基于斯格明子赛道存储器的内存计算系统及方法与流程
本发明涉及计算机技术领域,具体涉及一种基于斯格明子赛道存储器的内存计算系统及方法。
背景技术:
卷积神经网络可应用到在人脸识别、语音识别等方面,这些在物联网领域都有着广泛的应用。但是,这些需要使用大量的数据进行像乘法这样的高耗能的计算。这与人工智能设备超低功耗的需求是矛盾的。二进制卷积神经网络(bcnn)通过将输入和权值转换为二进制值(“1”或“-1”),从而大大减少运算数据,进而降低功耗,而且并没有因为减少运算数据带来较大精度损失。同时,二进制卷积运算中复杂的乘法运算可以被替换为与运算,与运算在电路上更容易实现,需要更少的能量消耗。
但是,内存单元和处理单元之间的数据传输仍然消耗大量的计算资源。前人的一些工作采用内存计算的方法解决了数据传输瓶颈问题。然而,这些设计都是基于易失性存储器sram,但由于sram本身的限制(如面积大、漏电流大等),这些设计仍然性能受到限制。
非易失性存储器,如电阻式随机存取存储器(rram)、自旋磁矩磁性随机存取存储器(sot-mram)、域壁存储器(dwm)和斯格明子赛道存储器(srm),由于其独特的性能,如接近于零的静态能耗和高集成度等,有望取代sram。在这些非易失性存储器中,dwm以其高集成度、低功耗等特点受到了广泛的研究。近年来,srm因其体积小(可达数纳米),移位电流(106a/m2)较dwm(1011-1012a/m2)小而备受关注。
技术实现要素:
本发明提出的一种基于斯格明子赛道存储器的内存计算系统和方法,可解决二进制卷积神经网络稀疏性问题,并且降低计算功耗。
为实现上述目的,本发明采用了以下技术方案:
一种基于斯格明子赛道存储器的内存计算系统,包括srm-cim的电路架构,所述srm-cim的电路架构包括行译码器rowdecoder、列译码器columndecoder、电压驱动voltagesupplier、存储阵列、感应电路msc、计数器bit-counter和模式控制器mc;
其中,所述电压驱动voltagesupplier包括两个nmos,所述两个nmos漏极分别连接为写操作和读操作提供电压的电压源,源极接地,栅极接入三选一选择器mux;还包括一根导线与两个nmos并联接入三选一选择器,代表读操作、与操作和异或操作所需位线bl电压为0;在模式控制器mc发出的控制信号cs的控制下,选择器选通相应的nmos或导线,根据工作模式提供驱动电压;
所述感应电路msc利用预充电读出放大器pcsa比较节点ab和节点cd之间的电阻大小;
所述节点ab分别连接电路的位线bl和源线sl,所述节点cd之间连接参考电阻;
所述参考电阻在不同工作模式下需要不同的电阻值,其中,三个nmos分别串联为读操作提供电阻值的mtjrrefr、为异或操作提供电阻值的mtjrrefx和为与操作提供电阻值的mtjrrefa,然后并联漏极接入节点c,源极接入节点d,栅极接入三选一选择器mux,选择器在控制信号cs的控制下,选通相应的nmos,根据工作模式选通相应的参考电阻;
所述存储阵列采用斯格明子赛道存储器构成。
进一步的,所述预充电读出放大器pcsa包括四个pmos和两个nmos连接,如果节点ab之间的电阻rab大于节点cd之间的电阻rcd,qm输出0而
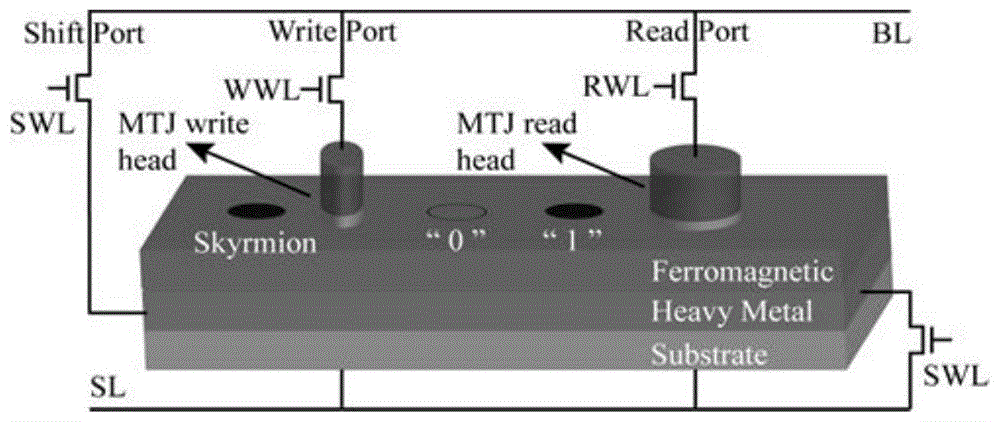
进一步的,所述srm-cim的电路架构为纳米赛道,包括铁磁层ferromagnetic、重金属层heavymetal和基底sustrate三层;
赛道上通过一个nmos串联写入mtj至位线bl和源线sl,nmos栅极连接写入字线wwl,为写端口,控制斯格明子的生成;
