模型训练方法、装置及系统与流程
本公开通常涉及机器学习领域,尤其涉及用于使用水平切分的训练集来经由多个训练参与方协同训练线性/逻辑回归模型的方法、装置及系统。
背景技术:
线性回归模型和逻辑回归模型是机器学习领域广泛使用的回归/分类模型。在很多情况下,多个模型训练参与方(例如,电子商务公司、快递公司和银行)各自拥有训练线性/逻辑回归模型所使用的特征样本的不同部分数据。该多个模型训练参与方通常想共同使用彼此的数据来统一训练线性/逻辑回归模型,但又不想把各自的数据提供给其它各个模型训练参与方以防止自己的数据被泄露。
面对这种情况,提出了能够保护数据安全的机器学习方法,其能够在保证多个模型训练参与方的各自数据安全的情况下,协同该多个模型训练参与方来训练线性/逻辑回归模型,以供该多个模型训练参与方使用。然而,现有的能够保护数据安全的机器学习方法的模型训练效率较低。
技术实现要素:
鉴于上述问题,本公开提供了一种用于经由多个训练参与方协同训练线性/逻辑回归模型的方法、装置及系统,其能够在保证多个训练参与方的各自数据安全的情况下提高模型训练的效率。
根据本公开的一个方面,提供了一种用于经由多个训练参与方来协同训练线性/逻辑回归模型的方法,所述线性/逻辑回归模型由第一数目个子模型组成,每个训练参与方具有一个子模型,所述第一数目等于所述训练参与方的数目,所述训练参与方包括训练发起方和至少一个训练协同方,所述方法由训练发起方执行,所述方法包括:执行下述迭代过程,直到满足预定条件:基于各个训练参与方的当前子模型以及所述训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得所述线性/逻辑回归模型针对所述特征样本集的当前预测值;确定所述特征样本集的当前预测值与对应的标记值之间的预测差值;基于所确定出的预测差值和所述特征样本集,确定模型更新量;将所确定出的模型更新量分割为所述第一数目个部分模型更新量,并且将第二数目个部分模型更新量中的每个分别发送给对应的训练协同方,所述第二数目等于所述第一数目减一;以及基于所述训练发起方的当前子模型以及对应的部分模型更新量来更新所述训练发起方的当前子模型,其中,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一迭代过程的当前子模型。
根据本公开的另一方面,提供一种用于经由多个训练参与方来协同训练线性/逻辑回归模型的方法,所述线性/逻辑回归模型由第一数目个子模型组成,每个训练参与方具有一个子模型,所述第一数目等于所述训练参与方的数目,所述训练参与方包括训练发起方和至少一个训练协同方,所述方法由训练协同方执行,所述方法包括:执行下述迭代过程,直到满足预定条件:基于各个训练参与方的当前子模型以及所述训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得所述线性/逻辑回归模型针对所述特征样本集的当前预测值;从所述训练发起方接收对应的部分模型更新量,其中,所述部分模型更新量是在所述训练发起方处对模型更新量进行分割后得到的所述第一数目个部分模型更新量中的一个部分模型更新量,所述模型更新量是在所述训练发起方处基于所确定出的当前预测值和对应的标记值之间的预测差值以及所述特征样本集确定出的;以及基于所述训练协同方的当前子模型以及所接收的部分模型更新量来更新所述训练协同方的当前子模型,其中,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一训练迭代过程的当前子模型。
根据本公开的另一方面,提供一种用于经由多个训练参与方来协同训练线性/逻辑回归模型的方法,所述线性/逻辑回归模型由第一数目个子模型组成,每个训练参与方具有一个子模型,所述第一数目等于所述训练参与方的数目,所述训练参与方包括训练发起方和至少一个训练协同方,所述方法包括:执行下述迭代过程,直到满足预定条件:基于所述各个训练参与方的当前子模型以及所述训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得所述线性/逻辑回归模型针对所述特征样本集的当前预测值;在所述训练发起方处,确定所述特征样本集的当前预测值与对应的标记值之间的预测差值,基于所确定出的预测差值与所述特征样本集确定模型更新量,将所确定出的模型更新量分割为所述第一数目个部分模型更新量,并且将所述第二数目个部分模型更新量中的每个分别发送给所述各个训练协同方;以及在所述各个训练参与方处,基于该训练参与方的当前子模型以及所接收的部分模型更新量来更新该训练参与方处的当前子模型,其中,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一迭代过程的当前子模型。
根据本公开的另一方面,提供一种用于经由多个训练参与方来协同训练线性/逻辑回归模型的装置,所述线性/逻辑回归模型由第一数目个子模型组成,每个训练参与方具有一个子模型,所述第一数目等于所述训练参与方的数目,所述训练参与方包括训练发起方和至少一个训练协同方,所述装置包括:预测值获取单元,被配置为基于各个训练参与方的当前子模型以及所述训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得所述线性/逻辑回归模型针对所述特征样本集的当前预测值;预测差值确定单元,被配置为确定所述特征样本集的当前预测值与对应的标记值之间的预测差值;模型更新量确定单元,被配置为基于所确定出的预测差值和所述特征样本集,确定模型更新量;模型更新量分割单元,被配置为将所确定出的模型更新量分割为所述第一数目个部分模型更新量;模型更新量发送单元,被配置为将第二数目个部分模型更新量中的每个分别发送给对应的训练协同方,所述第二数目等于所述第一数目减一;以及模型更新单元,被配置为基于所述训练发起方的当前子模型以及对应的部分模型更新量来更新所述训练发起方处的当前子模型,其中,所述预测值获取单元、所述预测差值确定单元、所述模型更新量确定单元、所述模型更新量分割单元、所述模型更新量发送单元以及所述模型更新单元被配置为循环执行操作,直到满足预定条件,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一迭代过程的当前子模型。
