基于神经网络的命名数据网内容存储池数据插入方法与流程
本发明属于高性能路由器结构设计领域中,特别针对命名数据网转发平面中内容存储池(contentstore)新型存储结构设计及其算法问题。
背景技术:
随着互联网规模的爆炸式增长,创新技术和计算模式的不断涌现,加速了互联网由“通信信道”向“数据处理平台”的角色转变。为了应对互联网内容化、个性化、超高移动性、“零”时延、超高流量密度等未来业务需求,彻底解决当前互联网ip架构下所带来的诸多问题,一种以内容缓存为特色、面向通信内容的命名数据网应用而生。
命名数据网不仅可以通过使用名称数据,实现互联网面向内容的通信模式;还可以通过在路由节点中部署缓冲存储器,缩短用户访问缓存数据的响应时间,实现真正意义上的内容共享,极大地降低网络负载,有效提高网络数据传输速率。因此被认为是未来互联网架构领域最有前景的发展方向之一。
然而命名数据网也面临着一系列亟待解决的问题和挑战[1],特别是路由数据平面中,对于contentstore线速处理支持的问题[2]。命名数据网中路由表的表项数据通常是由数字和字符组成的,并具有变长、无边界特点的字符串来命名,导致contentstore需能够存储数百万规模的数据存储量。此外,contentstore作为临时的内容缓存,其容量有限,所以contentstore需能够高效压缩存储数据以减少存储消耗,并及时进行缓存替换为新插入的数据包清理空间。另外,数据包的名称具有对传输网络不透明的特点。在转发平面中,命名数据网络中的各类应用程序可以在遵守统一命名策略的前提下,根据自己的需求使用不同的名称方案,且contentstore对两种类型的数据包:兴趣(interest)包和数据(data)包,处理过程具有差异性,因此,为完成内容转发,contentstore需能够在各类名称方案下快速支持不同名称数据检索算法[2]。
参考文献:
l.zhangetal.,“nameddatanetworking,”acmsigcommcomputercommunicationreview,vol.44,no.3,pp.66-73,2014.
z.li,y.xu,b,zhang,l.yan,andk.liu,“packetforwardinginnameddatanetworkingrequirementsandsurveyofsolutions,”ieeecommunicationssurveys&tutorials,doi:10.1109/comst.2018.2880444,2018.
技术实现要素:
本发明提供一种的新型存储结构学习位图内容存储池(称之为learnedbitmap-
contentstore,lbm-cs),并给出其插入方法。本发明结合contentstore的工作特点,对学习位图内容存储池存储结构进行优化,使之能够在保证检索效率,提升检索速度,同时支持数据缓存替换策略和所有子名称匹配及精确名称匹配名称数据检索算法基础上,支持数据的插入操作。技术方案如下:
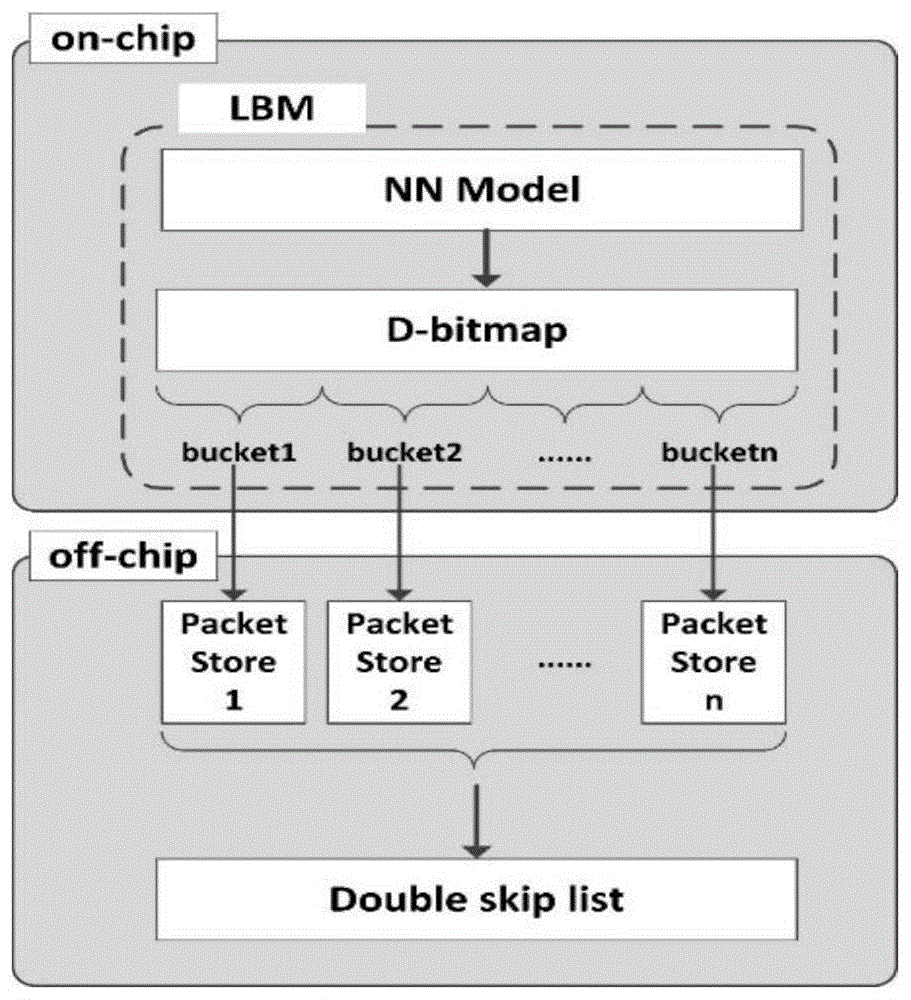
一种基于神经网络的命名数据网内容存储池数据插入方法,所采用的存储池包括:一个片内存储单元和一个片外存储单元,所述片内存储单元使用高速存储器,片内部署一个神经网络模型以实现对数据名称的均匀映射,部署一个改进型位图(d-bitmap)实现将包含相同名称前缀的数据包映射到同一桶(bucket)中;片外存储单元使用低速存储器,其上部署多个与改进型位图的动态索引单元的槽(slot)对应的动态存储器,来存储每个名称前缀的跳表信息,用于指导相同名称前缀data包在双向跳表中的下一次查找,以提高数据检索速度;另部署一个双向跳表结构,以存放数据包在学习位图内容存储池中的存储位置信息,且每个双向跳表节点中存有先入先出队列fifo单指针和最近最少使用lru双指针。
