一种自动解析英文文本语法现象的方法与流程
本发明属于自然语言处理技术领域,具体涉及一种基于语法知识的语法现象解析,能够自动解析输入句子的关于词法和句法的语法现象。
背景技术:
英语作为全球应用最为普及的一门语言,引起了越来越多人的重视,国内对于英语的教育也愈加普及深化,但英语作为我们第二语言,相比较于母语学习,难免会增添难度,传统的老师教学也并不能完全保障,在我们需要适当的英语语法指导时给予及时的帮助,这时,学习者往往需要一个能够随时辅助他们学习英语文本语法的学习工具。
目前,现有的自然语言处理领域相关的研究,大部分都是针对语言学和教育学上的理论研究,而对于软件应用方面涉及较少。而理论研究的相关成果,又具有特定领域的标记,没有专业知识的人很难理解相关结果,所以,理论研究成果并不能很好的直接适用于英语教育。
自然语言处理领域中,现有的相关理论研究能够对自然语言句子中的单词进行词性标注、引用解析、命名实体识别、依存句法分析以及句子情感分析等等。对自然语言中的句子进行语法分析,虽然涉及到词性标注和依存关系分析,但其中得到的词性标注类别仅有36种,如:jj表示形容词,cc表示连词,dt表示限定词等,词性标注的类别较宽泛,不能很好的得到单词相关语法现象,同理,依存句法分析类别有49种,如det(x,y):determiner表示x是名词短语,y是其限定词,两者的依赖关系为限定关系,也不能很好的映射出句子的相关语法现象。
现有技术缺少将已有的自然语言处理的相关理论成果进行再处理,直接能够得到常见的语法现象的技术,而且,仅从目前得到的理论成果,不能直接明了的得到所需要的语法现象,仅有较宽泛的单词词性标注和依存句法分析,结果较笼统,不能与平常见到的英语语法相统一起来。因此,自动对英文文本进行语法现象的解析,具有很强的现实意义。
技术实现要素:
鉴于上述情况,本发明提出一种英文文本自动解析语法现象的方法,用于对输入的自然语言进行词法和句法两方面的语法分析。根据本发明的语法解析方法,能够结合词性标注、依存句法关系以及正则表达式,实现将输入句子自动解析语法现象,结果映射到我们自己总结归纳的常见的语法知识点组成的语法树上,将所有满足条件的语法现象都输出。
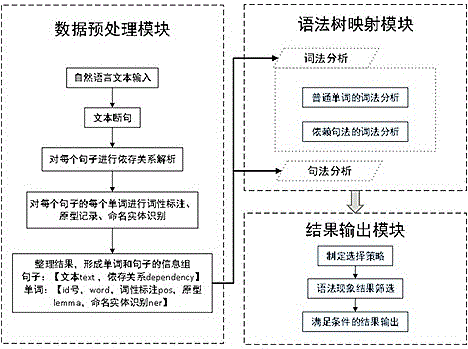
对于英文文本的自动解析过程,包括数据预处理模块、语法树映射模块以及结果输出模块三大模块,具体技术路线如下所述:
(一)数据预处理模块,利用自然语言处理包,对自然语言文本进行句子分割、字符标记、词性标注、命名实体识别、单词原型解析以及句子依存关系分析等,具体处理流程如下:
a.得到英语文本断句之后的结果,存为列表sentences
b.遍历列表sentences,对每一个句子sentence先调用依存句法分析方法得到树形结构的分析结果,存为dependency,然后对句子中每个单词进行标记,记为token,得到每个token代表的单词形式word,word对应的单词原型lemma,词性标记结果pos,以及命名实体识别结果ner
c.由上述结果整理得到句子和单词的信息组,两者分别包含[文本text,依存关系dependency]和[id号,word,词性标注pos,原型lemma,命名实体识别ner],作为下一模块语法树映射模块的输入
(二)语法树映射模块,将预处理模块得到的结果进行再处理,利用词性标记结果和依存句法分析结果,结合正则表达式,实现所得结果映射到我们自己总结归纳的常见语法组成的语法树上,主要包括词法分析和句法分析
词法分析过程大致如下:
a.读入单词信息组[id号,word,词性标注pos,原型lemma,命名实体识别ner],以及句子信息组[文本text,依存关系dependency]
b.调用遍历我们自己归纳的复合名词词汇表,进行复合名词的识别,以及其主谓一致现象的识别
c.词性标注类别分组,将语法树中的词法类别(包括名词、数词、形容词、副词、常见限定词、代词、动词、介词、冠词、连词)与词性标注结果对应起来
d.每类词法类别下,利用句子的依赖关系进行判断,查看树结构形成的依赖关系记录中,该单词的父节点具有的词性,实现单词功用的解析
e.单词对应形态变化的语法,利用word和原型lemma的对比给出
f.单词词组固定搭配的识别,不涉及语法的,利用原型lemma的正则匹配实现
g.涉及语法的固定搭配的识别,利用词性标注pos和单词word或原型lemma实现
h.语法树词法现象中最后叶子节点细化到某个词的解析,先用单词原型lemma进行识别,然后利用词性标注pos锁定词性分支,最后根据上下文特征细化到最后一层匹配
句法分析过程大致如下:
a.读入句子信息组[文本text,依存关系dependency]
b.利用词性标注为vb.*(动词的各种变化形态)实现时态或非谓语形式的解析
c.利用文本内容进行正则表达式匹配,结合匹配单词的词性标注结果pos,识别不同句型的标志词或引导词,达到句子种类的判别
d.进而根据不同句型进行细化分析,主要利用每个单词之间的依赖关系和单词及词性的正则匹配,这里的正则匹配主要是(id)lemma和pos的结构组合
e.记录依赖关系,进行句子结构的分析,查看该句拥有的依赖关系,判断基本句型和句子语序下的语法现象
(三)结果输出模块主要将映射得到的语法现象,根据用户制定的选择策略输出,主要流程如下:
a.用户根据自己需要制定选择策略,策略的制定可以是语法树上的任意一个节点或者任意节点的组合要求
b.根据用户定义的选择策略,进行语法现象的筛选。遍历语法树映射后的所有语法现象,查看每一条语法现象是否包含用户选择的语法树中的节点组合中的节点,如果包含则是满足条件的语法现象,反之,该条语法现象不满足用户定义的选择策略
c.将上一步得到的结果整理输出,返回给用户
附图说明
图1是本发明方法的总体流程图;
图2是本发明实例词法分析过程的具体处理流程图;
图3是本发明实例句法分析过程的具体处理流程图。
具体实施方式
下面按照附图来说明本发明的实施例。
本发明的自动解析语法现象方法的具体实施方式分为三个模块,包括数据预处理模块、语法树映射模块以及结果输出模块三大模块(见图1)
其中,数据预处理模块利用自然语言处理包,对自然语言文本进行句子分割、字符标记、词性标注、命名实体识别、单词原型解析以及句子依存关系分析等;语法树映射模块将预处理模块得到的结果进行再处理,利用词性标记结果和依存句法分析结果,结合正则表达式,实现所得结果映射到我们自己总结归纳的常见语法组成的语法树上;结果输出模块主要将映射得到的语法现象,根据用户制定的选择策略输出,也可以全部输出。
模块一:数据预处理模块
采用任意的语法分析工具,对自然语言文本进行句子分割、字符标记、词性标注、命名实体识别、单词原型解析以及句子依存关系分析,以stanfordcorenlp语言分析工具为例,开始之后,读入待处理的英语文本,然后调用相应的函数分别得到相应的值,这一步具体流程如下:
a.得到英语文本断句之后的结果,存为列表sentences
b.遍历列表sentences,对每一个句子sentence先调用依存句法分析方法得到树形结构的分析结果,存为dependency,然后对句子中每个单词进行标记,记为token,得到每个token代表的单词形式word,word对应的单词原型lemma,词性标记结果pos,以及命名实体识别结果ner
c.由上述结果整理得到句子和单词的信息组,两者分别包含[文本text,依存关系dependency]和[id号,word,词性标注pos,原型lemma,命名实体识别ner],作为下一模块语法树映射模块的输入
注:以自然语言句子therearemanybeautifulflowers为例
句子的依存关系结构图如下图所示,为树形结构:
->are/vbp(root)
->there/ex(expl)
->flowers/nns(nsubj)
->many/jj(amod)
->beautiful/jj(amod)
->./.(punct)
单词的信息组形式以其中一个单词there为例:[0,there,ex,there,0]
2.2.2模块二:语法树映射模块
在现有技术分析的基础上,对输入句子应用上下文特征、句子级特征来实现语法树的映射过程,其中上下文特征用来进行固定搭配及固定结构的识别过程,而句子级特征用来识别固定句式的标志词、引导词,以及判断整体句子的语法结构,包括基本句型、句子组成成分、句子语序等识别过程。
语法树的映射过程主要分为两大部分,一部分为词法分析,另一部分为句法分析,但有些词法分析过程依赖于句法,所以,词法分析细化为普通单词的词法分析,以及依赖句法的词法分析。
词法分析过程如下(见图2):
a.读入单词信息组[id号,word,词性标注pos,原型lemma,命名实体识别ner],以及句子信息组[文本text,依存关系dependency]
b.调用遍历我们自己归纳的复合名词词汇表,进行复合名词的识别,以及其主谓一致现象的识别
c.词性标注类别分组,将语法树中的词法类别(包括名词、数词、形容词、副词、常见限定词、代词、动词、介词、冠词、连词)与词性标注结果对应起来,如名词对应词性标志组{“nn”,“nnp”,“nns”,“nnps”},其中,不需要进一步细化解析的词法类别,可以根据单词word或原型lemma以及词性标注pos直接映射到语法树上的词法语法现象,其它需要细化的词法类根据以下步骤进行进一步细化解析
