一种复杂多含水层矿井突水水源识别方法与流程
本发明涉及水源识别领域,尤其涉及一种复杂多含水层矿井突水水源识别方法。
背景技术:
中国是一个以煤炭为主要能源的国家,而中国的煤矿床水文地质条件复杂多样,矿井水灾害形势严峻,是影响矿井安全生产的重要因素。矿井一旦发生水害不仅会造成巨大的经济损失,而且可能会造成人员伤亡。矿井水源识别是矿井水害防治的重要基础工作,可为防治水措施及灾后救援等提供依据。而选择合适的水源识别方法则是矿井水源识别的关键。
目前,矿井水源识别的主要方法有地下水水化学法、水位动态观测法、同位素法、水温度分析法等。其中,水化学方法由于基础资料丰富、通用性较强得到较为广泛的应用。利用水化学方法识别矿井突水水源的方法有很多,主要是在水化学数据基础上结合相关数理模型实现水源识别。如使用fisher识别模型、bayes识别模型、距离识别模型、神经网络模型、可拓识别模型、聚类分析、svm模型,以及先进行主成分分析再进行识别的组合模型等。
上述单一方法在矿井水文地质条件较简单、充水含水层类型较少的条件下,能取得较好的识别效果。但在水文地质条件较复杂、充水含水层较多时,识别有效性大大降低,无法满足矿井安全生产对水源识别模型的需求。
据此,目前急需一种能实现复杂多含水层突水水源类型的快速有效识别的复杂多含水层矿井突水水源识别方法。
技术实现要素:
本发明所要解决的技术问题在于提供一种能实现复杂多含水层突水水源类型的快速有效识别的复杂多含水层矿井突水水源识别方法,其适用于水文地质条件较复杂、充水含水层较多的矿井突水水源识别。
本发明采用以下技术方案解决上述技术问题:一种复杂多含水层矿井突水水源识别方法,该方法包括以下步骤:
s1:根据已知含水层水样的水化学数据,建立矿井的水源数据库;
s2:经过数据检验以及异常值的处理后的数据作为建模样本;
s3:确定识别指标及其阈值并采用回代检验判断初步识别模型中的识别指标的有效性;
s4:依据有效的识别指标以及fisher识别法,建立“综合-逐步识别法”模型;
s5:测定待判水样识别指标,并通过“综合-逐步识别法”模型依次判定,识别水源类型。
作为本发明的优选方式之一,所述水样的水化学数据为水样所属煤矿各含水层水的各种离子质量浓度和各离子的毫克当量及比值;常规离子可以为na++k+、ca2+、mg2+、cl-、hco3-、so42-等;此水化学数据作为建立水源数据库的建库指标。
作为本发明的优选方式之一,所述数据检验的方法为阴阳离子平衡检验,误差控制在±5%以内;异常样本的筛选和处理方法采用各指标柱状图、箱图、q~q图和聚类分析图的一种或几种结合,筛选出异常样本并剔除后的水样数据作为建模样本
作为本发明的优选方式之一,所述识别指标的选择方法是根据建模各含水层水样的水化学数据,从中选出能区分各含水层的指标作为识别指标,并确定其阈值,以及识别水源时的识别关系;识别指标选择的标准是识别指标在含水层水样中的含量变化比其他指标的含量变化大;某一识别的识别关系,即识别时将待测水样识别指标小于或大于确定的识别指标阈值的水样归为一类,识别指标至少可以区分两个含水层的水样;其中,识别指标是常规离子的质量浓度和常规离子的毫克当量比值。
作为本发明的优选方式之一,所述常规离子的质量浓度和常规离子的毫克当量比值分别叫做特征离子对比和离子比例系数。
