表可以花费大量时间。该表可以被存储在ssd的片外dram中,但是ssd必须安装16gb表以支持16tb容量ssd。随着ssd的容量增加,dram也必须增加。因为dram的成本可以很高,所以随之而来的ssd成本也可以很高。
此外,逻辑块大小(例如,4kb)与物理块大小(例如,16kb)之间的不一致可导致低效率和过度设计。基于逻辑大小(4kb)的小粒度生成并存储对应且必要的元数据可导致对驱动器的容量的次优利用。例如,处理元数据可以导致非平凡的开销并且存储元数据可以使用大量的存储器容量。
因此,虽然分布式存储系统可有效地存储大量数据,但是传统ssd和文件系统的缺点可降低系统的效率和总体性能。
技术实现要素:
一个实施例促进数据组织。在操作期间,系统接收指示要从非易失性存储器读取的文件的请求,其中,所述非易失性存储器被划分成多个逻辑分块,并且其中,分块被划分成多个大块。所述系统基于所述请求确定分块索引、在所述文件的开头与对应于所述分块索引的分块的开头之间的第一偏移以及所述文件的请求长度。所述系统基于所述分块索引和所述第一偏移计算所请求的文件的大块索引。所述系统基于所述大块索引识别所述非易失性存储器中的位置。所述系统基于所述请求长度从所述非易失性存储器中的所识别的位置读取所请求的文件。
在一些实施例中,所述系统基于所述请求确定在所述文件的开头与在所述文件内从中开始读取所述文件的起始位置之间的第二偏移,其中,计算所述大块索引并且识别所述位置进一步基于所述第二偏移。
在一些实施例中,确定所述分块索引进一步基于基于所请求的文件在数据结构中执行查找。所述数据结构包括在所述文件与一组对应的位置信息之间的映射。所述位置信息包括所述非易失性存储器中的所述存储的分块索引和大块索引。
在一些实施例中,响应于从所述非易失性存储器中的所识别的位置成功地读取所请求的文件,所述系统将所请求的文件发送到请求主机。
在一些实施例中,所述请求被第一服务器接收并发送到第二服务器。所述系统确定指示从中读取所请求的文件的一个或更多个存储服务器的路径信息。响应于确定所述路径信息未被缓存在所述第二服务器处:所述系统通过所述第二服务器从主节点中检索所述路径信息;并且所述系统通过所述第二服务器缓存所述路径信息。响应于确定所述路径信息被缓存在所述第二服务器处,所述系统通过所述第二服务器确定从中读取所请求的文件的一个或更多个存储服务器。
在一些实施例中,响应于从所述非易失性存储器中的所识别的位置未成功地读取所请求的文件,所述系统从与所述路径信息中指示的另一存储服务器相关联的非易失性存储器读取所请求的文件。
在一些实施例中,响应于从与所述路径信息中指示的所述存储服务器相关联的多个非易失性存储器未成功地读取所请求的文件:所述系统向所述第一服务器报告读取失败;并且所述系统从备份读取所请求的文件。
另一实施例促进数据组织。在操作期间,所述系统接收指示要写入到非易失性存储器的文件的请求,其中,所述非易失性存储器被划分成多个逻辑分块,并且其中,分块被划分成多个大块。所述系统确定与所述文件相关联的第一大块被成功地缓存在缓冲器中。所述系统将所述第一大块写入到所述非易失性存储器中的位置,其中,多个大块被顺序地写入在所述非易失性存储器中。所述系统在数据结构中存储所述文件与一组对应的位置信息之间的映射,其中,所述位置信息包括所述非易失性存储器的分块索引和大块索引,而不用在闪存转换层中访问逻辑块地址至物理块地址映射。
在一些实施例中,所述系统将所述文件划分成第一多个分块以获得对应的元数据,所述元数据指示用于每个分块的索引和所述文件的长度。
在一些实施例中,所述系统基于所述路径信息确定与所述第一大块被写入到的所述非易失性存储器相关联的存储服务器。
