一种OCR系统中采用深度学习矫正发票图片分割结果的方法与流程
本发明涉及液晶电视技术领域,具体的说,是一种ocr系统中采用深度学习矫正发票图片分割结果的方法。
背景技术:
在做发票核算、票面信息录入等批量业务ocr时,往往都是一张发票粘贴在一张a4纸张上,而票面ocr仅仅关注票据的主体部分,非发票主体部分空白边缘会对ocr处理时的计算资源造成浪费。所以就需要首先对a4纸进行分割。自动分割发票技术虽已应用,但由于发票图片的一些特殊性,难以和背景底色准确区分,所以分割后仍需对分割后的结果进行坐标纠正,以满足ocr处理需求。由于人工矫正很难统一标准,且批量矫正的工作量大,造成业务处理效率低下。
技术实现要素:
本发明的目的在于提供一种ocr系统中采用深度学习矫正发票图片分割结果的方法,用于解决现有技术中做发票核算、票面信息录入等批量业务ocr时发票图片难以和背景底色准确区分,而人工矫正很难统一标准,且批量矫正的工作量大,造成业务处理效率低下的问题。
本发明通过下述技术方案解决上述问题:
一种ocr系统中采用深度学习矫正发票图片分割结果的方法,所述方法包括如下步骤:
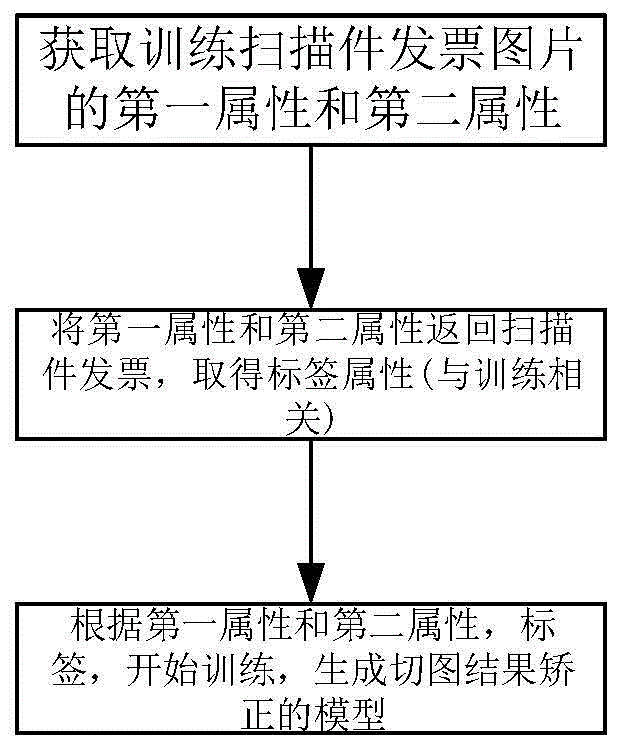
步骤1:获取训练图片,并提取其第一属性和第二属性进行训练,根据第一属性和第二属性返回训练图片取得正负样本标签,联合训练图片、第一属性和第二属性共同以生成矫正模型;
步骤2:搜集票据图片的第一属性和第二属性,联合扫描件发票图片提取训练的正样本图片,然后再提取截取的非发票的图片或被截取的残缺的发票图片标记为负样本,不记录其第二属性信息;
步骤3:构建矫正网络对步骤1和2所得的图片通过神经网络进行处理,运用常用的人脸检测常用数据集运用得出的模型进行迁移训练;
步骤4:对步骤3所得票据图片进行初步切图,并获取的第三属性和第四属性结合票据图片输入步骤1所得的矫正模型得到修正后的第三属性和第四属性,即得到最终的票据图片分割结果。
通过本方法,通过训练好的神经网络进行分割并且通过神经网络模型进行矫正,不用再人工进矫正或者审核,很好的解决了现有技术中做发票核算、票面信息录入等批量业务ocr时发票图片难以和背景底色准确区分,而人工矫正很难统一标准,且批量矫正的工作量大,造成业务处理效率低下的问题。
优选地,所述第一属性包括切出主体的中心点在原图中的坐标、切出主体的左上角点在原图中的坐标和右下角点在原图中的坐标;第二属性包括票据图片主体区域的宽度与高度;第三属性包括初步切图后的切出主体的中心点在原图中的坐标、切出主体的左上角点在原图中的坐标和右下角点在原图中的坐标;第四属性包括初步切图后票据图片主体区域的宽度与高度。
优选地,所述步骤2中正负样本的比例为10:1。
优选地,所述步骤3中的迁移训练包括如下步骤:
步骤3.1:使用已经标注好的人脸定位识别常用数据集widerface获取正样本数据,从人脸定位识别常用数据集celeba分别提取正样本和负样本数据,同时获得图片的第一属性和第二属性;
步骤3.2:将上述步骤2中准备好的数据,在已有的人脸定位矫正网络模型权重的基础上,进行迁移学习训练。
本发明与现有技术相比,具有以下优点及有益效果:
(1)本发明通过训练好的神经网络进行分割并且通过神经网络模型进行矫正,不用再人工进矫正或者审核,很好的解决了现有技术中做发票核算、票面信息录入等批量业务ocr时发票图片难以和背景底色准确区分,而人工矫正很难统一标准,且批量矫正的工作量大,造成业务处理效率低下的问题。
(2)本发明使用神经网络进行图片分割和矫正,减轻工作人员工作量提升工作效率的同时,还大大提升了矫正的稳定性和准确率。
附图说明
图1为根据本发明一个实施例用于扫描件发票图片分割结果矫正模型生成流程图;
图2为一个实施例的用于扫描件发票图片分割结果矫正的模型的结构;
具体实施方式
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例1:
一种ocr系统中采用深度学习矫正发票图片分割结果的方法,所述方法包括如下步骤:
步骤1:获取训练图片,并提取其第一属性和第二属性进行训练,根据第一属性和第二属性返回训练图片取得正负样本标签,联合训练图片、第一属性和第二属性共同以生成矫正模型;
步骤2:搜集票据图片的第一属性和第二属性,联合扫描件发票图片提取训练的正样本图片,然后再提取截取的非发票的图片或被截取的残缺的发票图片标记为负样本,不记录其第二属性信息;
步骤3:构建矫正网络对步骤1和2所得的图片通过神经网络进行处理,运用常用的人脸检测常用数据集运用得出的模型进行迁移训练;
