一种基于关键点区域特征融合的人脸识别方法及装置与流程
本发明实施例涉及计算机视觉处理技术领域,具体涉及一种基于关键点区域特征融合的人脸识别方法及装置。
背景技术:
计算机视觉是当前深度学习领域中最为火热的一个研究方向,特别是越来越多的计算机视觉技术已经落地应用,其中应用最广泛技术之一的就是人脸识别技术,人脸识别技术也是在生物特征识别领域里多种技术不断更新迭代竞争淘汰后存活下来的技术。目前人脸识别方法主要分为两类,一类是基于表象的方法,另一类是基于特征的方法。基于表象的方法的基本思想是将二维的人脸图像转换到另外一个空间,然后用统计方法分析人脸模式;而基于特征的方法是先提取人脸的局部或者全局特征,然后送入分类器进行人脸识别。传统的人脸识别方法对光照差异、面部表情、有无遮挡等多种不确定干扰存在敏感性,导致识别准确性大幅降低。
卷积神经网络是一个受生物视觉启发、以最简化预处理操作为目的的多层感知器的变形,本质是一个前向反馈神经网络,卷积神经网络与多层感知器的最大区别是网络前几层由卷积层和池化层交替级联组成,模拟视觉皮层中用于高层次特征提取的简单细胞和复杂细胞交替级联结构。卷积层的神经元对前一层输入的一部分区域有响应,提取输入的更高层次特征;池化层的神经元对前一层输入的一部分区域求平均值或最大值,抵抗输入的轻微形变或者位移。卷积神经网络的后几层一般是若干个全连接层和一个分类器构成的输出层。使用卷积神经网络进行人脸识别是一种基于特征的人脸识别方法,区别于传统的人工特征提取和针对特征的高性能分类器设计,它的优点是通过逐层卷积降维进行特征提取,然后经过多层非线性映射,使网络可以从未经特殊处理的训练样本中,自动学习形成适应该识别任务的特征提取器和分类器,该方法降低了对训练样本的要求,而且网络的层数越多,学习到的特征更具有全局性。而现有的基于卷积神经网络的人脸识别方法中存在对特征提取的不完整与不完善的问题,导致分类器分类能力不高,人脸识别准确性和鲁棒性不够。
技术实现要素:
为此,本发明实施例提供一种基于关键点区域特征融合的人脸识别方法及装置,以解决现有的人脸识别方法识别准确性低以及基于卷积神经网络的人脸识别方法对特征提取不完整、不完善,导致分类器分类能力不高,人脸识别准确性和鲁棒性不够的问题。
为了实现上述目的,本发明实施例提供如下技术方案:一种基于关键点区域特征融合的人脸识别方法,所述方法包括:
对训练集或测试集进行数据预处理;
构建卷积神经网络模型;
使用预处理后的训练集对所述卷积神经网络模型进行训练,提取出人脸关键点区域特征并进行融合;
使用预处理后的测试集对所述卷积神经网络模型进行测试。
优选的,所述对训练集或测试集进行数据预处理包括:
对所述训练集或测试集进行数据清洗;
对所述训练集或测试集中的人脸图片进行人脸检测,抠取出人脸图像;
将所述人脸图像进行人脸对齐处理。
优选的,所述人脸关键点区域包括左眼区域、右眼区域、鼻子区域以及嘴区域,所述人脸关键点包括左眼关键点、右眼关键点、鼻子关键点、左嘴角关键点以及右嘴角关键点。
优选的,所述左眼区域、右眼区域以及鼻子区域分别为以左眼关键点、右眼关键点以及鼻子关键点为中心点,取其周围边长为8的区域;所述嘴区域为以左嘴角关键点和右嘴角关键点的平均点为中心点,取其周围16×8的区域。
优选的,所述卷积神经网络模型采用基于resnet50扩展改进的深度神经网络模型。
优选的,所述卷积神经网络模型包括输入层、conv1卷积层、最大池化层、conv2卷积层、conv3卷积层、conv4卷积层、conv5卷积层、4个并列的conv6卷积层和均值池化层;