神经网络模型以实现对数据名称的均匀映射过程如下:
首先,神经网络采集样本进行训练,与命名数据网名称数据格式类似的大量统一资源定位符url作为样本数据;其次,计算样本数据的累积分布函数f(x)值作为标签;然后,训练反向传播神经网络,学习出能反映索引数据分布情况的神经网络模型,最后,将数据名称的名称字符串作为输入,输入训练出神经网络模型,得到一个0~1之间的实数值,该数值乘以改进型位图的槽总数,得到映射标号,即实现对数据名称的均匀映射。
双向跳表数据结构设计如下:
双向跳表采用多层结构,且每层由一条双向链表构成,其跳表节点按照名称前缀的id号增序排列。跳表节点间用fifo单指针和lru双指针相连,每个节点中存储有id、指向前向节点指针(prev)和后向节点的指针(next)信息。
动态存储器数据结构设计如下:
动态存储器中记录的内容有:名称前缀、前向节点(prev_nodes)、前向节点地址(next_node_addr)、后向节点(next_nodes)、后向节点地址(next_node_addr)和当前节点(recent_node)。其中名称前缀是从数据包名称<名称前缀,id>中提取出来的;前向节点和后向节点是某个节点在查找时转折的关键节点对,前向节点地址和后向节点地址为节点地址;当前节点为最近刚查找的节点。
在所述存储池中选择最优双向跳表查找节点并确定数据查找方向过程如下:
利用动态存储器中的节点信息:名称前缀、前向节点、前向节点地址、后向节点、后向节点地址和当前节点,选择最优双向跳表查找节点并确定查找方向过程如下:
对于有相同名称前缀的数据j,首先比较j的id和当前节点的id大小,如果id<当前节点的id,则从前向节点中依据id号选择与数据j最近的折返节点作为最佳开始查找节点;如果id>当前节点的id,则从后向节点中选取依据id号选择与数据j最近的折返节点作为最佳开始查找节点。若选择的最佳开始节点的id小于j的id,则从最佳开始节点向后查找,否则,从最佳开始节点向前查找。并且在数据查找过程中,及时更新以上记录的节点信息。
在所述存储池中插入data包,每插入一个data包的步骤如下:
步骤1:输入data包名称前缀和id:输入data包的名称前缀和id
到学习位图内容存储池存储结构中。
步骤2:精确名称匹配:在学习位图中对该名称前缀直接进行映射操作。
步骤3:计算映射标号:该名称前缀经神经网络运算得到一个0~1之间的索引映射值,该值乘改进型位图的槽总数,得出该data包映射到改进型位图上的映射标号。
步骤4:计算基地址和偏移地址:由映射标号除以每个桶的槽总量取整得到该名称前缀所在的桶序号即为基地址,名称前缀进入该桶的顺序号为该名称前缀的偏移地址。
步骤5:判断改进型位图中是否存在该名称前缀:若偏移地址所指向的槽中值不为0,则证明改进型位图中存在该名称前缀,执行步骤6,否则,证明不存在该名称前缀,执行步骤10。
步骤6:访问动态存储器:由该名称前缀经学习位图训练映射后得到的基地址和偏移地址来访问动态存储器。
步骤7:在双向跳表中查找data包:选择最优双向跳表查找节点并确定查找方向,在双向跳表中查找data包。
7-1:输入数据x的名称前缀和id:将数据x的名称前缀和id号输入到双向跳表,此时数据x的id记为id1,且假设id1是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-2:头结点查找:按照传统跳表的查找方式,从双向跳表跳表中的头节点最高层开始向后查找,并将查找路径节点信息记录与动态存储器中,并继续步骤8。
