一种基于机器学习多特征融合的红外活体检测方法与流程
本发明涉及智慧安防终端红外活体检测技术领域,特别是一种基于机器学习多特征融合的红外活体检测方法。
背景技术:
随着深度学习迅猛发展,人脸识别技术获得突破性的进步,越来越多的安防产品使用上人脸识别技术,人脸识别技术给生活带来了巨大的便利,但是,人脸识别技术带来便利同时也引发人们对产品安全性的担忧,例如生活中的门禁系统和支付系统很容易会遭到偷拍人脸的屏幕或者纸张攻击。因此,在重要的门禁系统进行人脸识别同时也需要进行人脸是否是活体判断,只有当前人脸是活体时,人脸识别结果才有效。活体检测在人脸识别安全性方面扮演着非常重要的角色。目前已有多种活体检测算法,各有优缺点,因此仅仅使用一种算法难以达到很好的识别效果效果。下面介绍几种典型的活体检测方法:
(1)配合式活体检测方法:其属于最原始的人脸活体检测算法。当人脸检测算法检测到人脸图像后,可以使用sdm回归68点或者使用3000pfs算法回归人脸图像特征点,然后通过人脸图像特征点计算人眼张开程度,人脸三个角度pitch,roll和yaw以及嘴巴张开程度,再通过机器(智慧安防终端)随机发出指令要求当前人脸做出来相应的动作,当系统识别到人脸做出来符合要求的动作则认为当前识别的人脸为活体。该算法优点:安全性高,算法简单容易实现;该算法的缺点:需要用户配合,识别时间较长。
(2)动态视频光流活体检测方法:该方法通过统计人脸区域光流变化,使纸张和屏幕照片攻击光流方向趋向一致,真人人脸光流方向不一致。该方法的优点:通过动态方法,用户无感知;该方法的缺点:真人如果刚好正对镜头不动会导致真人难以通过,识别时间较长,屏幕视频攻击会攻击过可见光系统,所以,光流法判断的活体方式在主流产品上是很少用到的。
(3)传统机器学习lbp+svm活体检测方法:当通过检测算法定位到人脸后,使用传统机器学习方法对人脸图像提取lbp特征,将样本库人脸化为lbp特征库输入svm训练模型,后续利用训练好的svm模型预测活体。该方法的优点:用户无感识别,预测速度快;该方法的缺点:场景复杂,在样本丰富时基于lbp特征svm学习能力不足。
(4)基于卷积神经网络提取特征的深度学习活体检测方法:通过人脸检测算法检测到人脸后,将真人和攻击的标签打好,直接将人脸区域图片输入到cnn网络中学习。相比svm分类器,深度学习的方法通过cnn网络自动学习输入样本的特征,在设计上更为简单,而且在数据量非常庞大时,cnn有更好拟合数据的能力。该方法的优点:用户无感识别,预测速度较快,能拟合复杂数据;该方法的缺点:一定需要大量的训练数据才能保证泛化能力。
(5)基于结构光构造人脸深度图的活体检测方法:通过辅助识别结构光器件,构建空间深度图,通过深度图与可见光图片对齐找到可见光人脸对应于深度图的位置,读取人脸深度图信息,直接通过人脸固有的深度信息识别活体,而且弯曲纸张,平板攻击都能轻易杜绝。该方法的优点:速度快,用户无感识别,准确率非常高;该方法的缺点:需要增加设备,成本高。
技术实现要素:
本发明为解决上述技术问题,本发明提供了一种基于机器学习多特征融合的红外活体检测方法,以在嵌入式arm平台门禁系统上实现基于多特征融合的机器学习实时的红外活体检测算法,在保证用户无感,识别时间短的前提下同时提高活体识别效果,而且在复杂环境下(包括白天或者黑夜不同光线下)有很高的识别率,并且具有很好的泛化能力。
为实现上述目的,本发明采用的技术方案为:
一种基于机器学习多特征融合的红外活体检测方法,包括以下步骤:
s1、机器学习特征的提取,其包括:
s11、采用sdm算法定位人脸68点特征点并且在68点处提取lbp特征;
s12、提取人眼区域cnn特征;
s13、提取人脸区域cnn特征;
s2、深度学习网络多特征融合,其包括:
s21、多特征融合:将68点lbp特征、人眼区域cnn特征以及人脸区域cnn特征通过深度学习框架caffe中的concat层连接在一起构成一个新的特征层;
s22、模型低学习率训练挑选最具代表性特征,根据该最具代表性特征输出预测结果。
进一步,所述步骤s11具体包括:首先经过人脸检测算法定位红外图像的人脸区域,然后将人脸区域输入sdm算法定位人脸68特征点,在将人脸图像归一化到96*96大小,最后在96*96人脸图像上提取对应的68点lbp特征。
进一步,所述步骤s12具体包括:选择步骤s11提取的68点特征点定位出的人眼区域作为一个维度特征输入,先将人眼区域图像归一化到64*64的尺寸,人眼块贴上对应的标签整理为人眼图像样本库,再将人眼图像样本库输入cnn进行训练提取人眼区域cnn特征。
进一步,所述步骤s13具体包括:选择步骤s11提取的68点特征点定位出的人脸区域作为一个维度特征输入,先将人脸区域图像归一化到96*96的尺寸,人脸块贴上对应的标签整理为人脸图像样本库,再将人脸图像样本库输入cnn进行训练提取人脸区域cnn特征。
进一步,所述步骤s22具体包括:将lbp特征,64*64的人眼图像和96*96的人脸图像输入低学习率学习模型进行重新训练,得到特征融合层之后的全连接层,且以全连接的方式连接输出2个神经元,2个神经元分别为0和1的概率,0和1分别代表非活体和活体,然后选择最具代表性的红外活体分类特征并且根据该特征输出预测结果。
采用上述技术方案后,相比于现有技术,本发明的具有以下优点:
1)、本发明充分考虑红外图像人脸活体区分性突出的特征,并在特征融合后采用低学习率的学习算法选取最具代表性的活体分类特征用于分类,融合后的特征最终获得的识别效果会比单一特征分类效果更好,而且可保证用户无感,识别时间短,模型泛化能力更强;
2)本发明给红外人脸活体研究带来新方向指引,现有的活体检测分类方法均采用单一特征进行分类,本发明的多特征融合后识别效果更好,在复杂环境下识别率更高,会引导更多研究人员采用多特征提取和融合方式来解决活体检测工程问题,因此具有极大的推广价值。
附图说明
图1为本发明基于机器学习多特征融合的红外活体检测方法的整体流程图;
图2为红外人脸68特征点图;
图3为多特征融合网络示意图。
具体实施方式
为了使本发明所要解决的技术问题、技术方案及有益效果更加清楚、明白,以下结合附图及实施例对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
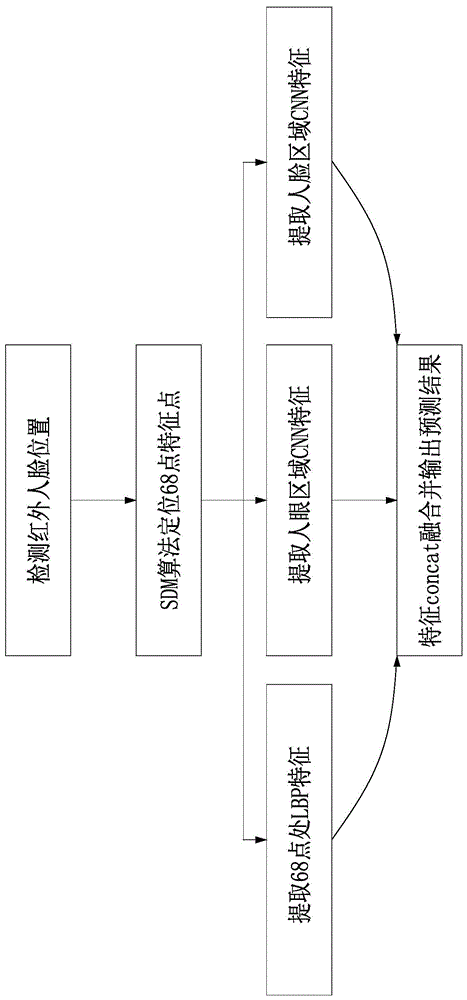
如图1所示,本发明揭示的一种基于机器学习多特征融合的红外活体检测方法,其包括以下步骤:
s1、机器学习特征的提取,其包括:
s11、采用sdm算法定位人脸68点特征点并且在68点处提取lbp特征,其具体包括:如图2所示,首先经过人脸检测算法定位红外图像的人脸区域,然后将人脸区域输入sdm算法定位人脸68特征点,为了减少不同大小的人脸对lbp特征提取引入过多噪声,在将人脸图像归一化到96*96大小,最后在96*96人脸图像上提取对应的68点lbp特征;现有的lbp特征提取方式是直接在96*96的整个图片(含人脸及非人脸部分)每个像素点上提取,对于红外图像的人脸上区域的许多细节纹理都体现不出来,而人脸最明显的特征主要在人脸轮廓,眼睛,鼻子和嘴巴附近,68点特征点刚好覆盖主要特征出现的地方,因此在96*96人脸图像上对应的68点lbp特征作为主要特征既能很好体现红外人脸特征又能提升lbp特征提取速度。
