一种基于机器学习的智能分析软件缺陷的方法、系统及存储介质与流程
本发明涉及计算机技术领域,尤其涉及一种基于机器学习的智能分析软件缺陷的方法、系统及存储介质。
背景技术:
随着社会的进步,科技的发展,软件已广泛应用于人们生活和生产当中,但是目前缺少对软件的缺陷进行计算测试的方法。
技术实现要素:
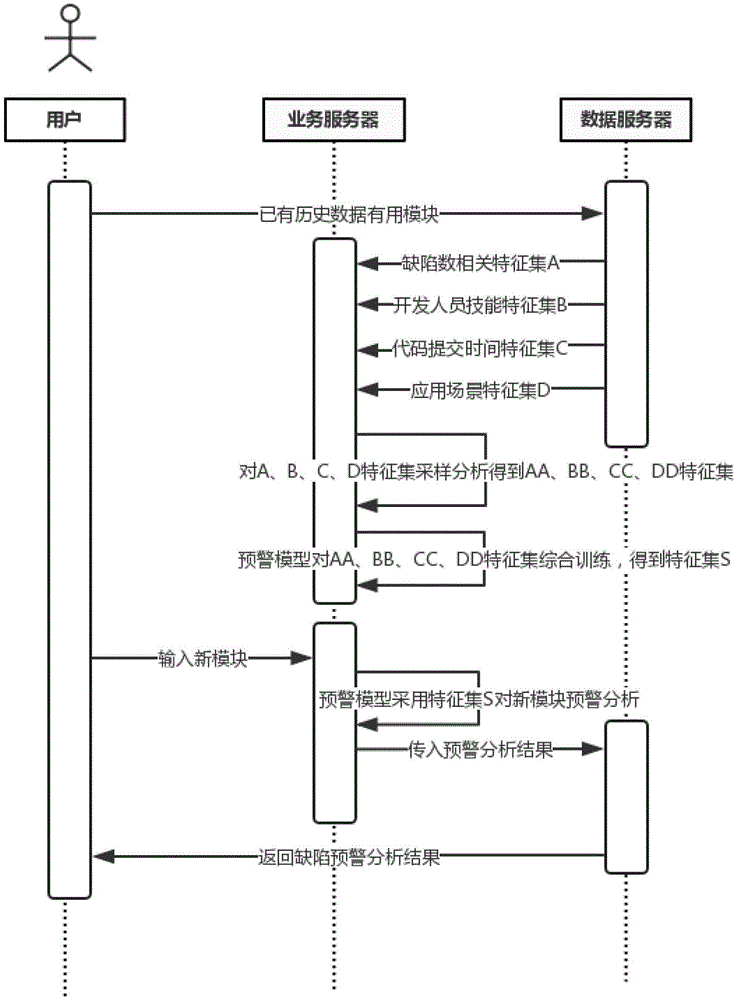
本发明提供了一种基于机器学习的智能分析软件缺陷的方法,包括如下步骤:
步骤1,获得初始特征集,初始特征集包括:
对历史数据训练抽取软件模块与缺陷数有关的特性,获得缺陷数相关的特征集a={a1,a2...an};
对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性,获得开发人员技能的特征集b={b1,b2...bn};
对历史数据训练抽取软件模块与提交代码时间段有关的特性,获得代码提交时间的特征集c={c1,c2...cn};
对历史数据训练抽取有用的模块与应用场景(如、开发语言、类、函数、代码行数、耦合情况等)有关的特性,获得应用场景的特征集d={d1,d2...dn};
步骤2,对特征集a、b、c、d进行多次采样,按照f=n/n比例进行采样分析,分别形成特征集aa、bb、cc、dd,n为样本大小,n为总样本数;
步骤3,预警模型对最终特征集aa、bb、cc、dd综合学习,采用随机森林方法随机生成特征矩阵,得到s个矩阵决策树集s;
步骤4,输入新模块时,预警模型采用决策树集s对新模块进行综合分析f(x)=s(x)/s(x)+1,将会得到s个分类结果,统计计数分析s类,数目越大则采用其作为软件缺陷分布情况预警,x为随机变量;f(x)为统计分类函数,用于计算s(x)分类情况,s(x)为决策树集。
作为本发明的进一步改进,对历史数据训练抽取软件模块与缺陷数有关的特性包括语法错误数量、接口错误数量、参数错误数量、逻辑错误数量。
作为本发明的进一步改进,对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性包括工作年限、学历、行业经验。
作为本发明的进一步改进,对历史数据训练抽取有用的模块与应用场景有关的特性包括开发语言、类、函数、代码行数、耦合情况。
本发明还提供了一种基于机器学习的智能分析软件缺陷的系统,包括:
初始特征集获得模块,用于获得初始特征集,初始特征集包括:
对历史数据训练抽取软件模块与缺陷数有关的特性,获得缺陷数相关的特征集a={a1,a2...an};
对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性,获得开发人员技能的特征集b={b1,b2...bn};
对历史数据训练抽取软件模块与提交代码时间段有关的特性,获得代码提交时间的特征集c={c1,c2...cn};
对历史数据训练抽取有用的模块与应用场景(如、开发语言、类、函数、代码行数、耦合情况等)有关的特性,获得应用场景的特征集d={d1,d2...dn};
采样分析模块,用于对特征集a、b、c、d进行多次采样,按照f=n/n比例进行采样分析,分别形成特征集aa、bb、cc、dd,n为样本大小,n为总样本数;
生成模块,用于预警模型对最终特征集aa、bb、cc、dd综合学习,采用随机森林方法随机生成特征矩阵,得到s个矩阵决策树集s;
预警分析模块,用于输入新模块时,预警模型采用决策树集s对新模块进行综合分析f(x)=s(x)/s(x)+1,将会得到s个分类结果,统计计数分析s类,数目越大则采用其作为软件缺陷分布情况预警,x为随机变量。
作为本发明的进一步改进,对历史数据训练抽取软件模块与缺陷数有关的特性包括语法错误数量、接口错误数量、参数错误数量、逻辑错误数量。
作为本发明的进一步改进,对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性包括工作年限、学历、行业经验。
作为本发明的进一步改进,对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性包括工作年限、学历、行业经验。
本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的方法的步骤。