将预处理后的224×224人脸图像输入至所述卷积神经网络模型的输入层,经输入层输出至conv1卷积层,所述conv1卷积层的输入为3ch×224×224、输出为64ch×112×112、卷积核尺寸为7×7,然后经conv1卷积层输出至最大池化层,所述最大池化层的输出为64ch×56×56、卷积核尺寸为3×3,再经最大池化层输出至conv2卷积层,所述conv2卷积层包括由3个不同的卷积构成的3个相同的块,所述conv2卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为64ch×56×56、64ch×56×56、256ch×56×56,再经conv2卷积层输出至conv3卷积层,所述conv3卷积层包括由3个不同卷积构成的4个相同的块,所述conv3卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为128ch×28×28、128ch×28×28、512ch×28×28,再经conv3卷积层输出至conv4卷积层,所述conv4卷积层包括由3个不同卷积构成的6个相同的块,所述conv4卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为256ch×14×14、256ch×14×14、1024ch×14×14,再经conv4卷积层输出至conv5卷积层,所述conv5卷积层包括由3个不同卷积构成的3个相同的块,所述conv5卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为512ch×7×7、512ch×7×7、1024ch×7×7;
由conv3卷积层的中间特征表达上提取出相应人脸关键点区域的特征,所述conv3卷积层后接入4个并列的conv6卷积层,所述conv6卷积层的输入为512ch×28×28、输出为256ch×7×7,每个conv6卷积层对应提取一个人脸关键点区域的特征,将4个conv6卷积层的输出端相连进行融合输出为1024ch×7×7,最后通过均值池化层输出1024ch×1×1。
优选的,所述训练集采用ms-celeb-1m数据集。
优选的,所述测试集采用lfw数据集。
本发明实施例还提出了一种基于关键点区域特征融合的人脸识别装置,所述装置包括:
预处理模块,用于对训练集或测试集进行数据预处理;
网络建立模块,用于构建卷积神经网络模型;
训练模块,用于使用预处理后的训练集对所述卷积神经网络模型进行训练,提取出人脸关键点区域特征并进行融合;
测试模块,用于使用预处理后的测试集对所述卷积神经网络模型进行测试。
优选的,所述预处理模块包括:
数据清洗单元,用于对训练集或测试集进行数据清洗;
人脸检测单元,用于对训练集或测试集中的人脸图片进行人脸检测,并抠取出人脸图像;
人脸对齐单元,用于将所述人脸图像进行人脸对齐处理。
本发明实施例具有如下优点:
本发明实施例提出的一种基于关键点区域特征融合的人脸识别方法及装置,利用卷积神经网络对提取的人脸关键点区域的特征进行融合,克服了传统人脸识别方法对光照差异、面部表情、有无遮挡等多种不确定干扰的敏感性的缺点,降低了对训练集样本的要求,使得学习到的特征更具有全局性,识别模型更具有鲁棒性和准确性,综合考虑人脸的全局特征和不变性特征,保证了人脸识别模型不会因干扰因素而降低性能,相较于其他基于卷积神经网络的人脸识别方法,加强了不同特征之间的联系,使得提取的特征更加完善和完整,能够更加准确地描述人脸信息,具备得到全局最优分类的能力,提高了分类器的分类能力。
附图说明
