基于子图同构的web数据自动可视化方法与流程
本发明涉及一种基于子图同构的web数据自动可视化方法。
背景技术:
rest(representationalstatetransfer)架构风格于2000年发布于国际会议icse上,它是一种web体系结构的抽象模型,用于指导重新设计和定义超文本传输协议和统一资源标识符。至今仍然能够根据这种架构风格的应用来了解万维网的工作方式与原理,这对于大规模软件架构的理解与发展有重要意义。royt.fielding博士提出rest架构风格的论文在谷歌学术上统计已经被引用超过7000次,发布于icse/toit的论文被引用超过2000次。
rest服务的流行使得网络上出现了大量的轻量级数据服务,并持续保持爆炸性指数增长,国际上网站上也出现了大量服务供应商,致力于网络服务的集中供应与质量保障。大型在线web服务网站programmableweb聚集了各个领域大量的api信息,目前其收集的api数量已超过两万,其中rest架构风格的服务占80%以上;各大网络科技公司也有自己的api公开平台,如:google、youtube、facebook、百度、阿里巴巴;还有许多个人开发的api公布在github和个人blog上。
programmableweb所收集的服务中,响应格式种类繁多,其中以json与xml格式为主。xml(可扩展标记语言)是最古老的数据格式之一。它由w3c(万维网联盟)定义,并基于较旧的sgml(标准通用标记语言)格式。在xml中,数据使用元素和属性进行结构化。json(javascriptobjectnotation)是一种轻量级的数据交换格式。易于人阅读和编写,同时也易于机器解析和生成。json采用完全独立于语言的文本格式,是一种理想的数据交换语言。相比之下,xml有大量的冗余元素,重复的元素名称导致数据体量增大。json则没有重复元素名称所带来的数据冗余,数据传输速率更高,解析效率与查找效率都高于xml。近年来开发者更倾向于使用json作为数据响应格式。在programmableweb收集的rest服务中,响应格式支持json的服务占据了90%以上的比例。
多样化的服务催生了巨量的数据信息,而数据信息创造的真正价值在于数据分析。数据可视化可以通过交互式可视化界面及数据-图像转换技术来辅助用户对数据进行分析理解。研究人员研发了多种可视化平台,试图实现数据自动或半自动可视化。roth提出的sage是经典的可视化设计系统,可以根据数据的特性,在用户指定相关约束的情况下,自动生成可视化;satyanarayan提出的lyra系统在数据管道中选择数据区域后,根据用户选定的可视化图形及参数实现数据可视化;ren提出的ivisdesigner系统提供了统一界面进行交互式可视化创建、编辑操作,由固定模式定义的数据集在转换为内部元素后用于可视化映射;viegas设计的manyeyes在用户上传数据后,先指定可视化方法,并在此基础上进行各种配置,最终生成交互式可视化结果。在上述可视化系统中,为了尽可能实现数据与图形的自动化匹配,都对数据结构与格式有固定的要求。数据结构与可视图形结构的匹配问题可以抽象为子图同构问题,现已有多种算法针对该问题提出了解决方案。ullmann算法是一种深度递归算法,也是第一个行之有效的子图同构搜索算法。该算法建立了一个部分匹配结果集,通过不断地增加或删除其中的元素来查找确定正确的匹配结果。近年来还有很多算法在ullmann算法的理念基础上进行改良,得到更有效的子图同构算法。vf2算法和graphql算法通过建立剪枝规则来剪除不符合条件的候选节点,从而减小候选集的大小;quicksi算法尝试尽可能早访问具有不常见标签的顶点和不常见的相邻边标签的顶点;gaddi算法结合相邻子距(theneighboringdiscriminatingsubstructure(nds)distance)理念,设计了独特的剪枝规则来缩小候选集的大小;spath算法通过匹配每个调用的路径来最小化递归树的深度,从而提高查找效率。现有的可视化系统虽然不同程度上化简了数据可视化的操作,但是仍然需要用户参与指导,尤其对于复杂数据需要手工编排以保障更好的可视化效果;没有匹配算法的支持令成图的结果限制于人工设置的范围内,无法充分体现自动可视化的优势。
技术实现要素:
为了尽可能实现web数据的自动可视化,本发明提出了一种基于子图同构的web数据自动可视化方法,通过对json数据进行树形结构建模及对常见可视化图形进行结构建模来构建标准化通用模型,并基于子图同构算法,给出了一种改进的降维匹配算法将模型进行自动化匹配,以实现数据的自动可视化。
本发明所采用的技术方案是:
一种基于子图同构的web数据自动可视化方法,所述方法包括以下步骤:
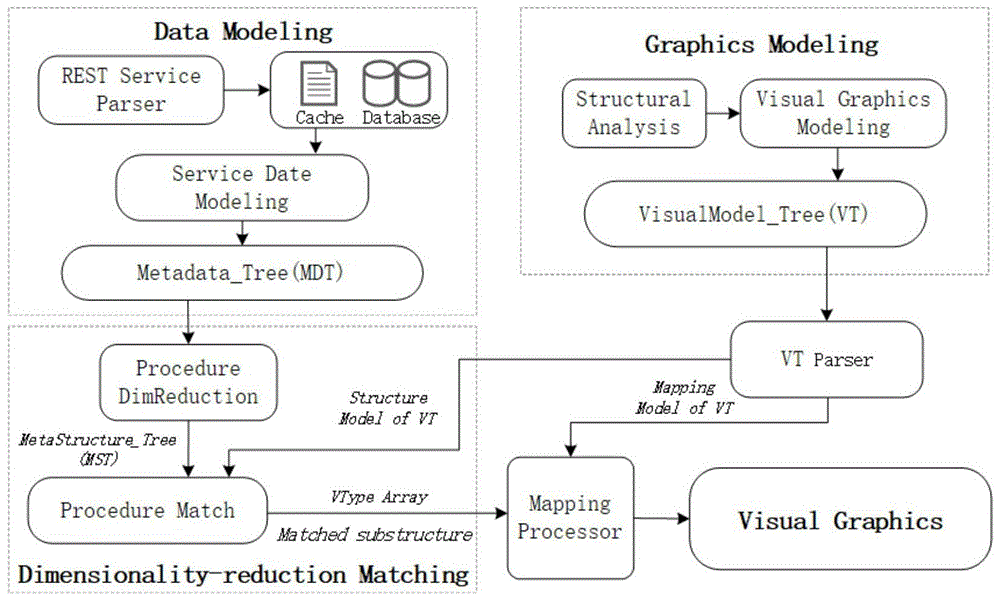
第一步:构建服务数据可视化建模与匹配方法的架构,包括三个模块:数据建模(datamodeling)、图形建模(graphicsmodeling)、降维匹配(dimensionality-reductionmatching);
第二步:定义元数据树(metadata_tree,简写为mdt),包括根节点(tree_root,简写为troot)、索引节点(index_node,简写为inode)、数据节点(data_node,简写为dnode),同时用深度(level)来表示节点在树结构中的层数,根节点默认为第一层,即level=1;
第三步:读取调用的restapi所返回的json数据,将json数据集ds作为建模算法的输入,对ds进行树形结构建模;
第四步:由于json数据集中可能存在批量数据,批量数据通常以相同的数据结构形式存在,在数据集中常用数组的形式表现。若是用户的对于json数据分析的重点不在于数据的定位、查询,而是针对数据结构的分析,在上述json数据解析建模的方法基础上,可以通过剪枝的方法,保留基本的数据结构信息,剪除相同的重复数据结构,缩小模型的体量,但仍然保留基础的数据结构,降低json数据结构所带来的查询开销;
第五步:对可视化图形进行分类,归纳总结各类图形的属性及结构特征,通过建模创建一种可视模型树(visualizationtree,简称vt),来形式化地表述各类图形信息;
第六步:子图同构是一个在查询图中查找查询子图,判断查询图中是否包含了查询子图的问题;本步骤中先用降维方法对mdt进行降维操作,生成元结构树(metastructure_tree,简称mst),再将可视模型树vt与mst进行匹配查询,调用基于子图同构的匹配方法查找mst中与vt的各个structmodel匹配的片段,并根据mapping信息进行数据映射,生成可视化图形。
进一步,所述第一步的过程如下:
1.1、数据建模:从internet获取的rest服务经解析器(restserviceparser)解析后进行注册,存储于缓存cache或数据库database中,自动调用后所获取的基于json的rest服务数据,通过服务数据建模(servicedatamodeling)将服务数据转变为标准化模型,并抽取出主要数据结构生成元数据树mdt;
1.2、图形建模:对多种配置型可视化工具所支持的图形进行数据结构分析与归纳(structuralanalysis),整理出主要图形的通用数据结构及数据映射关系,再根据上述信息进行可视化图形建模(visualgraphicsmodeling),创建描述性可视模型——visualmodeltree(简称vt);
1.3、降维匹配:调取数据建模所生成的mdt,通过降维算法(proceduredimreduction)对其进行结构降维,获得包含源数据基础数据结构的元结构树mst,然后通过vt解析器(vtparser)提取出vt中的图形结构模型(structuremodelofvt),在mst中使用基于子图同构的匹配算法(procedurematch)来搜索与图形结构模型匹配的数据结构片段,最后输出源数据可生成的图形种类(vtypearray)及mst中的匹配片段(matchedsubstructure);