赛道上通过一个nmos串联读出mtj至位线bl和源线sl,nmos的栅极连接读取字线rwl,为读端口,控制斯格明子的检测,在mtj读头上显示的不同电阻值分别代表数据“1”和“0”;
赛道两侧分别串联nmos至位线bl和源线sl,两个nmos栅极连接移位字线swl,为移位端口,控制斯格明子的移动。
进一步的,所述存储阵列包括垂直赛道群vrg和水平赛道群hrg,所述垂直赛道群vrg和水平赛道群hrg分别采用斯格明子赛道存储器构成;
在垂直赛道群vrg里,斯格明子赛道存储器竖直连接;
在水平赛道群hrg里,斯格明子赛道存储器水平连接。
另一方面本发明还公开一种基于斯格明子赛道存储器的内存计算方法,采用上述的基于斯格明子赛道存储器的内存计算系统,包括二进制卷积神经网络卷积过程,具体包括以下步骤,
输入input为m×m的矩阵,权重weight为n×n的矩阵,其中n小于m;权重矩阵在输入矩阵上扫描,相应的权重向量和输入向量进行卷积计算;
所述卷积计算公式表示为:
i&w=bit-count(i(b)&w(b))
其中i和w分别为输入和权重向量,i(b)和w(b)分别为输入和权重里每位上的二进制数。
进一步的,还包括二进制卷积神经网络卷积过程的移位方法,具体包括:
如果n×n的权重在m×m的输入上扫描,步长为l,则
s1、将权值数据和输入数据都按原始顺序存储在存储阵列中,输入存储到的水平赛道群hrg部分,权重存储到的垂直赛道群vrg部分;
s2、权重和对应输入进行卷积计算;
s3、权重向右移动l个单位长度,与对应输入进行卷积计算;
s4、重复步骤
s5、输入向上移动l个单位长度,权重移动到左侧初始位置;
s6、重复步骤s2、s3、s4;
s7、重复步骤
进一步的,还包括二进制卷积神经网络卷积过程写入向量的步骤:
启用wwl,并在bl和sl之间设置正电压,在写入头的赛道上写入“1”;如果要写入数据“0”,无需任何操作;
启用swls,在bl和sl之间设置一个正电压,将刚写入的数据向下移动到下一个单元,继续在写入头写入下一个数据。
进一步的,包括读取操作步骤,
如果读头所存数据为1,读头的电阻值用r1表示;反之读头所存数据为0,读头的电阻值用r0表示;参考电阻用rref表示,r1>rrefr>r0;
当启用wl且vread为0v时,将基于msc从“0”读取数据。
进一步的,还包括异或操作步骤,
在异或操作中,参考电阻rrefx与rij取值的关系为r11>r10=r01>rrefx>r00;
需要两个步骤得到异或操作结果:
第一步,msc执行与操作,将输出信号“0”传递给模式控制器mc;
第二步,根据“0”信号,mc输出控制信号cs,判断是否启用rrefx,然后使用pcsa得到xor结果;
如果“0”在步骤一中输出“1”,则表示要访问的数据为“1”,mc不启用任何参考电阻,使节点c和d断开,因此“0”在步骤二中输出“0”;否则,如果“0”在步骤一输出“0”,mc将启用参考电阻rrefx,然后“0”输出其他情况下的xor结果。
由上述技术方案可知,本发明利用斯格明子赛道存储器设计内存计算架构,不仅在内存中实现存储,而且可以在内存进行计算操作。本发明有效支持二进制卷积计算,充分利用srm的移位特性,减少数据内存访问冗余,解决了bcnn稀疏性问题,减少了计算负担,大大降低功耗。
同时,本发明针对广泛应用于物联网领域的卷积神经网络,基于斯格明子赛道存储器,提出了一种超低功耗内存计算架构(srm-cim),该架构可以同时执行存储操作和内存中计算操作(与操作和异或操作)。本发明可实现2×2内核在64×64的输入上完成一次卷积扫描过程只需要26.751nj的能量,而且执行时间仅仅72.641us。在典型的二进制卷积神经网络比如xnor-net情况下,本发明应用于卷积层时,与基于rram的等效物相比,所用能量降低了98.7%。
