从部分观察中合成新的字体字形的制作方法
本公开涉及用于深度学习和深度神经网络的技术。具体地,本公开涉及使用条件生成性对抗网络模型来从几个字形示例自动合成缺失字形的神经网络架构和方法。
背景技术:
文本是2d设计的突出视觉元素。艺术家投入大量时间设计在它们的形状和纹理上与其他元素在视觉上兼容的字形。在排版中,字形是商定的符号集合中的元素符号,旨在表示用于书写目的的可读字符。字体可以由字形集合组成,每个字形对应于字母表中的特定符号。例如字体包括字母表中每个字符的字形集合。每个字形都有特定的形状和潜在的装饰和着色。包括字体(形状和颜色)的字形将一种字体与另一种字体区分开。
然而,该过程是劳动密集合型的,并且艺术家通常仅设计标题或注释所必需的字形子集,这使得在创建设计之后难以改变文本或者难以将观察到的字体的实例传递到另一个项目。
关于字形合成的早期研究集合中于轮廓的几何建模,其限于特定的字形拓扑(例如不能应用于装饰或手写字形)并且不能与图像输入一起使用。然而,随着深度神经网络的兴起,研究人员开始研究对来自图像中的字形进行建模。这些方案取得了有限的成功。具体地,用于字形合成的已知方案采用了一次生成单个字形的方案。然而,使用这些类型的方案生成的字形的质量在字体上表现出有限的质量和生成的字形的一致性。此外,一些最近的纹理传递技术直接利用字形结构作为引导通道来改进装饰元素的放置。虽然这种方案在干净的字形上提供了良好的结果,但它往往会在自动生成的字形上失败,因为合成处理的工件使得从字形结构获得适当的引导变得更加困难。
因此,对于从部分观察生成字体的整个字形集合的技术是必要的,其中所生成的字形具有高质量并且在内部与字体中的其他字形一致。
附图说明
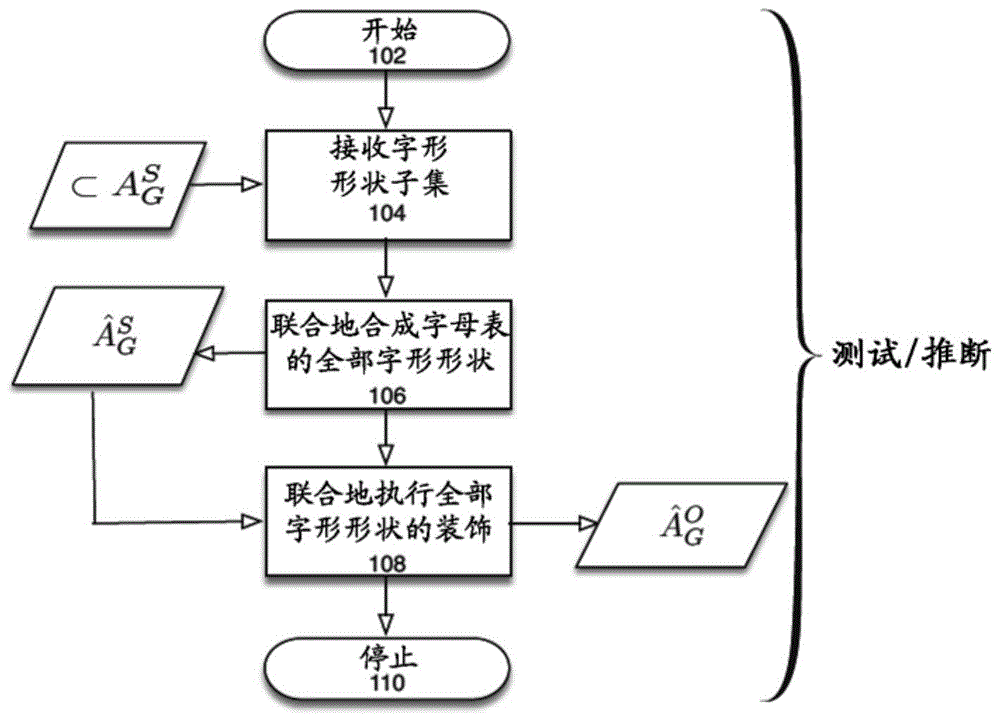
图1a是描绘了根据本公开的一个实施例的在测试或推断时间的多内容生成性对抗网络(mc-gan)的操作的流程图。
图1b是描绘了根据本公开的一个实施例的mc-gan的训练过程的流程图。
图1c是描绘了根据本公开的一个实施例的用于生成glyphnet预训练集合的过程的流程图。
图2a是根据本公开的一个实施例的被配置为在测试或推断时间操作的mc-gan的框图。
图2b是根据本公开的一个实施例的预训练配置中的glyphnet的框图。
图2c是根据本公开的一个实施例的联合训练配置中的mc-gan的框图。
图2d是根据本公开的一个实施例的预训练配置中的glyphnet的详细框图。
图2e是根据本公开的一个实施例的在训练配置中包括glyphnet和ornanet的mc-gan网络的详细框图。
图3a示出了根据本公开的一个实施例的来自数据集合的灰度级的一些示例性字体。
图3b示出了根据本公开的一个实施例的装饰字体的一些示例。
图3c是根据本公开的一个实施例的利用mc-gan模型组件的消融研究。
图3d是示出根据本公开的一个实施例的观察到的字形的数量对glyphnet预测的质量的影响的图。
图4a-4d使mc-gan模型(根据本公开的实施例)与示例集合上的文本传递方法的比较可视化。
图5a示出了根据本公开的一个实施例的执行mc-gan网络的示例计算系统。
图5b示出了根据本公开的一个实施例的mc-gan网络到网络环境的示例集合成。
具体实施方式
基于仅对槽隙内容的部分观察,公开了用于合成槽隙内容的全部集合的技术。如在本公开中所使用的,“槽隙内容”是指可以被组织为位置集合的任意内容,其中每个位置与特定类型相关联。例如对于字体,槽隙可以包括字母表中的特定字母或符号或字形。出于本公开的目的,术语“字母表”将指代字体中的字符或字形(即,字母、数字、特殊字符等)的范围。槽隙内容的其他示例包括表情符号或剪贴画,其中在前一种情况下,每个槽隙可以对应于特定的面部表情或情绪,并且在后一种情况下,每个槽隙可以对应于特定类型的图像或艺术表达。给定集合或字母表或其他槽隙内容中的任意字符或符号或标记在本文中通常可称为字形或装饰字形。
应当理解,神经网络接收输入,处理输入并生成输出。出于本公开的目的,术语“观察”将指的是在神经网络有效地“观察”输入并生成输出的意义上提供给神经网络的输入。术语“部分观察”指的是仅观察到一部分槽隙内容的事实(例如仅对应于来自字母表的字母子集的少数字形)。例如相反,如果槽隙内容是“完整观察”,则相关字母表中的每个字形将被“观察”或作为输入提供给神经网络。通常,期望生成与槽隙内容相对应的实体的全部集合(即,与每个未观察到的槽隙有关的内容)。未观察到的插槽可以视为漏洞或缺少信息。
用于合成生成字形的已知技术通常一次执行一个字符。如前所述,最近的纹理传递技术直接利用字形结构作为引导通道来改进装饰元素的放置。虽然这种方案在干净的字形上提供了良好的结果,但它往往会在自动生成的字形上失败,因为合成程序的工件使得从字形结构获得适当的引导变得更加困难。因此,因此希望一次生成字形的完整集合,其中合成过程可以在字体中的所有字符上绘制全部信息范围。但是,在许多情况下,字形的全部集合不可用。因此,如本文中不同地提供的从部分观察生成装饰字形的全部集合的能力可能是有益的。
根据本公开的一个实施例,槽隙内容可以是字符字体,由此字体中的字形包括槽隙内容。在该上下文中,部分观察可以包括所有字形的子集,其包括字体。如前所述,术语“部分观察”指的是如下事实,与字母表的字形的全部集合相反,仅提供字母表的字形的子集作为神经网络的输入。例如根据本公开的一个实施例,可以从对该字体的字形的部分子集(例如仅字母“t”、“o”、“w”、“e”和“r”)的观察来合成字体的字形的完整集合。相反,如果提供“完全观察”,则字母“a”-“z”中的每个字符将被提供作为神经网络的输入。