d.每类词法类别下,利用句子的依赖关系进行判断,查看树结构形成的依赖关系记录中,该单词的父节点具有的词性,实现单词功用的解析,如:该单词词性标注pos是rb(表示副词),其对应父节点的词性标注为vb.*,即任何vb开头的词性标注结果,表示动词的各种变化形态,则该单词是副词功用->副词修饰动词,其他类别词性的功用判断同理
e.单词对应形态变化的语法,利用word和原型lemma的对比给出,如名词复数的变化规则,形容词或副词比较级、最高级的变化规则,动词过去式、过去分词、第三人称单数、现在分词的变化规则等等
f.单词词组固定搭配的识别,不涉及语法的,利用原型lemma的正则匹配实现,如修饰词alotof的识别
g.涉及语法的固定搭配的识别,利用词性标注pos和单词word或原型lemma实现,如表示整点的时刻表示法,采用(id)pos:cd+(id+1)word:o’clock识别,表示前一个词的词性标注结果为序数词,后一个词为o’clock;又比如形容词/副词原级肯定形式as+adj./adv.+as...固定语法词组的识别,采用(id)word:as+(id+1)pos:jj/rb+(id+2)word:as;又比如情态动词表一般情况推测的语法现象,采用(id)pos:md+(id+1)pos:vb
h.语法树词法现象中最后叶子节点细化到某个词的解析,先用单词原型lemma进行识别,然后利用词性标注pos锁定词性分支,最后根据上下文特征细化到最后一层匹配
句法分析过程如下(见图3):
a.读入句子信息组[文本text,依存关系dependency]
b.利用词性标注为vb.*(动词的各种变化形态)实现时态或非谓语形式的解析,如一般将来时的识别,采用(id)lemma:be+(id+1)pos:vbg+(id+2)word:to,而时态和非谓语形式的区分利用句子依存关系判定
c.利用文本内容进行正则表达式匹配,结合匹配单词的词性标注结果pos,识别不同句型的标志词或引导词,达到句子种类的判别,如文本正则匹配therebe判别therebe句型,文本正则匹配和词性标注辅助(id)word:what/how+(id+1)word:a+(id+2)pos:nn判别感叹句的一种句型,又比如,特殊疑问词词性加符号标识符问号,判别特殊疑问句等等
d.进而根据不同句型进行细化分析,主要利用每个单词之间的依赖关系和单词及词性的正则匹配,这里的正则匹配主要是(id)lemma和pos的结构组合,如祈使句的细化,(id)pos:vb+(id+1)pos:nn.*识别祈使句中一种do+sth.句型,(id)word:be+(id+1)pos:jj识别一种be+形容词句型,(id)word:let+(id+1)pos:prp+(id+2)pos:vb+(id+3)pos:nn.*识别一种letsb.dosth.句型;又比如,对特殊疑问词word的正则匹配,实现疑问词whatcolor或howold或其它疑问词的识别
e.记录依赖关系,进行句子结构的分析,查看该句拥有的依赖关系,判断基本句型和句子语序下的语法现象,如dobj(x,y)表示y是x的直接宾语,csubj(x,y)表示谓语动词(被动)及主语从句中的主要成分等等,通过句子拥有的句子成分,判断基本句型及句子语序
注:一条语法现象的输出形式为语法树的根节点一直到叶子节点的记录,为:句子->词法->->...->叶子节点,或句子->句法->->...->叶子节点,整个语法树映射后的结果为这样形式的语法现象的集合
2.2.3模块三:结果输出模块
结果输出模块主要用来整理上一模块语法树映射之后的结果,用户可以自己制定选择策略,根据自我需求进行语法现象的输出。主要流程如下:
a.用户根据自己需要制定选择策略,策略的制定可以是语法树上的任意一个节点或者任意节点的组合要求,更特殊的,可以选择一棵子树,即某一大类的输出,如:选择策略,词法中定义为形容词,句法中定义为基本句型和句子种类
b.根据用户定义的选择策略,进行语法现象的筛选。我们遍历语法树映射后的所有语法现象,查看每一条语法现象是否包含用户选择的语法树中的节点组合中的节点,如果包含则是满足条件的语法现象,反之,该条语法现象不满足用户定义的选择策略
c.将上一步得到的结果整理输出,返回给用户
注:因为同一文本,可能有很多用户需要得到其语法分析结果,但每个人需要得到的语法指导不同,比如:英语课本上的英文文本,所以每次会得到输入文本的所有语法现象,然后再根据不同用户自定义的选择策略,将语法现象筛选输出。
- 还没有人留言评论。精彩留言会获得点赞!