1.4、图像生成:根据所属1.3输出的图形种类及mst中的匹配片段,将其按照vt解析器提取出的映射关系(mappingmodelofvt)通过映射处理器(mappingparser)来自动化生成可视化图形(visualgraphics);
再进一步,所述第二步的过程如下:
2.1、根节点:mdt的根节点,即mdt的起始节点;
2.2、索引节点:代表json数据中每一个关键字(key),但不包括json数据中最内层的“键-值”对的关键字,索引节点为非根节点、非叶子节点;
2.3、数据节点:代表json数据中最内层的“键-值”对,存储为叶子节点。
所述2.1中,所述根节点内包含以下信息:
2.1.1、星标(ismark):记录json数据中最外层结构是否为数组类型,若是用1标记,若否用0标记;ismark形式化定义表述如(1)(2),ismark的数据类型为数字(number),若json数据中“键-值”对中的值(value)为数组(array),则ismark=1,否则ismark=0;“#”为数据类型定义符,“::=”为赋值符,〖a→condition⊕<b>:<c>〗表示若a符合条件condition,则该式值为b,否则该式值为c;
(1)、“ismark”#<number>
(2)、“ismark”::=〖“value”→array⊕<1>:<0>〗
2.1.2、元素数量(arraynum):若当前节点的ismark为1,则记录数组元素个数,若当前节点的ismark为0,则用0标记;arraynum形式化定义表述如(3)(4),arraynum属性值为数字(number)类型,若json数据中“键-值”对中的值(value)为array,则arraynum等于value数组的长度,否则arraynum=0;
(3)、“arraynum”#<number>
(4)、
所述2.2中,所述索引节点内包含以下信息:
2.2.1、节点名称(name):name的数据类型为字符串(string),name属性值为json数据中“键-值”对中的关键字(key);name形式化定义表述如(5)(6);
(5)、“name”#<string>
(6)、“name”::=<key>
2.2.2、节点值类型(vtype):vtype是json数据中“键-值”对中的值(value)的数据类型,属性值为对象(object)、数组(array)、字符串(string)、数字(number)、true、false之一;vtype形式化定义表述如(7);
(7)、“vtype”::=[object|array|string|number|true|false]
2.2.3、星标(ismark):记录json数据中,以当前节点名称(name)作为关键字的“键-值”对中的值(value)是否为数组类型,若是用1标记,若否用0标记;ismark形式化定义表述同步骤2.1.1中的(1)(2);
2.2.4、元素数量(arraynum):若当前节点的ismark为1,则记录“键-值”对中的值(value)的数组元素个数,若当前节点的ismark为0,则用0标记;arraynum形式化定义表述同步骤2.1.2中的(3)(4)
所述2.3中,所述数据节点内包含以下信息:
2.3.1、节点名称(name):保存json数据中“键-值”对中的关键字(key),数据类型为字符串(string);name形式化定义表述同步骤2.2.1中的(5)(6);
2.3.2、节点值(nvalue):nvalue的数据类型为string,属性值为json数据中“键-值”对中的值(value);nvalue形式化定义表述如(8)(9);
(8)、“nvalue”#<string>
(9)、“nvalue”::=<value>
2.3.3、节点类型(type):保存json数据中“键-值”对中的值(value)的数据类型,为“str”、“num”或null,其中“str”代表type的数据类型为string,“num”代表type的数据类型为number,null表示type的属性值为空;type形式化定义表述如(10);
(10)、“type”::=[“str”|“num”|null]。
更进一步,所述第三步的步骤如下:
3.1、创建一棵根节点为troot的mdt,troot是起始节点,根节点的深度(level)默认为1;
3.2、读取json数据集ds,如果是首次读取ds,设置ds的第一个元素为当前元素,元素包括关键字(key)及其值(value);否则设置ds的下一个元素为当前元素;若json数据最外层就是array,则troot的ismark=1,元素数量(arraynum)为array元素个数。
优选的,所述步骤3.2的过程如下:
3.2.1、若value的数据类型非object,同时非array,创建深度为level+1的数据节点,节点名称(name)为关键字(key),节点值(nvalue)为值(value),节点类型(type)为值(value)的数据类型;完成后跳转至步骤3.2;
3.2.2、若value的数据类型为array,创建深度level’=level+1的索引节点,节点名称(name)为关键字(key),节点值类型(vtype)为array,ismark=1,元素数量(arraynum)为当前value数组中的元素个数;
3.2.2.1、若所述3.2.2中的value数组的元素不是object类型,则创建level”=level’+1的数据节点,节点名称(name)为关键字(key),节点值(nvalue)为值(value),节点类型(type)为值(value)的数据类型;完成后跳转至步骤3.2;
3.2.2.2、若所述3.2.2中的value数组的元素是object类型,则创建level”=level’+1的索引节点,节点名称(name)为每个object元素中的关键字(key),节点值类型(vtype)为每个object元素中的值(value)的数据类型。若当前vtype为array,则ismark=1,元素数量(arraynum)为当前value数组中的元素个数;若当前vtype不为array,则ismark=0,arraynum=0;
3.2.2.3、将步骤3.2.2.2中value数组作为新的json数据集ds’,跳转至步骤3.2;
3.2.3、若value的数据类型为object,创建深度level’=level+1的索引节点,节点名称(name)为每个object元素中的关键字(key),节点值类型(vtype)为每个object元素中的值(value)的数据类型。若当前vtype为array,则ismark=1,元素数量(arraynum)为当前value数组中的元素个数;若当前vtype不为array,则ismark=0,arraynum=0;
3.2.4、将步骤3.2.3中value数组作为新的json数据集ds’,跳转至步骤3.2。
所述第四步的步骤如下:
4.1、从level=1的troot开始,按广度优先策略,按层遍历mdt的根节点与索引节点;广度优先策略将按level逐层遍历mdt,从level=1的第一层开始遍历,当level层的节点遍历完成后,再继续遍历level+1层的节点;
4.2、将mdt的troot存入遍历队列;
4.3、按遍历队列顺序,读取每个节点的ismark属性;
4.3.1、若遍历到的节点的ismark属性值为1,则保留当前节点的第一个子节点,剪除其余的子节点及其子节点的子树结构,跳转至步骤4.3.4;