根据本公开的另一方面,提供一种用于经由多个训练参与方来协同训练线性/逻辑回归模型的装置,所述线性/逻辑回归模型由第一数目个子模型组成,每个训练参与方具有一个子模型,所述第一数目等于所述训练参与方的数目,所述训练参与方包括训练发起方和至少一个训练协同方,所述装置包括:预测值获取单元,被配置为基于各个训练参与方的当前子模型以及所述训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得所述线性/逻辑回归模型针对所述特征样本集的当前预测值;模型更新量接收单元,被配置为从所述训练发起方接收对应的部分模型更新量,其中,所述部分模型更新量是在所述训练发起方处对模型更新量进行分割后得到的所述第一数目个部分模型更新量中的一个部分模型更新量,所述模型更新量是在所述训练发起方处基于所确定出的当前预测值和对应的标记值之间的预测差值以及所述特征样本集确定出的;以及模型更新单元,被配置为基于所述训练协同方的当前子模型以及所接收的部分模型更新量来更新所述训练协同方的当前子模型,其中,所述预测值获取单元、所述模型更新量接收单元以及所述模型更新单元被配置为循环执行操作,直到满足预定条件,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一训练迭代过程的当前子模型。
根据本公开的另一方面,提供一种用于经由多个训练参与方来协同训练线性/逻辑回归模型的系统,所述线性/逻辑回归模型由第一数目个子模型组成,每个训练参与方具有一个子模型,所述第一数目等于所述训练参与方的数目,所述训练参与方包括训练发起方和至少一个训练协同方,所述系统包括:可信初始化方设备,被配置为生成所述第一数目个随机权重向量、所述第一数目个随机特征矩阵和所述第一数目个随机标记值向量,其中,所述第一数目个随机权重向量之和与所述第一数目个随机特征矩阵之和相乘所得的乘积等于所述第一数目个随机标记值向量之和;训练发起方设备,包括如上所述的用于在训练发起方侧执行训练的装置;以及至少一个训练协同方设备,每个训练协同方设备包括如上所述的用于在训练协同方侧执行训练的装置。
根据本公开的另一方面,提供一种计算设备,包括:至少一个处理器,以及与所述至少一个处理器耦合的存储器,所述存储器存储指令,当所述指令被所述至少一个处理器执行时,使得所述至少一个处理器执行如上所述的在训练发起方侧执行的训练方法。
根据本公开的另一方面,提供一种非暂时性机器可读存储介质,其存储有可执行指令,所述指令当被执行时使得所述至少一个处理器执行如上所述的在训练发起方侧执行的训练方法。
根据本公开的另一方面,提供一种计算设备,包括:至少一个处理器,以及与所述至少一个处理器耦合的存储器,所述存储器存储指令,当所述指令被所述至少一个处理器执行时,使得所述至少一个处理器执行如上所述的在训练协同方侧执行的训练方法。
根据本公开的另一方面,提供一种非暂时性机器可读存储介质,其存储有可执行指令,所述指令当被执行时使得所述至少一个处理器执行如上所述的在训练协同方侧执行的训练方法。
本公开的实施例的方案利用有可信初始化方的秘密共享矩阵乘法来经由多个训练参与方协同训练线性/逻辑回归模型,其能够在不泄漏该多个训练参与方的秘密数据的情况下训练得到线性/逻辑回归模型的模型参数,并且模型训练的工作量仅与训练所使用的特征样本的数量成线性关系,而不是指数关系,因此,与现有技术相比,本公开的实施例的方案能够实现在保证多个训练参与方的各自数据安全的情况下提高模型训练的效率。
附图说明
通过参照下面的附图,可以实现对于本公开内容的本质和优点的进一步理解。在附图中,类似组件或特征可以具有相同的附图标记。
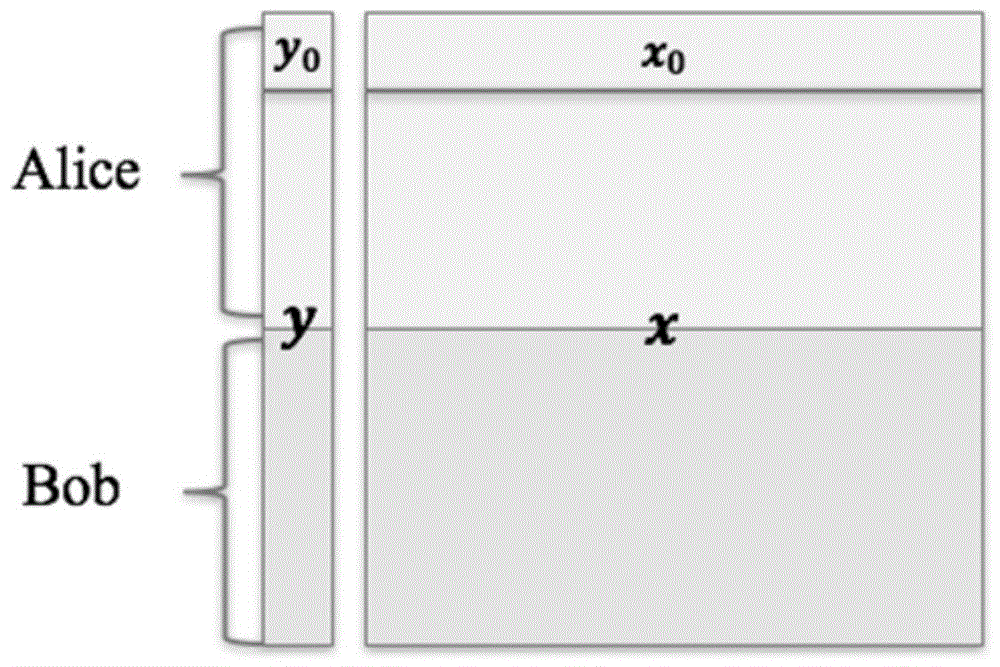
图1示出了根据本公开的实施例的经过水平切分的数据的示例的示意图;
图2示出了示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的系统的架构示意图;
图3示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的方法的总体流程图;
图4示出了图3中的有可信初始化方的秘密共享矩阵乘法过程的一个示例的流程图;
图5示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的装置的方框图;
图6示出了图5中的预测值获取单元的一个实现示例的方框图;
图7示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的装置的方框图;
图8示出了图7中的预测值获取单元的一个实现示例的方框图;
图9示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的计算设备的示意图;
图10示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的计算设备的示意图。
具体实施方式