在一些实施例中,在确定所述第一大块被成功地缓存在所述缓冲器中之前,所述系统通过所述存储服务器缓存所述缓冲器中的所述第一大块。所述系统将所述数据的剩余部分以大块为单位缓存在所述缓冲器中。当所述缓冲器中的相应的大块单元满时所述系统将所述数据的剩余部分写入到所述非易失性存储器。
在一些实施例中,响应于确定当前分块未被密封,所述系统从写入指针的当前位置开始将所述文件附加到所述当前分块的末尾。响应于确定所述当前分块被密封,所述系统:打开新分块;将所述新分块设置为所述当前分块;并且将所述文件写入到所述当前分块。所述系统将与所述文件相关联的元数据写入到所述当前分块中。
在一些实施例中,所述系统响应于以下各项中的一个或更多个而密封所述当前分块:确定没有剩余文件要写入;以及确定所述当前分块已打开持续长于预定时间段。所述系统响应于确定所述当前分块具有剩余空间并且进一步响应于以下各项中的一个或更多个而填充所述当前分块:确定没有剩余文件要写入;以及确定所述当前分块已打开持续长于预定时间量。
在一些实施例中,所述请求、所述文件和所述对应的元数据由所述第一服务器发送到第二服务器,并且进一步由所述第二服务器发送到与所述第一大块被写入到的所述非易失性存储器相关联的存储服务器。
附图说明
图1图示依照本申请的实施例的促进逐分块数据组织的示例性环境。
图2图示依照本申请的实施例的驱动器中的示例性逐分块数据组织。
图3图示依照本申请的实施例的驱动器的物理空间中的示例性逐分块数据组织。
图4a呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图。
图4b呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图。
图4c呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图。
图4d呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图。
图5a呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中读取数据的方法的流程图。
图5b呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中读取数据的方法的流程图。
图6图示依照本申请的实施例的促进逐分块数据组织的示例性计算机系统。
在图中,相似的附图标记指代相同的图元素。
具体实施方式
以下描述被呈现来使得本领域的任何技术人员能够做出并使用实施例,并且是在特定应用及其要求的上下文中提供的。对所公开的实施例的各种修改对于本领域的技术人员而言将是容易地显而易见的,并且在不脱离本公开的精神和范围的情况下,可以将本文所定义的一般原理应用于其他实施例和应用。因此,本文所描述的实施例不限于所示出的实施例,而是将符合与本文所公开的原理和特征一致的最宽范围。
概要
本文所描述的实施例提供解决在执行输入/输出(i/o)请求时由于逻辑块的大小与物理块的大小之间的不一致而产生的挑战问题的系统。该系统还解决由大ftl表以及在执行i/o请求时通常涉及的表查找所产生的低效率。
存储在驱动器上的数据通常是基于文件系统和闪存转换层(ftl)来组织的,所述ftl将数据的逻辑块地址(lba)映射到驱动器的物理块地址(pba)。然而,在逻辑块的大小(例如,512b或4096b)与物理块的大小(例如,16kb)之间可以存在显著不一致。作为将lba映射到pba的一部分,ftl维护查找表,其中每一4kblba被指派一个条目,所述条目它本身具有4b的近似大小。在具有16tb容量的ssd中,此ftl查找表可具有40亿个条目(即,16tb/4kb=4e+9)。假如每个条目是4b,则ftl查找表可以和16gb(即,4e+9x4=16e+9)一样大。