4.3.2、若遍历到的节点的ismark属性值为0,则不进行任何操作,跳转至步骤4.3.4;
4.3.3、若遍历到的节点为数据节点,将当前节点从遍历队列中删除,跳转至步骤4.3;
4.3.4、将当前遍历到的节点的子节点加入遍历队列,并将当前节点从遍历队列中删除,再跳转至步骤4.3;
4.4、当遍历队列中全部为数据节点时或遍历队列为空时,停止遍历,结束方法;
4.5、输出剪枝后的mdt。
所述第五步的过程如下:
5.1、定义vt包括基础属性(basicattribute)和可视结构(dvschema)两个部分,形式化定义如(11),其中basicattribute保存了图形标题、副标题及其他文本样式的通用信息;
(11)、visualmodel::=<basicattribute><dvschema>
5.2、basicattribute包括三个属性:标题(title)、子标题(subtitle)、属性(attributes),形式化定义如(12),title用于保存最终生成的可视化图形的标题,subtitle用于保存最终生成的可视化图形的子标题,attributes用于保存最终生成的可视化图形的位置、颜色组合、字体、字号设置参数;
(12)、basicattribute::=<title><subtitle><attributes>
5.3、basicattribute根据图形所需的数据类型、图形数据结构、图形维度将常见的可视化图形归纳为四种基础类别:一般图形(general)、拓扑图(topology)、地图(map)、文本图形(text),形式化定义如(13);
(13)、dvschema::=<general><topology><map><text>
5.4、步骤5.3中的四种基础类别下属均分别包含两个属性:图形类型(vtype)和图形结构(structmodel),vtype保存了该类别所属图形种类,structmodel保存了该类别所属图形的基本可视化结构,形式化定义如(14),“a::b”表示“a包含了属性b”;
(14)、dvschema::=<general><topology><map><text>::<vtype><structmodel>
所述5.4中,四种基础类别的vtype属性的所属图形如下:
5.4.1、general包括柱状图(barchart)、折线图(linechart)、饼图(piechart)、雷达图(radarchart)、散点图(scatterchart);
5.4.2、topology包括网络图(networkchart)、树图(treemap)、面积树图(treemapchart);
5.4.3、map包括地区地图(areamapchart)、国家地图(countrymapchart)、世界地图(worldmapchart);
5.4.4、text包括词云(worldcloudchart);
5.5、步骤5.4中四种基础类别均有各自的映射关系(mapping),描述了各类图形的数据结构、数据维度、图形结构关系、数据映射位置信息;根据mapping信息并结合图形的数据结构,可以抽象出各类图形的基本可视化结构structmodel,步骤三中所生成的mdt将与structmodel进行匹配,来判断restapi的返回数据能够生成何种可视化图形。
所述步骤5.5的过程如下:
5.5.1、general类型中的图形通常用于表示二维数据或三维数据,可用二元组(xaxis,yaxis)或三元组(xaxis,yaxis,zaxis)来表示信息,此类图形的mapping结构如(15),其中legendname表示图例名称,以array类型来存储各分组信息;根据mapping结构可抽象出基础structmodel的结构如(16),structmodel的子节点为临时根节点root,root包含两个子节点:键值对k_v与图例节点legendnode;
(15)、mapping::=<xaxis,yaxis,[zaxis]><legendname>
(16)、structmodel::=<root::<k_v><legendnode>>
5.5.2、topology类型中的图形通常用于表示拓扑关系数据,树图与面积树图可用嵌套的键值对{key:value,children:{key:value}}来表示属性结构,mapping结构如(17);网络图可用节点集合(nodes)和边集合(links)来表示图结构,mapping结构如(18),其中source表示一条边link的起始节点,target表示该条边link的指向节点;根据mapping结构可抽象出基础structmodel的结构如(19),structmodel有两个子结构,root1和root2分别为两个子结构的临时根节点,root1包含两个子节点:键值对k_v和孩子节点children,children的子结构为键值对k_v;root2包含两个子节点:节点集合nodes和边集合links,节点集合的子节点为关键字key和值value,其中value可能为空,边集合的子节点为起点source和目标target;
(17)、mapping::=<k_v><children::<k_v>>
(18)、mapping::=<nodes::<key,[value]><links::<source><target>>
(19)、structmodel::=<root1::<k_v><children::<k_v>>><root2::<nodes::<key,[value]>,<links::<source><target>>>
5.5.3、map类型中的图形通常用于表示地图信息,用键值对数组[{placename:value}]或三元组数组[{lng,lat,value}]来表示地图信息,此类图形的mapping结构如(20),其中placename表示地名,lng表示纬度,lat表示经度;根据mapping结构可抽象出基础structmodel的结构如(21),structmodel有两个子结构,root1和root2分别为两个子结构的临时根节点,root1包含子子节点键值对k_v;root2包含了三个子节点:经度lat,纬度lng,数值value;
(20)、mapping::=<data1::<placename><value>><data2::<lng><lat><value>>
(21)、structmodel::=<root1::<k_v>>,<root2::<lng>,<lat>,<value>>
5.5.4、text类型中的图形常用二元组(keyword,frequency)来表示关键字频率,此类图形的mapping结构如(22),其中keyword为文本中提取出的词汇,frequency表示该词汇在文本中的出现频率;根据mapping结构可抽象出基础structmodel的结构如(23),structmodel的子节点为临时根节点root,root包含了键值对k_v;
(22)、mapping::=<keyword><frequency>
(23)、structmodel::=<root::<k_v>>。
所述第六步的过程如下:
6.1、定义元结构树(mst),包括子树根节点(subtree_root,简称stroot)、子结构(substruct),形式化定义如(24),mst用于保存降维后的mdt;其中子结构substruct由引导节点(guide_node,简称gnode)和数据节点(leaf_node,简称lnode)两部分构成,形式化定义如(25);根节点stroot内包含的信息同2.1.1至2.1.2;引导节点gnode内包含的信息同2.2.1至2.2.4;叶子节点lnode内包含的信息同2.3.1至2.3.3;同时用深度(level)来表示节点在树结构中的层数,stroot默认为第一层,即level=1;