作为本发明的优选方式之一,所述步骤s3中采用回代检验判断初步识别模型中的识别指标的有效性具体方法为:将已知含水层类型的水样作为新样本,依次代入建立的初步识别模型中,若识别结果与实际一致,则说明识别指标的选择以及建立的初步识别模型是有效的;若同一含水层水样识别结果多数与实际不一致,则应该重新选择新的识别指标,建立新的初步识别模型。
作为本发明的优选方式之一,所述步骤s4中综合-逐步识别法为综合采用特征离子对比法、离子比例系数法和fisher识别法,对不同含水层水源识别采用不同方法,先简单后复杂,逐步判定水源类型;即对于某一待判单一含水层水样,识别时将待测水样特征离子或者离子比例系数小于确定的识别指标阈值的水样归为某种水源类型,或将该指标大于阈值的水样归为某种水源类型,如能判断出结果,则停止识别,否则将其归为新的待判样本,对此选择新的识别指标及其阈值,如此循环;对无法用识别指标判定突水水源类型时,则采用fisher识别法。利用本发明能够实现复杂多含水层矿井出水水源类型的快速识别。
作为本发明的优选方式之一,所述综合-逐步识别法具体步骤如下:
第一步,对于某一待判单一含水层水样,采用特征离子对比法判断该水样是奥灰水还是二含水,如能判断出结果,则停止识别,否则进行第二步识别;
第二步,采用离子比例系数法判断该水样是推覆体水还是煤系水;
第三步,在第二步基础上,如果该水样判定为推覆体水,则采用特征离子对比法,判定该水样是推覆体片麻岩水与推覆体寒灰水;如果该水样判定为煤系水,则采用fisher识别法,判定该水样是砂岩水或太灰水。
至此,经过上述三步,该待判单一含水层水样被判定为二含水、推覆体片麻岩水、推覆体寒灰水、砂岩水、太灰水、奥灰水中的一种。
作为本发明的优选方式之一,所述综合-逐步识别法具体操作方法为:在经过数据校验及异常剔除后的水样中:首先,当tds>4300mg/l、cl->2000mg/l、na++k+>1350mg/l时,所述水样为奥灰水,识别结束;否则,进一步识别,当tds<440mg/l、cl-<50mg/l、na++k+<80mg/l时,所述水样为二含水,识别结束;否则,进一步识别,当γcl-/γca2+<5.2时,所述水样为推覆体水,进一步识别,当tds<1360mg/l、cl-<474mg/l时,所述水样为推覆体水片麻岩水,识别结束;否则所述水样为推覆体水寒灰水,识别结束;当γcl-/γca2+>5.2时,所述水样为煤系水,再利用fisher识别法,识别出砂岩水或太灰水,此时识别结束。
本发明相比现有技术的优点在于:本发明的优点是综合采用特征离子对比法、离子比例系数法和fisher识别法等,对不同含水层水源识别采用不同方法,先简单后复杂,即可逐步判定水文地质条件较复杂、充水含水层较多的矿井水源类型。本发明直接通过检测未知水样中识别流程所采用的识别指标,即可代入所建立的“综合-逐步识别法”模型中,进行水源识别。因此,可以提高复杂多含水层矿井突水水源识别的快速性和准确性。
附图说明
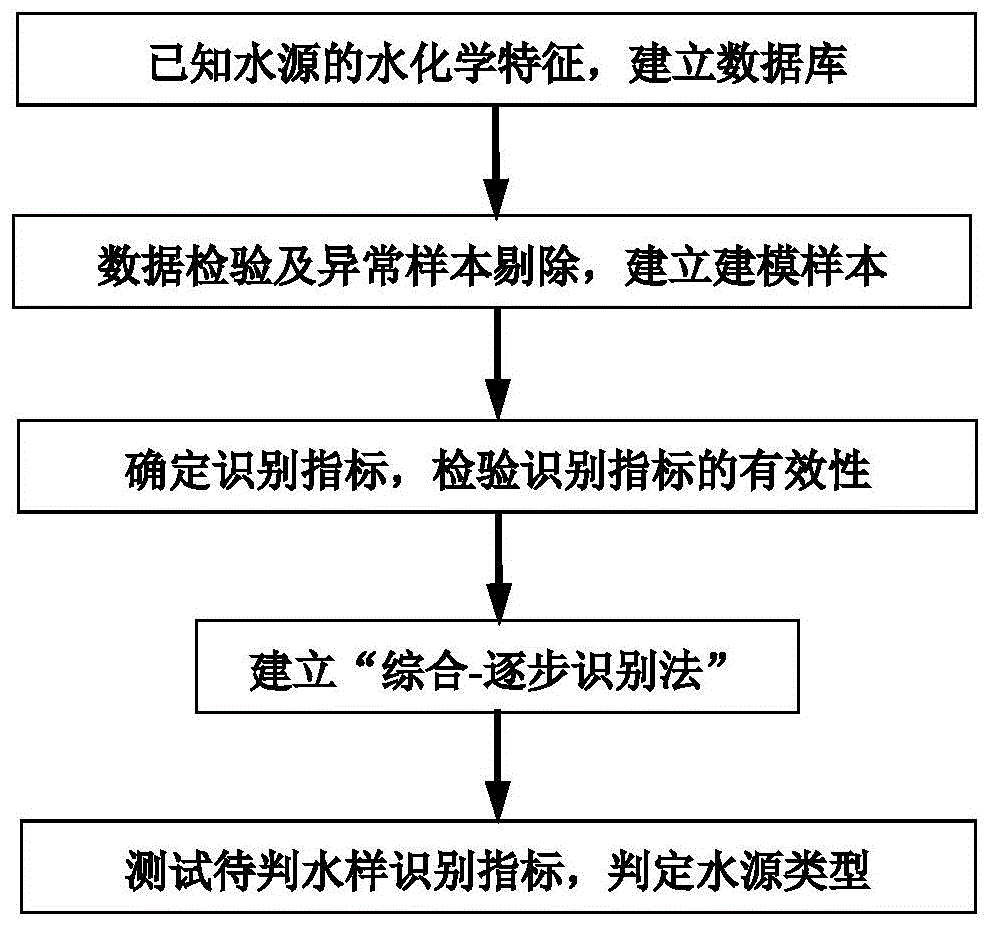
图1是实施例1中的复杂多含水层突水水源识别流程图;
图2为本实施例的异常值处理柱状图;
图3为本实施例的异常值处理聚类结果图;
图4为本实施例的异常值处理指标箱图;
图5为本实施例的“综合-逐步识别法”模型具体流程图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
实施例1
如图1所示,本实施例的一种复杂多含水层矿井突水水源识别方法,该方法包括以下步骤:
s1:根据已知含水层水样的水化学数据,建立矿井的水源数据库;所述水样的水化学数据为水样所属煤矿各含水层水的各种离子质量浓度和各离子的毫克当量及比值;常规离子可以为na++k+、ca2+、mg2+、cl-、hco3-、so42-等;此水化学数据作为建立水源数据库的建库指标。
s2:经过数据检验以及异常值的处理后的数据作为建模样本;所述数据检验的方法为阴阳离子平衡检验,误差控制在±5%以内。在所述数据检验的阴阳离子平衡检验中:异常样本的筛选和处理方法采用各指标柱状图、箱图、q~q图和聚类分析图的一种或几种结合,筛选出异常样本并剔除后的水样数据作为建模样本。
s3:确定识别指标及其阈值并采用回代检验判断初步识别模型中的识别指标的有效性;所述识别指标的选择方法是根据建模各含水层水样的水化学数据,从中选出能区分各含水层的指标作为识别指标,并确定其阈值,以及识别水源的识别关系;识别指标选择的标准是识别指标在含水层水样中的含量变化比其他指标的含量变化大;某一识别的识别关系,即识别时将待测水样识别指标小于或大于确定的识别指标阈值的水样归为一类,识别指标至少可以区分两个含水层的水样;其中,识别指标是常规离子的质量浓度和常规离子的毫克当量比值,所述常规离子的质量浓度和常规离子的毫克当量比值分别叫做特征离子对比和离子比例系数。所述步骤s3中采用回代检验判断初步识别模型中的识别指标的有效性具体方法为:将已知含水层类型的水样作为新样本,依次代入建立的初步识别模型中,若识别结果与实际一致,则说明识别指标的选择以及建立的初步识别模型是有效的;若同一含水层水样识别结果多数与实际不一致,则应该重新选择新的识别指标,建立新的初步识别模型。
s4:依据有效的识别指标以及fisher识别法,建立“综合-逐步识别法”模型;所述步骤s4中综合-逐步识别法为综合采用特征离子对比法、离子比例系数法和fisher识别法,对不同含水层水源识别采用不同方法,先简单后复杂,逐步判定水源类型;即对于某一待判单一含水层水样,识别时将待测水样特征离子或者离子比例系数小于确定的识别指标阈值的水样归为某种水源类型,或将该指标大于阈值的水样归为某种水源类型,如能判断出结果,则停止识别,否则将其归为新的待判样本,对此选择新的识别指标及其阈值,如此循环;对无法用识别指标判定突水水源类型时,则采用fisher识别法。fisher识别法对总体的分布没有特定要求,是一种线性识别方法。它的特点是将高维数据点投影到低维空间(如一维直线)上,这样数据点就可以变得比较密集,从而可以克服由于维数高引起的“维数祸根”。投影的原则是将总体与总体之间尽可能的分开,然后根据类间距离最大、类内距离最小的原则确定识别分析函数,进而将新的样本进行分类识。利用本发明能够实现复杂多含水层矿井出水水源类型的快速识别。
所述综合-逐步识别法具体步骤如下:
第一步,对于某一待判单一含水层水样,采用特征离子对比法判断该水样是奥灰水还是二含水,如能判断出结果,则停止识别,否则进行第二步识别;
第二步,采用离子比例系数法判断该水样是推覆体水还是煤系水;
第三步,在第二步基础上,如果该水样判定为推覆体水,则采用特征离子对比法,判定该水样是推覆体片麻岩水与推覆体寒灰水;如果该水样判定为煤系水,则采用fisher识别法,判定该水样是砂岩水或太灰水。
至此,经过上述三步,该待判单一含水层水样被判定为二含水、推覆体片麻岩水、推覆体寒灰水、砂岩水、太灰水、奥灰水中的一种。