本发明的有益效果是:本发明对原始的测试数据训练,获得软件模块的特征及相应的软件模块标签;对软件模块数据、人员技能素质进行特征提取,基于测试数据选取与相应测试数据距离最近的训练数据,不断优化测试数据,利用学习到特征来计算测试模块是否含有错误缺陷,提高效率,满足用户需求。
附图说明
图1是本发明的原理框图。
图2是本发明的方法流程图。
具体实施方式
如图1所示,本发明公开了一种基于机器学习的智能分析软件缺陷的方法,包括如下步骤:
步骤1,获得初始特征集,初始特征集包括:
对历史数据训练抽取软件模块与缺陷数有关的特性(如语法错误数量、接口错误数量、参数错误数量、逻辑错误数量等),获得缺陷数相关特征集a={a1,a2...an};
对历史数据训练抽取软件模块与软件开发人员技能素质(如工作年限、学历、行业经验等)有关的特性,获得开发人员技能特征集b={b1,b2...bn};
对历史数据训练抽取软件模块与提交代码时间段有关的特性(如9:00-12:00,14:00-18:00,19:00-21:00等),获得代码提交时间特征集c={c1,c2...cn};
对历史数据训练抽取有用的模块与应用场景(如、开发语言、类、函数、代码行数、耦合情况等)有关的特性,获得应用场景特征集d={d1,d2...dn};
步骤2,为保证数据的准确性,通过对特征集a、b、c、d进行多次采样,按照f=n/n(n为样本大小,n为总样本数)比例进行采样分析,分别形成最终特征集aa、bb、cc、dd;
步骤3,预警模型对最终特征集aa、bb、cc、dd综合学习,采用随机森林方法随机生成特征矩阵,采用
矩阵
矩阵
.....
矩阵
步骤4,新提交模块m时,采用预测模型决策树s对新模块进行综合分析f(x)=s(x)/s(x)+1,(x为随机变量)将会得到s个分类结果,统计计数分析s类,数目越大则采用其作为软件缺陷分布情况预警;f(x)为统计分类函数,用于计算s(x)分类情况,s(x)为决策树集,x为自然数(1-n)。
本发明还公开了一种基于机器学习的智能分析软件缺陷的系统,包括:
初始特征集获得模块,用于获得初始特征集,初始特征集包括:
对历史数据训练抽取软件模块与缺陷数有关的特性,获得缺陷数相关的特征集a={a1,a2...an};
对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性,获得开发人员技能的特征集b={b1,b2...bn};
对历史数据训练抽取软件模块与提交代码时间段有关的特性,获得代码提交时间的特征集c={c1,c2...cn};
对历史数据训练抽取有用的模块与应用场景(如、开发语言、类、函数、代码行数、耦合情况等)有关的特性,获得应用场景的特征集d={d1,d2...dn};
采样分析模块,用于对特征集a、b、c、d进行多次采样,按照f=n/n比例进行采样分析,分别形成特征集aa、bb、cc、dd,n为样本大小,n为总样本数;
生成模块,用于预警模型对最终特征集aa、bb、cc、dd综合学习,采用随机森林方法随机生成特征矩阵,得到s个矩阵决策树集s;
预警分析模块,用于输入新模块时,预警模型采用决策树集s对新模块进行综合分析f(x)=s(x)/s(x)+1,将会得到s个分类结果,统计计数分析s类,数目越大则采用其作为软件缺陷分布情况预警,x为随机变量。
对历史数据训练抽取软件模块与缺陷数有关的特性包括语法错误数量、接口错误数量、参数错误数量、逻辑错误数量。
对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性包括工作年限、学历、行业经验。
对历史数据训练抽取软件模块与软件开发人员技能素质有关的特性包括工作年限、学历、行业经验。
本发明还公开了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序配置为由处理器调用时实现本发明所述的方法的步骤。
本发明对原始的测试数据训练,获得软件模块的特征及相应的软件模块标签;对软件模块数据、人员技能素质进行特征提取,基于测试数据选取与相应测试数据距离最近的训练数据,不断优化测试数据,利用学习到特征来计算测试模块是否含有错误缺陷,提高效率,满足用户需求。
以上内容是结合具体的优选实施方式对本发明所作的进一步详细说明,不能认定本发明的具体实施只局限于这些说明。对于本发明所属技术领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!