7-3:输入数据y的名称前缀和id:将与数据x有相同前缀的数据y的名称前缀名称前缀和id号输入到双向跳表输入,并提取数据y的id号记为id2,假设输入的y不是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-4:选择最佳开始查找节点及查找方向:如果id1大于id2,则从记录在动态存储器中前折返节点中选择id值相差最小的节点作为最佳节点,否则,从后折返节点中选择id值相差最小的节点作为最佳节点。
7-5:查找双向跳表:从最佳开始查找节点按照查找方向进行查找,同时更新动态存储器中记录的折返节点信息。
步骤8:判断双向跳表中是否存在该data包:在双向跳表中查找与id号对应的data包,若未找到id相同的节点,则说明不存在该data包,则执行步骤9,否则,执行步骤11。
步骤9:插入双向跳表:按照id号增序将该data包插入双向跳表,并将名称前缀记录与动态存储器中,并继续执行步骤11。
步骤10:创建双向跳表:对该名称前缀新建一个双向跳表,将该数据插入跳表中,并将名称前缀记录与动态存储器中,并继续执行步骤11。
步骤11:data包在学习位图内容存储池结构中的插入结束。
在所述存储池中双向查找名称数据,每查找一次名称数据的步骤如下:
步骤1:输入数据x的名称前缀和id:将数据x的名称前缀和id号输入到双向跳表,此时数据x的id记为id1,且假设id1是第一次在该名称前缀所对应的双向跳表结构中进行查找。
步骤2:头结点查找:按照传统跳表的查找方式,从双向跳表跳表中的头节点最高层查找直至找到id1节点,并返回该数据x的实际存储地址。
步骤3:记录折返节点信息:将id1查找过程中每层跳表的前折返节点和后折返节点信息全部记录于所属该名称前缀的动态存储器中。
步骤4:输入数据y的名称前缀和id:将与数据x有相同前缀的数据y的名称前缀名称前缀和id号输入到双向跳表输入,并提取数据y的id号记为id2。
步骤5:判断id是否相等:若id1=id2,证明数据y与数据x相等,则执行步骤10,否则执行步骤6。
步骤6:选择最佳开始查找节点及查找方向:如果id1大于id2,则从记录在动态存储器中前折返节点中选择id值相差最小的节点作为最佳节点,否则,从后折返节点中选择id值相差最小的节点作为最佳节点。
步骤7:查找双向跳表:从最佳开始查找节点按照查找方向进行查找,同时更新动态存储器中记录的折返节点信息。
步骤8:判断是否存在该data包:若双向跳表中存在id相等的节点,则证明存在该data包,执行步骤9,否则,证明不存在该data包,执行步骤10。
步骤9:输出实际存储地址:返回该data包的实际内容的存储地址,继续执行步骤11。
步骤10:输出不存在该data包:输出不存在该data包,并继续执行步骤11。
步骤11:数据名称在双向跳表结构中的查找结束。
附图说明
图1为本发明中新型存储结构学习位图内容存储池系统结构框图。
图2为本发明学习位图内容存储池存储结构对interest包检索操作流程图。
图3为本发明学习位图内容存储池存储结构对data包检索操作流程图。
图4为本发明学习位图内容存储池存储结构对data包插入操作流程图。
图5为本发明学习位图内容存储池存储结构对data包删除操作流程图。
图6为本发明中数据名称在双向跳表中查找操作流程框图。
图7为本发明中学习位图内容存储池存储结构中双向跳表数据结构图。
图8为本发明中学习位图内容存储池存储结构中双向跳表节点结构图。
图9学习位图内容存储池存储结构中动态存储器结构示意图。
具体实施方式