s5:测定待判水样识别指标,并通过“综合-逐步识别法”模型依次判定,识别水源类型。
所述综合-逐步识别法具体操作方法为:在经过数据校验及异常剔除后的水样中:首先,当tds>4300mg/l、cl->2000mg/l、na++k+>1350mg/l时,所述水样为奥灰水,识别结束;否则,进一步识别,当tds<440mg/l、cl-<50mg/l、na++k+<80mg/l时,所述水样为二含水,识别结束;否则,进一步识别,当γcl-/γca2+<5.2时,所述水样为推覆体水,进一步识别,当tds<1360mg/l、cl-<474mg/l时,所述水样为推覆体水片麻岩水,识别结束;否则所述水样为推覆体水寒灰水,识别结束;当γcl-/γca2+>5.2时,所述水样为煤系水,再利用fisher识别法,识别出砂岩水或太灰水,此时识别结束。
本实施例综合采用特征离子对比法、离子比例系数法和fisher识别法等,对不同含水层水源识别采用不同方法,先简单后复杂,即可逐步判定水文地质条件较复杂、充水含水层较多的矿井水源类型。本实施例直接通过检测未知水样中识别流程所采用的识别指标,即可代入所建立的“综合-逐步识别法”模型中,进行水源识别。因此,可以提高复杂多含水层矿井突水水源识别的快速性和准确性。
下面选择新集二水质台账中新生界二含水、推覆体片麻岩水、推覆体寒灰水、砂岩水和太灰水等含水层水样数据作为数据库,来具体阐述本实施例的设计方案与理论依据。
数据检验和异常样本处理
进行单一含水层特征指标判断时,要求所分析的水样水化学成分需是该含水层的典型代表。因此,在进行特征指标分析与水源识别模型建立前,需对各含水层水样进行检验和异常样本处理。
样本数据检验的方法为阴阳离子平衡检验,由于na++k+、ca2+、mg2+、cl-、hco3-、so42-指标均为实测值,因此要求误差控制在±5%以内,即测试误差在此范围内的为合格水样,做为基础数据进行下一步分析。
虽经阴阳离子检验合格,但有少数水样在水样采集、层位判定、测试分析等过程中的某一环节存在一定问题,导致该水样并不能真实反映某一含水层水质特征,在水质分析过程中表现为离群样本,需进行筛选剔除处理。下面以奥灰水样为例,阐述对异常样本的筛选和处理方法,如图2-4。
对收集的17个奥灰水样tds、na++k+、ca2+、cl-离子进行对比分析,如图2所示。标号为o-03、o-04、o-05三个水样上述几个指标与其余14个水样差异明显。为进一步判断奥灰水o-04、o-05和o-06号三个水样与其余水样关系,对奥灰水样进行了系统聚类分析。采用tds、na++k+、ca2+、mg2+、cl-、hco3-、so42-等7个指标作为变量,聚类结果如图3所示。由图3可见,除标号为o-03、o-04、o-05号样品外,其余样品间差异性最小,最能代表奥灰水性质,而标号为o-03、o-04、o-05与其余样品间距离最大,在最后才完成分类。而箱线图,是一种用来描述数据分布的统计图形,可以用来表现观测数据的中位数、4分位数和极值等描述性统计量,从视觉的角度观测变量值的分布情况。奥灰水17个水样tds、na++k+、ca2+、mg2+、cl-指标箱图如图4所示。由图可见,在这5个指标上标号为o-3、o-4、o-5三个水样,也均显示与其余水样有显著的差异。
因此,奥灰水17个样品中o-03、o-04、o-05号三个样品可视为异常样本,不能代表奥灰水典型特征,在后续水样类型识别模型建立中将剔除,不作为标准水样参与建模。