从如本文定义的部分观察生成装饰字形的全部集合提出了许多技术挑战。根据本公开的一个实施例,通过利用两个单独的网络来解决这些技术挑战,一个用于形状(glyphnet)的生成而另一个用于装饰(ornanet)。使用对抗损失函数结合l2和l1损失函数集合来训练网络,以强制执行与训练集合的基础真值相关的各种条件。这些架构和训练特征有助于网络的功能,以从本文定义的部分观察中生成装饰字形的全部集合。
根据本公开的一个实施例,使用大量字体来训练深度学习架构。在训练过程期间,从字体集合生成包括部分观察的训练示例集合。根据一个这样的实施例,每个训练示例是部分观察,其可以包括来自字母表和基础真值标签的字符子集,其是黑白格式的字形字符的完整集合。
现在将描述深度学习处理的高级概述。在推理时,接收来自特定字体的字形的子集。基于该输入,与输入字体相对应的字母表中的所有字形以黑白格式联合生成。然后对生成的字形集合进行装饰(例如着色)以生成最终字形字体。
根据本公开的一个实施例,深度神经网络架构用于从少数图像示例自动合成损失的字形。具体地,根据一个这样的实施例,利用条件生成性对抗网络(“cgan”)架构来仅使用少数观察到的字形为每个观察到的字符集合重新训练定制网络。
根据一些实施例,深度神经网络以两个阶段操作,每个阶段具有相关联的网络部分,以自动合成字形。在本文称为字形形状合成的第一阶段中,对整体字形进行建模。在本文称为字形装饰的第二阶段中,执行合成字形的最终外观的合成,由此引入颜色和纹理,从而能够传递精细装饰元素。第一阶段可以实现为字形生成网络,第二阶段可以实现为装饰网络。
根据一些这样的实施例,利用字形生成网络联合训练装饰网络,允许装饰合成过程以学习如何用颜色和纹理来装饰自动生成的字形,并且还解决在字形生成期间出现的问题。
根据一些实施例,同时合成字体的所有字形。与一次生成单个字形的先前的方法相比,同时生成导致显着更高质量的字形。这种同时生成所有字形的方案需要特定的训练操作,这将在下面描述。
鉴于本公开,将理解许多配置。例如在一个特定实施例中,通过利用字形生成阶段,接着是纹理传递阶段,来从部分观察(从作为观察者的glyphnet的角度)合成新的字体字形。具体地,字形生成阶段由第一网络执行,在本文中称为“glyphnet”,而纹理传递阶段(第二阶段)由第二网络执行,在本文中称为“ornanet”(装饰)。基于观察到的字形掩模的部分集合的处理,glyphnet可以预测字形掩模的全部集合,然后将其作为输入提供给ornanet。通过对生成的字形进行微调、着色和装饰,ornanet可以处理由glyphnet生成的字形掩模的预测完整集合。
根据一些这样的实施例,glyphnet和ornanet可以组合为复合网络中的子网络,在本文中称为“mc-gan”(“多内容生成性对抗网络”),其包括用于从部分观察中合成新字体字形的端到端网络,其中如前所述,glyphnet和ornanet充当观察者。根据一个这样的实施例,glyphnet和ornanet都利用cgan网络架构,该架构适合于对字形或装饰预测进行样式化的目的。将会理解其他实施例。
图1a是描绘了根据本公开的一个实施例的在测试或推断时间的mc-gan的操作的流程图。下面将详细描述用于训练mc-gan的技术以及mc-gan的示例结构。图1a中所示的过程可以用于接收部分字形集合(观察到的字形)作为输入并且为特定字体生成装饰字形完整的集合(即,字母表中的所有字形),如下所示:
遵守以下符号约定。a指的是字母表。上标s或o分别指形状或装饰。加帽变量是指由mc-gan网络(glyphnet或ornanet)生成的实体。因此,例如
参考图1a,该过程在102中开始。在104中,字形形状的子集
对应于字体作为输入被接收。字形形状的子集可以是与字体相关联的字母表(a)中的字形的子集。将理解,字母表指的是特定上下文中的整个符号集合。例如在某些上下文中,字母表可以包括大写和小写字符,而在其他情况下,字母表可以仅包括例如小写字符。在其他情况下,字母表不仅可以包括字符,还可以包括数字和其他特殊符号。输入字形形状在本文中称为观察到的字形,而字母表中的缺失形状在本文中称为未观察到的字形形状。
根据本公开的一个实施例,字形形状可以包括字形的黑白像素数据或灰度像素数据。此外,可以使用适当的变换从完全风格化/彩色化的字形的彩色图像数据导出输入字形。具体地,根据本公开的一个实施例,可以将用于字形的彩色图像数据转换为灰度图像数据。随后,可以对灰度图像执行下采样操作以适应特定的期望图像尺寸。根据本公开的一个实施例,可以用空白数据(例如0)填充未观察到的字形形状。
例如根据本公开的一个实施例,对应于包括整个字母表‘a’-‘z’的子集的字母‘t’、‘o’、‘w’、‘e’和‘r’的字形形状可以被接收。基于这5个字形形状,可以生成整个字母表的装饰字形的完整集合。
在106中,字母表的所有字形形状是从104中接收的字形形状的子集联合合成的。具体地说:
根据本公开的一个实施例,使用glyphnet网络从部分观察生成字形形状的全部集合。下面描述glyphnet的示例结构和功能。然而,出于本讨论的目的,足以认识到glyphnet可以包括利用对抗损失函数的cgan,其可以与其他损失函数结合使用。