现在将参考示例实施方式讨论本文描述的主题。应该理解,讨论这些实施方式只是为了使得本领域技术人员能够更好地理解从而实现本文描述的主题,并非是对权利要求书中所阐述的保护范围、适用性或者示例的限制。可以在不脱离本公开内容的保护范围的情况下,对所讨论的元素的功能和排列进行改变。各个示例可以根据需要,省略、替代或者添加各种过程或组件。例如,所描述的方法可以按照与所描述的顺序不同的顺序来执行,以及各个步骤可以被添加、省略或者组合。另外,相对一些示例所描述的特征在其它例子中也可以进行组合。
如本文中使用的,术语“包括”及其变型表示开放的术语,含义是“包括但不限于”。术语“基于”表示“至少部分地基于”。术语“一个实施例”和“一实施例”表示“至少一个实施例”。术语“另一个实施例”表示“至少一个其他实施例”。术语“第一”、“第二”等可以指代不同的或相同的对象。下面可以包括其他的定义,无论是明确的还是隐含的。除非上下文中明确地指明,否则一个术语的定义在整个说明书中是一致的。
秘密共享方法是一种将秘密分割存储的密码技术,其将秘密以适当的方式拆分成多个秘密份额,每一个秘密份额由多个参与方中的一个参与方拥有和管理,单个参与方无法恢复完整秘密,只有若干个参与方共同协作才能恢复完整秘密。秘密共享方法目标在于阻止秘密过于集中,以达到分散风险和容忍入侵的目的。
秘密共享方法可大致分为两类:有可信初始化方(trustinitializier)秘密共享方法以及无可信初始化方秘密共享方法。在有可信初始化方的秘密共享方法中,需要该可信初始化方对参与多方安全计算的各个参与方进行参数初始化(往往是产生满足一定条件的随机数)。在初始化完成后,可信初始化方将数据销毁,同时也消失,在接下来的多方安全计算过程中不再需要。
有可信初始化方的秘密共享矩阵乘法适用于下述情形:完整秘密数据是第一秘密份额集与第二秘密份额集的乘积,并且各个参与方各自拥有第一秘密份额集中的一个第一秘密份额以及第二秘密份额集中的一个第二秘密份额。通过有可信初始化方的秘密共享矩阵乘法,多个参与方中的每个参与方可以得到完整秘密数据的部分完整秘密数据并且各个参与方所得到的部分完整秘密数据之和是完整秘密数据,并且各个参与方将所得到的部分完整秘密数据公开给其余参与方,从而使得各个参与方能够在不需要公开各自所拥有的秘密份额的情况下得到完整秘密数据,由此保证了该多个参与方各自数据的安全。
在本公开中,线性/逻辑回归模型训练方案中所使用的训练样本集是经过水平切分的训练样本集。术语“对训练样本集进行水平切分”是指按照某个字段的某种规则来将该训练样本集中的训练样本切分为多个训练样本子集中,各个训练样本子集包含一部分训练样本,并且每个训练样本子集中所包括的训练样本是完整的训练样本,即,包括该训练样本的所有字段数据和对应的标记值。在本公开中,假设存在三个数据方alice、bob和charlie,则在各个数据方处获取本地样本以形成本地样本集,在该本地样本集中所包含的每条样本都是完整的样本,然后,三个数据方alice、bob和charlie所获取的本地样本集组成用于线性/逻辑回归模型训练的训练样本集,其中,每个本地样本集作为该训练样本集的训练样本子集,以用于训练线性/逻辑回归模型。
假设给定由d个属性(也称为特征)描述的属性值样本示例xt=(x1;x2;…;xd),其中,xi是x在第i个属性上的取值和t表示转置,那么线性回归模型为y=wx,逻辑回归模型为y=1/(1+e-wx),其中,y是预测值,以及,w是线性/逻辑回归模型的模型参数(即,本公开中所述的模型),
在本公开中,各个训练参与方各自拥有训练线性/逻辑回归模型所使用的训练样本的不同部分数据。例如,以两个训练参与方为例,假设训练样本集包括100个训练样本,每一个训练样本包含多个特征值和标记实际值,那么,第一参与方拥有的数据可以是训练样本集内的前30个训练样本,以及,第二参与方拥有的数据可以是训练样本集内的后70个训练样本。
在本公开中的任何地方描述的矩阵乘法计算,需要根据情况来确定是否对参与矩阵乘法的两个或多个矩阵中的一个或多个对应的矩阵进行转置处理,以满足矩阵乘法规则,由此完成矩阵乘法计算。
下面将结合附图来详细描述根据本公开的用于经由多个训练参与方来协同训练线性/逻辑回归模型的方法、装置以及系统的实施例。
图1示出了根据本公开的实施例的经过水平切分的训练样本集的示例的示意图。图1中示出了2个数据方alice和bob,多个数据方也类似。每个数据方alice和bob拥有的训练样本子集中的每条训练样本是完整的,即,每条训练样本包括完整的特征数据(x)和标记数据(y)。比如,alice拥有完整的训练样本(x0,y0)。
图2示出了示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的系统1(下文中称为模型训练系统1)的架构示意图。
如图2所示,模型训练系统1包括可信初始化方设备10、训练发起方设备20以及至少一个训练协同方设备30。在图2中示出了2个训练协同方设备30。在本公开的其它实施例中,可以包括一个训练协同方设备30或者包括多于2个的训练协同方设备30。可信初始化方设备10、训练发起方设备20以及至少一个训练协同方设备30可以通过例如但不局限于互联网或局域网等的网络40相互通信。在本公开中,训练发起方设备20以及至少一个训练协同方设备30统称为训练参与方设备。
在本公开中,所训练的线性/逻辑回归模型被分割为第一数目个子模型。这里,第一数目等于参与模型训练的训练参与方设备的数目。这里,假设训练参与方设备的数目为n。相应地,线性/逻辑回归模型被分割为n个子模型,每个训练参与方设备具有一个子模型。用于模型训练的训练样本集位于训练发起方设备20处,所述训练样本集是如上所述的经过水平划分后的训练样本集,并且训练样本集包括特征数据集以及对应的标记值,即,图1中示出的x0和y0。每一个训练参与方所拥有的子模型以及对应的训练样本是该训练参与方的秘密,不能被其他训练参与方获悉或者完整地获悉。
