一种植物光谱库的建立方法与流程
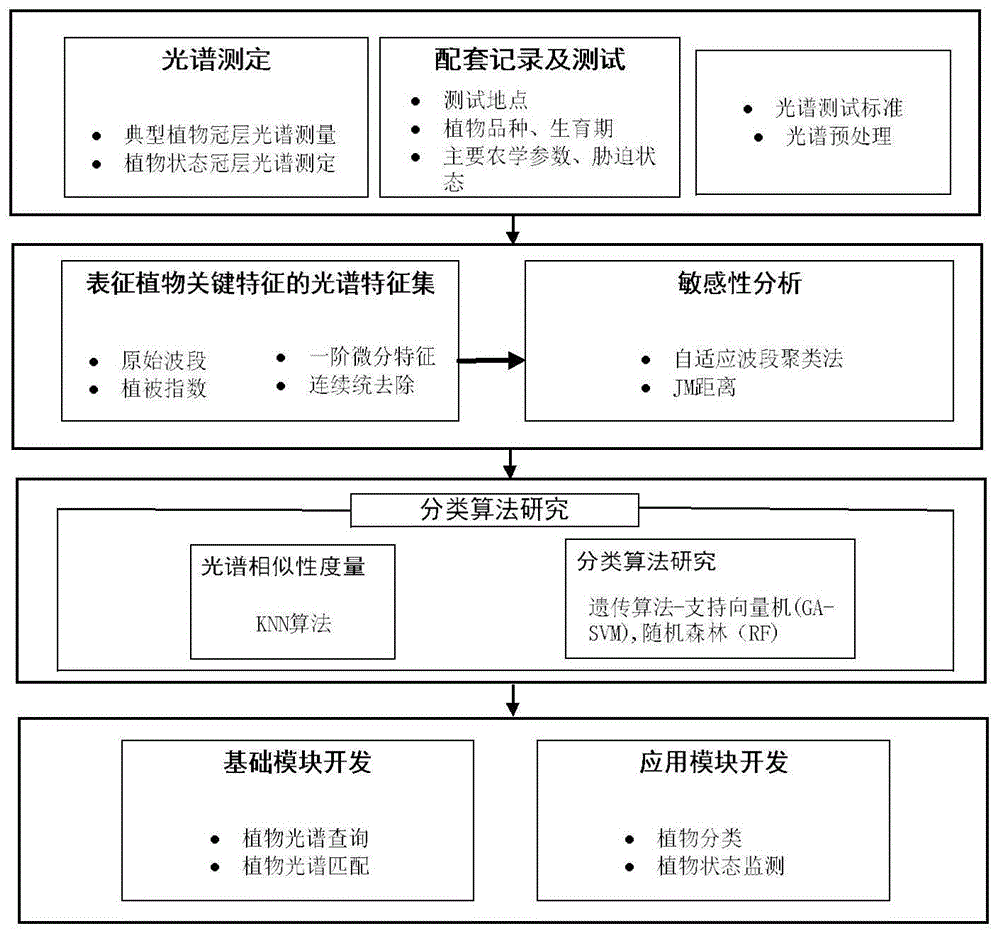
本发明涉及植物光谱库的建立和应用,具体包括基于植物光谱库的高光谱数据采集方法,基于高光谱数据的特征提取方法、特征敏感性分析方法和分类算法研究,并建立实现植物光谱及配套信息存储和查询,植物分类和状态监测等应用的植物光谱库。
背景技术:
植物分类对于农业种植区规划、营养调控、病虫害防治等农事管理十分重要;在生态学中了解植物的种类、分布,群落构成,指示生态环境变化,在园林绿化设计中植物种类选择,种植分布设计等方面都有非常重要的应用价值。利用无人机、卫星遥感影像中的光谱信息进行植物分类和状态监测可以为大面积植物分类制图提供重要手段。
光谱库技术作为遥感影像自动解译过程的重要技术在植物分类和状态监测方面具有潜力。目前为止,基于不同的应用目的,国内外学者构建了多种不同类型的地物光谱库,主要涉及岩石、植被、土壤、冰雪、建筑材料等类型。而植物遥感监测由于具有较强的特殊性,如植物的光谱反射或发射特性由其组织结构、生理生化参数和自身形态学特征共同决定,而这些特征又与植物的发育、受胁迫状况以及生长环境等密切相关。因此,需要通过大量实验和研究确定适应植物种类和状态监测特点的光谱特征,作为植物光谱库技术的核心。同时,一些传统光谱库偏重对光谱信息的浏览和查询,往往通过光谱的直接匹配或基于一些通用光谱特征进行查询,从功能上无法满足植物遥感监测这种细分领域的应用需求。针对目前专用植物光谱库技术的缺失,本方法提出一套植物光谱库构建方法,包括标准化的数据采集方法,针对植物分类和状态监测的光谱特征敏感性分析方法、光谱特征提取方法、分类建模方法等。其中,在光谱特征提取环节提出的自适应波段聚类和波段冗余信息消减方法能够有效提高光谱特征在植物分类和状态监测上的精度。依据本方法建立的植物光谱库能够为植物遥感监测的分析和应用提供有效的支持。
技术实现要素:
本发明的目的是针对现有技术的不足,提供一种植物光谱库的建立方法。该植物光谱库用于常见植物的光谱及配套信息展示、植物分类和状态监测研究。
本发明具体步骤如下:
步骤一:获取数据
采用现有技术按照严格标准规范的方法获取植物冠层高光谱数据以及配套信息,其中配套信息包括植物种类和状态信息,状态信息是指植物生育期、长势和病虫害情况等。
本发明中可以采用严格标准规范的方法,通过asdfieldspec4profr(350nm~2500nm)型光谱仪等仪器获取植物冠层光谱。之后,采用规范标准的配套信息获取方法,通过咨询专家,查阅专门书籍和资料等方式获取植物种类和状态信息等配套数据。
