一种基于CBOW模型和依存句法关系的词向量表示方法与流程
本发明涉及自然语言处理领域,具体涉及一种基于cbow模型和依存句法关系的词向量表示方法。
背景技术:
word2vec是用于训练词向量的神经网络模型,它能够在训练语言模型的同时将词表示成分布式词向量。cbow模型是word2vec中一种常用训练方式,cbow模型在训练过程使用大量的文本语料库,通过随机窗口构造中心词的上下文,利用随机梯度下降和反向传播算法,大大提升了词向量的训练效率。但在cbow模型中使用随机窗口来构造中心词的上下文,这对学习高质量词向量的表征仍然是不够的。为了提高词向量的表示,近年来提出了将各种附加资源整合到词向量表示法学习框架中的研究工作。通常,一些增强的词嵌入模型试图利用词汇知识资源作为学习词嵌入的语义约束,也有人尝试利用多语种并行语料库来指导单词向量的训练过程。然而,这些工作没有充分考虑到训练语料的词性以及句法信息。
技术实现要素:
本发明的目的在于克服上述已有技术的不足,利用词性以及依存句法关系,得到具有依存句法关系的句法上下文,以此提出一种基于cbow模型和依存句法关系的词向量表示方法。
本发明方法包括以下步骤:
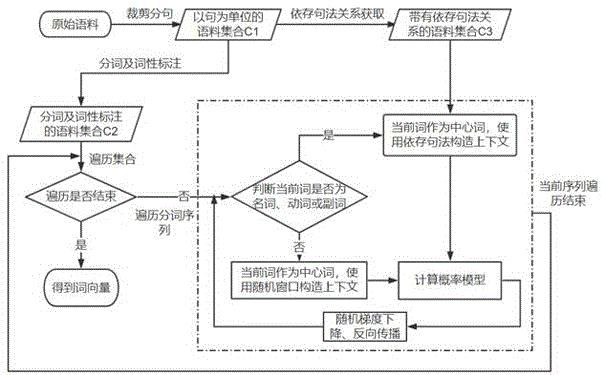
1.语料预处理
针对原始语料进行裁剪分句得到语料集合c1。针对语料集合c1,获得每行语料的分词及词性标注,构成语料集合c2。语料集合c2为:
c2={j1,j2,ji...jn}
ji为语料集合c2中一行带有分词及词性标注的序列,1<=i<=n,n为语料集合c2的行数。
针对语料集合c1,获得每行语料的依存句法关系,构成语料集合c3。
2.词向量表示学习
2.1遍历语料集合
根据步骤1的结果,将语料集合c2作为cbow模型的输入。遍历语料集合c2中的每个分词序列ji。
2.2遍历分词序列ji中的分词,具体步骤如下:
a)将分词序列ji中的当前分词作为中心词。
b)通过判断中心词的词性,构造上下文得到概率模型。
判断中心词的词性,若中心词的词性是动词或名词或副词,则通过语料集合c3获得中心词的依存句法关系,将依存句法关系中构成强依存关系的词并入到中心词的上下文中,具体强依存关系判断如下:
若中心词是动词,则强依存关系为主谓关系或动宾关系或连谓关系或状语关系。
若中心词是名词,则强依存关系为主谓关系或动宾关系或同位关系或限定关系或定中关系或数量关系。
若中心词是副词,则强依存关系为状语关系或定中关系。
考虑到副词的强依存关系较少,将副词构成强依存关系的依存词再次进行强依存关系的选定,把再次选定的依存词一起并入到中心词的上下文中。
将具有强依存关系的词构成句法上下文,修改cbow模型中的概率模型为:
p=(wtarget|wdobj+wnsub+...+wamod)
其中p是cbow模型中的概率模型,wtarget为中心词,wdobj,wnsub,wamod是与wtarget构成强依存关系的词。
若中心词不为上述三种词性,则使用随机窗口构造中心词的上下文,使用cbow模型中原始的概率模型:
p=(wtarget|context(wtarget))
其中context(wtarget)是用随机窗口对wtarget构造的上下文。
c)针对步骤b)中得到的概率模型,使用随机梯度下降和反向传播,对训练的参数以及词向量进行更新,设置下一个分词为当前分词并返回到步骤a),直到当前分词序列ji遍历结束。
2.3语料集合c2遍历结束后得到词向量。
本发明的有益效果:本发明结合词性以及依存句法信息,改进了cbow模型中心词的上下文信息构造方法和概率模型,从而提高了词向量表示的准确性。
附图说明
图1是本发明的流程图。
具体实施方式
为了使本发明的内容、特点阐述的更加清晰明白,以下结合附图1,对本发明进一步详细说明,具体内容如下:
1.语料预处理
针对原始语料进行裁剪分句得到语料集合c1。针对语料集合c1,获得每行语料的分词及词性标注,构成语料集合c2。语料集合c2为:
c2={j1,j2,ji...jn}
ji为语料集合c2中一行带有分词及词性标注的序列,1<=i<=n,n为语料集合c2的行数。
针对语料集合c1,获得每行语料的依存句法关系,构成语料集合c3。
例如对于原始语料:
“此次英国新签证政策的实施,使英国院校在整个留学申请中担当了非常重要的角色。但是直接由英国院校来审核中国学生提交信息的真实性并不现实,因此院校会通过与中国权威专业的留学服务机构的合作来达到目的。但是这不表示申请学生可以存侥幸心理,通过特殊的方式达到留学的目的。”
将原始语料通过相应的工具裁剪分句后,得到语料集合c1:
["英国新签证政策的实施,英国院校在整个留学申请中担当了非常重要的角色"
"由英国院校来审核中国学生提交信息的真实性并不现实"
"院校会通过与中国权威专业的留学服务机构的合作达到目的"
"这不表示申请学生可以存侥幸心理通过特殊的方式达到留学的目的"]
针对语料集合c1,获得每行语料的分词及词性标注,构成语料集合c2:
["英国-ns,新-a,签证-v,政策-n,的-uj,实施-v,英国-ns,院校-n,在-p,整个-b,留学-v,申请-v,中-f,担当-v,了-ul,非常-d,重要-a,的-uj,角色-n",
……
……
"这-r,不-d,表示-v,申请-v,学生-n,可以-c,存-v,侥幸心理-vn,-x,通过-p,特殊-a,的-uj,方式-n,达到-v,留学-v,的-uj,目的-n"]
针对语料集合c1,获得每行语料的依存句法关系,构成语料集合c3:
["签证-英国-nmod,签证-新-amod,政策-签证-compound:nn,实施-政策-nmod:assmod,政策-的-case,担当-实施-nmod:topic,担当-,-punct,院校-英国-nmod:assmod,担当-院校-nsubj,申请-在-case,申请-整个-det,申请-留学-compound:nn,担当-申请-nmod:prep,申请-中-case,担当-了-aux:asp,重要-非常-advmod,角色-重要-amod,重要-的-mark,担当-角色-dobj",
……
……
"表示-这-nsubj,表示-不-neg,学生-申请-compound:nn,存-学生-nsubj,存-可以-aux:modal,目的-存-acl,心理-侥幸-compound:nn,存-心理-dobj,方式-通过-case,方式-特殊-amod,特殊-的-case,达到-方式-nmod:prep,存-达到-conj,达到-留学-dobj,存-的-mark,表示-目的-dobj"]
2.词向量表示学习
2.1遍历语料集合
根据步骤1的结果,将语料集合c2作为cbow模型的输入。遍历语料集合c2中的每个分词序列ji。
2.2遍历分词序列ji中的分词,具体步骤如下:
a)将分词序列ji中的当前分词作为中心词。
b)通过判断中心词的词性,构造上下文得到概率模型。
判断中心词的词性,若中心词的词性是动词或名词或副词,则通过语料集合c3获得中心词的依存句法关系,将依存句法关系中构成强依存关系的词并入到中心词的上下文中,具体强依存关系判断如下:
若中心词是动词,则强依存关系为主谓关系或动宾关系或连谓关系或状语关系。
若中心词是名词,则强依存关系为主谓关系或动宾关系或同位关系或限定关系或定中关系或数量关系。
若中心词是副词,则强依存关系为状语关系或定中关系。
考虑到副词的强依存关系较少,将副词构成强依存关系的依存词再次进行强依存关系的选定,把再次选定的依存词一起并入到中心词的上下文中。
将具有强依存关系的词构成句法上下文,修改cbow模型中的概率模型为:
p=(wtarget|wdobj+wnsub+...+wamod)
其中p是cbow模型中的概率模型,wtarget为中心词,wdobj,wnsub,wamod是与wtarget构成强依存关系的词。
若中心词不为上述三种词性,则使用随机窗口构造中心词的上下文,使用cbow模型中原始的概率模型:
p=(wtarget|context(wtarget))
其中context(wtarget)是用随机窗口对wtarget构造的上下文。
例如在训练的时候,语料集合c2如下:
["英国-ns,新-a,签证-v,政策-n,的-uj,实施-v,英国-ns,院校-n,在-p,整个-b,留学-v,申请-v,中-f,担当-v,了-ul,非常-d,重要-a,的-uj,角色-n"
……
]
语料集合c3如下:
["签证-英国-nmod,签证-新-amod,政策-签证-compound:nn,实施-政策-nmod:assmod,政策-的-case,担当-实施-nmod:topic,担当-,-punct,院校-英国-nmod:assmod,担当-院校-nsubj,申请-在-case,申请-整个-det,申请-留学-compound:nn,担当-申请-nmod:prep,申请-中-case,担当-了-aux:asp,重要-非常-advmod,角色-重要-amod,重要-的-mark,担当-角色-dobj"
……
]
当中心词为"签证"时,根据词性判断中心词为动词,从语料集合c3中获得与中心词构成依存句法关系的词,根据强依存关系的判断,得到中心词的强依存关系词为"英国"、"政策"、"新",这些强依存关系词作为中心词的句法上下文,修改cbow模型中的概率模型:
p=(签证|(英国+政策+新))
其中p是cbow模型中的概率模型,"签证"为中心词,"英国"、"政策"、"新"为中心词的强依存关系词。
当中心词为"院校"时,判断该中心词为名词,从语料集合c3获得"院校"的强依存关系词为"英国"、"担当",修改cbow模型中的概率模型:
p=(院校|(英国+担当))
其中p是cbow模型中的概率模型,"院校"为中心词,"英国"、"担当"为中心词的强依存关系词。
c)针对步骤b)中得到的概率模型,使用随机梯度下降和反向传播,对训练的参数以及词向量进行更新,设置下一个分词为当前分词并返回到步骤a),直到当前分词序列ji遍历结束。
例如在训练的时候,语料集合c2如下:
["英国-ns,新-a,签证-v,政策-n,的-uj,实施-v,英国-ns,院校-n,在-p,整个-b,留学-v,申请-v,中-f,担当-v,了-ul,非常-d,重要-a,的-uj,角色-n"
……
]
如当前词为"签证"时,得到"签证"的句法上下文,构造其概率模型:
p=(签证|(英国+政策+新))
使用反向传播和随机梯度下降对"签证"、"英国"、"政策"、"新"的词向量进行更新,并且让"签证"的下一个分词"政策"为当前分词回到步骤a)。
2.3语料集合c2遍历结束后得到词向量。
例如对于"调研"、"提出"这两个词,当训练结束完毕得到的词向量如下:
签证:[-0.37914750-0.515692613-0.32542463-9.813804180.5488254-6.32801294-0.878692613-6.45021260-7.687482831.15415455-1.20365568……-0.75415544]
政策:[-0.53575015-0.5234345-0.53435270.1672930.389905-0.23422-6.3801294-0.78692613-6.45021260-7.235464730.333545220.03453661……-0.48597723]。
- 还没有人留言评论。精彩留言会获得点赞!