在本公开中,线性/逻辑回归模型和各个训练参与方的子模型分别使用权重向量w和权重子向量wi来表示,其中,i用于表示训练参与方的序号。特征数据集使用特征矩阵x来表示,以及预测值和标记值分别使用预测值向量~y和标记值向量y来表示。
在进行模型训练时,可信初始化方设备10被配置为生成n个随机权重向量wr,i、n个随机特征矩阵xr,i和n个随机标记值向量yr,i,其中,
然后,训练发起方设备20和至少一个训练协同方设备30一起使用训练发起方设备20处的训练样本集、各自的子模型以及从可信初始化方接收的各自的随机权重向量、随机特征矩阵和随机标记值向量来进行秘密共享矩阵乘法,以得到针对训练样本集的预测值,从而来协同训练线性/逻辑回归模型。关于模型的具体训练过程将在下面参照图3和图4进行详细描述。
在本公开中,可信初始化方设备10、训练发起方设备20以及训练协同方设备30可以是任何合适的具有计算能力的计算设备。所述计算设备包括但不限于:个人计算机、服务器计算机、工作站、桌面型计算机、膝上型计算机、笔记本计算机、移动计算设备、智能电话、平板计算机、蜂窝电话、个人数字助理(pda)、手持装置、消息收发设备、可佩戴计算设备、消费电子设备等等。
图3示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的方法的总体流程图。在图3中,以一个训练发起方alice和2个训练协同方bob和charlie为例来进行说明。
如图3所示,首先,在块310,训练发起方alice、训练协同方bob和charlie初始化其子模型的子模型参数,即,权重子向量wa、wb和wc,以获得其子模型参数的初始值,并且将已执行训练迭代次数t初始化为零。这里,假设迭代过程的结束条件为执行预定次数训练迭代,例如,执行t次训练迭代。
在如上初始化后,在块320,基于各个训练参与方的当前子模型wa、wb和wc以及训练发起方alice的特征样本集x,使用有可信初始化方的秘密共享矩阵乘法来获得待训练的线性/逻辑回归模型针对特征样本集x的当前预测值
在得到当前预测值
然后,在块340,基于所确定出的预测差值e以及特征样本集x,确定模型更新量。在本公开的一个示例中,可以通过计算预测差值e以及特征样本集x的乘积来确定出模型更新量tmp=x*e。
接着,在块350,将所确定出的模型更新量tmp分割为第一数目个部分模型更新量。该第一数目个部分模型更新量中的每个部分模型更新量包括模型更新量中的各个元素的部分元素值,并且,对于每个元素,该第一数目个部分模型更新量之和等于模型更新量。例如,将所确定出的模型更新量tmp分割为3个部分模型更新量tmpa、tmpb和tmpc。比如,对于tmp中的每个元素tmpi,将其分割为3个部分tmpi,a、tmpi,b和tmpi,c,并且tmpi=tmpi,a+tmpi,b+tmpi,c。
接着,在块360,将第二数目个部分模型更新量中的每个分别发送给各个训练协同方,例如,将部分模型更新量tmpi,b发送给训练协同方bob,以及将部分模型更新量tmpi,c发送给训练协同方charlie,同时训练发起方alice保留部分模型更新量tmpi,a。
然后,在块370,在各个训练参与方处,基于该训练参与方的当前子模型以及对应的部分模型更新量来更新该训练参与方处的当前子模型。例如,训练发起方alice使用当前子模型wa以及对应的部分模型更新量tmpi,a来更新训练发起方alice处的当前子模型,训练协同方bob使用当前子模型wb以及对应的部分模型更新量tmpi,b来更新训练协同方bob处的当前子模型,以及训练协同方charlie使用当前子模型wc以及对应的部分模型更新量tmpi,c来更新训练协同方charlie处的当前子模型。
在本公开的一个示例中,基于训练参与方的当前子模型以及对应的部分模型更新量来更新该训练参与方处的当前子模型可以按照以下等式更新训练参与方处的当前子模型:wn+1=wn-α·tmpi,其中,wn+1表示该训练参与方处的更新后的当前子模型,wn表示该训练参与方处的当前子模型,α表示学习率,以及tmpi表示与该训练参与方对应的部分模型更新量。
在如上在各个训练参与方完成各自的子模型更新后,在块380,判断是否达到预定迭代次数,即,判断是否达到预定条件。如果达到预定迭代次数,则各个训练参与方将各自的子模型参数的当前更新值,存储为其子模型参数的最终值,从而得到各自的训练后的子模型,然后流程结束。如果未达到预定迭代次数,则流程返回到块320的操作来执行下一训练迭代过程,其中,在该下次训练迭代过程中,各个训练参与方在当前迭代过程所获得的更新后的当前子模型被用作下一迭代过程的当前子模型。
这里要说明的是,在上述的示例中,训练迭代过程的结束条件是指达到预定迭代次数。在本公开的其它示例中,训练迭代过程的结束条件也可以是所确定出的预测差值位于预定范围内,即,预测差值e中的每个元素ei都位于预定范围内,例如,预测差值e中的每个元素ei都小于预定阈值。相应地,图3中的块380的操作可以在块320的操作之后执行。
图4示出了图3中的有可信初始化方的秘密共享矩阵乘法过程的一个示例的流程图。在图4中,以一个训练发起方alice和2个训练协同方bob和charlie为例来进行说明。
如图4所示,首先,在可信初始化方处,生成第一数目个随机权重向量、第一数目个随机特征矩阵以及第一数目个随机标记值向量,并且第一数目个随机权重向量之和与第一数目个随机特征矩阵之和的乘积等于第一数目个随机标记值向量之和。这里,第一数目等于训练参与方的数目。
例如,如图4所示,可信初始化方生成3个随机权重向量wr,1、wr,2和wr,3,3个随机特征矩阵xr,1、xr,2和xr,3,以及3个随机标记值向量yr,1、yr,2和yr,3,其中,