在108中,用于字母表的装饰字形的全部集合是从106中生成的字形形状的完整集合联合合成的,如下所示:
根据本公开的一个实施例,字形形状的装饰可以由ornanet执行,这将在下面详细描述。该过程在110结束。
图1b是描绘了根据本公开的一个实施例的mc-gan的训练过程的流程图。该过程在120中开始。在122中,生成对字体集合的部分观察glyphnet预训练集合。下面参考图1c描述用于生成部分观察glyphnet预训练集合的过程。出于本公开的目的,将足以认识到部分观察glyphnet预训练集合中的每个训练示例可以包括来自所选字体的一些任意数量的观察到的字形形状以及对应于作为空白(即0)的未观察到的字形的形状的其余部分。根据本公开的一个实施例,可以从不同的字体生成每个训练示例。也就是说,对于每个训练示例,可以从随机选择的字体生成观察到的字形形状的每个集合。在124中,使用122中确定的训练集合在glyphnet上执行预训练过程。将认识到训练过程将学习网络的参数集合。应当理解,所学习的参数可以包括用于网络的多层感知器部分的权重和偏差,用于网络的卷积部分的卷积内核或其他参数。如前所述,glyphnet的结构和相关的损失函数将在下面描述。出于本公开的目的,足以认识到预训练过程可以利用与梯度下降耦合的反向传播算法。
在126中,将利用在预训练步骤(124)中确定的参数来初始化glyphnet。在128中,将在该字体集合上生成部分观察联合训练集合。在130中,将使用在128中生成的部分观察联合训练集合在glyphnet和ornanet(mc-gan)的复合网络上执行联合训练过程。下面将描述mc-gan网络的结构。出于本公开的目的,将足以认识到mc-gan网络可以利用与附加损耗函数耦合的一个或多个cgan架构。mc-gan网络的联合训练将执行124中确定的glyphnet参数的进一步完善以及ornanet网络的最终参数。该过程在132结束。
图1c是描绘了根据本公开的一个实施例的用于生成glyphnet预训练集合的过程的流程图。该过程在140中开始。在142中,确定是否已生成所有训练示例。如果是(142的“是”分支),则过程在148结束。如果不是(142的“否”分支),则流程继续144,其中选择随机字体。根据本公开的一个实施例,可以从任意数量的现有字体(例如10000)生成预训练集合。在146中,从所选字体中选择任意数量的随机字形。对于每个训练示例,随机字形的数量可以是固定的,或者可以针对每个训练示例随机选择随机字形的数量。例如根据一个实施例,可以为特定字体选择对应于字母‘t’、‘o’、‘w’、‘e’和‘r’的字形。通常,用于生成训练示例的字体集合可以被装饰(包括彩色图像数据的程式化和着色字体),在148中,146中选择的字形可以被转换为黑白图像。根据本公开的一个实施例,可以首先将字形转换为灰度而不是纯黑白图像。在这种情况下,根据一个实施例,为每个训练示例选择的n个字形可以是灰度图像。在150中,生成字母表中剩余字形的占位符。例如如果在146中选择了与字母‘t’、‘o’、‘w’、‘e’和‘r’对应的字形,则在150中,为字母表中的其余字符生成占位符(即‘a’-‘d’、‘f’-‘n’、‘p’-‘q’和‘s’-‘z’)。根据本公开的一个实施例,占位符可以包括用于图像数据的0。然后流程继续142。
生成性对抗网络
深度学习试图发现丰富的分层模型,其表示在人工智能应用中遇到的各种数据的概率分布,诸如自然图像、包含语音的音频波形和自然语言语料库中的符号。在深度学习中的许多早期成功涉及辨别模型,通常是那些将高维度、丰富的感官输入映射到类别标签的模型。这些早期的成功主要基于反向传播和损失算法,使用具有特别良好的行为梯度的分段线性单元。由于难以近似在最大似然估计和相关策略中出现的许多难以处理的概率计算,并且由于难以在生成性上下文中利用分段线性单元的益处,因此深度生成性模型具有较小的影响。gan通过引入生成性模型估计程序来解决这些问题中的一些,该程序避开了许多这些困难。
在gan框架中,生成性模型与对手进行对抗。特别地,判别模型学习确定样本是来自模型分布还是来自数据分布。生成性模型可以被认为类似于造假者团队,试图生产虚假货币并在没有检测的情况下使用它,而判别模型类似于警察,试图检测伪造货币。在这个游戏中的竞争促使两个团队改进他们的方法,直到伪造与真正的物品无法区分。
为了学习生成器在数据x上的分布pg,在输入噪声变量pz(z)上定义先验。然后定义到数据空间的映射g(z,θg),其中g是由具有参数θg的多层感知器表示的可微函数。然后定义第二多层感知器d(x,θd),其输出单个标量。d(x)表示x来自数据而不是pg的概率。然后训练d以最大化为训练样本和来自g的样本分配正确标签的概率。同时,训练g以最小化log(1-d(g(z))。有效地,d和g玩以下具有值函数v(g,d)的双人迷你极限游戏:
条件生成性对抗网络
如果生成器和判别器两者均以某些额外信息y为条件,则生成性对抗网络可以扩展到条件模型。y可以是任意类型的辅助信息,诸如类标签或来自其他模态的数据。可以通过将y馈入判别器和生成器两者作为附加输入层来执行调节。在生成器中,先前的输入噪声pz()和z被组合到联合隐藏表示,并且对抗训练框架允许在如何组成该隐藏表示中的相当大的灵活性。在判别器中,x和y被表示为输入和判别功能(在这种情况下由mlp(“多层感知器”)体现)。使用cgan框架的双人迷你极限游戏的目标函数可表示为:
mc-gan模型
根据本公开的一个实施例,mc-gan模型可以包括两个子网:用于合成字形形状的glyphnet和用于执行由glyphnet生成的字形形状的合成装饰的ornanet。如下面将更详细描述的,包括mc-gan模型的glyphnet和ornanet可以在训练期间各自分别使用cgan模型。关于合成图像的生成,从随机噪声矢量z开始,gan训练模型以生成图像y,通过对比训练生成器与判别器(z→y)来遵循特定分布。当判别器试图区分真实和虚假图像时,生成器通过试图生成逼真的图像来对抗判别器。在条件(cgan)场景中,通过将观察到的图像x与随机噪声矢量一起馈送到生成器({x,z}→y)来修改该映射。根据本公开的一个实施例,生成器和判别器之间的对抗过程可以被表述为以下损失函数:
这里g和d分别最小化和最大化该损失函数。
给定生成器的基础真值输出,除了欺骗判别器之外,迫使模型通过l1损失函数生成接近其目标的图像也是有益的。根据本公开的一个实施例,生成器的目标可以总结如下:
其中
如下面将更详细描述的,根据本公开的一个实施例,通过设置子网(glyphnet和ornanet)中的每一个以通过仅观察馈入作为堆栈x的仅一些示例来生成字母表的整个字母集合来调用该cgan模型。根据本公开的一个实施例,忽略随机噪声作为生成器的输入,并且损失是网络中随机性的唯一来源。
mc-gan测试/推断架构
图2a是根据本公开的一个实施例的被配置为在测试或推断时间操作的mc-gan的框图。出于本公开的目的,假设mc-gan已经如本公开中关于图1a-1c和图2b-2d所描述的那样进行了训练。具体地,如图2a所示,mc-gan290执行以下操作:
也就是说,mc-gan290可以从对应于字体的字母表接收字形形状的子集(部分观察),并联合合成字母表的装饰字形的全部集合。因此,根据本公开的一个实施例,mc-gan290可以从部分观察中合成字形的全部集合。如图2a所示,mc-gan290还可以包括glyphnet282和ornanet284。
根据本公开的一个实施例,glyphnet282可以执行以下操作:
glyphnet282可以进一步包括字形形状生成器网络gs,其从部分观察联合生成字母表的全部字形形状。
根据本公开的一个实施例,ornanet284可以执行以下操作:
具体地,ornanet可以从glyphnet282接收合成的字形集合作为输入,并合成用于字母表的装饰字形的完整集合。如图2a所示,ornanet284可以进一步包括字形纹饰生成器网络go,其从字形形状联合生成具有用于字母表的装饰的所有字形。
图2b是根据本公开的一个实施例的预训练配置中的glyphnet的框图。如下面将更详细描述的,根据本公开的一个实施例,在执行mc-gan290(即,glyphnet282和ornanet284)的联合训练阶段(下面描述)之前,预先训练glyphnet282。如图2b所示,在预训练阶段期间,glyphnet282还可以包括形状生成器网络(g1)、形状判别器网络(d1)和损失函数模块
图2c是根据本公开的一个实施例的联合训练配置中的mc-gan的框图。具体地,图2c涉及glyphnet282和ornanet284的联合训练。在联合训练操作期间,mc-gan290可以执行以下操作:
具体地,mc-gan290可以接收字形形状的子集(部分观察)并且合成整个字母表的装饰字形的全部集合。根据本公开的一个实施例,在mc-gan290的联合训练之前,使用在glyphnet282的预训练期间确定的参数来初始化glyphnet282。
如图2c所示,在mc-gan290的联合训练阶段期间,glyphnet282可以进一步包括形状生成器网络(g1)和损失函数模块
glyphnet
图2d是根据本公开的一个实施例的预训练配置中的glyphnet的详细框图。如下面将更详细描述的,一旦完成预训练操作,可以在联合配置(mc-gan290)中进一步训练glyphnet282和ornanet284。在完成训练后,glyphnet282和ornanet284可用于端到端配置,以基于部分观察执行字体/字形的生成。glyphnet282子网可以基于字体的观察输入形状示例的子集生成字母表的形状的全部集合。如下面将更详细描述的,ornanet子网络284可以在glyphnet的输出(形状的完整集合)上操作以生成装饰字形的完整集合。
从几个示例字形概括字体的所有26个大写字母需要捕获源字母和看不见的字母之间的相关性和相似性。根据本公开的一个实施例,glyphnet282可以自动地学习相关性,以便从如先前定义的包括整个字母表的字形的子集的部分观察生成风格上类似的字形的整个集合。
由于所有内容图像之间的样式相似性,为每个单独的字形添加一个输入通道,从而在输入和生成的输出中产生“字形堆栈”。然而,将所有26个字形基本平铺成单个图像无法捕获它们之间的相关性,具体地针对沿图像长度彼此远的那些。这是由于卷积接收场的尺寸小于合理数量的卷积层内的图像长度而发生的。
为了解决这个问题,跨网络信道学习不同字形之间的相关性,以便自动地传递它们的样式。这是经由生成器(g1)204特定架构设计来实现的,其利用六个resnet块。具体地,根据本公开的一个实施例,字母表中的所有字形(例如26)在输入的单个卷积信道中堆叠在一起,该输入允许网络学习字形内和字形之间的空间相关性。下面详细描述glyphnet282的全部架构规范。