步骤4:对步骤3所得票据图片进行初步切图,并获取的第三属性和第四属性结合票据图片输入步骤1所得的矫正模型得到修正后的第三属性和第四属性,即得到最终的票据图片分割结果。
优选地,所述第一属性包括切出主体的中心点在原图中的坐标、切出主体的左上角点在原图中的坐标和右下角点在原图中的坐标;第二属性包括票据图片主体区域的宽度与高度;第三属性包括初步切图后的切出主体的中心点在原图中的坐标、切出主体的左上角点在原图中的坐标和右下角点在原图中的坐标;第四属性包括初步切图后票据图片主体区域的宽度与高度。
优选地,所述步骤2中正负样本的比例为10:1。
优选地,所述步骤3中的迁移训练包括如下步骤:
步骤3.1:使用已经标注好的人脸定位识别常用数据集widerface获取正样本数据,从人脸定位识别常用数据集celeba分别提取正样本和负样本数据,同时获得图片的第一属性和第二属性;
步骤3.2:将上述步骤2中准备好的数据结合步骤3.1所得,在已有的人脸定位矫正网络模型权重的基础上,进行迁移学习训练。
如上所述的方法,结合附图,一种ocr系统中采用深度学习矫正发票图片分割结果的方法,包括如下步骤:
步骤1:如图1所示,获取第一属性,和第二属性。第一属性包括切出主体的中心点在原图中的坐标(c_x,,c_y)、切出主体的左上角点在原图中的坐标(x_left,y_top),右下角点在原图中的坐标(x_right,y_bottom)等,第二属性包括发票图片主体区区域的宽度w与高度h。
举例而言,具体办法如采用已有的手段,通过付费方式,将贴有发票的a4纸扫描件发票图片的关键信息打马赛克后统一上传至众包平台amazonmechanicalturk,设定好发票主体区面积需占据的切后图片面积的占比,不超过此阈值的分割均为合格,一般返回xml文件,xml文件内包含分割区左上角的坐标点(x_left,y_left),发票主体区宽w和高度h,中心点坐标即可经简单计算得出为(x_left+1/2*w,y_top+1/2*h)
步骤2:搜集发票图片的第一属性和第二属性,联合扫描件发票图片通过第一提取模块提取训练的正样本图片,此类图片边缘合适,且均为正样本发票图片,然后再使用第一提取模块提取截取的非发票的图片或被截取的残缺的发票图片,这些标记为负样本,不记录其第二属性信息。
举例而言,上述得出的含有左上角点坐标和主体区宽和高的xml使用opencv等现有的工具包,在原图裁切,得到正样本发票的图片,负样本发票图片的定义这里规定为:1、从扫描件原件图片的左顶点开始,随机截取出来的图片;2、非发票图片。一般地,正负样本比例设置为10:1。
步骤3:构建矫正网络,构建矫正网络对步骤1和2所得的图片通过神经网络进行处理,运用常用的人脸检测常用数据集运用得出的模型进行迁移训练。具体的网络的输入为输入裁切返回后的图片,等比例缩放至24*24大小,经过卷积-maxpooling操作等,首先输出至全连接层,再经过两个同级的全连接层,分别概率输出与坐标值和与主体区有关的宽高等输出,运用常用的人脸检测常用数据集运用得出的模型,迁移训练。
迁移学习是经过验证的有效提升训练效率和在小数据集上获得良好性能的方法。由于含有发票主体的图片资源有限,且没有开源的国内发票图片数据库供使用。网络上进行人脸定位识别的数据集有很多,获取起来较容易,且均已标注完毕,有相关的数据集,这里采用相同的矫正网络,使用人脸数据库和已标注完成的含有坐标和宽高等信息的xml文件,开始训练。迭代训练次数具体举例而言,如可设定为100万次。
一般情况,迁移学习可考虑使用已经标注好的人脸定位识别常用数据集widerface获取正样本数据,可以考虑从人脸定位识别常用数据集celeba分别提取正样本和负样本数据,同时获得图片的第一属性和第二属性。将上述步骤2中准备好的标定数据,在已有的人脸定位矫正网络模型权重的基础上,进行迁移学习训练。另外,如果判断模型的损失值不再变化,且准确度超过预设阈值,则直接使用该模型作为矫正模型使用。
最后,将得到的第三属性和第四属性等随分割完成后的发票主体图片一起送入训练好的矫正网络后,返回修正后的第三属性和第四属性,即得到最后的分割结果。分割完成后,和得到的坐标和宽高等信息随原图一起送入训练好的矫正网络后,返回新的坐标点(x_,y_)和宽w_高h_,返回原图,需满足要求:x_-w_/2>0,y_-h_/2>0,x_+w_/2<原图的宽,y_+h_/2<原图的高,确认为矫正完成,可将切好的图片送入后续业务进行ocr。
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 还没有人留言评论。精彩留言会获得点赞!