此大16gbftl查找表可以导致若干问题。该表可以被存储在非易失性存储器(例如,nand闪存)中以确保内容的完整性,但是在给驱动器加电的同时加载这种大表可能花费大量时间。该表可以被存储在ssd的片外dram中,但是ssd必须安装16gb表以支持16tb容量ssd。随着ssd的容量增加,dram也必须增加。因为dram的成本可以很高,所以随之而来的ssd成本也可以很高。
此外,逻辑块大小(例如,4kb)与物理块大小(例如,16kb)之间的不一致可导致低效率和过度设计。基于逻辑大小(4kb)的小粒度生成并存储对应且必要的元数据可导致对驱动器的容量的次优利用。例如,处理元数据可以导致非平凡的开销并且存储元数据可以使用大量的存储器容量。因此,传统ssd和文件系统的缺点可降低系统的效率和总体性能。
本文所描述的实施例提供通过在执行i/o请求时执行实时计算来解决这些缺点的系统。该系统可以是分布式存储系统的一部分,在所述分布式存储系统中可以定制非易失性存储器以避免传统ssd和文件系统的前述缺点。非易失性存储器(其也被称为非易失性存储器)的示例包括但不限于:闪速存储器(例如,闪存驱动器);只读存储器;磁计算机存储设备(例如,硬盘驱动器、固态驱动器、软盘和磁带);以及光盘。
在写入操作中,系统可将数据划分成多个分块(chunk),其中分块由多个大块(bulk)组成。分块可具有例如64mb的大小,并且大块可具有例如128kb的大小。系统可将数据以大块为单位顺序地写入到驱动器。系统还可存储要写入的数据(例如,文件)与写入数据在闪存驱动器中的位置的分块索引和大块索引(例如,对应的位置信息)之间的映射。这允许系统在驱动器中写入数据并存储数据的位置信息,而无需在闪存转换层中访问lba至pba映射表。在下面关于图4a-4d描述示例性写入操作。
在读取操作中,不是普遍地将驱动器的存储划分成小块(例如,512b或4kb,如在传统ssd中的扇区中一样),而是系统可使用分块索引、文件偏移、请求的偏移和请求的长度以读出数据。文件偏移是文件的开头与对应于分块索引的分块的开头之间的空间。所请求的偏移是文件的开头与在文件内开始读取文件的起始位置之间的空间(例如,当由用户请求的数据从在文件中除文件的开头以外的位置开始时)。请求长度可涵盖整个文件,或者可涵盖文件的仅一部分。系统可通过基于分块索引和文件偏移(以及所请求的偏移,如果被包括的话)对于所请求的文件执行大块索引的实时计算来从驱动器读取数据。在下面关于图5a-5b描述示例性读取操作。
因此,本文所描述的实施例提供改进存储系统的效率和性能的系统。通过基于大块单元在闪存驱动器中组织数据,并且通过基于作为最小量的大块单元存储位置信息(例如,分块索引、大块索引和偏移),系统可消除对大ftl表(例如,其对于每个4kb扇区单元来说通常可包括4b条目)的需要。系统可将数据按照分块和大块写入到闪存驱动器,并且通过执行实时计算以确定数据的位置来存储随后读取数据所需的位置信息。因此,系统通过避免ftl查找克服了基于逻辑块大小(例如,4kb)与物理块大小(例如,16kb)之间的不一致而产生的低效率。此外,系统可降低在存储数据时涉及的开销、访问存储的数据所涉及的延迟、硬件的成本以及驱动器上的固件的复杂性。
示例性环境和网络
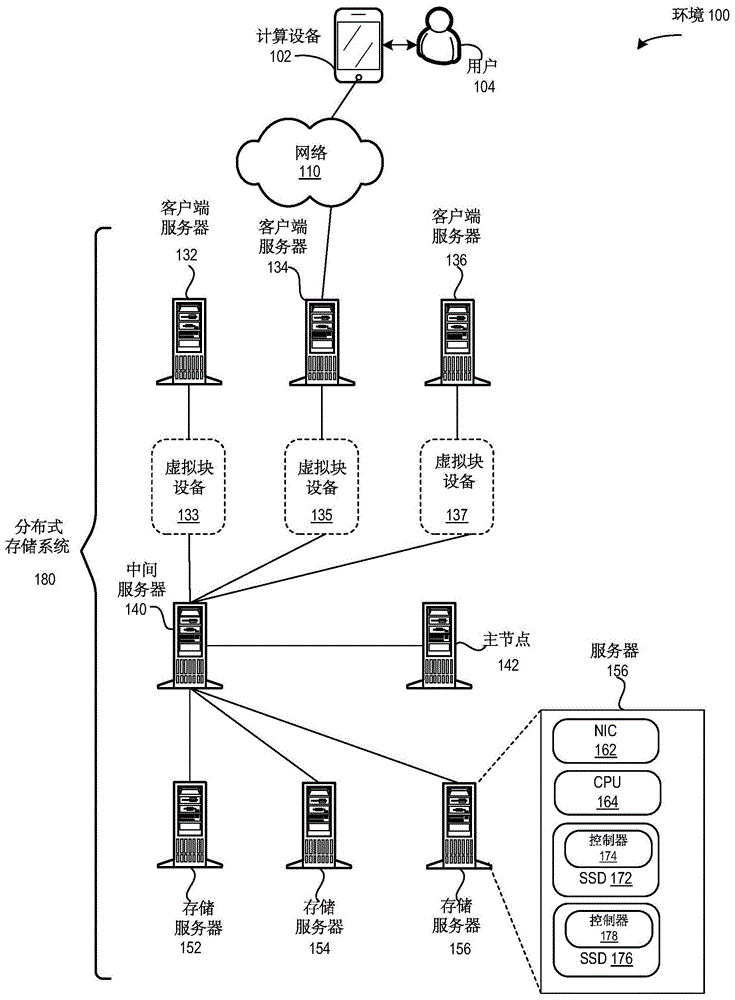