附图说明
图1为本发明实施例斯格明子赛道存储器的原理图;
图2为本发明实施例3×3权重在5×5输入上的卷积扫描过程示意图(步长为2);
图3为本发明实施例卷积计算的移位策略示意图;
图4为本发明实施例srm-cim的架构示意图;
图5:为本发明实施例vrg和hrg的结构示意图;
图6为本实施例扫描卷积过程的数据存储和移位示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
本实施例利用所设计的电路结构和移位策略完成图2所示的卷积计算操作,具体如下:
图4(a)是srm-cim的整体架构,它由行译码器(rowdecoder)、列译码器(columndecoder)、电压驱动(voltagesupplier)、存储阵列(vrg+hrg)、改进的感应电路(msc)、计数器(bit-counter)和模式控制器(mc)组成。
其中电压驱动如图4(b)所示,由两个nmos和一个选择器连接而成。在模式控制器mc发出的控制信号cs的控制下,选择器选通相应的mos管或导线,根据不同的工作模式(写操作,移位操作,读操作、与操作、异或操作)提供不同的驱动电压。
其中改进的感应电路(msc)如图4(c)所示,利用预充电读出放大器(pcsa)可以比较节点ab和cd之间的电阻大小(所存储的数据)。节点ab分别连接电路的位线bl和源线sl,cd之间连接参考电阻。根据不同的操作(读操作、与操作、异或操作)需求,需要在cd间连入不同的阻值的参考电阻。本实施例设计了虚线框内的结构,在控制信号cs的控制下,选择器选通相应操作所需的参考电阻rrefr,rrefa,rrefx。
图5为存储阵列,存储阵列由两部分组成:垂直赛道(vrg)和水平赛道(hrg),输入和权重分别存储在vrg和hrg中。
所述存储阵列vrg和存储阵列hrg采用斯格明子赛道存储器构成。在vrg,斯格明子赛道存储器竖直连接(所存数据可以沿竖直方向移动)。在hrg,斯格明子赛道存储器水平连接(所存数据可以沿水平方向移动)。
首先对组成存储阵列vrg和hrg的斯格明子赛道存储器介绍
其中,数据的存储是基于图1所示的斯格明子赛道存储器(vrg和hrg就是由这些斯格明子赛道组成的)。整个电路为纳米赛道,它由铁磁层、重金属层和基底三层组成。斯格明子(黑色实心圆)是在磁化分布均匀的背景下,具有稳定的螺旋磁序的手性自旋结构。二进制数据“1”(或“0”)可以用赛道上的斯格明子的存在(或不存在)来表示。赛道上通过一个nmos串联写入mtj至位线bl和源线sl,nmos栅极连接写入字线wwl,为写端口,控制斯格明子的生成。赛道上通过一个nmos串联读出mtj至位线bl和源线sl,nmos的栅极连接读取字线rwl,为读端口,控制斯格明子的检测,在mtj读头上显示的不同电阻值分别代表数据“1”和“0”。赛道两侧分别串联nmos至位线bl和源线sl,两个nmos栅极连接移位字线swl,为移位端口,控制斯格明子的移动。
其次,介绍存储阵列vrg和hrg的内部结构和其存储的二进制数
如图5a为vrg和hrg的内部结构,图5b为对应的二进制数据。
在图5a中,实心黑色圆表示赛道上存在数据为“1”的斯格明子,黑色轮廓的空心圆表示数据为“0”。
下面来说明本发明实施例针对二进制图像卷积过程的移位策略
1、卷积过程介绍
