一种基于用户社区和评分联合社区的推荐方法与流程
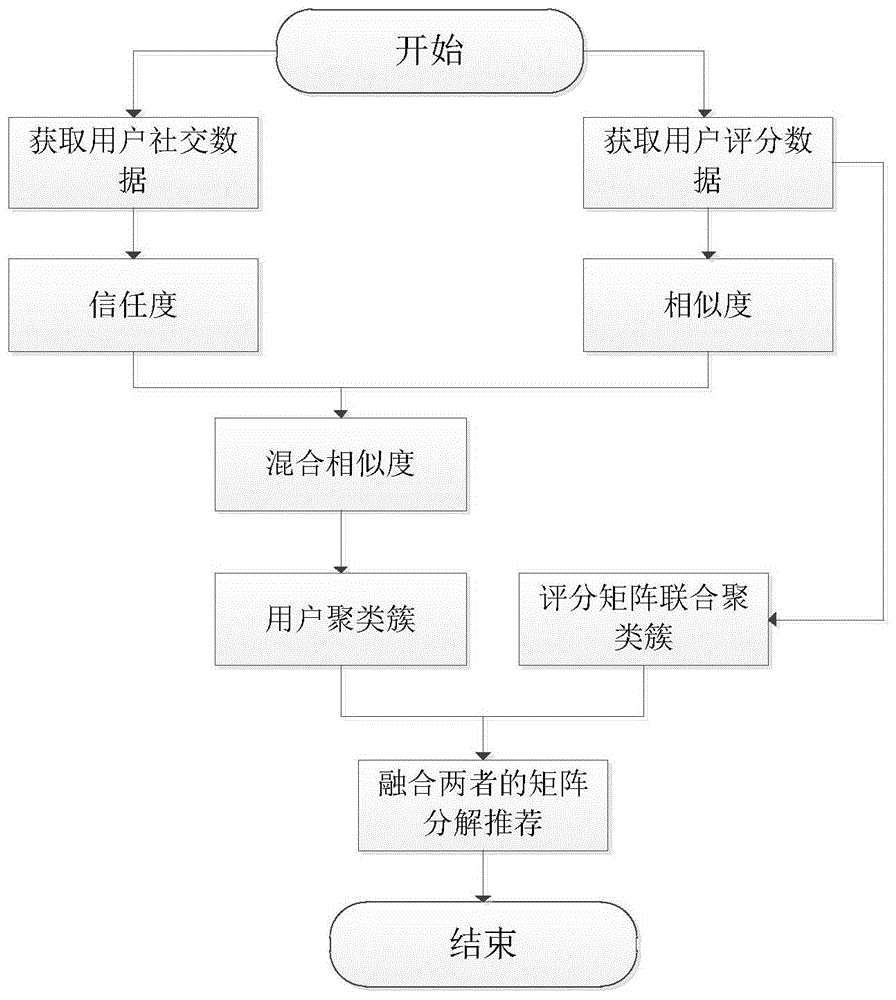
本发明属于个性化推荐领域,具体的说是一种基于用户社区和评分联合社区的推荐方法。
背景技术:
随着信息技术的发展,带来了信息超载问题,面对如此庞大的网络数据,带给用户的不是大数据的优越感,而是一种在如此庞大的数据中的不知所措,这样反而让信息的使用效率降低了。很多时候用户都没有明确的需求,这样推荐系统便应运而生。推荐系统就是在用户需求不明确的情况下,根据用户的历史行为记录,比如用户的浏览记录,购买记录,播放视频记录等等,以这些历史记录为基础为用户推荐感兴趣的物品,帮助用户发现物品的价值。
目前存在的推荐算法中,协同过滤算法是使用最为普遍的算法之一,其主要依靠用户的历史记录,给用户推荐相似的商品,尽管该算法能保持比较好的推荐精度,但也存在着时间复杂度高的问题。
由于时间复杂度高的问题,一些基于社区的推荐技术也在不断被提出,其主要思想是基于用户的历史行为信息,利用社区挖掘技术将相似的用户或项目划分到同一个社区中,然后在每一个社区中应用传统的协同过滤推荐算法。但是当前的研究工作大多只考虑了单一的信息源的社区结构,比如用户社区,项目社区等,因此探究多种社区结构相结合是一个重点要研究的问题。
技术实现要素:
本发明旨在解决以上现有技术的问题。提出了一种方法。本发明的技术方案如下:
一种基于用户社区和评分联合社区的推荐方法,其包括以下步骤:
1)、首先,基于用户间的社交关系数据得到用户间的信任度,基于用户间的评分数据得到用户间的相似度,从而得出用户间的混合相似度值;
2)、然后根据混合相似度的值对用户采用改进的k-means聚类操作,改进k-means聚类操作改进主要在于对用户成为专家的可能性进行评估,寻找专家值最大的k个用户作为初始的聚类中心,最后得到用户聚类簇;
3)、其次,根据评分矩阵的评分模式利用概率的方法对评分矩阵中的用户和商品进行联合聚类,得到评分矩阵联合聚类簇;
4)、最后面向用户-物品的联合社区结构利用矩阵分解技术,并融合用户聚类簇和评分矩阵联合聚类簇进行用户社区结构进行推荐。
进一步的,步骤1)中所述分别利用输入的用户社交关系数据和用户评分数据构建用户间的信任关系和相似关系,融合两者构建新的相似度计算方法,其计算公式如下:
sim(u,v)=β·trust(u,v)+(1-β)·simrat(u,v)(1)
式中trust(u,v)和simrat(u,v)分别表示用户间的信任关系和评分相似性,trust(u,v)表示信任矩阵t中用户u和用户v之间的信任关系,rat(u,v)表示用户u和v之间的相似关系;定义一个权重β来表示二者所占的比重,为了权衡信任关系和相似关系,这里将β设置为0.5。
进一步的,所述用户间的信任度、用户间的相似度分别为:
定义用户间的信任关系值度量公式如下:
式中,t(u,v)∈(0,1],d(u,v)是用户u和用户v之间的最短距离;