图1图示依照本申请的实施例的促进逐分块数据组织的示例性环境100。环境100可包括计算设备102和相关用户104。计算设备102可经由网络110与分布式存储系统180进行通信,所述分布式存储系统180可包括:客户端服务器132、134和136,它们分别被各自映射到逻辑或虚拟块设备133、135和137;中间服务器140;主节点142;以及存储服务器152、154和156。中间服务器140可处理来自客户端服务器132-136的传入i/o请求(分别经由虚拟块设备133、135和137接收)。与传入i/o请求相关联的数据不由客户端服务器132-136或者由对应的虚拟块设备133-137保持。不是被客户端服务器132-136直接地访问,而是主节点142可经由中间服务器140按需与客户端服务器进行通信。主节点142可确定路径信息,例如,放置/存储数据或者从中读取数据的多个副本的位置,同时中间服务器140可缓存路径信息。允许中间服务器140检索/缓存路径信息可导致减小的总体延迟并且还可减轻主节点的负担。
存储服务器可包括多个存储驱动器,并且每个驱动器可包括控制器和用于数据存储的多个物理介质。例如,存储服务器156可包括:网络接口卡(nic)162;中央处理单元(cpu)164;具有控制器174的ssd172;以及具有控制器178的ssd176。可基于副本的数量将虚拟块设备映射到多个驱动器。传入数据首先被组织或者划分成逻辑“分块”,其中分块的大小可从mb到数十mb(例如,64mb)变动。每个分块被组织或者划分成“大块”,其中大块可以是具有大小为128kb的单元。每个大块可被设计为逻辑扇区的倍数(例如,512b或4kb)。
示例性逐分块数据组织
图2图示依照本申请的实施例的驱动器中的示例性逐分块数据组织200。数据可经由映射的虚拟块设备133从客户端服务器132传递到ssd驱动器172(经由通信250和252)。ssd驱动器172可包括被划分成逻辑组分块和大块的存储器。存储器可包括i/o解除阻塞层240,所述i/o解除阻塞层240包括分块210-218,其中分块可具有64mb的大小。每个分块可被划分成大块,所述大块可包括i/o合并层242(其在本文所描述的实施例中是用于写入操作的数据的单位)。例如,分块214可被划分成大块220-226,并且i/o合并层242可包括大块220-226以及包括分块210-218的其他大块。每个大块可被划分成扇区,所述扇区可包括lba格式244(其在本文所描述的实施例中是用于读取操作的数据的单位)。例如,大块222可被划分成扇区230-236,并且lba格式244可包括扇区230-236以及包括i/o合并层242的大块的其他扇区。
在写入操作期间,当数据由客户端服务器132接收到时,系统可在没有阻塞的情况下将该数据从客户端服务器132转移到容纳ssd驱动器172的存储服务器。在ssd驱动器172内部,物理存储介质可执行i/o合并层242的角色。例如,ssd驱动器172(或容纳ssd172的存储服务器)可缓冲要写入的输入数据。当累积在缓冲器中的数据的大小大于大块的大小时,系统可将数据顺序地写入到物理ssd驱动器172中。如果累积在缓冲器中的数据的大小小于大块的大小,则系统可记录数据,并且等待直到缓冲器中的数据的大小已达到大块的大小为止。因此,可基于大块的单位写入ssd172的存储介质,从而消除将扇区单元用于写入映射的需要。
在读取操作期间,系统可将传入读取请求/文件转换成分块索引、分块内的偏移(“文件偏移”)以及要读取的数据的请求长度。文件偏移可以是文件的开头与对应于分块索引的分块的开头之间的空间。传入读取请求还可指示请求的偏移,所述请求的偏移可以是文件的开头与在文件内开始读取文件的起始位置之间的空间(例如,当请求被读取的数据从在文件中除文件的开头以外的位置处开始时)。请求长度可涵盖整个文件或文件的仅一部分。