根据本公开的一个实施例,利用灰度级的64×64字形,导致26个大写英文字母的输入张量维度bx26x64x64204,其中b表示批量大小,输出张量维度为bx26x64x64214。根据本公开的一个实施例,形状判别器网络d1包括局部判别器218和全局判别器220。利用patchgan模型,在所生成的输出栈顶部采用三个卷积层来应用21×21局部判别器218,以便区分导致接收场大小等于21的真实和虚假的局部补片。并行地,添加两个额外的卷积层以用作全局判别器220,从而产生覆盖整个图像的感知场以区分真实字体图像和生成的字体图像。尽管图2d示出了单个判别器网络d1内的局部判别器218和全局判别器220,但是应该理解,其他布置是可能的,并且局部判别器218和全局判别器220可以不在单个网络中组合。
根据一个实施例,为了稳定gan训练,两个最小二乘gan(lsgan)损失函数分别用于局部和全局判别器(218,220),具有生成的图像g1(x1)与其基础真值y1的l1损失惩罚偏差:
其中
为了执行上述损失函数,如图2d所示,虚假对连接节点208执行输入张量204和合成输出张量214的连接,其被提供给判别器d1。类似地,实对连接节点210执行输入张量204和基础真值张量212的连接,其被提供给判别器d1。l1损失块216基于基础真值张量212和合成输出张量214来生成l1损失度量。
根据本公开的一个实施例,可以在收集的10k字体数据集合上训练glyphnet282,其中在每次训练迭代中,x1包括随机选择的y1字形的子集,其中其余输入通道归零。出于本公开的目的,该训练模型被称为g′1。
ornanet
根据本公开的一个实施例,第二子网络ornanet284被设计为通过由生成器g2和判别器d2组成的另一个条件gan网络来将少数观察到的字母的装饰传递到灰度字形。将字形作为输入图像x2馈入,该网络生成输出g2(x2),富含理想的颜色和装饰。
根据本公开的一个实施例,ornanet284和glyphnet282可以利用类似的架构,但是可以在输入和输出的维度和类型方面不同,以及各个模型在生成具有特定风格的图像时的广泛性与特定性有何不同。虽然glyphnet282被设计为概括跨我们所有训练字体的字形相关性,但ornanet284可能专门用于仅应用在给定观察字体中观察到的特定装饰。因此,ornanet可能仅针对可用的少量观察进行训练。此外,ornanet284的输入和输出可以包括具有三个rgb通道的一批图像,其中输入通道是灰度字形的相同副本。
mc-gan(端到端)网络
图2e是根据本公开的一个实施例的在训练配置中包括glyphnet和ornanet的mc-gan网络的详细框图。mc-gan290可以操作用于将观察到的字形的样式和装饰推广到未观察到的字形。
参考图2e,在训练配置中操作的mc-gan290可以进一步包括glyphnet282和ornanet284。glyphnet282还可以包括生成器g1和l1损失模块236。l1损失模块236可以操作以在执行提取操作后比较基础真值232和生成器g1的输出,基础真值是尺寸1x26x64x64的张量(如下所述)。
留出一个采样
与包括观察到的字母表的字母表相对应的所有字形(例如,26个仅小写字符)通过预训练的glyphnet282被处理,并被馈送到ornanet284(用随机权重初始化)以进行微调。根据本公开的一个实施例,利用留一法。因此,如图2e所示,根据本公开的一个实施例,尺寸(n+1)x26×64×64的输入张量被提供给glyphnet282中的生成器g1,其中n指的是观察到的字形的数量。参数n+1出现是因为留出一个采样创建了一个批处理,其中省略了0-n个字母。也就是说,留一法通过所有可能未被观察到的字母循环。例如给定图2e中所示的单词tower的5个观察字母,前4个字母‘t’、‘o’、‘w,‘e’被组装成1x26x64x64输入堆栈并馈送到预先训练的glyphnet282以生成所有26个字母。然后,提取未包括在输入堆栈中的一个虚假字形“r”。然后可以重复该过程以从预先训练的glyphnet生成所有5个观察到的字母(‘t’、‘o’、‘w,‘e’、‘r’)。
类似地,继续相同的示例,剩余21个字母(‘a’-‘d’、‘f’-‘n’、‘p’-‘q’、‘r’-‘v’和‘x’-‘z’)通过馈入1x26x64x64输入堆栈来从预先训练的glyphnet282中提取,输入堆栈被同时填充所有5个观察到的字母,其中其余通道归零。整个过程可以通过以下各项来进行总结:传递6个输入堆栈通过glyphnet作为批处理,每个输入堆栈具有1x26x64x64的尺寸,从每个输出堆栈中提取相关通道,并且最后将它们连接成单个1x26x64x64输出。
重塑变型
根据本公开的一个实施例,然后可以通过符号τ进行符号化并来执行整形变换,随后进行灰度信道重复。具体地,根据本公开的一个实施例,灰度通道重复将由重塑操作生成的张量对象重复为具有尺寸3x64x64的新输入张量中的三个单独通道,其作为批量x2被馈送到ornanet284。这种留一法使ornanet284能够从粗略生成的字形生成高质量的程式化字母。
mc-gan损失函数