定义用户间的相似关系,提出一种基于用户评分偏好的相似度计算方法,其计算公式如下:
其中,
进一步的,所述步骤2)利用改进k-means算法对用户进行聚类操作,具体包括以下步骤:
(1)、从可信度tu,权威性au以及评分多样性du三个指标出发,对用户成为专家的可能性进行评估,式(4),(5)和(6)分别表示用户的可信度,权威性以及评分多样,综合这三个指标的均值
式中,du表示用户u的入度,dmax表示信任网络中入度的最大值。nu表示用户u评过分的物品数量。vu表示用户u的评分方差。
(2)、取专家值最大的k个用户作为初始的簇中心集合,用集合的形式表示为u={expert(u1),expert(u1),…expert(uk)},其中,expert(uk)表示用户uk的专家值;聚类中心集合记为center={ce1,ce2,…cek},其中cek表示第k个聚类簇的聚类中心;并初始化k个聚类簇,记作c={c1,c2,…ck},其中ck表示第k个聚类簇。
(3)、对用户集合中的每个用户,计算其与所有聚类中心的混合相似度,找到其中相似度最大的用户max(sim(u,cei)),将用户u加入聚类中心cei所在的聚类簇ci;
(4)、更新所有的聚类中心,计算每个聚类簇中用户混合相似度均值最大的用户作为新的聚类中心,利用混合相似度计算每个簇中的用户与聚类中心的误差平方和
(5)、若聚类中心未发生改变,则整个过程结束,若聚类中心发生改变,则回到步骤(3)继续执行。
进一步的,所述步骤3)根据评分矩阵的评分模式利用概率的方法对评分矩阵中的用户和商品进行联合聚类,得到评分矩阵联合聚类簇具体包括以下步骤:
(1)、随机初始化每个评分属于某个类别的概率p(k|ui,vj,r),满足
∑k′∈kp(k′|ui,vj,r)=1,其中k′表示某个类别,r表示用户ui对物品vj的评分。设置迭代的阈值ωmax,初始化迭代次数ω=1;
(2)、对评分矩阵中的每一个用户和项目,分别根据公式(7),(8)和(9)计、算该用户和项目属于某个类别的概率以及某个类别中存在某个评分的概率;
其中,r表示用户ui对物品vj的评分。式(7)中v(ui)表示用户ui评分过的项目集合,k′表示某个聚类簇;式(8)中u(vj)表示对物品vj有过评分的用户集合,式(9)中r′表示不同的评分集合;
(3)、利用公式(10)计算第ω次迭代时用户ui对项目vj的评分rij属于第k个类别的概率,式中对每个概率加上α,β,γ是为了防止分母为0而设置的超参数;
令ω=ω+1,并判断ω≤ωmax是否成立,如果成立的话则返回步骤(3)继续执行,如果不满足则表示获得了评分属于某个类别的概率;
重复步骤(2),(3)和(4),直到所有的用户和项目以及评分都被划分到概率最大的类别中去。
进一步的,所述步骤4中面向评分矩阵的联合社区结构进行矩阵分解,其正则化公式为:
式中,mw表示存在于第w个评分联合社区内的用户个数,α为调整聚类正则化程度的系数,iig为指示函数,g∈{1,2,3...k},k表示社区数量,iig的取值情况是,如果用户ui在社区g内时其值为1,否则为0;neg(i)表示与用户ui在同一社区中的邻居用户集合,ui为用户ui的偏好,uf表示邻居用户uf的偏好,其邻居用户的平均偏好记作
