一种结合属性信息的实体多分类方法与流程
本发明涉及实体多分类技术,尤其涉及一种结合属性信息的实体多分类方法。
背景技术:
实体分类任务的目的是对一个实体结合其上下文信息赋予合适的类别标签。在实体多分类任务中,实体的类别标签仅有一个,通过分类模型预测类别标签概率,将概率最大的标签作为实体的类别。而实体的类别信息能够增强文本中实体的背景信息,有助于许多自然语言处理任务,如问答和阅读理解、知识库构建、实体链接和关系抽取等。
传统的实体多分类方法使用手工特征,依赖于专家知识而有一定局限。此外多数实体多分类方法判断实体的类别时仅考虑上下文信息,却忽视了有些句子信息并不充分。本发明提出了结合属性信息表示实体的深度学习模型,以便充分利用知识库中实体属性信息提供的丰富背景知识。同时考虑测试数据中实体属性信息可能缺失,本发明提出的模型通过联合训练属性和实体表示,从而避免预测阶段需要属性信息。此外,模型中还应用了字符级别信息表示实体的形态学和词形特征,并使用实体感知的注意力机制表示上下文特征。
技术实现要素:
本发明利用实体的文本信息以及知识库中属性列表信息,克服了现有方法忽视知识库信息以及实体上下文信息不充分的缺陷,提高实体多分类的效果,提供一种结合属性信息的实体多分类方法。
本发明解决其技术问题采用的技术方案如下:一种结合属性信息的实体多分类方法,包括以下步骤:
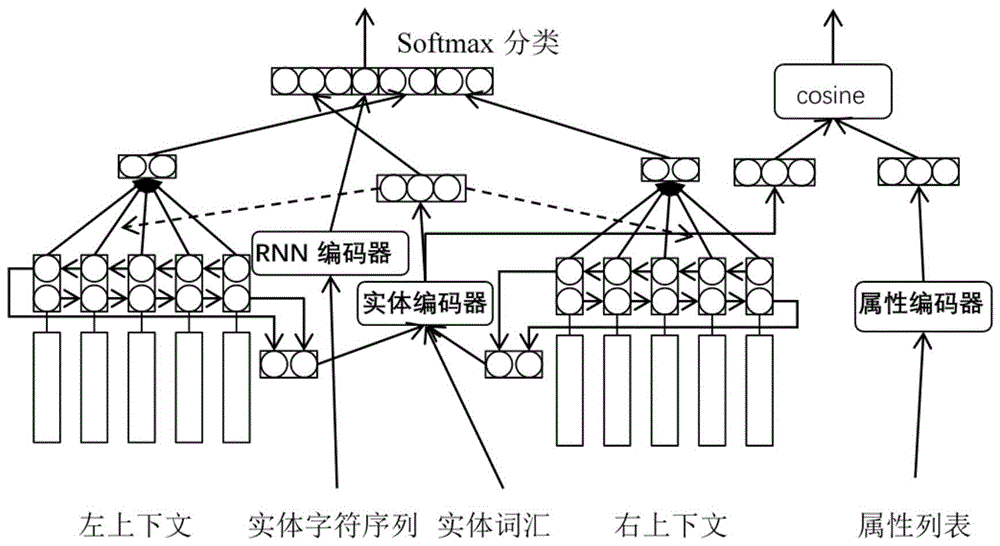
(1)使用循环神经网络表示实体字符级别特征,使用平均编码器表示实体词汇级别初步特征;
(2)使用双向lstm表示上下文初步特征,并结合上下文初步特征和实体词汇级别初步特征得到实体词汇级别的更新特征和最终特征,然后结合实体字符级别特征和实体词汇级别最终特征得到实体最终特征;
(3)使用实体感知的注意力机制得到上下文最终特征;
(4)使用max-pooling方式表示实体的属性特征,并联合实体词汇级别的更新特征构建实体-属性的cosine相似度损失函数;
(5)融合步骤(2)得到的实体最终特征和步骤(3)得到的上下文最终特征实现实体多分类,并构建交叉熵损失函数,最后联合步骤(4)得到的实体-属性损失函数进行优化训练。
进一步地,所述步骤(1)包括:
1.1)对语料中所有字符c建立字符表vc,使用随机初始化表示字符对应的向量,字符向量维度为dc,字符向量的映射函数uc表示为
1.2)使用循环神经网络(recurrentneuralnetwork,rnn)表示实体字符级别特征。设实体的字符序列表示echar=[c1,c2,…,cm],则字符级别特征为:
hi=f(wcuc(ci)+uchi-1)
ec=tanh(hm)
其中:ci、uc(ci)和hi分别表示i时刻的输入字符、字符的向量表示和隐层状态向量,m为实体的字符序列长度,wc、uc为rnn的权重矩阵,并将rnn最后一次输出的向量作为最终实体字符级别特征
1.3)设语料中所有词汇(包括属性的词汇)组成的词表为vw,词向量维度为dw,词向量的映射函数u表示为
其中:u(ei)表示第i个词汇的向量表示,n为实体的词汇序列长度。实体词汇级别初步特征
进一步地,所述步骤(2)包括:
2.1)使用双向lstm(longshort-termmemory,长短时记忆网络)表示上下文初步特征,其中lstm可以表示为:
it=σ(wi[ht-1;xt]+bi)