对新生界二含水、推覆体片麻岩水、推覆体寒武系水、砂岩水和太灰水等其余5个单一含水层水样均采用上述或其他多种方法进行离群样本的综合筛查和剔除。经过数据检验及异常样本剔除后的数据,作为建模的样本。
识别指标及阈值确定
根据前述分析,二含水和奥灰水在tds、cl-和na++k+含量上具有典型特征,与其它含水层水样可以有效区分开来。因此,选择上述3个指标作为二含水和奥灰水的识别指标,其含量范围如表1所示。
表1二含水和奥灰水特征指标含量范围
(2)推覆体水和煤系水
推覆体片麻岩水与推覆体寒灰水常规离子和水质类型相近,砂岩水与太灰水常规离子和水质类型相近。这里把推覆体片麻岩水和推覆体寒灰水先归为一类,统称为推覆体水;把砂岩水和太灰水归为一类,统称为煤系水。通过建模样本的数据表明,推覆体水和煤系水的特征离子比例系数(γcl-/γca2+)差异性明显(表2),可作为重新归类的推覆体水和煤系水的区分标志。
表2推覆体水和煤系水特征离子比例系数范围
(3)推覆体片麻岩水与推覆体寒灰水
推覆体片麻岩水与推覆体寒武系水在tds和cl-含量上具有典型特征,可做为区分这两类含水层水的标志。
表3推覆体水特征指标含量范围
(4)砂岩水与太灰水
砂岩水与太灰水在特征例子指标和离子比例系数上差异均不明显,仅从上述两个方面常规手段尚无法区分。为此,综合选择tds、ca2+、mg2+、na++k+、hco3-、so42-、cl-等7个指标作为砂岩水与太灰水之间分类的识别因子,采用fisher识别法进行判定水源类型。
fisher识别法对总体的分布没有特定要求,是一种线性识别方法。它的特点是将高维数据点投影到低维空间(如一维直线)上,这样数据点就可以变得比较密集,从而可以克服由于维数高引起的“维数祸根”。投影的原则是将总体与总体之间尽可能的分开,然后根据类间距离最大、类内距离最小的原则确定识别分析函数,进而将新的样本进行分类识。
识别方法选择及识别步骤
本次新集二矿复杂多含水层水源类型识别方法采用“综合-逐步识别法”。
具体步骤如下:
第一步,对于某一待判单一含水层水样,采用特征离子对比法判断该水样是奥灰水还是二含水,如能判断出结果,则停止识别,否则进行第二步识别。
第二步,采用离子比例系数法判断该水样是推覆体水还是煤系水。
第三步,在第二步基础上,如果该水样判定为推覆体水,则采用特征离子对比法,判定该水样是推覆体片麻岩水与推覆体寒灰水;如果该水样判定为煤系水,则采用fisher识别法,判定该水样是砂岩水和太灰水。
至此,经过上述三步,该待判单一含水层水样被判定为二含水、推覆体片麻岩水、推覆体寒灰水、砂岩水、太灰水、奥灰水中的一种。
“综合-逐步识别法”模型的建立
对于某一待判单一含水层水样,在进行数据检验和异常样本处理、识别指标及界限值、识别方法选择及识别步骤确定后,建立的识别模型及流程如图3所示。
识别效果的检验
采用回代检验判断识别指标的有效性,将已知含水层类型的水样作为新样本,依次代入建立的识别模型中,若识别结果与实际一致,则说明识别指标的选择以及建立的“综合-逐步识别法”模型是有效的;若同一含水层水样识别结果多数与实际不一致,则应该重新选择新的识别指标,建立新的水源识别模型。
确定“综合-逐步识别法”模型后,对未知含水层水样,通过测试识别指标的含量后,代入所建立的模型,即可得出未知水样的含水层类型。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!