因此,融合矩阵分解的框架得到一种结合社区结构和用户-项目聚类的联合矩阵分解模型,其目标函数如下所示:
式中,
因此,融合矩阵分解的框架可以得到一种结合社区结构和用户-项目聚类的联合矩阵分解模型,其目标函数如下所示:
式中,
按照公式(15)获得预测评分,将满足要求的评分推荐给相应的用户;
式中,
本发明通过结合用户社区和评分矩阵的联合社区,解决了协同过滤算法中推荐的时效低的问题,同时还能保持一定的推荐精度。
1.本发明在步骤2.2中利用专家用户来作为k-means算法的初始聚类中心,改进了原始聚类中心选择的随机性,这种处理有助于发现更合理的用户社区结构。
2.本发明在步骤3中利用用户、项目和评分属于某个类别的概率来划分类别,这样保证了联合社区发现的可靠性,有助于提高推荐的效率。
3.本发明在步骤4中将用户社区结构和评分矩阵联合社区结构相结合,基于联合社区的子矩阵来进行矩阵分解,有助于在保持不错的推荐精度的同时,提高推荐的效率。
附图说明
图1是本发明提供优选实施例基于用户社区和评分联合社区的推荐方法流程示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
在本实施例中,一种基于用户社区和评分联合社区的推荐方法是按如下步骤进行的。
步骤1构造用户间的混合相似度
步骤1.1在社交网络中,人与人之间存在着一种相互信任的关系,通常系统无法直接给出十分精确的数值用来反映两个用户之间的信任程度,系统给出的往往是二元的,同时由于信任网络是十分稀疏的,所以需要对信任网络进行扩展,我们定义用户间的信任关系值度量公式如下:
式中,t(u,v)∈(0,1],d(u,v)是用户u和用户v之间的最短距离,可以宽度优先搜索算法进行搜索,两个用户之间的距离越短则说明两个用户之间的信任值越大,我们限制两个用户之间的最远距离为6,即d(u,v)≤6。
步骤1.2定义用户间的相似关系,提出一种基于用户评分偏好的相似度计算方法,其计算公式如下:
其中,
步骤1.3用户间的混合相似度计算,把用户间的信任关系和评分相似性融合在一起,扬长避短,得到一种新的计算用户间相似度的方法。下面用线性关系来融合这两种关系,如下所式:
sim(u,v)=β·trust(u,v)+(1-β)·simrat(u,v)(3)
式中,β是一个权重系数,用来衡量信任关系和评分相似性的权重,trust(u,v)表示信任矩阵t中用户u和用户v之间的信任关系,simrat(u,v)是步骤1.2中计算的用户间相似度,为了权衡信任相似关系,这里将β设置为0.5。
步骤2.基于混合相似度的用户社区挖掘
步骤2.1定义了用户间的专家评估方法,从可信度,权威性以及评分多样性三个指标出发,对用户成为专家的可能性进行评估。式(4),(5)和(6)分别用tu,au,du表示用户的可信度,权威性以及评分多样,综合这三个指标的均值来作为评估用户成为专家的可能性。