读取操作可使用这三个参数:分块索引;文件偏移;以及请求长度。基于这三个参数(并且由于写入操作的顺序性质),系统可执行实时计算以确定要读取并且如存储在物理存储介质上的请求数据的确切物理位置。如果读取请求指示请求的偏移,则读取操作还可将所请求的偏移用作第四参数来执行读取操作。
虽然中间水平的大块粒度可被用于写入操作,但是读取操作不需要使用此中间水平的粒度,并且因此也不需要维护逐扇区映射(例如,不需要维护具有4b条目的ftl表,其中一个条目对应于物理存储介质的每个4kb扇区)。
图3图示依照本申请的实施例的驱动器的物理空间300中的示例性逐分块数据组织。物理空间300可包括规则/活动物理区域302和保留物理区域332。活动区域302可包括各自对应于逻辑分块的物理单元,其中每个物理单元(或表示的逻辑分块)可被划分成多个大块。每个大块可被划分成多个页面。例如,活动区域302可包括物理单元310,所述物理单元310包括多个大块,诸如大块312。大块312可包括多个页面,诸如页面314、316和318。活动区域302还可包括物理单元320,所述物理单元320包括多个大块,诸如大块322。保留物理区域332可包括空闲物理单元340和350。
每个分块可对应于或者被映射到一定量的物理单元(例如,数据的逻辑分块可对应于具有诸如64mb的大小的物理单元)。相应的存储服务器可存储此映射。在一些实施例中,中间服务器还可维护此映射,例如,通过由系统缓存最近使用或访问的条目以确保更高效的访问。
取决于写入指针的当前位置,可将传入数据放置到当前打开的分块中或者放置到新分块中。结果,无论传入数据是否是对现有数据的更新,它都被始终视为新数据。系统还可在逐分块基础上执行回收的内部进程。例如,当分块被标记用于回收时,系统可复制出数据的有效部分并且将那些有效部分写入到空闲分块中。也就是说,准备好被回收的数据可被从活动物理单元移动到保留物理单元(例如,如通过通信362所示出的)。来自保留区域的空闲物理单元可被打开并用作活动物理单元(例如,如通过通信360所示出的)。
系统还可通过写入与要写入到驱动器或者从驱动器读取的文件相关联的元数据来更新元数据区域。系统可进一步在被写入到驱动器的大块中写入与(缓存的)数据相关联的分层元数据。系统可将元数据向下传递到驱动器并且也可将元数据存储在驱动器中。
用于促进逐分块数据组织的方法(写入操作)
图4a呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图400。在操作期间,系统接收指示要写入到非易失性存储器的文件的请求,其中,非易失性存储器被划分成多个逻辑分块,并且其中,分块被划分成多个大块(操作402)。如上面所讨论的,非易失性存储器可以是例如闪存驱动器或ssd。系统确定与文件相关联的第一大块被成功地缓存在缓冲器中(操作404)。系统将第一大块写入到非易失性存储器中的位置,其中,多个大块被顺序地写入在非易失性存储器中(操作406)。系统在数据结构中存储在文件与一组对应的位置信息之间的映射,其中,位置信息包括非易失性存储器中的存储的分块索引和大块索引,而不用在闪存转换层中访问逻辑块地址至物理块地址映射(操作408)。
图4b呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图410。在操作期间,系统接收指示要写入到存储服务器的非易失性存储器的文件的请求,其中,非易失性存储器被划分成多个逻辑分块,并且其中,分块被分成多个大块(操作412)。存储服务器可包括多个非易失性存储器。系统将文件划分成第一多个分块(操作414)。系统可获得文件的对应元数据,其可指示用于每个分块的索引和文件的长度。系统确定当前分块是否被密封(判定416)。如果不是,则系统从写入指针的当前位置开始将文件附加到当前分块的末尾(操作418)。如果当前分块被密封(判定416),则系统将新分块作为当前分块打开(操作422),并且将文件写入到当前分块(操作424)。系统还可重置写入指针。系统将与文件相关联的元数据写入到当前分块中(操作426),并且由第一服务器向第二服务器发送文件和相关元数据(操作428)。操作像图4c的标签a处所描述的那样继续。