ft=σ(wf[ht-1;xt]+bf)
ot=σ(wo[ht-1;xt]+bo)
ht=ot⊙tanh(ct)
其中:xt表示t时刻输入向量,ht-1,ht分别是上一时刻和当前时刻的隐层状态向量,ct-1,ct分别是上一时刻和当前时刻的cell状态向量,
2.2)对于长度为c的左上下文contextleft=[lc,lc1,…,l2,l1],应用双向lstm得到编码序列为
2.3)对于长度为c的右上下文contextright=[r1,r2,…,rc],应用双向lstm得到编码序列为
2.4)结合上下文初步特征和实体词汇级别初步特征,实体词汇级别更新特征
其中:
2.5)结合实体字符级别特征ec和实体词汇级别最终特征
进一步地,所述步骤(3)中,应用实体感知的注意力机制,将实体信息作为上下文权重计算的输入之一,最终对所有的输出进行加权表示,得到上下文最终特征,具体为:
3.1)经双向lstm得到左上下文编码序列
其中:
3.2)经双向lstm得到右上下文编码序列
其中:
3.3)结合左上下文最终特征cleft和右上下文最终特征cright,上下文最终特征c表示为c=cleft;cright]。
进一步地,所述步骤(4)包括:
4.1)属性分词:实体的属性是知识库中实体属性键值对列表中的键名,因此实体属性列表表示为a(a1,a2,…,ar),其中每个属性通过中文分词后可以得到多个细粒度词汇,则第i个属性的词汇序列可表示为
4.2)对每个属性使用平均编码器得到属性的向量表示:
其中:u(aij)为第i个属性的第j个词汇的向量表示。
4.3)使用max-pooling方式对所有属性的向量表示进行处理,即对所有输入向量同一维度取最大值,得到实体的属性特征a:
a=maxpooling([a1,a2,…,ar])
4.4)联合实体词汇级别更新特征
通过联合训练实体和属性特征表示,可以消除预测阶段需要引入实体的属性信息。
进一步地,所述步骤(5)包括:
5.1)拼接实体最终特征e和上下文最终特征c得到实体多分类模型最终特征x=e;c],通过全连接网络后并应用softmax分类器预测每个类别的概率值,最终得到实体的类别概率分布向量
其中:wy是全连接层的参数,用于学习分类特征。
5.2)使用交叉熵作为实体多分类的损失函数jce(θ):
对于有n个类别的多分类问题,t表示真实标签,满足
5.3)通过实体-属性的cosine相似度损失函数ja(θ)和交叉熵损失函数jce(θ),得到联合的损失函数j(θ)为
其中:λa是属性信息训练的损失函数权重;
使用梯度下降法对损失函数j(θ)进行优化训练。
本发明所提出的方法与现有的实体多分类方法相比,具有以下优势:
1.使用属性信息增强实体表示,并通过实体和属性特征联合训练避免了预测阶段需要属性信息。
2.摒弃手工特征,仅利用神经网络构建实体多分类模型,并应用实体字符级别特征和实体感知的注意力机制表示上下文特征。
附图说明
图1是本发明提出的结合属性信息的实体多分类模型的示意图;
图2是实体多分类模型中实体编码器的示意图;
图3是实体多分类模型中属性编码器的示意图;
图4是实体编码器和属性编码器中使用的平均编码器示意图;
图5是实体多分类中实体字符序列的rnn编码器示意图。
具体实施方式
如图1中模型框架所示,结合图2至图5,本发明提出的结合属性信息的实体多分类方法,包括以下步骤:
(1)使用循环神经网络表示实体字符级别特征,使用平均编码器表示实体词汇级别初步特征,具体步骤如下:
1.1)对语料中所有字符c建立字符表vc,使用随机初始化表示字符对应的向量,字符向量维度为dc,字符向量的映射函数uc表示为
1.2)使用循环神经网络(recurrentneuralnetwork,rnn)表示实体字符级别特征。设实体的字符序列表示echar=[c1,c2,…,cm],则字符级别特征为:
hi=f(wcuc(ci)+uchi-1)
ec=tanh(hm)
其中:ci、uc(ci)和hi分别表示i时刻的输入字符、字符的向量表示和隐层状态向量,m为实体的字符序列长度,wc、uc为rnn的权重矩阵,并将rnn最后一次输出的向量作为最终实体字符级别特征
1.3)设语料中所有词汇(包括属性的词汇)组成的词表为vw,词向量维度为dw,词向量的映射函数u表示为
其中:u(ei)表示第i个词汇的向量表示,n为实体的词汇序列长度。实体词汇级别初步特征
(2)使用双向lstm表示上下文初步特征,并结合上下文初步特征和实体词汇级别初步特征得到实体词汇级别的更新特征和最终特征,然后结合实体字符级别特征和实体词汇级别最终特征得到实体最终特征,具体步骤如下:
2.1)使用双向lstm表示上下文初步特征,其中lstm可以表示为:
it=σ(wi[ht-1;xt]+bi)
ft=σ(wf[ht-1;xt]+bf)
ot=σ(wo[ht-1;xt]+bo)
ht=ot⊙tanh(ct)
其中:xt表示t时刻输入向量,ht-1,ht分别是上一时刻和当前时刻的隐层状态向量,ct-1,ct分别是上一时刻和当前时刻的cell状态向量,
2.2)对于长度为c的左上下文contextleft=[lc,lc1,…,l2,l1],应用双向lstm得到编码序列为
2.3)对于长度为c的右上下文contextright=[r1,r2,…,rc],应用双向lstm得到编码序列为
2.4)结合上下文初步特征和实体词汇级别初步特征,实体词汇级别更新特征
其中
2.5)结合实体字符级别特征ec和实体词汇级别最终特征
(3)使用实体感知的注意力机制得到上下文最终特征,具体步骤如下:
应用实体感知的注意力机制,将实体信息作为上下文权重计算的输入之一,最终对所有的输出进行加权表示,得到上下文最终特征,具体为:
3.1)经双向lstm得到左上下文编码序列
其中:
3.2)经双向lstm得到右上下文编码序列
其中:
3.3)结合左上下文最终特征cleft和右上下文最终特征cright,上下文最终特征c表示为:
c=cleft;cright]
(4)使用max-pooling方式表示实体的属性特征,并联合实体词汇级别的更新特征构建实体-属性的cosine相似度损失函数,具体步骤如下:
4.1)属性分词:实体的属性是知识库中实体属性键值对列表中的键名,因此实体属性列表表示为a(a1,a2,…,ar),其中每个属性通过中文分词后可以得到多个细粒度词汇,则第i个属性的词汇序列可表示为
4.2)对每个属性使用平均编码器得到属性的向量表示:
其中:u(aij)为第i个属性的第j个词汇的向量表示。
4.3)使用max-pooling方式对所有属性的向量表示进行处理,即对所有输入向量同一维度取最大值,得到实体的属性特征a:
a=maxpooling([a1,a2,…,ar])
4.4)联合实体词汇级别更新特征
通过联合训练实体和属性特征表示,可以消除预测阶段需要引入实体的属性信息。
(5)融合步骤(2)得到的实体最终特征和步骤(3)得到的上下文最终特征实现实体多分类,并构建交叉熵损失函数,最后联合步骤(4)得到的实体-属性损失函数进行优化训练,具体步骤如下:
5.1)拼接实体最终特征e和上下文最终特征c得到实体多分类模型最终特征x=e;c],通过全连接网络后并应用softmax分类器预测每个类别的概率值,最终得到实体的类别概率分布向量
其中:wy是全连接层的参数,用于学习分类特征;
5.2)使用交叉熵作为实体多分类的损失函数jce(θ):
对于有n个类别的多分类问题,t表示真实标签,满足
5.3)通过实体-属性的cosine相似度损失函数ja(θ)和交叉熵损失函数jce(θ),得到联合的损失函数j(θ)为
其中:λa是属性信息训练的损失函数权重。
使用梯度下降法对损失函数j(θ)进行优化训练。
实施例
下面结合本技术的方法详细说明该实例实施的具体步骤,如下:
(1)本实例采用的数据集构建自英文维基百科以及wikidata数据。利用wikidata获得属性名,经过清洗获得约24万实体及其属性信息列表。此外建立包括25个标签的实体类别体系,通过远程监督的方法将wikidata中类别信息为实体标注,并选择维基百科中包含实体的文本作为上下文。最后将数据划分为训练集和测试集,其中训练集数据大小是430389,测试集数据大小是37900。
(2)选择tensorflow框架根据上述步骤构建深度学习分类模型,并使用300维的glove作为词向量,100维的随机初始向量作为字符向量,adam方法优化训练步骤5.3)中联合损失函数。
(3)模型的输入包括实体词、实体的字符序列、实体的句子上下文,此外在训练阶段还需要输入实体的属性列表,通过神经网络分别得到实体和上下文特征表示,经过全连接以及softmax分类后将概率值最大的标签作为实体的预测类别。
(4)模型使用宏平均(包括macroprecision,recall,f1)以及正确率(accuracy)依存进行效果评估。
(5)相关的对比实验包括:
a.基础模型:本发明提出的模型去除字符级别特征以及属性信息,同时上下文特征表示中未使用实体作为注意力机制的输入;
b.基础模型+字符级别特征:在基础模型上增加实体的字符级别特征,并将实体的词汇级别特征作为实体感知注意力模型的输入;
c.基础模型+属性信息特征:在基础模型之上增加属性信息进行联合训练;
d.完整模型:即本发明提出的模型,包括实体属性信息联合训练以及字符级别特征、实体感知的注意力机制。
(6)实验结果
各个模型的实验结果如下表所示:
对比上述模型的实体多分类效果,本发明提出的结合属性特征的模型相比基础模型有较大的提升效果,此外实体的字符级别特征对实体多分类也有促进效果。因此,结合属性信息的实体多分类模型能够有效利用知识库中实体属性信息,进而补充上下文信息,对于实体分类任务有良好的使用价值和应用前景。
上述具体实施方式用来解释说明本发明,而不是对本发明进行限制,在本发明的精神和权利要求的保护范围内,对本发明作出的任何修改和改变,都落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!