本发明中,命名数据网转发平面新型存储结构学习位图内容存储池设计,如图1所示,其所述结构包括:一个片内存储单元和一个片外存储单元构成。其中,所述片内存储单元中具有一个高速存储器,片内部署一个神经网络模型(nnmodel)实现对数据名称的均匀映射,部署一个改进型位图(dynamic-bitmap,d-bitmap)实现将包含相同名称前缀的数据包映射到同一桶(bucket)中。片外存储单元使用一个低速存储器,其上部署多个与改进型位图的动态索引单元的槽(slot)对应的动态存储器(packetstore),来存储每个名称前缀的跳表信息。另部署一个双向跳表结构,以存放数据包在contentstore中的存储位置信息,且每个双向跳表节点中存有先入先出队列(firstinputfirstoutput,fifo)单指针和最近最少使用(leastrecentlyused,lru)双指针。通过以上各数据结构之间高效配合,使设计的新型存储结构学习位图内容存储池能够支持数据的检索、插入、删除操作。
3、在所设计的命名数据网转发平面学习位图内容存储池存储结构中采用子名称匹配算法检索interest包,每检索一次interest包的步骤如下:
步骤1:输入interest包名称前缀和id:输入interest包的名称前缀和id
到学习位图内容存储池存储结构中。
步骤2:所有子名称匹配:在学习位图中对所有包含该名称前缀的子名字进行匹配,并选择出最佳匹配的名称前缀。
步骤3:计算映射标号:该最佳匹配的名称前缀经神经网络运算得到一个0~1之间的索引映射值,该值乘改进型位图的槽总数,得出该interest包映射到改进型位图上的映射标号。
步骤4:计算基地址和偏移地址:由映射标号除以每个桶的槽总量取整得到该名称前缀所在的桶序号即为基地址,名称前缀进入该桶的顺序号为该名称前缀的偏移地址。
步骤5:判断改进型位图中是否存在最佳匹配名称前缀:若偏移地址所指向的槽中值为0,则证明改进型位图中不存在最佳匹配名称前缀,执行步骤10,否则,证明存在最佳匹配名称前缀,执行步骤6。
步骤6:访问动态存储器:由该最佳匹配名称前缀经学习位图训练映射后得到的基地址和偏移地址来访问动态存储器。
步骤7:在双向跳表中查找data包:选择最优双向跳表查找节点并确定查找方向,在双向跳表中查找data包。
7-1:输入数据x的名称前缀和id:将数据x的名称前缀和id号输入到双向跳表,此时数据x的id记为id1,假设id1是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-2:头结点查找:按照传统跳表的查找方式,从双向跳表跳表中的头节点最高层开始向后查找,并将查找路径节点信息记录与动态存储器中,并继续步骤8。
7-3:输入数据y的名称前缀和id:将与数据x有相同前缀的数据y的名称前缀名称前缀和id号输入到双向跳表输入,并提取数据y的id号记为id2,假设输入的y不是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-4:选择最佳开始查找节点及查找方向:如果id1大于id2,则从记录在动态存储器中前折返节点中选择id值相差最小的节点作为最佳节点,否则,从后折返节点中选择id值相差最小的节点作为最佳节点。
7-5:查找双向跳表:从最佳开始查找节点按照查找方向进行查找,同时更新动态存储器中记录的折返节点信息。
步骤8:判断双向跳表中是否存在最佳匹配data包:在双向跳表中查找与id号对应的data包,若找到id相同的节点,则说明存在最佳匹配data包,则执行步骤9,否则,执行步骤10。
步骤9:输出存在最佳匹配data包:学习位图内容存储池输出该最佳匹配data包,并继续执行步骤11。
步骤10:输出不存在最佳匹配data包:学习位图内容存储池输出不存在最佳匹配data包,并继续执行步骤11。
步骤11:interest包在学习位图内容存储池结构中的检索结束。
在所述存储池采用精确名称匹配算法检索data包,每检索一次data包的步骤如下:
步骤1:输入data包名称前缀和id:输入data包的名称前缀和id到学习
位图内容存储池存储结构中。
步骤2:精确名称匹配:在学习位图中对该名称前缀直接进行映射操作。
步骤3:计算映射标号:该名称前缀经神经网络运算得到一个0~1之间的索引映射值,该值乘改进型位图的槽总数,得出该data包映射到改进型位图上的映射标号。
步骤4:计算基地址和偏移地址:由映射标号除以每个桶的槽总量取整得到该名称前缀所在的桶序号即为基地址,名称前缀进入该桶的顺序号为该名称前缀的偏移地址。
步骤5:判断改进型位图中是否存在该名称前缀:若偏移地址所指向的槽中值为0,则证明改进型位图中不存在该名称前缀,执行步骤10,否则,证明存在该名称前缀,执行步骤6。
步骤6:访问动态存储器:由该名称前缀经学习位图训练映射后得到的基地址和偏移地址来访问动态存储器。
步骤7:在双向跳表中查找data包:选择最优双向跳表查找节点并确定查找方向,在双向跳表中查找data包。
7-1:输入数据x的名称前缀和id:将数据x的名称前缀和id号输入到双向跳表,此时数据x的id记为id1,且假设id1是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-2:头结点查找:按照传统跳表的查找方式,从双向跳表跳表中的头节点最高层开始向后查找,并将查找路径节点信息记录与动态存储器中,并继续步骤8。
7-3:输入数据y的名称前缀和id:将与数据x有相同前缀的数据y的名称前缀名称前缀和id号输入到双向跳表输入,并提取数据y的id号记为id2,假设输入的y不是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-4:选择最佳开始查找节点及查找方向:如果id1大于id2,则从记录在动态存储器中前折返节点中选择id值相差最小的节点作为最佳节点,否则,从后折返节点中选择id值相差最小的节点作为最佳节点。
7-5:查找双向跳表:从最佳开始查找节点按照查找方向进行查找,同时更新动态存储器中记录的折返节点信息。
步骤8:判断双向跳表中是否存在该data包:在双向跳表中查找与id号对应的data包,若找到id相同的节点,则说明存在该data包,则执行步骤9,否则,执行步骤10。
步骤9:输出该data包:学习位图内容存储池输出该data包,并继续执行步骤11。
步骤10:输出不存在data包:学习位图内容存储池输出不存在该data包,并继续执行步骤11。
步骤11:data包在学习位图内容存储池结构中的检索结束。
在所所述存储池中插入data包,每插入一个data包的步骤如下:
步骤1:输入data包名称前缀和id:输入data包的名称前缀和id
到学习位图内容存储池存储结构中。
步骤2:精确名称匹配:在学习位图中对该名称前缀直接进行映射操作。
步骤3:计算映射标号:该名称前缀经神经网络运算得到一个0~1之间的索引映射值,该值乘改进型位图的槽总数,得出该data包映射到改进型位图上的映射标号。
步骤4:计算基地址和偏移地址:由映射标号除以每个桶的槽总量取整得到该名称前缀所在的桶序号即为基地址,名称前缀进入该桶的顺序号为该名称前缀的偏移地址。
步骤5:判断改进型位图中是否存在该名称前缀:若偏移地址所指向的槽中值不为0,则证明改进型位图中存在该名称前缀,执行步骤6,否则,证明不存在该名称前缀,执行步骤10。
步骤6:访问动态存储器:由该名称前缀经学习位图训练映射后得到的基地址和偏移地址来访问动态存储器。
步骤7:在双向跳表中查找data包:选择最优双向跳表查找节点并确定查找方向,在双向跳表中查找data包。