根据本公开的一个实施例,为了稳定ornanet284生成器(g2)和判别器(d2)的对抗训练,可以采用lsgan损失并且对所观察到的字母x2以及它们的基础真值y2的生成图像的l1损失函数耦合。另外,根据本公开的一个实施例,为了生成具有清晰轮廓的彩色图像集合,ornanet284中生成器的输出和输入的二进制掩模之间的均方误差(“mse”)可以使用相关的损失函数来被最小化,该输出和输入分别为虚假彩色的字母g2(x2)和虚假灰度字形x2。根据本公开的一个实施例,可以通过使图像通过s形函数来获得二进制掩模,如图2e中的σ所示。
因此,根据本公开的一个实施例,在端到端场景中应用于ornanet之上的损失函数可以被写为:
其中x2=τ(g1(x1))以及
根据本公开的一个实施例,在glyphnet282和ornanet284的最终端到端训练中,不调用glyphnet判别器(d1)。相反,ornanet284通过反向传播目标的梯度(上面的等式)来起到损失函数的作用,以改进生成的字形的样式。
在glyphnet282(g1)中在生成器的顶部添加加权l1损失也处理与预训练的glyphnet282(g′1)的预测的偏差。根据本公开的一个实施例,可以在所观察的字形(τ(g1(x1)))的虚假版本的二进制掩模与其对应的基础真值字形y2的掩模之间添加mse损失函数。总之,除了源自ornanet284的梯度之外,以下损失函数的梯度还通过glyphnet282传递:
其中wi允许对观察到的与未观察到的字形应用不同的权重。根据本公开的一个实施例,基于超参数λ1-λ4来定义参考损失函数(前两个等式)中的不同项之间的比率。
具体地,上述损失函数可以在mc-gan网络中实现,如图2e所示。ornanet284还可以包括生成器g2、判别器d2,其利用lsganlocal和lsganglobal损失函数248、l1损失模块246和mse损失模块242和244。具有超参数λ2的第一mse损失函数242强制执行生成器g2不应该改变掩模的条件。注意,图2e中所示的σ函数将彩色图像转换为黑白。具有超参数λ4的第二mse损失函数244强制执行在应用掩模之后glyphnet282的输出应该与基础真值的掩模匹配的条件。l1损失模块246强制执行生成器的输出g2应该与基础真值相匹配的条件。
网络架构
根据本公开的一个实施例,生成器(编码器-解码器)架构基于j.johnson、a.alahi和l.fei-fei的实时样式传递和超分辨率的感知损失。在欧洲计算机视觉会议,第694-711页,springer,2016.2,3,16。由k个通道构成的convolution-batchnorm-relu使用crk、具有ck的convolution-batchnorm层、具有crdk的convolution-batchnorm-relu-dropout、和具有clk的convolution-leakyrelu表示。在上述表示法中,所有输入通道都被卷积到每层中的所有输出通道。
根据本公开的一个实施例,可以采用另一个convolution-batchnorm-relu块,其中每个输入通道与其自己的滤波器集合卷积并由cr26k表示,其中26表示这样的组的数量。训练期间的信号丢失(“dropout”)为50%,而在测试时被忽略。leakyrelu的负斜率也设置为0.2。
生成器架构
根据本公开的一个实施例,glyphnet中的编码器架构是:cr2626-cr64-cr192-cr576-(crd576-c576)-(crd576-cr576)-(crd576-c576),其中卷积是由因子分别为1-1-2-2-1-1-1-1-1-1的下采样,并且每个(crd576-c576)对是一个resnet块。
根据本公开的一个实施例,ornanet中的编码器遵循类似的网络架构,除了在其已经消除了cr2626的第一层中之外。
glyphnet和ornanet中的解码器架构如下:
(crd576-c576)-(crd576-c576)-(crd576-c576)-cr192-cr64各自分别由1-1-1-1-1-1-2-2因子进行上采样。然后在解码器的最后一层中应用具有26个通道接着是tanh单元的另一个卷积层。
判别器架构
根据本公开的一个实施例,glyphnet和ornanet判别器d1和d2由局部和全局判别器组成,其中局部判别器的权重与后者共享。局部判别器由cl64-cl128组成,然后是将其128个输入通道映射到一个输出的卷积。这里的卷积分别由因子2-1-1进行下采样。全局判别器在连接局部判别器中的层之前有两个附加层,因为cr52-cr52各自由因子2进行下采样。局部判别器的接收场大小为21,而全局判别器覆盖图像域中比64个像素大的区域,因此可以从每个图像捕获全局信息。
字体数据集合
根据本公开的一个实施例,组装了包括10k灰度拉丁字体的数据集合,每个拉丁字体具有26个大写字母。通过确定每个字形周围的边界框并调整其大小以使较大尺寸达到64像素来处理数据集合。然后执行填充操作以创建64x64字形。图3a示出了根据本公开的一个实施例的来自数据集合的灰度中的一些示例性字体。这些字体包含有关字体样式中字母间相关性的丰富信息,但仅编码字形轮廓而非字体装饰。为了创建装饰字体的基线数据集合,可以将随机颜色渐变和轮廓应用于灰度字形,每种字体上有两个随机颜色渐变,从而产生20k颜色的字体数据集合。图3b示出了根据本公开的一个实施例的装饰字体的一些示例。
通过生成更多随机颜色,可以任意增加该数据集合的大小。这些渐变字体与自然环境下的装饰的分布不同,但可用于诸如网络预训练的应用。
实验和结果
使用以下超参数设置进行各种实验:
如果epoch<200,则λ1=300,λ2=300,否则λ2=3