式中,du表示用户u的入度,dmax表示信任网络中入度的最大值。nu表示用户u评过分的物品数量。vu表示用户u的评分方差。
步骤2.2取专家值最大的k个用户作为初始的簇中心集合,用集合的形式表示为u={expert(u1),expert(u1),…expert(uk)},expert(uk)表示用户uk的专家值;聚类中心集合记为center={ce1,ce2,…cek},其中cek表示第k个聚类簇的聚类中心;并初始化k个聚类簇,记作c={c1,c2,…ck},其中ck表示第k个聚类簇。
步骤2.3对用户集合中的每个用户,利用公式(3)计算其与所有聚类中心的混合相似度,找到其中相似度最大的用户max(sim(u,cei)),将用户u加入聚类中心cei所在的聚类簇ci。
步骤2.4更新所有的聚类中心,计算每个聚类簇中用户混合相似度均值最大的用户作为新的聚类中心,计算每个簇中的用户与聚类中心的误差平方和
步骤3.用户-评分矩阵r通过联合聚类划分成若干个类别
步骤3.1初始化每个评分属于某个类别的概率p(k|ui,vj,r),满足
步骤3.2对评分矩阵中的每一个用户和项目,分别根据公式(7),(8)和(9)计算该用户和项目属于某个类别的概率以及某个类别中存在某个评分的概率。
式(7)中v(ui)表示用户ui评分过的项目集合,k′表示某个聚类簇;式(8)中u(vj)表示对物品vj有过评分的用户集合,式(9)中r′表示不同的评分集合;
步骤3.3利用公式(10)计算第ω次迭代时用户ui对项目vj的评分rij属于第k个类别的概率,式中对每个概率加上α,β,γ是为了防止分母为0而设置的超参数。
步骤3.4令ω=ω+1,并判断ω≤ωmax是否成立,如果成立的话则返回步骤3.2继续执行,如果不满足则表示获得了评分属于某个类别的概率。
步骤3.5重复步骤3.2-3.4,直到所有的用户和项目以及评分都被划分到概率最大的类别中去。
步骤4面向评分矩阵的联合社区结构的矩阵分解算法,从而进行推荐
步骤4.1定义一个新的正则化项
根据用户与在同一个社区中的其他用户有更大的偏好相似性,结合用户社区的正则化公式如下:
式中,mw表示存在于第w个评分联合社区内的用户个数,α为调整聚类正则化程度的系数,iig为指示函数,g∈{1,2,3…k},k表示社区数量,iig的取值情况是,如果用户ui在社区g内时其值为1,否则为0;neg(i)表示与用户ui在同一社区中的邻居用户集合,ui为用户ui的偏好,uf表示用户ui邻居用户uf的偏好,其邻居用户的平均偏好记作
步骤4.2面向联合社区的矩阵分解
整个矩阵分解的公式如下:
式中,
步骤4.3矩阵分解的求解
通过随机梯度下降法不断迭代更新,来求得用户的隐特征矩阵
步骤4.4按照公式(15)获得预测评分,将满足要求的评分推荐给相应的用户。
式中,
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!