7-1:输入数据x的名称前缀和id:将数据x的名称前缀和id号输入到双向跳表,此时数据x的id记为id1,且假设id1是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-2:头结点查找:按照传统跳表的查找方式,从双向跳表跳表中的头节点最高层开始向后查找,并将查找路径节点信息记录与动态存储器中,并继续步骤8。
7-3:输入数据y的名称前缀和id:将与数据x有相同前缀的数据y的名称前缀名称前缀和id号输入到双向跳表输入,并提取数据y的id号记为id2,假设输入的y不是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-4:选择最佳开始查找节点及查找方向:如果id1大于id2,则从记录在动态存储器中前折返节点中选择id值相差最小的节点作为最佳节点,否则,从后折返节点中选择id值相差最小的节点作为最佳节点。
7-5:查找双向跳表:从最佳开始查找节点按照查找方向进行查找,同时更新动态存储器中记录的折返节点信息。
步骤8:判断双向跳表中是否存在该data包:在双向跳表中查找与id号对应的data包,若未找到id相同的节点,则说明不存在该data包,则执行步骤9,否则,执行步骤11。
步骤9:插入双向跳表:按照id号增序将该data包插入双向跳表,并将名称前缀记录与动态存储器中,并继续执行步骤11。
步骤10:创建双向跳表:对该名称前缀新建一个双向跳表,将该数据插入跳表中,并将名称前缀记录与动态存储器中,并继续执行步骤11。
步骤11:data包在学习位图内容存储池结构中的插入结束。
在所述存储池中删除data包,每删除一个data包的步骤如下:
步骤1:输入data包名称前缀和id:输入data包的名称前缀和id到学习
位图内容存储池存储结构中。
步骤2:精确名称匹配:在学习位图中对该名称前缀直接进行映射操作。
步骤3:计算映射标号:该名称前缀经神经网络运算得到一个0~1之间的索引映射值,该值乘改进型位图的槽总数,得出该data包映射到改进型位图上的映射标号。
步骤4:计算基地址和偏移地址:由映射标号除以每个桶的槽总量取整得到该名称前缀所在的桶序号即为基地址,名称前缀进入该桶的顺序号为该名称前缀的偏移地址。
步骤5:判断改进型位图中是否存在该名称前缀:若偏移地址所指向的槽中值为0,则证明改进型位图中不存在该名称前缀,执行步骤10,否则,证明存在该名称前缀,执行步骤6。
步骤6:访问动态存储器:由该名称前缀经学习位图训练映射后得到的基地址和偏移地址来访问动态存储器。
步骤7:在双向跳表中查找data包:选择最优双向跳表查找节点并确定查找方向,在双向跳表中查找data包。
7-1:输入数据x的名称前缀和id:将数据x的名称前缀和id号输入到双向跳表,此时数据x的id记为id1,且假设id1是第一次在该名称前缀所对应的双向跳表结构中进行查找。
7-2:头结点查找:按照传统跳表的查找方式,从双向跳表跳表中的头节点最高层开始向后查找,并将查找路径节点信息记录与动态存储器中,并继续步骤8。
7-3:输入数据y的名称前缀和id:将与数据x有相同前缀的数据y的名称前缀名称前缀和id号输入到双向跳表输入,并提取数据y的id号记为id2。
7-4:选择最佳开始查找节点及查找方向:如果id1大于id2,则从记录在动态存储器中前折返节点中选择id值相差最小的节点作为最佳节点,否则,从后折返节点中选择id值相差最小的节点作为最佳节点。
7-5:查找双向跳表:从最佳开始查找节点按照查找方向进行查找,同时更新动态存储器中记录的折返节点信息。
步骤8:判断双向跳表中是否存在该data:在双向跳表中查找与id号对应的data包,若未找到id相同的节点,则说明不存在该data包,则执行步骤10,否则,执行步骤9。
步骤9:删除该data包节点,并继续执行步骤10。