(24)、mst::=<subtree_root><substruct>
(25)、substruct::=<guide_node><leaf_node>
6.2、解析vt中四种基础类别的structmodel,提取每种structmodel中的临时根节点及其子结构,每一个临时根节点及其子结构构成的树结构片段将作为查询子图,根据步骤5.5.1至5.5.4可以提取出六个查询子图:general类型的structmodel的下属root为起点的子结构,topology类型的structmodel的下属分别以root1和root2为起点的两个子结构,map类型的structmodel的下属分别以root1和root2为起点的两个子结构,text类型的structmodel的下属root为起点的子结构;
6.3、定义基于子图同构的匹配方法match(mst),以mst作为输入,将步骤6.2中的六个查询子图用structmodelk表示,与每个structmodelk同属于一个大类(general、topology、map、text之一)的vtype用vtypek表示;
6.4、基于子图同构的降维匹配算法通过对mdt进行降维操作生成mst后,调用步骤6.3中定义的基于子图同构的匹配方法match(mst)进行自动化匹配,将mdt作为输入,最后输出源数据可生成的图形种类及mst中的匹配片段;
6.5、根据match(mst)方法输出的匹配片段从源数据中提取数据,并将数据根据mapping结构映射到输出的对应类型的图形结构中,从而生成可视化图形。
所述步骤6.3的过程如下:
6.3.1、按照广度优先策略,按层遍历mst,将mst的节点从stroot开始,按层数从小到大的顺序,将stroot和所有gnode存入遍历队列q;
6.3.2、设置节点s为structmodelk的根节点;
6.3.3、按遍历队列q的顺序,将当前q中遍历到的节点xi与节点s进行比较,判断xi与s的ismark属性值是否相等;
6.3.3.1、若xi与s的ismark属性值相等,将xi加入集合p,设置i=i+1,跳转至步骤6.3.3;
6.3.3.2、若xi与s的ismark属性值不相等,设置i=i+1,跳转至步骤6.3.3;
6.3.4、当q遍历完成后,遍历集合p中的节点pj,判断pj与s的父子节点关系是否一致;
6.3.4.1、若pj与s的父子节点关系不一致,设置j=j+1,跳转至步骤6.3.4;
6.3.4.2、若pj与s的父子节点关系一致,将pi加入集合m,跳转至步骤6.3.5;
6.3.5、判断集合m与structmodelk的结构是否一致;
6.3.5.1、若m与structmodelk的结构一致,输出集合m和structmodelk对应的vtypek;清空集合p,设置k=k+1,设置xi为q的第一个节点,跳转至步骤6.3.2;
6.3.5.2、若m与structmodelk的结构不一致,将s设置为它在structmodelk中的下一个节点,清空集合p,设置k=k+1,设置xi为q的第一个节点,跳转至步骤6.3.3;
6.3.6、当六个查询子图均完成查询后,结束方法match(mst),输出源数据可生成的图形种类(vtypek)及mst中匹配片段的集合m;
所述步骤6.4的过程如下:
6.4.1、按照广度优先策略,按层遍历mdt,将mdt的节点从troot开始,按层数从小到大的顺序,将troot和所有inode存入遍历队列l;
6.4.2、按遍历队列l的顺序,对当前遍历到的节点ma的ismark属性和m的子节点的type属性进行判断,是否符合ismark=1且type=”num”;
6.4.2.1、若ismark=1且type=”num”,将ma加入集合s,设置a=a+1,跳转至步骤6.4.2;
6.4.2.2、若不符合ismark=1且type=”num”,设置a=a+1,跳转至步骤6.4.2;
6.4.3、当l遍历完成后,按集合s中节点加入顺序的逆序来遍历集合s,当前遍历到的节点用nb表示;
6.4.4、如果在s中没有其他节点与nb有相同的父节点,将nb和它的子结构存储为临时子树subtree,将subtree加入mst,作为stroot的子结构,再从mdt中剪除subtree,并将nb从集合s中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5;
6.4.5、如果在s中存在其他节点与nb有相同的父节点,将nb加入集合u;
6.4.6、按顺序遍历集合u,对遍历到的节点uc的arraynum属性值进行判断;
6.4.6.1、若arraynum>2,将uc和它的子结构存储为临时子树subtree,将subtree加入mst,作为stroot的子结构,再从mdt中剪除subtree,并将uc从集合u中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5;
6.4.6.2、若arraynum<=2,在u中查找出其他的arraynum<=2节点d,将uc的父节点、uc、d、uc的子节点、d的子节点存储为总层数为3的临时子树subtree,若subtree与topology类中structmodel的两个子结构之一结构相同,则将该subtree存入mst,以uc的父节点为stroot,再从mdt中剪除subtree,并将nb和d从集合u与s中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5;
6.4.6.3、若arraynum<=2,在u中没有其他的arraynum<=2节点,将uc和它的子结构存储为临时子树subtree,将subtree加入mst,作为stroot的子结构,再从mdt中剪除subtree,并将uc从集合u中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5。
本发明的有益效果表现在:本方法能够智能地理解服务响应的json数据,对其进行树形结构建模,生成标准化数据结构,无需人工对数据格式进行编排,也无需预先设置数据模板;自动构建的数据模型可与常用的可视化图形模型——可视模型树vt进行匹配,在匹配过程中使用基于子图同构的降维匹配算法能够缩减查询图体量,减小查询范围,匹配过程中优化了候选集,剪除不符合候选条件的节点,达到了优化自动查找匹配结构过程的目的,提高了查询效率,降低查询开销与成本;在自动可视化整体过程中减少了人工编辑操作,化简数据可视化流程。
附图说明
图1示出了web数据可视化建模与匹配方法的架构图
图2示出了2018世界杯restapi所返回的json数据结构图。
图3示出了json数据转化的树形结构图。
图4示出了json数据剪枝后的树形结构图。
图5示出了可视模型树vt的结构图
图6示出了基于子图同构的web数据自动可视化系统功能模块图
具体实施方式
下面结合附图对本发明作进一步描述。
参照图1~图5,一种基于子图同构的web数据自动可视化方法,包括以下步骤:
第一步:构建服务数据可视化建模与匹配方法的架构,参照图1,包括三个模块:数据建模(datamodeling)、图形建模(graphicsmodeling)、降维匹配(dimensionality-reductionmatching)。
1.1、数据建模:从internet获取的rest服务经解析器(restserviceparser)解析后进行注册,存储于缓存cache或数据库database中,自动调用后所获取的基于json的rest服务数据,通过服务数据建模(servicedatamodeling)将服务数据转变为标准化模型,并抽取出主要数据结构生成元数据树mdt;