根据本公开的一个实施例,实现了基线图像到图像转换网络。在这种基线方案中,考虑了尺寸为bx78x64x64的输入和输出堆栈中的通道字母,其中b代表训练批量大小,78对应于26个rgb通道。输入堆栈以“观察”颜色字母给出,而所有字母都在输出堆栈中生成。
根据本公开的一个实施例,在彩色字体数据集合上训练网络,其中在每个灰度字体上应用随机选择的颜色梯度。在测试时间期间,将任意字体的rgb字母的随机子集馈入该模型中,期望网络生成类似于26个字母的风格。
图3c是根据本公开的一个实施例的利用mc-gan模型组件的消融研究。对于每个示例字体,显示以下项目:
基础真值(第1行)
观察到的字母(第1行中的红色方块)
基线图像转换网络的预测(第2行)
具有随机初始化(ri)ornanet和λ2=λ3=λ4=0来对mc-gan模型的预测(第3行)
预训练(pt)ornanet权重和λ2=λ3=λ4=0(第4行)
有选择地禁用损失项(第5-7行)
完整的端到端mc-gan模型(底行)
由λ3的样式传递改进以蓝色突出显示,并且以红色突出显示通过省略每个单独的正则化器的预测中的降级。
如图3c所示,虽然网络已经学习了字形结构的粗略方面,但是预测不遵循一致的颜色或装饰方案,因为网络不能有效地专门用于所提供的装饰风格。即使在从简化的颜色梯度数据集合导出的测试集上进行评估时,也观察到类似的伪像。
图3d是示出了根据本公开的一个实施例的观察到的字形的数量对glyphnet预测的质量的影响的图。图中示出的红线穿过每个分布的中位数。
感知评估
为了评估mc-gan模型的性能,将生成的mc-gan字母与基于贴片的合成方法的输出进行比较。由于基于补片的合成模型仅被设计用于在干净的字形上传输文本装饰,因此它与合成未观察到的字母的mc-gan方法不完全可比。为了探索基于补片的合成模型,预训练的glyphnet的预测被用作该算法的输入。此外,基于补片的合成模型仅从一个输入装饰字形传递风格化,而mc-gan方案同时使用所有观察到的示例。因此,为了在传递装饰中实现公平比较,允许基于补片的合成模型使用简单的图像空间距离度量在所观察的实例中选择与生成的字形掩模最相似的字形。
两种方法的输出在33个字体示例上被评估,从web被下载。具体地,当观察到的字母和两种方法的全部字形结果被呈现时,11个人被要求选择他们喜欢的字符集合。
总体用户在80.0%的时间内优选mc-gan方法的结果。图4a-4d示出了根据本公开的一个实施例的mc-gan模型与文本传递方法在示例集合上的比较。具体地,基础真值和给定字母(第一行),文本效果传递方法的预测被应用于我们的glyphnet合成的字形之上(第二行),以及mc-gan模型的预测(最后一行)。每个方法的两个最佳得分和两个最差得分结果显示在顶部和底部示例中。文本传递方案被设计为生成干净字形上的文本模式,但在给定合成灰度字母的情况下,大多数情况下无法传递样式。另外,由于它们依赖于基于补片匹配的算法,当给定字母和新字母的形状不是非常相似时,文本传输方案通常不能正确地传递样式。
计算系统与网络环境的集成
图5a示出了根据本公开的一个实施例的执行mc-gan网络290的示例计算系统。如图5a中所描绘的,计算设备500可以包括cpu504,其执行一个或多个过程以实现mc-gan网络290。具体地,cpu504可以进一步经由编程指令来被配置以执行mc-gan网络290(如本文各种描述的)。诸如例如协处理器、处理核、图形处理单元、鼠标、触摸板、触摸屏、显示器等的计算系统的典型的其他组件和模块未被示出但是将是显而易见的。鉴于本公开,许多计算环境变化将是显而易见的。计算设备500可以是任意独立的计算平台,诸如桌面或工作站计算机、膝上型计算机、平板计算机、智能电话或个人数字助理、游戏控制台、机顶盒或其他合适的计算平台。
图5b示出了根据本公开的一个实施例的mc-gan网络到网络环境的示例集集成。如图5b所示,计算设备500可以在云环境、数据中心、局域网(“lan”)等中处于同一位置。图5b中所示的计算设备500的结构与关于图5a描述的示例实施例完全相同。如图5b所示,客户端应用512可以经由网络510与计算设备500交互。具体地,客户端应用512可以经由在api服务器506处接收的api调用来发出请求和接收响应,这些api调用经由网络510和网络接口508被发送。
应当理解,网络510可以包括任意类型的公共或专用网络,其包括因特网或lan。将进一步容易理解,网络510可以包括任意类型的公共和/或专用网络,包括因特网、lan、wan或这些网络的某种组合。在该示例情况下,计算设备500是服务器计算机,并且客户端应用512可以是任意个人计算平台。
如将进一步理解的,计算设备500,无论是图5a或65中所示的计算设备,包括和/或以其他方式访问一个或多个非暂态计算机可读介质或存储设备,其上编码有用于实现本公开中以各种方式描述的技术的一个或多个计算机可执行指令或软件。存储设备可以包括任意数量的耐用存储设备(例如任意电子、光学和/或磁存储设备,包括ram、rom、闪存、usb驱动器、板载cpu高速缓存、硬盘驱动器、服务器存储装置、磁带、cd-rom或其他物理计算机可读存储介质,用于存储实现本文提供的各种实施例的数据和计算机可读指令和/或软件)。可以使用任意存储器组合,并且各种存储组件可以位于在单个计算设备中或分布在多个计算设备上。另外,并且如前所述,一个或多个存储设备可以与一个或多个计算设备分开地或远程地提供。许多配置都是可能的。