然后,在块401,将所生成的wr,1、xr,1和yr,1发送给训练发起方alice,在块402,将所生成的wr,2、xr,2和yr,2发送给训练协同方bob,以及在块403,将所生成的wr,3、xr,3和yr,3发送给训练协同方charlie。
接着,在块404,在训练发起方alice处,将用于本次迭代训练的训练样本集中的特征样本集x(下文中称为特征矩阵x)分割成第一数目个特征样本子集(下文中称为特征子矩阵),例如,如图4中所示分割为3个特征子矩阵x1、x2和x3。
例如,假设将特征样本集x分割为2个特征样本子集,且特征样本集x包括两个特征样本s1和s2,特征样本s1和s2各自包括3个属性值,其中,s1=[a11,a21,a31]和s2=[a12,a22,a32],那么,在将特征样本集x分割成2个特征样本子集之后,第一特征样本子集包括特征子样本[a111,a211,a311]和特征子样本[a112,a212,a312],第二特征样本子集包括特征子样本[a121,a221,a321]和特征子样本[a122,a222,a322],其中,a111+a121=a11,a211+a221=a21,a311+a321=a31,a112+a122=a12,a212+a222=a22和a312+a322=a32。
然后,训练发起方alice将所分割出的第一数目个特征子矩阵中的第二数目个特征子矩阵中的每个分别发送给训练协同方,第二数目等于第一数目减一。例如,在块405和406,将2个特征子矩阵x2和x3分别发送给训练协同方bob和charlie。
然后,在各个训练参与方处,基于各个训练参与方的权重子向量、对应的特征子矩阵以及所接收的随机权重向量和随机特征矩阵,确定该训练参与方处的权重子向量差值e和特征子矩阵差值d。例如,在块407,在训练发起方alice处,确定出其权重子向量差值e1=wa-wr,1以及特征子矩阵差值d1=x1-xr,1。在块408,在训练协同方bob处,确定出其权重子向量差值e2=wb-wr,2以及特征子矩阵差值d2=x2-xr,2。在块409,在训练协同方charlie处,确定出其权重子向量差值e3=wc-wr,3以及特征子矩阵差值d3=x3-xr,3。
在各个训练参与方确定出各自的权重子向量差值ei和特征子矩阵差值di后,各个训练参与方将所确定出的各自的权重子向量差值ei和特征子矩阵差值di公开给剩余的训练参与方。例如,在块410和411,训练发起方alice将d1和e1分别发送给训练协同方bob和charlie。在块412和413,训练协同方bob将d2和e2分别发送给训练发起方alice和训练协同方charlie。在块414和415,训练协同方charlie将d3和e3分别发送给训练发起方alice和训练协同方bob。
然后,在块416,在各个训练参与方处,对所述各个训练参与方处的权重子向量差值和特征子矩阵差值进行求和,以得到权重子向量总差值e和特征子矩阵总差值d。例如,如图4中所示,d=d1+d2+d3,以及e=e1+e2+e3。
然后,在各个训练参与方处,基于所接收的随机权重向量wr,i、随机特征矩阵xr,i、随机标记值向量yr,i、权重子向量总差值e、特征子矩阵总差值d计算各自对应的预测值矩阵zi。
在本公开的一个示例中,在各个训练参与方处,可以对该训练参与方的随机标记值向量、权重子向量总差值与该训练参与方的随机特征矩阵之积以及特征子矩阵总差值与该训练参与方的随机向量矩阵之积进行求和,以得到对应的预测值向量(第一种计算方式)。或者,可以对该训练参与方的随机标记值向量、权重子向量总差值与该训练参与方的随机特征矩阵之积、特征子矩阵总差值与该训练参与方的随机权重向量之积以及权重子向量总差值与特征子矩阵总差值之积进行求和,以得到对应的预测值向量(第二种计算方式)。
这里要说明的是,在各个训练参与方处的预测值向量计算时,仅仅只有一个训练参与方处计算出的预测值向量中包含权重子向量总差值与特征子矩阵总差值之积。换言之,针对各个训练参与方,仅仅只有一个训练参与方的预测值向量是按照第二种计算方式计算出的,而其余的训练参与方按照第一种计算方式来计算出对应的预测值向量。
例如,在块417,在训练发起方alice处,计算出对应的预测值向量z1=yr,1+e*xr,1+d*wr,1+d*e。在块418,在训练协同方bob处,计算出对应的预测值向量z2=yr,2+e*xr,2+d*wr,2。在块419,在训练协同方charlie处,计算出对应的预测值向量z3=yr,3+e*xr,3+d*wr,3。
这里要说明的,在图4中示出的是在训练发起方alice处计算出的z1中包含d*e。在本公开的其它示例中,也可以在训练协同方bob和charlie中的任一方所计算出的zi中包含d*e,相应地,在训练发起方alice处计算出的z1中不包含d*e。换言之,在各个训练参与方处所计算出的zi中,仅仅只有一个包含d*e。
然后,各个训练参与方将所计算出的各自的预测值向量公开给其余训练参与方。例如,在块420和421,训练发起方alice将预测值向量z1分别发送给训练协同方bob和charlie。在块422和423,训练协同方bob将预测值向量z2分别发送给训练发起方alice和训练协同方charlie。在块424和425,训练协同方charlie将预测值向量z3分别发送给训练发起方alice和训练协同方bob。
然后,在块426,427和428,各个训练参与方对所述各个训练参与方的预测值向量进行求和z=z1+z2+z3,以得到线性/逻辑回归模型针对特征样本集的当前预测值。