1.2、图形建模:对多种配置型可视化工具所支持的图形进行数据结构分析与归纳(structuralanalysis),整理出主要图形的通用数据结构及数据映射关系,再根据上述信息进行可视化图形建模(visualgraphicsmodeling),创建描述性可视模型——visualmodeltree(简称vt);
1.3、降维匹配:调取数据建模所生成的mdt,通过降维算法(proceduredimreduction)对其进行结构降维,获得包含源数据基础数据结构的元结构树mst,然后通过vt解析器(vtparser)提取出vt中的图形结构模型(structuremodelofvt),在mst中使用基于子图同构的匹配算法(procedurematch)来搜索与图形结构模型匹配的数据结构片段,最后输出源数据可生成的图形种类(vtypearray)及mst中的匹配片段(matchedsubstructure)。
1.4、图像生成:根据所属1.3输出的图形种类及mst中的匹配片段,将其按照vt解析器提取出的映射关系(mappingmodelofvt)通过映射处理器(mappingparser)来自动化生成可视化图形(visualgraphics)。
第二步:定义元数据树(metadata_tree,简写为mdt),包括根节点(tree_root,简写为troot)、索引节点(index_node,简写为inode)、数据节点(data_node,简写为dnode),同时用深度(level)来表示节点在树结构中的层数,根节点默认为第一层,即level=1;
2.1、根节点:mdt的根节点,即mdt的起始节点;
2.2、索引节点:代表json数据中每一个关键字(key),但不包括json数据中最内层的“键-值”对的关键字,索引节点为非根节点、非叶子节点;
2.3、数据节点:代表json数据中最内层的“键-值”对,存储为叶子节点;
所述2.1中,所述根节点内包含以下信息:
2.1.1、星标(ismark):记录json数据中最外层结构是否为数组类型,若是用1标记,若否用0标记;ismark形式化定义表述如(1)(2),ismark的数据类型为数字(number),若json数据中“键-值”对中的值(value)为数组(array),则ismark=1,否则ismark=0;“#”为数据类型定义符,“::=”为赋值符,〖a→condition⊕<b>:<c>〗表示若a符合条件condition,则该式值为b,否则该式值为c;
(1)、“ismark”#<number>
(2)、“ismark”::=〖“value”→array⊕<1>:<0>〗
2.1.2、元素数量(arraynum):若当前节点的ismark为1,则记录数组元素个数,若当前节点的ismark为0,则用0标记;arraynum形式化定义表述如(3)(4),arraynum属性值为数字(number)类型,若json数据中“键-值”对中的值(value)为array,则arraynum等于value数组的长度,否则arraynum=0;
(3)、“arraynum”#<number>
(4)、“arraynum”::=〖“value”→array⊕<array.length>:<0>〗
所述2.2中,所述索引节点内包含以下信息:
2.2.1、节点名称(name):name的数据类型为字符串(string),name属性值为json数据中“键-值”对中的关键字(key);name形式化定义表述如(5)(6);
(5)、“name”#<string>
(6)、“name”::=<key>
2.2.2、节点值类型(vtype):vtype是json数据中“键-值”对中的值(value)的数据类型,属性值为对象(object)、数组(array)、字符串(string)、数字(number)、true、false之一;vtype形式化定义表述如(7);
(7)、“vtype”::=[object|array|string|number|true|false]
2.2.3、星标(ismark):记录json数据中,以当前节点名称(name)作为关键字的“键-值”对中的值(value)是否为数组类型,若是用1标记,若否用0标记;ismark形式化定义表述同步骤2.1.1中的(1)(2);
2.2.4、元素数量(arraynum):若当前节点的ismark为1,则记录“键-值”对中的值(value)的数组元素个数,若当前节点的ismark为0,则用0标记;arraynum形式化定义表述同步骤2.1.2中的(3)(4)
所述2.3中,所述数据节点内包含以下信息:
2.3.1、节点名称(name):保存json数据中“键-值”对中的关键字(key),数据类型为字符串(string);name形式化定义表述同步骤2.2.1中的(5)(6);
2.3.2、节点值(nvalue):nvalue的数据类型为string,属性值为json数据中“键-值”对中的值(value);nvalue形式化定义表述如(8)(9);
(8)、“nvalue”#<string>
(9)、“nvalue”::=<value>
2.3.3、节点类型(type):保存json数据中“键-值”对中的值(value)的数据类型,为“str”、“num”或null,其中“str”代表type的数据类型为string,“num”代表type的数据类型为number,null表示type的属性值为空;type形式化定义表述如(10);
(10)、“type”::=[“str”|“num”|null]
第三步:读取调用的restapi所返回的json数据,将json数据集ds作为建模算法的输入,对ds进行树形结构建模,步骤如下:
3.1、创建一棵根节点为troot的mdt,troot是起始节点,根节点的深度(level)默认为1;
3.2、读取json数据集ds,如果是首次读取ds,设置ds的第一个元素为当前元素,元素包括关键字(key)及其值(value);否则设置ds的下一个元素为当前元素;若json数据最外层就是array,则troot的ismark=1,元素数量(arraynum)为array元素个数;
3.2.1、若value的数据类型非object,同时非array,创建深度为level+1的数据节点,节点名称(name)为关键字(key),节点值(nvalue)为值(value),节点类型(type)为值(value)的数据类型;完成后跳转至步骤3.2;
3.2.2、若value的数据类型为array,创建深度level’=level+1的索引节点,节点名称(name)为关键字(key),节点值类型(vtype)为array,ismark=1,元素数量(arraynum)为当前value数组中的元素个数;
3.2.2.1、若所述3.2.2中的value数组的元素不是object类型,则创建level”=level’+1的数据节点,节点名称(name)为关键字(key),节点值(nvalue)为值(value),节点类型(type)为值(value)的数据类型;完成后跳转至步骤3.2;
3.2.2.2、若所述3.2.2中的value数组的元素是object类型,则创建level”=level’+1的索引节点,节点名称(name)为每个object元素中的关键字(key),节点值类型(vtype)为每个object元素中的值(value)的数据类型。若当前vtype为array,则ismark=1,元素数量(arraynum)为当前value数组中的元素个数;若当前vtype不为array,则ismark=0,arraynum=0;