为了更清楚地说明本发明的实施方式或现有技术中的技术方案,下面将对实施方式或现有技术描述中所需要使用的附图作简单地介绍。显而易见地,下面描述中的附图仅仅是示例性的,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图引伸获得其它的实施附图。
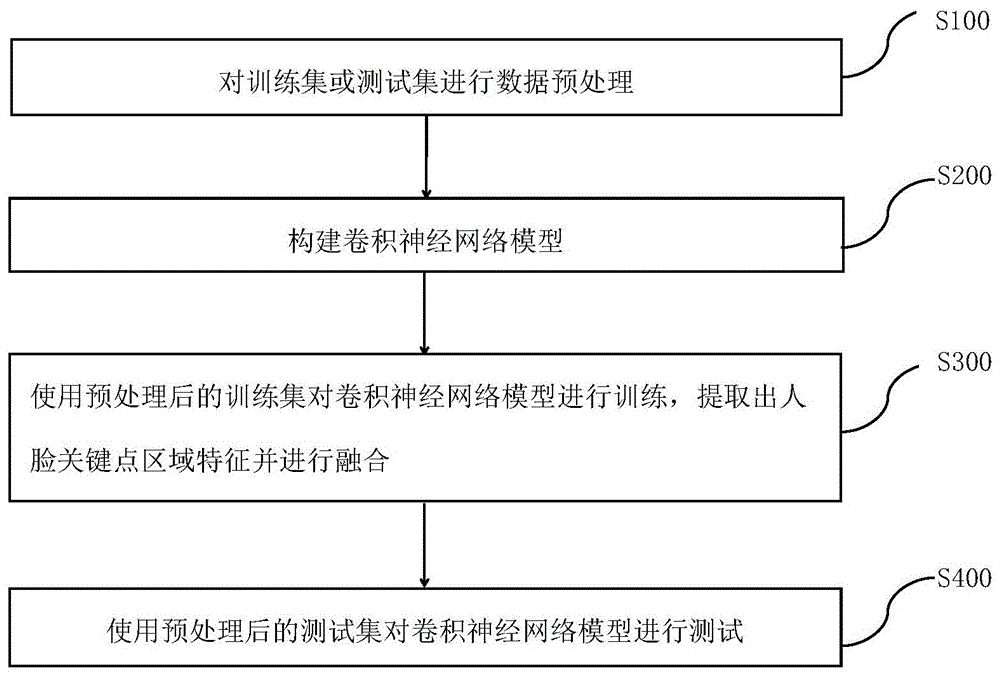
图1为本发明实施例1提供的一种基于关键点区域特征融合的人脸识别方法的流程示意图。
具体实施方式
以下由特定的具体实施例说明本发明的实施方式,熟悉此技术的人士可由本说明书所揭露的内容轻易地了解本发明的其他优点及功效,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
如图1所示,本发明实施例提出了一种基于关键点区域特征融合的人脸识别方法,该方法包括:
s100、对训练集或测试集进行数据预处理。本实施例中,训练集采用ms-celeb-1m数据集。
msrirc是目前世界上规模最大、水平最高的图像识别赛事之一,ms-celeb-1m就是这个比赛的公开数据集,从1m个名人中,根据他们的受欢迎程度,选择100k个人,然后利用搜索引擎,根据选择的100k个人,每人搜大概100张图片,共100k×100=10m个图片。训练集中包括1000个名人,这1000个名人来自于1m个明星中随机挑选,而且经过标注,每个名人大概有20张图片,这些图片都是网上找不到的。
具体的,对训练集或测试集进行数据预处理包括:
s101、对训练集或测试集进行数据清洗。清洗后,将所有的人脸图片分别存入对应人名的文件夹中。
s102、对训练集或测试集中的人脸图片进行人脸检测,抠取出人脸图像。由于训练集或测试集图片中人脸图像的大小、位置不一致,在做进一步特征提取之前需要检测人脸,将人脸图像部分抠取出来。
s103、将人脸图像进行人脸对齐处理。除了要得到人脸外,还要进行人脸人脸对齐,只要将人脸对齐后的人脸送进网络才能得到更高的精度。给定每个人脸的五个人脸关键点,包括左眼关键点、右眼关键点、鼻子关键点、左嘴角关键点以及右嘴角关键点。
s200、构建卷积神经网络模型。卷积神经网络模型采用基于resnet50扩展改进的深度神经网络模型。
resnet:residualnetwork,深度残差,它是2015年提出的深度卷积神经网络,一经出世,便在imagenet中斩获图像分类、检测、定位三项的冠军,残差网络更容易优化,并且能够通过增加相当的深度来提高准确率,核心是解决了增加深度带来的退化问题,这样能够通过单纯地增加网络深度,来提高网络性能。
s300、使用预处理后的训练集对卷积神经网络模型进行训练,提取出人脸关键点区域特征并进行融合。
本实施例中,卷积神经网络模型包括输入层、conv1卷积层、最大池化层、conv2卷积层、conv3卷积层、conv4卷积层、conv5卷积层、4个并列的conv6卷积层和均值池化层。
具体训练过程为:将预处理后的224×224训练集人脸图像输入至卷积神经网络模型的输入层,经输入层输出至conv1卷积层,conv1卷积层的输入为3ch×224×224、输出为64ch×112×112、卷积核尺寸为7×7,然后经conv1卷积层输出至最大池化层,最大池化层的输出为64ch×56×56、卷积核尺寸为3×3,再经最大池化层输出至conv2卷积层,conv2卷积层包括由3个不同的卷积构成的3个相同的块,conv2卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为64ch×56×56、64ch×56×56、256ch×56×56,再经conv2卷积层输出至conv3卷积层,conv3卷积层包括由3个不同卷积构成的