这里要说明的是,在图4中示出的模型训练过程中,alice被作为训练发起方来发起当前模型迭代训练,即,使用alice处的训练数据来执行模型迭代训练。换言之,在图4中示出的模型训练过程中,数据方alice作为训练发起方,数据方bob和charlie作为训练协同方。在本公开的其它示例中,每次模型迭代训练中所使用的训练数据可以是训练参与方中的任一方中所具有的训练数据。例如,也可以使用数据方bob的训练数据来进行模型训练。在这种情况下,数据方bob作为训练发起方,数据方alice和charlie作为训练协同方。相应地,图3中所述的方法还可以包括:在每次迭代训练时,由训练参与方来协商确定哪个训练参与方作为训练发起方,即,协商确定使用哪个训练参与方中的训练数据来执行本次迭代训练。然后,各个训练参与方按照所确定出的训练角色来执行图4中示出的对应操作。
此外,要说明的是,图3和图4中示出的是1个训练发起方和2个训练协同方的模型训练方案,在本公开的其它示例中,也可以包括1个训练协同方或者包括多于2个训练协同方。
利用图3和图4中公开的线性/逻辑回归模型训练方法,能够在不泄漏该多个训练参与方的秘密数据的情况下训练得到线性/逻辑回归模型的模型参数,并且模型训练的工作量仅与训练所使用的特征样本的数量成线性关系,而不是指数关系,从而能够在保证多个训练参与方的各自数据安全的情况下提高模型训练的效率。
图5示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的装置(下文中称为模型训练装置)500的示意图。如图5所示,模型训练装置500包括预测值获取单元510、预测差值确定单元520、模型更新量确定单元530、模型更新量分割单元540、模型更新量发送单元550和模型更新单元560。
在进行训练时,预测值获取单元510、预测差值确定单元520、模型更新量确定单元530、模型更新量分割单元540、模型更新量发送单元550和模型更新单元560被配置为循环执行操作,直到满足预定条件。所述预定条件可以包括:达到预定迭代次数;或者所确定出的预测差值位于预定范围内。
具体地,在每次迭代过程中,预测值获取单元510被配置为基于各个训练参与方的当前子模型以及所述训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得所述线性/逻辑回归模型针对所述特征样本集的当前预测值。预测值获取单元510的操作可以参考上面参照图3描述的块320的操作以及图4中示出的训练发起方执行的操作。
预测差值确定单元520被配置为确定特征样本集的当前预测值与对应的标记值之间的预测差值。预测差值确定单元520的操作可以参考上面参照图3描述的块330的操作。
模型更新量确定单元530被配置为基于所确定出的预测差值和所述特征样本集,确定模型更新量。模型更新量确定单元530的操作可以参考上面参照图3描述的块340的操作。
模型更新量分割单元540被配置为将所确定出的模型更新量分割为所述第一数目个部分模型更新量。模型更新量分割单元540的操作可以参考上面参照图3描述的块350的操作。
模型更新量发送单元550为将第二数目个部分模型更新量中的每个分别发送给对应的训练协同方,所述第二数目等于所述第一数目减一。模型更新量发送单元550的操作可以参考上面参照图3描述的块360的操作。
模型更新单元560为基于所述训练发起方的当前子模型以及对应的部分模型更新量来更新所述训练发起方处的当前子模型,其中,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一迭代过程的当前子模型。模型更新单元560的操作可以参考上面参照图3描述的块370的操作。
图6示出了图5中的预测值获取单元的一个实现示例的方框图。如图6所示,预测值获取单元510包括随机矩阵接收模块511、特征样本分割模块512、特征样本发送模块513、差值确定模块514、差值发送/接收模块515、预测值向量确定模块516、预测值向量发送/接收模块517和求和模块518。在图6中示出的示例中,各个训练参与方的子模型使用权重子向量来表示,以及特征样本集、预测值和标记值分别使用特征矩阵、预测值向量和标记值向量来表示。
随机矩阵接收模块511被配置为从可信初始化方接收对应的随机权重向量、随机特征矩阵和随机标记值向量。所述对应的随机权重向量、随机特征矩阵和随机标记值向量分别是在可信初始化方处生成的第一数目个随机权重向量、第一数目个随机特征矩阵和第一数目个随机标记值向量中的随机权重向量、随机特征矩阵和随机标记值向量,其中,第一数目个随机权重向量之和与第一数目个随机特征矩阵之和相乘所得的乘积等于第一数目个随机标记值向量之和。随机矩阵接收模块511的操作可以参考上面参照图4描述的块401的操作。
特征样本分割模块512被配置为将特征矩阵分割为第一数目个特征子矩阵。特征样本发送模块513被配置为将第二数目个特征子矩阵中的每个分别发送给对应的训练协同方。随机矩阵接收模块512可以参考上面参照图4描述的块404的操作。特征样本发送模块513的操作可以参考上面参照图4描述的块405和406的操作。
差值确定模块514被配置为基于训练发起方的权重子向量、对应的特征子矩阵以及所接收的随机权重向量和随机特征矩阵,确定训练发起方处的权重子向量差值和特征子矩阵差值。差值确定模块514的操作可以参考上面参照图4描述的块407的操作。
差值发送/接收模块515被配置为将所确定出的权重子向量差值和特征子矩阵差值发送给各个训练协同方,以及从各个训练协同方接收对应的权重子向量差值和特征子矩阵差值。差值发送/接收模块514的操作可以参考上面参照图4描述的块410、411、412和415的操作。
预测值向量确定模块516被配置为基于各个训练参与方的权重子向量差值和特征子矩阵差值、所接收的随机权重向量、随机特征矩阵以及随机标记值向量,确定训练发起方处的预测值向量。预测值向量确定模块516的操作可以参考上面参照图4描述的块416和417的操作。