图4c呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图430。在操作期间,系统由第二服务器接收文件和相关元数据(操作432)。系统确定路径信息是否被缓存在第二服务器处(判定434)。路径信息可指示要将文件写入到的一个或更多个存储服务器。如果路径信息未被缓存在第二服务器处(判定434),则系统由第二服务器从主节点中检索路径信息(操作436)。系统由第二服务器缓存路径信息(操作438)。
如果路径信息被缓存在第二服务器处(判定434),则系统基于路径信息确定要将传入文件和元数据写入到的一个或更多个存储服务器(操作440)。系统通过第二服务器向存储服务器发送要存储为副本的文件和相关元数据(操作442)。系统通过相应的存储服务器来接收文件和相关元数据(即,要存储的副本)(操作444),并且操作像图4d的标签b处所描述的那样继续。
图4d呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中写入数据的方法的流程图460。在操作期间,系统通过相应的存储服务器来将传入文件和元数据以大块为单位缓存在缓冲器中(操作462)。当大块满了时,系统将数据写入到非易失性存储器。例如,如果大块满了(判定464),则系统通过相应的存储服务器来将大块中的缓存数据写入到与相应的存储服务器相关联的第一非易失性存储器中的位置,其中,多个大块被顺序地写入在非易失性存储器中(操作466)。如果大块未满(判定464),则系统等待直到相应的存储服务器已缓存足够的数据以将缓冲器填充至大块的大小为止(例如,操作462)。回想一下,非易失性存储器可以是例如闪存驱动器或ssd。如果分块或大块(如在判定464中一样)打开持续超过预定时间段,则驱动器可主动地密封循环(例如,通过关闭分块或大块,或者通过将小于大块的大小的数据写入到驱动器)。
随后,系统将与经缓存的数据相关联的分层元数据写入到元数据区域中,其中,分层元数据包括与在第一非易失性存储器中写入有经缓存的数据的位置相对应的分块索引和大块索引(操作468)。如果文件不是要写入的最终文件(判定470),则操作返回到图4b的操作412。如果文件是要写入的最终文件(判定470),则系统通过填充数据来密封当前分块和大块(操作472)。注意的是,如果分块打开持续大于预定时间段,则系统可通过关闭当前分块并且填充数据来主动地密封循环。系统通过相应的存储服务器来在数据结构中存储文件与该文件的一组对应的位置信息(包括分层元数据)之间的映射(操作474)。数据结构可以由存储服务器维护。在一些实施例中,数据结构还可以由第二服务器(例如,图1的中间服务器140)维护,诸如最近使用或访问的条目的缓存版本以确保更高效的访问。
用于促进逐分块数据组织的方法(读操作)
图5a呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中读取数据的方法的流程图500。在操作期间,系统接收指示要从存储服务器的非易失性存储器读取的文件的请求,其中,非易失性存储器被划分成多个逻辑分块,并且其中,分块被划分成多个大块(操作502)。系统基于请求确定分块索引、在文件的开头与对应于分块索引的分块的开头之间的第一偏移以及文件的请求长度(操作504)。系统还可确定请求中所指示的第二偏移,其中第二偏移是在文件的开头与在文件内从中读取文件(例如,当读取文件的仅一部分时)的起始位置之间的空间(未示出)。