输入input为m×m的矩阵,权重weight为n×n的矩阵,其中n小于m。权重矩阵在输入矩阵上扫描,相应的权重向量和输入向量进行卷积计算。
以图2所示卷积过程为例3×3的权重(灰色部分)矩阵在5×5的输入矩阵(白色部分)上扫描。整个过程包括(a)(b)(c)(d)四个卷积计算。相应的结果是包含四个元素的2×2矩阵,这四个元素分别是这四次卷积计算的结果。每个卷积计算都是将相应的二进制输入和二进制权重对应位进行与操作,然后对每位上的与操作结果进行累加。每个卷积计算公式可以表示为
i&w=bit-count(i(b)&w(b))
其中i和w分别为输入和权重向量,i(b)和w(b)分别为输入和权重里每位上的二进制数。
2、卷积过程的移位策略
如果n×n的权重在m×m的输入上扫描,步长为l。
1.将权重和输入分别写入hrg和vrg。
2.权重和对应输入进行卷积计算。
3.权重向右移动l个单位长度,与对应输入进行卷积计算。
4.重复步骤
5.输入向上移动l个单位长度,权重移动到左侧初始位置。
6.重复步骤2、3、4。
7.重复步骤
具体移位策略参考图3。由图2可以看出相同的权重向量要和不同输入矩阵里的不同块做卷积计算。本发明实施例的移位策略可以只存储一次权重数据和输入数据完成整个卷积扫描过程。避免了数据的存储冗余。过程如图3,在卷积过程之前将权值数据和输入数据都按原始顺序存储在存储阵列中,输入存储到的hrg部分,权重存储到的vrg部分。完成第一次卷积计算后,将权重数据向右移动两个单位长度(根据图2,卷积扫描步长为2),进行第二次卷积计算。然后将输入数据上移两个单位长度;将权值数据左移两个单位长度,来完成第三个卷积计算。最后,再次将权重右移两个单位长度,为第四次卷积计算做准备。
3、完成图2所示的卷积步骤过程的
3.1、将输入和权重按照顺序(存储)写入电路
启用wwl,并在bl和sl之间设置正电压,可在写入头的赛道上写入“1”。如果要写入数据“0”,无需任何操作。启用swls,在bl和sl之间设置一个正电压,将刚写入的数据向下移动到下一个单元,这样我们就可以继续在写入头写入下一个数据。
图5展示了每个存储单元对应写入的数据。根据图5,输入矩阵中的(1,0,0,1,1)向量要写入vrg中的第三个赛道,根据设计,写入数据的先后顺序与数据顺序相反,即我们先后写入(1,1,0,0,1),以此为例,介绍写入向量的步骤:首先,启用wwl,并在bl和sl之间设置正电压,我们在写入头的赛道上写入“1”。然后启用swls,在bl和sl之间设置一个正电压,将数据“1”向下移动到下一个单元,这样我们就可以在写入头写入下一个数据“1”,因为接下来两个数据都是“0”,我们不需要做任何处理,只需将斯格明子链向下移动两个单位的长度,即写入两个“0”。最后,将斯格明子链向下移动1个单位长度,然后在写头上写入最后一个数据“1”,完成向量(1,0,0,1,1)的写操作。按照这样的思路,输入和权重矩阵的所有向量可并行存储到存储阵列。
3.1.1、写操作的具体步骤
如图3所示,当启用wwl时,在位线(bl)和源线(sl)之间增加正电压,产生自旋极化电流。如果这个电流大于临界电流,则在一段时间后会生成一个表示逻辑数据“1”的斯格明子结构。相反,如果没有斯格明子,则表示逻辑数据“0”。
3.1.2、移位操作具体实现步骤
当赛道两边的swls启动,如果在bl和sl之间加一个正向电压,赛道中会产生移位电流。如果移位电流大于移位的临界电流,斯格明子以一定的速度向右移动。(如果bl和sl之间存在适当的负电流,斯格明子会向左移动。)
3.2、完成如图2(a)所示的卷积计算
3.2.1、卷积计算的实现步骤