4个相同的块,conv3卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为128ch×28×28、128ch×28×28、512ch×28×28,再经conv3卷积层输出至conv4卷积层,conv4卷积层包括由3个不同卷积构成的6个相同的块,conv4卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为256ch×14×14、256ch×14×14、1024ch×14×14,再经conv4卷积层输出至conv5卷积层,conv5卷积层包括由3个不同卷积构成的3个相同的块,conv5卷积层中三个卷积的卷积核尺寸分别为1×1、3×3、1×1,输出分别为512ch×7×7、512ch×7×7、1024ch×7×7。
人脸关键点区域包括左眼区域、右眼区域、鼻子区域以及嘴区域,左眼区域、右眼区域以及鼻子区域分别为以左眼关键点、右眼关键点以及鼻子关键点为中心点,取其周围边长为8的区域,嘴区域为以左嘴角关键点和右嘴角关键点的平均点为中心点,取其周围16×8的区域,由conv3卷积层的中间特征表达上提取出相应人脸关键点区域的特征。conv3卷积层后接入4个并列的conv6卷积层,conv6卷积层的输入为512ch×28×28、输出为256ch×7×7,每个conv6卷积层对应提取一个人脸关键点区域的特征,将4个conv6卷积层的输出端相连进行融合输出为1024ch×7×7,最后通过均值池化层输出1024ch×1×1。
s400、使用测试集对卷积神经网络模型进行测试。本实施例中,测试集采用lfw数据集对模型性能进行检测。测试集数据通过与训练集相同的方式进行数据预处理,将经过数据清洗、人脸检测、人脸图像抠取以及人脸图像人脸对齐后的人脸图像输入至卷积神经网络模型进行测试。
lfw:无约束自然场景人脸识别数据集,该数据集由13000多张全世界知名人士互联网自然场景不同朝向、表情和光照环境人脸图片组成,共有5000多人,其中有1680人有2张或2张以上人脸图片,每张人脸图片都有其唯一的姓名id和序号加以区分。
本发明实施例提出的一种基于关键点区域特征融合的人脸识别方法,克服了传统人脸识别方法对光照差异、面部表情、有无遮挡等多种不确定干扰的敏感性的缺点,利用卷积神经网络对提取的人脸关键点区域的特征进行融合,降低了对训练集样本的要求,使得学习到的特征更具有全局性,识别模型更具有鲁棒性。横向比较而言,本发明实施例采用对人脸关键点区域的特征融合手段进行人脸识别,相较于其他基于卷积神经网络的人脸识别方法,具备得到全局最优分类的能力。纵向比较而言,本发明实施例相比于传统的人脸识别,综合考虑人脸的全局特征和不变性特征,保证了人脸识别模型不会因干扰因素而降低性能。
实施例2
与上述实施例1相对应的,本实施例提出了一种基于关键点区域特征融合的人脸识别装置,该装置包括:
预处理模块,用于对训练集或测试集进行数据预处理。
网络建立模块,用于构建卷积神经网络模型。
训练模块,用于使用预处理后的训练集对所述卷积神经网络模型进行训练,提取出人脸关键点区域特征并进行融合。
测试模块,用于使用预处理后的测试集对所述卷积神经网络模型进行测试。
进一步的,预处理模块包括:
数据清洗单元,用于对训练集或测试集进行数据清洗;
人脸检测单元,用于对训练集或测试集中的人脸图片进行人脸检测,并抠取出人脸图像;
人脸对齐单元,用于将所述人脸图像进行人脸对齐处理。
虽然,上文中已经用一般性说明及具体实施例对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!