如果请求指示读取整个文件,则系统可使用分块索引和第一偏移来访问文件,如下所述。如果请求指示读取文件的一部分,则系统可使用分块索引、第一偏移和第二偏移来访问文件。例如,系统可读出一个物理页面(例如,16kb),并且计算第一比特的位置,然后从该点读取许多比特,其中比特的数量通过请求长度来确定。
系统通过第二服务器从第一服务器接收请求(操作506)。系统确定路径信息是否被缓存在第二服务器处(判定508)。路径信息可指示要将文件写入到的一个或更多个存储服务器。如果路径信息未被缓存在第二服务器处(判定508),则系统通过第二服务器从主节点中检索路径信息(操作510)。系统通过第二服务器来缓存路径信息(操作512)。
如果路径信息被缓存在第二服务器处(判定508),则系统基于路径信息确定从中读取所请求的文件的一个或更多个存储服务器(操作512),并且操作像图5b的标签c处所描述的那样继续。
图5b呈现图示依照本申请的实施例的用于在促进逐分块数据组织的系统中读取数据的方法的流程图530。在操作期间,系统从相应的存储服务器的非易失性存储器(即,从多个副本中的一个)读取所请求的文件(操作532)。系统基于分块索引和第一偏移计算所请求的文件的大块索引(操作534)。系统基于大块索引识别相应的存储服务器的非易失性存储器中的位置(操作536)。系统还可基于所识别的位置计算或者确定所请求的文件的物理块地址。位置可对应于所计算出的大块索引并且可基于分块索引和所计算出的大块索引。
系统基于请求长度从相应的存储服务器的非易失性存储器中的所识别的位置读取所请求的文件,而不用在闪存转换层中查找逻辑块地址至物理块地址映射(操作538)。如果读取是成功的(判定540),则系统将所请求的读取数据发送到请求主机(操作542)。
如果读取是不成功的(判定540),则系统确定这是否是最后副本(即,是否存在任何剩余的副本)(判定550)。如果这不是最后副本(即,存在剩余的副本)(判定550),则操作返回到操作532(例如,基于路径信息从相同或不同的存储服务器的另一驱动器上的另一副本读取所请求的文件)。如果这是最后副本,则系统向第一服务器报告读取失败并且从备份读取所请求的文件(操作552)。系统可从备份异步地读取数据。
如果所请求的文件不是要读取的最后文件(判定554),则操作在图5a的操作502处继续。如果所请求的文件是要读取的最后文件(判定554),则操作返回。
示例性计算机系统
图6图示依照本申请的实施例的促进逐分块数据组织的示例性计算机系统600。计算机系统600包括处理器602、存储器604和存储设备608。存储器604可包括用作受管理存储器的易失性存储器(例如,ram),并且可用于存储一个或更多个存储器池。计算机系统600可以是计算设备或存储设备。此外,计算机系统600可联接到显示设备618、键盘612和指点设备614。存储设备608可存储操作系统616、内容处理系统618和数据634。
内容处理系统618可包括指令,所述指令当由计算机系统600执行时,可使计算机系统600执行本公开中所描述的方法和/或过程。例如,内容处理系统618可包括用于接收并发送数据分组的指令,所述数据分组包括指示要从非易失性存储器(例如,闪存驱动器或ssd)读取或者写入到非易失性存储器(例如,闪存驱动器或ssd)的文件的请求、要编码并存储的数据或数据的块或页面。