如图6(a)所示,用黑色实线圈出的输入数据(101,011,100)和权值数据(100,111,011)为要访问的数据。卷积计算的实现需要三个步骤。步骤1:在vrg第一行的输入(1,0,1)和hrg第一行的权值(1,0,0)之间进行与操作:1&1,0&0和1&0。然后将结果传输到位计数器。步骤2和步骤3分别对存储在vrg和hrg的第二行和第三行中的数据执行与步骤1相同的过程。然后经过计数器输出第一个卷积计算(a)的结果。
3.2.2、与运算的具体实现步骤
这里需要用到与操作,具体实现步骤如下:待处理两单元格的结构和运算如图4(c)所示,由rij给出(i和j分别为逻辑数据“1”和“0”)。rij是与rj并联的ri的阻值(ri和rj必须在同一列)。它有四个可能的值r11、r10、r01和r00,如表1所示。rrefa为c与d之间的参考电阻,r11>rrefa>r10=r01>r00。当启用两个被访问单元的wls且vand为0v时,将基于msc从(o)输出与操作结果。
3.2.3、完成如图2(b)所示的卷积计算
完成如图2(b)所示的卷积计算。在图6(b)中,启用hrg中的移位端口,使权值(100,111,011)右移两个单位长度。使执行图1(b)中第二次卷积计算所需的输入和权重现在都在同一列中。黑色实线环绕要访问的数据。经过3.2.1描述的卷积计算的三个步骤,我们可以完成第二次卷积计算(b)。
3.2.4、完成如图2(c)和2(d)所示的卷积计算
在图6(c)中,通过启用vrg中的swls,我们将输入向上移动了两个单位的长度,以便将上两个卷积计算(c)和(d)中要访问的输入移动到读取头。并且权重都移动到左边为第三个卷积计算(c)做准备。完成卷积计算(c)之后,在图6(d),像如图6(b)一样向右移动权重,我们将实现最后卷积计算(d)。因此,本发明和映射策略可以在不存在内存访问冗余的情况下执行图2中的卷积过程,实现扫描卷积,大大降低了计算能量。
4、本发明实施例还可以实现的其他操作
以上描述的写操作、移位操作、与操作不仅限于卷积计算。另外本设计也可以实现异或操作和存储器常用的读操作。
4.1、读取操作具体步骤
如果读头所存数据为1,读头的电阻值用r1表示;反之读头所存数据为0,读头的电阻值用r0表示。参考电阻用rref表示。r1>rrefr>r0,当启用wl且vread为0v时,将基于msc从(o)读取数据。
表1显示了读操作和异或操作的参数。“pre”和“abs”表示赛道上斯格明子的存在和缺失,分别表示逻辑数据“1”和“0”。待读取单元格的结构如图4(c)所示,由ri表示(i为逻辑数据“1”或“0”)。r1和r0是对应的读头电阻值。refr为节点c与d之间的参考电阻,它们之间的关系为r1>rrefr>r0。当启用wl且vread为0v时,将基于msc从(o)读取数据。
表1
4.2、异或操作具体步骤
在异或操作中,参考电阻rrefx与rij可能取值的关系为r11>r10=r01>rrefx>r00。需要两个步骤得到异或操作结果:第1步,msc执行与操作,将输出信号(o)传递给模式控制器(mc)。第二步,根据(o)信号,mc输出控制信号cs,判断是否启用rrefx,然后使用pcsa得到xor结果。如果(o)在步骤1中输出“1”,则表示要访问的数据为“1”,mc不启用任何参考电阻,使节点c和d断开,因此(o)在步骤2中输出“0”。否则,如果(o)在步骤1输出“0”,mc将启用参考电阻rrefx,然后(o)可以输出其他情况下的xor结果。
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!