3.2.2.3、将步骤3.2.2.2中value数组作为新的json数据集ds’,跳转至步骤3.2;
3.2.3、若value的数据类型为object,创建深度level’=level+1的索引节点,节点名称(name)为每个object元素中的关键字(key),节点值类型(vtype)为每个object元素中的值(value)的数据类型。若当前vtype为array,则ismark=1,元素数量(arraynum)为当前value数组中的元素个数;若当前vtype不为array,则ismark=0,arraynum=0;
3.2.4、将步骤3.2.3中value数组作为新的json数据集ds’,跳转至步骤3.2。
第四步:由于json数据集中可能存在批量数据,批量数据通常以相同的数据结构形式存在,在数据集中常用数组的形式表现。若是用户的对于json数据分析的重点不在于数据的定位、查询,而是针对数据结构的分析,在上述json数据解析建模的方法基础上,可以通过剪枝的方法,保留基本的数据结构信息,剪除相同的重复数据结构,缩小模型的体量,但仍然保留基础的数据结构,降低json数据结构所带来的查询开销,方法步骤如下:
4.1、从level=1的troot开始,按广度优先策略,按层遍历mdt的根节点与索引节点;广度优先策略将按level逐层遍历mdt,从level=1的第一层开始遍历,当level层的节点遍历完成后,再继续遍历level+1层的节点;
4.2、将mdt的troot存入遍历队列;
4.3、按遍历队列顺序,读取每个节点的ismark属性;
4.3.1、若遍历到的节点的ismark属性值为1,则保留当前节点的第一个子节点,剪除其余的子节点及其子节点的子树结构,跳转至步骤4.3.4;
4.3.2、若遍历到的节点的ismark属性值为0,则不进行任何操作,跳转至步骤4.3.4;
4.3.3、若遍历到的节点为数据节点,将当前节点从遍历队列中删除,跳转至步骤4.3;
4.3.4、将当前遍历到的节点的子节点加入遍历队列,并将当前节点从遍历队列中删除,再跳转至步骤4.3;
4.4、当遍历队列中全部为数据节点时或遍历队列为空时,停止遍历,结束方法;
4.5、输出剪枝后的mdt。
第五步:参照图5,对可视化图形进行分类,归纳总结各类图形的属性及结构特征,通过建模创建一种可视模型树(visualizationtree,简称vt),来形式化地表述各类图形信息。
5.1、定义vt包括基础属性(basicattribute)和可视结构(dvschema)两个部分,形式化定义如(11),其中basicattribute保存了图形标题、副标题及其他文本样式的通用信息;
(11)、visualmodel::=<basicattribute><dvschema>
5.2、basicattribute包括三个属性:标题(title)、子标题(subtitle)、属性(attributes),形式化定义如(12),title用于保存最终生成的可视化图形的标题,subtitle用于保存最终生成的可视化图形的子标题,attributes用于保存最终生成的可视化图形的位置、颜色组合、字体、字号设置参数;
(12)、basicattribute::=<title><subtitle><attributes>
5.3、basicattribute根据图形所需的数据类型、图形数据结构、图形维度将常见的可视化图形归纳为四种基础类别:一般图形(general)、拓扑图(topology)、地图(map)、文本图形(text),形式化定义如(13);
(13)、dvschema::=<general><topology><map><text>
5.4、步骤5.3中的四种基础类别下属均分别包含两个属性:图形类型(vtype)和图形结构(structmodel),vtype保存了该类别所属图形种类,structmodel保存了该类别所属图形的基本可视化结构,形式化定义如(14),“a::b”表示“a包含了属性b”;
(14)、dvschema::=<general><topology><map><text>::<vtype><structmodel>
所述5.4中,四种基础类别的vtype属性的所属图形如下:
5.4.1、general包括柱状图(barchart)、折线图(linechart)、饼图(piechart)、雷达图(radarchart)、散点图(scatterchart);
5.4.2、topology包括网络图(networkchart)、树图(treemap)、面积树图(treemapchart);
5.4.3、map包括地区地图(areamapchart)、国家地图(countrymapchart)、世界地图(worldmapchart);
5.4.4、text包括词云(worldcloudchart);
5.5、步骤5.4中四种基础类别均有各自的映射关系(mapping),描述了各类图形的数据结构、数据维度、图形结构关系、数据映射位置信息;根据mapping信息并结合图形的数据结构,可以抽象出各类图形的基本可视化结构structmodel,步骤三中所生成的mdt将与structmodel进行匹配,来判断restapi的返回数据能够生成何种可视化图形;
5.5.1、general类型中的图形通常用于表示二维数据或三维数据,可用二元组(xaxis,yaxis)或三元组(xaxis,yaxis,zaxis)来表示信息,此类图形的mapping结构如(15),其中legendname表示图例名称,以array类型来存储各分组信息;根据mapping结构可抽象出基础structmodel的结构如(16),structmodel的子节点为临时根节点root,root包含两个子节点:键值对k_v与图例节点legendnode;
(15)、mapping::=<xaxis,yaxis,[zaxis]><legendname>
(16)、structmodel::=<root::<k_v><legendnode>>
5.5.2、topology类型中的图形通常用于表示拓扑关系数据,树图与面积树图可用嵌套的键值对{key:value,children:{key:value}}来表示属性结构,mapping结构如(17);网络图可用节点集合(nodes)和边集合(links)来表示图结构,mapping结构如(18),其中source表示一条边link的起始节点,target表示该条边link的指向节点;根据mapping结构可抽象出基础structmodel的结构如(19),structmodel有两个子结构,root1和root2分别为两个子结构的临时根节点,root1包含两个子节点:键值对k_v和孩子节点children,children的子结构为键值对k_v;root2包含两个子节点:节点集合nodes和边集合links,节点集合的子节点为关键字key和值value,其中value可能为空,边集合的子节点为起点source和目标target;
(17)、mapping::=<k_v><children::<k_v>>
(18)、mapping::=<nodes::<key,[value]><links::<source><target>>
(19)、structmodel::=<root1::<k_v><children::<k_v>>><root2::<nodes::<key,[value]>,<links::<source><target>>>