在本公开的一些示例实施例中,本文描述的各种功能模块以及网络340的具体训练和/或测试可以用软件实现,诸如指令集合(例如html、xml、c、c++、面向对象的c、javascript、java、basic等),其被编码在任意非暂态计算机可读介质或计算机程序产品(例如硬盘驱动器、服务器、盘或其他合适的非暂态存储器或存储器集合)上,当由一个或多个处理器执行时,所述软件使得执行本文提供的各种创建者推荐方法。
在其他实施例中,使用基于软件的引擎来实现本文提供的技术。在这样的实施例中,引擎是包括一个或多个处理器的功能单元,所述处理器被编程或以其他方式被配置有编码如本文中不同地提供的创建者推荐过程的指令。以这种方式,基于软件的引擎是功能电路。
在其他实施例中,本文提供的技术用硬件电路实现,诸如门级逻辑(fpga)或专用半导体(例如专用集合成电路或asic)。还有其他实施例用微控制器实现,该微控制器具有处理器、用于接收和输出数据的多个输入/输出端口、以及处理器用于执行本文提供的功能的多个嵌入式例程。在更一般的意义上,可以使用硬件、软件和固件的任意合适的组合,这是显而易见的。如本文所使用的,电路是一个或多个物理组件并且可用于执行任务。例如电路可以是被编程或以其他方式被配置有软件模块的一个或多个处理器,或者是响应于某个输入激励集合来提供输出集合的基于逻辑的硬件电路。许多配置将是显而易见的。
已经出于说明和描述的目的呈现了本公开的示例实施例的前述描述。其并非旨在穷举或将本公开限制于所公开的精确形式。鉴于本公开,许多修改和变体都是可能的。旨在本公开的范围不受该详细描述的限制,而是受所附权利要求的限制。
其他示例实施例
以下示例涉及进一步实施例,来自进一步实施例的许多排列和配置将是显而易见的。
示例1是一种用于合成字体的方法,该方法包括:接收字形形状的部分观察,从所述部分观察生成字形形状的全部集合,以及处理所述字形形状的全部集合以生成装饰字形的全部集合。
示例2是根据示例1的方法,其中所述字形形状的部分观察包括针对字形的黑色和白色掩模。
示例3是根据示例1-2中任一项的方法,其中从所述部分观察生成字形形状的全部集合包括由第一网络处理所述部分观察,所述第一网络使用条件生成性对抗过程而被训练以合成字形形状。
示例4是根据示例3的方法,其中预训练操作使用包括生成性对抗损失和l1损失的组合的损失函数在所述第一网络上被执行。
示例5是根据示例3-4中任一示例的方法,其中处理所述字形形状的全部集合以生成装饰字形的全部集合包括由第二网络处理所述字形形状的全部集合,所述第二网络使用条件对抗过程而被训练以合成字形装饰。
示例6是根据示例5的方法,其中训练操作使用生成性对抗损失函数和l1损失函数、以及所述第二网络上的至少一个均方误差(“mse”)损失函数的组合以端对端配置在第一和第二网络上被执行。
示例7是根据示例1-2中任一项的方法,其中所述装饰字形的全部集合同时被生成。
示例8是一种用于合成字体的系统,包括用于从字形形状的部分观察来生成字形形状的全部集合的第一网络、用于从字形形状集合来生成装饰字形形状的全部集合的第二网络、以及在所述第一和第二网络之间用于执行重塑和灰度重复函数的耦合模块。
示例9是根据示例8的系统,其中所述字形形状的部分观察包括针对字形的黑色和白色掩模。
示例10是根据示例8-9中任一项的系统,其中所述第一网络使用条件生成性对抗过程而被训练以合成字形形状。
示例11是根据示例8-9中任一项的系统,其中所述第二网络使用条件对抗性过程被训练以合成地执行字形形状的装饰。
示例12是根据示例11的系统,其中预训练操作使用包括生成性对抗损失和l1损失的组合的损失函数在所述第一网络被执行。
示例13是根据示例8-9中任一项的系统,其中训练操作使用生成性对抗损失函数和l1损失函数、以及所述第二网络上的至少一个均方误差(“mse”)损失函数的组合以端对端配置在第一网络和第二网络上被执行。
示例14是根据示例8-9中任一项的系统,其中所述装饰字形的全部集合同时被生成。
示例15是一种计算机程序产品,所述计算机程序产品包括被编码有指令的一个或多个非暂态机器可读介质,所述指令在由一个或多个处理器执行时,使得过程被执行以用于合成字体,所述过程包括:接收字形形状的部分观察,从所述部分观察生成字形形状的全部集合,以及处理所述字形形状的全部集合以生成装饰字形的完整集合。
示例16是根据示例15的计算机程序产品,其中所述字形形状的部分观察包括针对字形的黑色和白色掩模。
示例17是根据示例15-16中任一项的计算机程序产品,其中从所述部分观察生成字形形状的全部集合包括由第一网络处理所述部分观察,所述第一网络使用条件生成性对抗过程而被训练以合成字形形状。
示例18是根据示例17的计算机程序产品,其中预训练操作使用包括生成性对抗性损失和l1损失的组合的损失函数在所述第一网络上被执行。
示例19是根据示例17-18中任一个的计算机程序产品,其中处理所述字形形状的全部集合以生成装饰字形的全部集合包括由第二网络处理所述字形形状的全部集合,所述第二网络被使用条件生成性对抗过程而被训练以合成字形装饰。
示例20是根据示例19的计算机程序产品,其中训练操作是使用生成对抗性损失函数和l1损失函数、以及所述第二网络上的至少一个均方误差(“mse”)损失函数的组合以端对端配置在第一和第二网络上被执行。
- 还没有人留言评论。精彩留言会获得点赞!