内容处理系统618可进一步包括用于接收指示要从非易失性存储器读取的文件的请求的指令,其中,非易失性存储器被划分成多个逻辑分块,并且其中,分块被划分成多个大块(通信模块620)。内容处理系统618可包括用于基于请求确定分块索引、文件的开头与对应于分块索引的分块的开头之间的第一偏移以及文件的请求长度的指令(位置信息确定模块622)。内容处理系统618还可包括用于基于分块索引和第一偏移计算所请求的文件的大块索引的指令(位置识别模块624)。内容处理系统618可包括用于基于大块索引识别非易失性存储器中的位置的指令(位置识别模块624)。内容处理系统618可附加地包括用于在不用在闪存转换层中查找逻辑块地址至物理块地址映射的情况下基于请求长度从非易失性存储器中的所识别的位置读取所请求的文件的指令(数据读取模块628)。
内容处理系统618还可包括用于接收指示要写入到非易失性存储器的文件的请求的指令(通信模块620)。内容处理系统618可包括用于确定与文件相关联的第一大块被成功地缓存在缓冲器中的指令(数据写入模块632)。内容处理系统618可包括用于将第一大块写入到非易失性存储器中的位置的指令,其中,多个大块被顺序地写入在非易失性存储器中(数据写入模块632)。内容处理系统618可包括用于在数据结构中存储文件与一组对应的位置信息之间的映射的指令,其中,位置信息包括非易失性存储器的分块索引和大块索引,而不用在闪存转换层中访问逻辑块地址至物理块地址映射(数据结构管理模块626)。
内容处理系统618可进一步包括用于基于基于所请求的文件在数据结构中执行查找来确定分块索引的指令(数据结构管理模块626)。内容处理系统618可包括用于确定指示从中读取或者将所请求的文件写入到的一个或更多个存储服务器的路径信息的指令(路径确定模块630)。
数据634可包括被要求作为输入或者通过本公开中所描述的方法和/或过程生成作为输出的任何数据。具体地,数据634可存储至少:请求;指示要写入到非易失性存储器或者从非易失性存储器读取的文件或数据的请求;i/o请求;要存储、写入、加载、移动、检索或者复制的数据;数据的分块;数据的大块;数据的扇区;数据的页面;数据结构;文件与一组对应的位置信息之间的映射;逻辑分块;大块;分块索引;文件的开头与对应于分块索引的分块的开头之间的第一偏移;文件的长度;文件的请求长度;大块索引;非易失性存储器中的位置;逻辑块地址;物理块地址;文件的开头与在文件内从中开始读取文件的起始位置之间的第二偏移;指示从中读取或者将文件写入到的一个或更多个存储服务器的路径信息;以及预定时间段。
在此详细描述中描述的数据结构和代码通常被存储在计算机可读存储介质上,所述计算机可读存储介质可以是可存储代码和/或数据以供由计算机系统使用的任何设备或介质。计算机可读存储介质包括但不限于易失性存储器、非易失性存储器、诸如磁盘驱动器、磁带、cd(紧致盘)、dvd(数字通用盘或数字视频盘)的磁和光学存储设备,或能够存储现在已知或以后开发的计算机可读介质的其他介质。
可以将在具体实施方式部分中描述的方法和过程具体实现为代码和/或数据,所述代码和/或数据可被存储在如上所述的计算机可读存储介质中。当计算机系统读取并执行存储在计算机可读存储介质上的代码和/或数据时,计算机系统执行被具体实现为数据结构和代码并且存储在计算机可读存储介质中的方法和过程。
此外,上述的方法和过程可被包括在硬件模块中。例如,硬件模块可包括但不限于专用集成电路(asic)芯片、现场可编程门阵列(fpga)以及现在已知或以后开发的其他可编程逻辑器件。当硬件模块被激活时,硬件模块执行包括在硬件模块内的方法和过程。
已经仅出于图示和描述的目的呈现了本文所描述的前面的实施例。它们不旨在为详尽的或者将本文所描述的实施例限于所公开的形式。因此,许多修改和变化对于本领域的技术人员而言将是显而易见的。附加地,以上公开内容不旨在限制本文所描述的实施例。本文所描述的实施例的范围由所附权利要求来限定。
- 还没有人留言评论。精彩留言会获得点赞!