步骤10:data包在学习位图内容存储池结构中的删除结束。
在所述存储池中双向查找名称数据,每查找一次名称数据的步骤如下:
步骤1:输入数据x的名称前缀和id:将数据x的名称前缀和id号输入到双向跳表,此时数据x的id记为id1,且假设id1是第一次在该名称前缀所对应的双向跳表结构中进行查找。
步骤2:头结点查找:按照传统跳表的查找方式,从双向跳表跳表中的头节点最高层查找直至找到id1节点,并返回该数据x的实际存储地址。
步骤3:记录折返节点信息:将id1查找过程中每层跳表的前折返节点和后折返节点信息全部记录于所属该名称前缀的动态存储器中。
步骤4:输入数据y的名称前缀和id:将与数据x有相同前缀的数据y的名称前缀名称前缀和id号输入到双向跳表输入,并提取数据y的id号记为id2。
步骤5:判断id是否相等:若id1=id2,证明数据y与数据x相等,则执行步骤10,否则执行步骤6。
步骤6:选择最佳开始查找节点及查找方向:如果id1大于id2,则从记录在动态存储器中前折返节点中选择id值相差最小的节点作为最佳节点,否则,从后折返节点中选择id值相差最小的节点作为最佳节点。
步骤7:查找双向跳表:从最佳开始查找节点按照查找方向进行查找,同时更新动态存储器中记录的折返节点信息。
步骤8:判断是否存在该data包:若双向跳表中存在id相等的节点,则证明存在该data包,执行步骤9,否则,证明不存在该data包,执行步骤10。
步骤9:输出实际存储地址:返回该data包的实际内容的存储地址,继续执行步骤11。
步骤10:输出不存在该data包:输出不存在该data包,并继续执行步骤11。
步骤11:数据名称在双向跳表结构中的查找结束。
本发明实现对数据的快速压缩处理操作,关键是在contentstore中,运用神经网络的网络映射以提高存储效率以及支持不同名称数据检索算法,设计满足支持快速缓存替换策略的特殊双向跳表数据结构以及可指导数据检索的动态存储器数据结构。其具体设计及实施方案如下:
(1)快速支持缓存替换策略的双向跳表数据结构设计
本发明中所设计的双向跳表数据结构是在传统跳表的基础上进行改进,因此双向跳表与传统跳表相似,也采用多层结构,且每层由一条双向链表构成,其跳表节点按照名称前缀的id号增序排列,其具体结构如图5所示。跳表节点间用fifo单指针和lru双指针相连,每个节点中有id、指向前向节点指针(prev)和后向节点的指针(next),节点地址,以图7所示的双向跳表节点图中id为6的节点为例,节点结构示意图如图8所示。
(2)用于指导数据检索的动态存储器数据结构设计
本发明中的动态存储器结构,用于记录节点在双向跳表查找过程中的前后折返节点信息,以指导相同数据名称前缀的下一次查找。动态存储器中记录的内容有:名称前缀、前向节点(prev_nodes)、前向节点地址(next_node_addr)、后向节点(next_nodes)、后向节点地址(next_node_addr)和当前节点(recent_node)。其中名称前缀是从数据包名称<名称前缀,id>中提取出来的;前向节点和后向节点是某个节点在查找时转折的关键节点对,前向节点地址和后向节点地址为节点地址;当前节点为最近刚查找的节点。其结构示意图如图9所示。假设查找节点为h,x为双向跳表中的节点,如果x<h≤x下一跳节点id,则前向节点记录x,后向节点记录x下一跳节点id,前向节点地址记录为各个对应的x节点地址,后向节点地址记录为各个对应的x下一跳节点地址,当前节点为h。以数据名称/a/b/c/7第一次到来图7所示的双向跳表数据结构为例说明以上过程。