5.5.3、map类型中的图形通常用于表示地图信息,用键值对数组[{placename:value}]或三元组数组[{lng,lat,value}]来表示地图信息,此类图形的mapping结构如(20),其中placename表示地名,lng表示纬度,lat表示经度;根据mapping结构可抽象出基础structmodel的结构如(21),structmodel有两个子结构,root1和root2分别为两个子结构的临时根节点,root1包含子子节点键值对k_v;root2包含了三个子节点:经度lat,纬度lng,数值value;
(20)、mapping::=<data1::<placename><value>><data2::<lng><lat><value>>
(21)、structmodel::=<root1::<k_v>>,<root2::<lng>,<lat>,<value>>
5.5.4、text类型中的图形常用二元组(keyword,frequency)来表示关键字频率,此类图形的mapping结构如(22),其中keyword为文本中提取出的词汇,frequency表示该词汇在文本中的出现频率;根据mapping结构可抽象出基础structmodel的结构如(23),structmodel的子节点为临时根节点root,root包含了键值对k_v;
(22)、mapping::=<keyword><frequency>
(23)、structmodel::=<root::<k_v>>
第六步:子图同构是一个在查询图中查找查询子图,判断查询图中是否包含了查询子图的问题;本步骤中用降维方法对mdt进行降维操作,生成元结构树(metastructure_tree,简称mst),再将可视模型树vt与mst进行匹配查询,调用基于子图同构的匹配方法查找mst中与vt的各个structmodel匹配的片段,并根据mapping信息进行数据映射,生成可视化图形;
6.1、定义元结构树(mst),包括子树根节点(subtree_root,简称stroot)、子结构(substruct),形式化定义如(24),mst用于保存降维后的mdt;其中子结构substruct由引导节点(guide_node,简称gnode)和数据节点(leaf_node,简称lnode)两部分构成,形式化定义如(25);根节点stroot内包含的信息同2.1.1至2.1.2;引导节点gnode内包含的信息同2.2.1至2.2.4;叶子节点lnode内包含的信息同2.3.1至2.3.3;同时用深度(level)来表示节点在树结构中的层数,stroot默认为第一层,即level=1;
(24)、mst::=<subtree_root><substruct>
(25)、substruct::=<guide_node><leaf_node>
6.2、解析vt中四种基础类别的structmodel,提取每种structmodel中的临时根节点及其子结构,每一个临时根节点及其子结构构成的树结构片段将作为查询子图,根据步骤5.5.1至5.5.4可以提取出六个查询子图:general类型的structmodel的下属root为起点的子结构,topology类型的structmodel的下属分别以root1和root2为起点的两个子结构,map类型的structmodel的下属分别以root1和root2为起点的两个子结构,text类型的structmodel的下属root为起点的子结构;
6.3、定义基于子图同构的匹配方法match(mst),以mst作为输入,将步骤6.2中的六个查询子图用structmodelk表示,与每个structmodelk同属于一个大类(general、topology、map、text之一)的vtype用vtypek表示;
6.3.1、按照广度优先策略,按层遍历mst,将mst的节点从stroot开始,按层数从小到大的顺序,将stroot和所有gnode存入遍历队列q;
6.3.2、设置节点s为structmodelk的根节点;
6.3.3、按遍历队列q的顺序,将当前q中遍历到的节点xi与节点s进行比较,判断xi与s的ismark属性值是否相等;
6.3.3.1、若xi与s的ismark属性值相等,将xi加入集合p,设置i=i+1,跳转至步骤6.3.3;
6.3.3.2、若xi与s的ismark属性值不相等,设置i=i+1,跳转至步骤6.3.3;
6.3.4、当q遍历完成后,遍历集合p中的节点pj,判断pj与s的父子节点关系是否一致;
6.3.4.1、若pj与s的父子节点关系不一致,设置j=j+1,跳转至步骤6.3.4;
6.3.4.2、若pj与s的父子节点关系一致,将pi加入集合m,跳转至步骤6.3.5;
6.3.5、判断集合m与structmodelk的结构是否一致;
6.3.5.1、若m与structmodelk的结构一致,输出集合m和structmodelk对应的vtypek;清空集合p,设置k=k+1,设置xi为q的第一个节点,跳转至步骤6.3.2;
6.3.5.2、若m与structmodelk的结构不一致,将s设置为它在structmodelk中的下一个节点,清空集合p,设置k=k+1,设置xi为q的第一个节点,跳转至步骤6.3.3;
6.3.6、当六个查询子图均完成查询后,结束方法match(mst),输出源数据可生成的图形种类(vtypek)及mst中匹配片段的集合m;
6.4、基于子图同构的降维匹配算法通过对mdt进行降维操作生成mst后,调用步骤6.3中定义的基于子图同构的匹配方法match(mst)进行自动化匹配,将mdt作为输入,最后输出源数据可生成的图形种类及mst中的匹配片段;
6.4.1、按照广度优先策略,按层遍历mdt,将mdt的节点从troot开始,按层数从小到大的顺序,将troot和所有inode存入遍历队列l;
6.4.2、按遍历队列l的顺序,对当前遍历到的节点ma的ismark属性和m的子节点的type属性进行判断,是否符合ismark=1且type=”num”;
6.4.2.1、若ismark=1且type=”num”,将ma加入集合s,设置a=a+1,跳转至步骤6.4.2;
6.4.2.2、若不符合ismark=1且type=”num”,设置a=a+1,跳转至步骤6.4.2;
6.4.3、当l遍历完成后,按集合s中节点加入顺序的逆序来遍历集合s,当前遍历到的节点用nb表示;
6.4.4、如果在s中没有其他节点与nb有相同的父节点,将nb和它的子结构存储为临时子树subtree,将subtree加入mst,作为stroot的子结构,再从mdt中剪除subtree,并将nb从集合s中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5;
6.4.5、如果在s中存在其他节点与nb有相同的父节点,将nb加入集合u;
6.4.6、按顺序遍历集合u,对遍历到的节点uc的arraynum属性值进行判断;
6.4.6.1、若arraynum>2,将uc和它的子结构存储为临时子树subtree,将subtree加入mst,作为stroot的子结构,再从mdt中剪除subtree,并将uc从集合u中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5;
6.4.6.2、若arraynum<=2,在u中查找出其他的arraynum<=2节点d,将uc的父节点、uc、d、uc的子节点、d的子节点存储为总层数为3的临时子树subtree,若subtree与topology类中structmodel的两个子结构之一结构相同,则将该subtree存入mst,以uc的父节点为stroot,再从mdt中剪除subtree,并将nb和d从集合u与s中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5;