预测值向量发送/接收模块517被配置为将所确定出的预测值向量发送给各个训练协同方,以及从各个训练协同方接收对应的预测值向量。预测值向量发送/接收模块517的操作可以参考上面参照图4描述的块420、421、422和425的操作。
求和模块518被配置为对所得到的各个训练参与方的预测值向量进行求和,以得到线性/逻辑回归模型针对特征样本集的当前预测值。求和模块518的操作可以参考上面参照图4描述的块426的操作。
此外,在本公开的其它示例中,模型训练装置500还可以包括协商单元(未示出),被配置为在多个训练参与方之间协商确定出所述训练发起方和所述训练协同方。
图7示出了根据本公开的实施例的用于经由多个训练参与方来协同训练线性/逻辑回归模型的装置(下文中称为模型训练装置700)的方框图。如图7所示,模型训练装置700包括预测值获取单元710、模型更新量接收单元720和模型更新单元730。
在模型训练时,预测值获取单元710、模型更新量接收单元720以及模型更新单元730被配置为循环执行操作,直到满足预定条件。所述预定条件可以包括:达到预定迭代次数;或者所确定出的预测差值位于预定范围内。
具体地,在每次迭代过程中,预测值获取单元710被配置为基于各个训练参与方的当前子模型以及所述训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得线性/逻辑回归模型针对特征样本集的当前预测值。预测值获取单元710的操作可以参考上面参照图3描述的块320的操作以及图4中示出的任一训练协同方执行的操作。
模型更新量接收单元720被配置为从所述训练发起方接收对应的部分模型更新量,其中,所述部分模型更新量是在所述训练发起方处对模型更新量进行分割后得到的所述第一数目个部分模型更新量中的一个部分模型更新量,所述模型更新量是在所述训练发起方处基于所确定出的当前预测值和对应的标记值之间的预测差值以及所述特征样本集确定出的。模型更新量接收单元720的操作可以参考上面参照图3描述的块360的操作。
模型更新单元730被配置为基于训练协同方的当前子模型以及所接收的部分模型更新量来更新训练协同方的当前子模型,其中,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一训练迭代过程的当前子模型。模型更新单元730的操作可以参考上面参照图3描述的块370的操作。
图8示出了图7中的预测值获取单元的一个实现示例的方框图。如图8所示,预测值获取单元710包括矩阵接收模块711、差值确定模块712、差值发送/接收模块713、预测值向量确定模块714、预测值向量发送/接收模块715和求和模块716。在图8中示出的示例中,各个训练参与方的子模型使用权重子向量来表示,特征样本集、预测值和标记值分别使用特征矩阵、预测值向量和标记值向量来表示。
矩阵接收模块711被配置为从训练发起方接收对应的特征子矩阵,以及从可信初始方接收对应的随机权重向量、随机特征矩阵和随机标记值向量。所述对应的特征子矩阵是在训练发起方处对所述特征矩阵进行分割后得到的第一数目个特征子矩阵中的一个特征子矩阵。所述对应的随机权重向量、随机特征矩阵和随机标记值向量分别是在可信初始化方处生成的第一数目个随机权重向量、第一数目个随机特征矩阵和第一数目个随机标记值向量中的随机权重向量、随机特征矩阵和随机标记值向量,其中,第一数目个随机权重向量之和与第一数目个随机特征矩阵之和相乘所得的乘积等于第一数目个随机标记值向量之和。
差值确定模块712被配置为基于训练协同方的权重子向量、对应的特征子矩阵以及所接收的随机权重向量和随机特征矩阵,确定训练协同方处的权重子向量差值和特征子矩阵差值。差值确定模块712的操作可以参考上面参照图4描述的块408或409的操作。
差值发送/接收模块713被配置为将所确定出的权重子向量差值和特征子矩阵差值发送给训练发起方和其余训练协同方,以及从训练发起方和其余训练协同方接收对应的权重子向量差值和特征子矩阵差值。差值发送/接收模块713的操作可以参考上面参照图4描述的块410-415的操作。
预测值向量确定模块714被配置为基于各个训练参与方的权重子向量差值和特征子矩阵差值、所接收的随机权重向量、随机特征矩阵以及随机标记值向量,确定训练协同方的预测值向量。预测值向量确定模块714的操作可以参考上面参照图4描述的块416、418或419的操作。
预测值向量发送/接收模块715被配置为将所确定出的预测值向量发送给训练发起方和其余训练协同方,以及从训练发起方和所述其余训练协同方接收对应的预测值向量。预测值向量发送/接收模块715的操作可以参考上面参照图4描述的块420-425的操作。
求和模块716被配置为对所得到的各个训练参与方的预测值向量进行求和,以得到线性/逻辑回归模型针对特征样本集的当前预测值。求和模块716的操作可以参考上面参照图4描述的块427或428的操作。
如上参照图1到图8,对根据本公开的模型训练方法、装置及系统的实施例进行了描述。上面的模型训练装置可以采用硬件实现,也可以采用软件或者硬件和软件的组合来实现。
图9示出了根据本公开的实施例的用于实现经由多个训练参与方来协同训练线性/逻辑回归模型的计算设备900的硬件结构图。如图9所示,计算设备900可以包括至少一个处理器910、存储器920、内存930和通信接口940,并且至少一个处理器910、存储器920、内存930和通信接口940经由总线960连接在一起。至少一个处理器910执行在存储器920中存储或编码的至少一个计算机可读指令(即,上述以软件形式实现的元素)。