s12、提取人眼区域cnn特征,其具体包括:选择步骤s11提取的68点特征点定位出的人眼区域作为一个维度特征输入,红外人眼成像在室内会有亮瞳效应,在室外真人眼和纸张攻击人眼也是有很大纹理区别的,因此,选择人眼区域作为一个维度特征输入;先将人眼区域图像归一化到64*64的尺寸,人眼块贴上对应的标签整理为人眼图像样本库,再将人眼图像样本库输入cnn进行训练提取人眼区域cnn特征。
s13、提取人脸区域cnn特征,其具体包括:选择步骤s11提取的68点特征点定位出的人脸区域作为一个维度特征输入,人脸整体上的信息是更为丰富的,能学习到遍布整个人脸的特征变化,人脸特征是一个综合类型的特征;人脸比人眼较大,所以先将人脸区域图像归一化到96*96的尺寸,人脸块贴上对应的标签整理为人脸图像样本库,再将人脸图像样本库输入cnn进行训练提取人脸区域cnn特征。
s2、深度学习网络多特征融合,如图3所示其包括:
s21、多特征融合:将68点lbp特征、人眼区域cnn特征以及人脸区域cnn特征通过深度学习框架caffe中的concat层连接在一起构成一个新的特征层;
s22、模型低学习率训练挑选最具代表性特征,根据该最具代表性特征输出预测结果。其具体包括:将lbp特征,64*64的人眼图像和96*96的人脸图像输入低学习率学习模型进行重新训练,得到特征融合层之后的全连接层,且以全连接的方式连接输出2个神经元,2个神经元分别为0和1的概率,0和1分别代表非活体和活体,然后选择最具代表性的红外活体分类特征并且根据该特征输出预测结果。
本发明考虑到性价比因素,通过多特征融合方式构建分类器,在保证用户无感,识别时间快同时提高活体识别效果,而且在嵌入式arm平台门禁系统上实现了基于多特征融合的机器学习实时的红外活体检测算法。
上述的sdm算法是人脸识别领域常用的特征定位算法,本实施例对此不在赘述。
上述的caffe学习框架提供了一个用于训练、测试、微调和开发模型的完整工具包,而且它拥有完善文档的例子用于这些工作。caffe的特性和优点主要有:
模块性:caffe本着尽可能模块化的原则,这样使新的数据格式,网络层和损失函数容易扩展。网络层和损失函数已定义,大量示例展示了这些部分是怎样组成一个识别系统用于不同情况工作的。
表示和实现的分离:caffe模型的定义已经用protoclbuffer语言写成了配置文件。caffe支持在任意有向非循环图形式的网络构建。根据实例化,caffe保留网络需要的内存,并且从主机或者gpu底层的位置抽取内存,在cpu和gpu之间转换只需要调用一个函数。
caffe与其他深度学习开发工具相比,主要有以下两个区别:(1)caffe完全用c++语言来实现,便于移植,并且无硬件和平台的限制,适用于商业开发和科学研究。(2)caffe提供了许多训练好的模型,通过微调(fine-tuning)这些模型,在不用重写大量代码的情况下,就可以快速、高效的开发出新的应用,因此本发明采用caffe学习框架具有极快的识别效率。
上述说明示出并描述了本发明的优选实施例,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文发明构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!