提取id为7,查找路径为head[4]-6[4]-nil[4]-6[3]-25[3]-6[2]-9[2]-6[1]-7。此时动态存储器中记录的名称前缀为/a/b/c,后向节点为<nil,25,9,7>,对应的后向节点地址为<0xb,0x9,0x4,0x3>,前向节点为<6,6,6,6>,对应的前向节点地址为<0x2,0x2,0x2,0x2>,当前节点为7。
(3)数据名称前缀经神经网络模型高效检索得到映射标号
数据名称前缀经神经网络模型高效检索,重点在于对样本训练学习,构建满足需求的神经网络模型。首先神经网络采集样本进行训练,对于样本来说,本发明中使用与命名数据网名称数据格式类似的大量统一资源定位符(uniformresourcelocator,url)作为样本数据,利用样本数据,结合反向传播神经网络,学习训练出能反映索引数据分布情况的累积分布函数,根据数学定理,如果x服从任意分布,作为自己的累积分布函数f(x)的输入,则y=f(x)变换后值的分布必将服从u(0,1)。因此,将样本的名称前缀字符串视为数值,输入其累积分布函数,即可得到一个0~1之间的映射值,该值乘以改进型位图的总槽数,即可得到实现均匀映射的映射标号。
(4)双向跳表中实现快速双向查找
利用动态存储器中的节点信息:名称前缀、前向节点、前向节点地址、后向节点、后向节点地址和当前节点,指导具有相同名称前缀的数据查找过程如下:对于有相同名称前缀的数据j,首先比较j的id和当前节点的id大小,如果id<当前节点的id,则从前向节点中依据id号选择与数据j最近的折返节点作为最佳开始查找节点;如果id>当前节点的id,则从后向节点中选取依据id号选择与数据j最近的折返节点作为最佳开始查找节点。若选择的最佳开始节点的id小于j的id,则向后查找,否则,从最佳节点想前查找。并且在数据查找过程中,及时更新以上记录的节点信息。以数据名称/a/b/19、/a/b/26、/a/b/21到达图4所示的双向跳表结构,且动态存储器中的记录信息为图9所示为例,说明以上过程。
当查找/a/b/19时,提取名称id为19,因为19>7,所以从后向节点中查找最优节点和层数。判断9<19<25,所以从(19-9)>(25-19),所以从25[3]开始查找,i为3,且19<25,所以向前查找。路径为:25[3]-6[3]-25[2]-17[2]-25[1]-21[1]-19;动态存储器中更新节点信息如下:后向节点为<nil,25,25,21>,对应的后向节点地址为<0xb,0x9,0x9,0x8>,前向节点为<6,6,17,19>,对应的前向节点地址为<0x2,0x2,0x6,0x7>,当前节点为19。
当查找/a/b/26时,提出提取名称id为26,且19<26,所以从后向节点中选择查找最优节点和层数。判断25<26<nil,且(26-25)<(nil-26),所以从25[2]开始查找,i为3,且26>25,所以向后查找。路径为:25[3]-nil[3]-25[2]-nil[2]-25[1]-26;动态存储器中更新节点信息如下:后向节点为<nil,nil,nil,26>对应的后向节点地址为<0xb,0xb,0xb,0xa>,前向节点为<6,25,25,25>,对应的前向节点地址为<0x2,0x9,0x9,0x9>,当前节点为26。
当查找/a/b/c/21时,提出提取名称id为21,且26>21,所以从前向节点中选择查找最优节点和层数。判断6<21<25,且(25-21)<(21-6),所以从25[3]开始查找,i为3,且25>21,所以向后查找。路径为:25[3]-6[3]-25[2]-17[2]-25[1]-21;动态存储器中更新节点信息如下:后向节点为<nil,25,25,25>对应的后向节点地址为<0xb,0x9,0x9,0x9>,前向节点为<6,6,17,21>,对应的前向节点地址为<0x2,0x2,0x6,0x8>,当前节点为21。
- 还没有人留言评论。精彩留言会获得点赞!