6.4.6.3、若arraynum<=2,在u中没有其他的arraynum<=2节点,将uc和它的子结构存储为临时子树subtree,将subtree加入mst,作为stroot的子结构,再从mdt中剪除subtree,并将uc从集合u中删除,调用步骤6.3中定义的基于子图同构的匹配方法match(mst),跳转至步骤6.5;
6.5、根据match(mst)方法输出的匹配片段从源数据中提取数据,并将数据根据mapping结构映射到输出的对应类型的图形结构中,从而生成可视化图形。
实例:图2示出了2018世界杯restapi所返回的json数据结构图。worldcupinjsonapi的供应商为softwareforgood,这是一个体育类的api,它的发布主页为http://worldcup.sfg.io,文档主页url为https://github.com/estiens/world_cup_json。在所示json数据结构中展示了2018世界杯第一场比赛信息,fifa_id标注了比赛的id,weather包含了比赛当天的比赛地区的天气信息,attendance表示该场比赛的观众人数,officials包含了该场比赛的工作人员名单,home_team和away_team介绍了该场比赛两支对阵队伍的信息,home_team_events和away_team_events包含了比赛中对阵双方的判、罚事件,home_team_statistics和away_team_statistics包含了在该场比赛中对阵队伍的比赛数据统计信息。
图3是基于我们的方法步骤二得到的json数据转化的树形结构图。图中tree_root为mdt的根节点(troot),index_node为索引节点(inode),data_node为数据节点(dnode)。在level为1的根节点troot下,level=2的每一个inode都包含了一场比赛的信息,下层的每一个节点代表一个属性和它的值。其中,level=3的home_team_statistics属性,包含了on_target、off_target、blocked、offsides属性,则在home_team_statistics节点下创建level=4的on_target、off_target、blocked、offsides节点作为dnode。在图2的mdt中,troot的属性ismark=1,因为2018世界杯的64场比赛信息以数组形式返回;除根节点外,有子节点的节点为索引节点,即json数据中,value为array类型或object类型的节点均为索引节点;mdt中的叶子节点为数据节点,即json数据中,value不为array类型,也不为object类型的节点均为数据节点。图2展示的就是2018世界杯json数据的树形模型。
图4示出了json数据剪枝后的树形结构图。“比赛1”至“比赛64”的信息以数组形式返回,即troot的ismark属性值为1。每一场比赛数据中都包含了相同的属性,即每场比赛数据的子结构是一致的,只需保留一场比赛的信息结构,就能知道所有比赛的信息结构,所以保留“比赛1”分支,剪除其余分支信息。在“比赛1”分支下的home_team_event属性中,每一事件都作为一个数组元素,每个事件都包含了id、type_of_event、player、time四个属性,只需保留一个数组元素,就能知道所有事件的信息结构,所以保留第一个事件的分支,剪除其余分支信息。依次对于所有ismark=1的节点都进行如步骤三的剪枝,就能获得化简后的mdt。
使用本方法能够生成2018世界杯数据的多种图形,如第一轮小组赛信息汇总的柱状图:横轴为attempts_on_goal、on_target、off_target、blocked、wookwork、corners、offsides、ball_possession、pass_accuracy、distance_covered、balls_recovered、tackles、clearances、yellow_cards、red_cards、fouls_committed,纵轴为数值,图例为参赛的32个国家的名称,此柱状图可以表现出各个国家队在各个指标中的表现情况,并能明显地对比国家间的水平;也能够生成半决赛信息汇总的饼图:图例为参加半决赛的法国、英格兰、比利时、克罗地亚,其中八张饼图的比较指标为:射门次数、进球数、铲球次数、抢断次数、传球准确率、守门成功次数,每张图中根据国家对应的图例颜色占比的大小,可以了解每支队伍在该方面的表现情况;还能够生成决赛信息汇总的雷达图:极轴为attempts_on_goal、on_target、off_target、blocked、offsides、corners、ball_possession、pass_accuracy、distance_covered、balls_recovered、tackles、clearances、fouls_committed,图例为法国和克罗地亚,此雷达图可以表现出两支队伍在各个指标中的能力分布情况,法国队的守门员在防守上非常出色,克罗地亚队在进攻射门上非常猛烈。
图6示出了基于子图同构的web数据自动可视化系统功能模块图。可视化系统功能模块说明如下:
(1)可视化平台pc端
(1.1)用户端
(1.1.1)web服务查看:用户可对平台上现有的所有web服务信息进行查看,选择符合需求的服务;
(1.1.2)web服务调用:用户根据需求选择服务后,查看供应商提供的使用协议及资费要求,若同意使用规则并支付资费后,页面将显示web服务的授权,用户在页面上选择“调用”即可;
(1.1.3)可视化参数设置:用户在页面上设置可视化图形的标题、副标题、文本样式信息,并确认调用;
(1.1.4)可视化结果查看:在可视化结果页面用户可查看调用的服务所生成的所有可视化图像,并提供下载功能;
(1.2)供应商端
(1.2.1)web服务列表:供应商可对平台上现有的所有web服务信息进行查看,并可以对自己上传的web服务进行增删改查;
(1.2.2)web服务上传:供应商在页面上填写web服务信息、使用协议、调用方法及密钥、授权要求及方法,还有其他备注信息后,可以上传web服务,待管理员审核完成后,新上传的服务将发布于用户端;
(1.2.3)web服务测试:供应商可对自己上传的通过审核的web服务进行在线测试,确定服务的可用性及正确性;
(1.3)管理员端
(1.3.1)web服务管理:管理员可对平台上的所有web服务信息进行增删改查;对新上传的服务进行服务信息、服务内容及安全性检查,对符合要求与规范条例的服务予以发布;对通过审核的服务进行服务注册,并配置在线调用方法;查看平台上所有的服务使用情况,确保所有服务的正常使用;
(1.3.2)可视化结果管理:管理员可以对平台上所有使用可视化功能使用结果的反馈意见进行管理,及时了解平台性能效果及可视化结果的使用情况;
(1.3.3)用户/供应商管理:对用户及供应商的信息及资质权限进行管理;
(2)可视化服务器
(2.1)web服务注册:在服务器上注册web服务,存储服务信息;
(2.2)web服务监控:监控记录web服务的每一次调用信息、使用情况、调用者信息;
(2.3)数据建模:存储自动化调用的web服务所返回的json数据,并对其
进行数据建模生成mdt;
(2.4)可视化图形建模:对常用可视化图形进行建模,归纳总结各类图形的属性及结构特征;当有新图形纳入可视化结构时,更新可视化模型;
(2.5)自动化匹配:使用基于子图同构的降维匹配算法对数据模型及可视化模型进行自动化匹配,查找匹配数据片段及可生成的可视化图形结构;
(2.6)自动化映射成图:根据匹配的数据片段提取源数据片段并进行数据编排,根据mapping结构将编排好的数据映射至可视化图形中,返回最终生成的可视化图形信息至前端页面生成图像。
- 还没有人留言评论。精彩留言会获得点赞!