在一个实施例中,在存储器920中存储计算机可执行指令,其当执行时使得至少一个处理器910:执行下述迭代过程,直到满足预定条件:基于各个训练参与方的当前子模型以及训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得线性/逻辑回归模型针对特征样本集的当前预测值;确定特征样本集的当前预测值与对应的标记值之间的预测差值;基于所确定出的预测差值和特征样本集,确定模型更新量;将所确定出的模型更新量分割为第一数目个部分模型更新量,并且将第二数目个部分模型更新量中的每个分别发送给对应的训练协同方,第二数目等于第一数目减一;以及基于训练发起方的当前子模型以及对应的部分模型更新量来更新训练发起方的当前子模型,其中,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一迭代过程的当前子模型。
应该理解,在存储器920中存储的计算机可执行指令当执行时使得至少一个处理器910进行本公开的各个实施例中以上结合图1-8描述的各种操作和功能。
图10示出了根据本公开的实施例的用于实现经由多个训练参与方来协同训练线性/逻辑回归模型的计算设备1000的硬件结构图。如图10所示,计算设备1000可以包括至少一个处理器1010、存储器1020、内存1030和通信接口1040,并且至少一个处理器1010、存储器1020、内存1030和通信接口1040经由总线1060连接在一起。至少一个处理器1010执行在存储器1020中存储或编码的至少一个计算机可读指令(即,上述以软件形式实现的元素)。
在一个实施例中,在存储器1020中存储计算机可执行指令,其当执行时使得至少一个处理器1010:执行下述迭代过程,直到满足预定条件:基于各个训练参与方的当前子模型以及训练发起方的特征样本集,使用有可信初始化方的秘密共享矩阵乘法来获得线性/逻辑回归模型针对特征样本集的当前预测值;从训练发起方接收对应的部分模型更新量,其中,所述部分模型更新量是在训练发起方处对模型更新量进行分割后得到的第一数目个部分模型更新量中的一个部分模型更新量,所述模型更新量是在训练发起方处基于所确定出的当前预测值和对应的标记值之间的预测差值以及特征样本集确定出的;以及基于训练协同方的当前子模型以及所接收的部分模型更新量来更新训练协同方的当前子模型,其中,在迭代过程未结束时,所述更新后的各个训练参与方的当前子模型被用作下一训练迭代过程的当前子模型。
应该理解,在存储器1020中存储的计算机可执行指令当执行时使得至少一个处理器1010进行本公开的各个实施例中以上结合图1-8描述的各种操作和功能。
根据一个实施例,提供了一种比如非暂时性机器可读介质的程序产品。非暂时性机器可读介质可以具有指令(即,上述以软件形式实现的元素),该指令当被机器执行时,使得机器执行本公开的各个实施例中以上结合图1-8描述的各种操作和功能。具体地,可以提供配有可读存储介质的系统或者装置,在该可读存储介质上存储着实现上述实施例中任一实施例的功能的软件程序代码,且使该系统或者装置的计算机或处理器读出并执行存储在该可读存储介质中的指令。
根据一个实施例,提供了一种比如非暂时性机器可读介质的程序产品。非暂时性机器可读介质可以具有指令(即,上述以软件形式实现的元素),该指令当被机器执行时,使得机器执行本公开的各个实施例中以上结合图1-8描述的各种操作和功能。具体地,可以提供配有可读存储介质的系统或者装置,在该可读存储介质上存储着实现上述实施例中任一实施例的功能的软件程序代码,且使该系统或者装置的计算机或处理器读出并执行存储在该可读存储介质中的指令。
在这种情况下,从可读介质读取的程序代码本身可实现上述实施例中任何一项实施例的功能,因此机器可读代码和存储机器可读代码的可读存储介质构成了本发明的一部分。
可读存储介质的实施例包括软盘、硬盘、磁光盘、光盘(如cd-rom、cd-r、cd-rw、dvd-rom、dvd-ram、dvd-rw、dvd-rw)、磁带、非易失性存储卡和rom。可选择地,可以由通信网络从服务器计算机上或云上下载程序代码。
本领域技术人员应当理解,上面公开的各个实施例可以在不偏离发明实质的情况下做出各种变形和修改。因此,本发明的保护范围应当由所附的权利要求书来限定。
需要说明的是,上述各流程和各系统结构图中不是所有的步骤和单元都是必须的,可以根据实际的需要忽略某些步骤或单元。各步骤的执行顺序不是固定的,可以根据需要进行确定。上述各实施例中描述的装置结构可以是物理结构,也可以是逻辑结构,即,有些单元可能由同一物理实体实现,或者,有些单元可能分由多个物理实体实现,或者,可以由多个独立设备中的某些部件共同实现。
以上各实施例中,硬件单元或模块可以通过机械方式或电气方式实现。例如,一个硬件单元、模块或处理器可以包括永久性专用的电路或逻辑(如专门的处理器,fpga或asic)来完成相应操作。硬件单元或处理器还可以包括可编程逻辑或电路(如通用处理器或其它可编程处理器),可以由软件进行临时的设置以完成相应操作。具体的实现方式(机械方式、或专用的永久性电路、或者临时设置的电路)可以基于成本和时间上的考虑来确定。
上面结合附图阐述的具体实施方式描述了示例性实施例,但并不表示可以实现的或者落入权利要求书的保护范围的所有实施例。在整个本说明书中使用的术语“示例性”意味着“用作示例、实例或例示”,并不意味着比其它实施例“优选”或“具有优势”。出于提供对所描述技术的理解的目的,具体实施方式包括具体细节。然而,可以在没有这些具体细节的情况下实施这些技术。在一些实例中,为了避免对所描述的实施例的概念造成难以理解,公知的结构和装置以框图形式示出。
本公开内容的上述描述被提供来使得本领域任何普通技术人员能够实现或者使用本公开内容。对于本领域普通技术人员来说,对本公开内容进行的各种修改是显而易见的,并且,也可以在不脱离本公开内容的保护范围的情况下,将本文所定义的一般性原理应用于其它变型。因此,本公开内容并不限于本文所描述的示例和设计,而是与符合本文公开的原理和新颖性特征的最广范围相一致。
- 还没有人留言评论。精彩留言会获得点赞!