步骤二:光谱特征提取
根据步骤一获取的植物冠层高光谱数据和配套信息提取光谱特征,作为植物分类特征。这里的光谱特征包括原始波段特征,一阶微分特征,连续统特征和植被指数。
原始波段特征,包括所有采集的原始波段光谱数据;
一阶微分特征包括波段为490-540nm的蓝边处最大微分值(maximumdifferentialvalue(bmv)),最大微分值位置(positionofthemaximumdifferentialvalue(bpmv)),微分值之和(sumofdifferentialvalues(bsv));波段为540-620nm的黄边处最大微分值(maximumdifferentialvalue(ymv)),最大微分值位置(positionofthemaximumdifferentialvalue(ypmv)),微分值之和(sumofdifferentialvalues(ysv));以及波段为660-780nm的红边处的最大微分值(maximumdifferentialvalue(rmv)),最大微分值位置(positionofthemaximumdifferentialvalue(rpmv)),微分值之和(sumofdifferentialvalues(rsv))。
上述最大微分值、最大微分值位置、微分值之和的获取方式属于现有成熟技术,故不详解。
连续统特征主要包括近红外波段530-770nm处连续统处深度(depth)、宽度(width)和面积(area);上述深度(depth)、宽度(width)和面积(area)的获取方式属于现有成熟技术,故不详解。
植被指数特征是根据植被的光谱特性,将波段进行组合,可以构建多种植被指数。植被指数可以作为对地表植物种类、植物状态以及环境情况的简单、有效和经验的度量。本发明中具体使用的植被指数见表1。
表1植被指数
上表中,r800指800nm波长处的光谱反射率,同理,其他r波长均代表该波长处的光谱反射率,x,a,b,s等均为调节参数。
步骤三:特征敏感性分析
针对原始波段特征,为了选择出敏感性较高的波段特征,可采用jm距离作为每个波长处的敏感性指标,jm距离较大则该波长处在植物分类和状态监测中的可分离性越大,则认为该波长较敏感。但是在使用jm距离对原始波段特征进行选择的过程中,容易将一些相邻或相近波长处的波段同时选中,这些波段由于相互较高的相关性导致了大量的信息冗余,降低了特征选择的效率,故在使用jm距离作为敏感性指标前先利用自适应波段聚类法将原始光谱波段进行聚类,可将相关性较高的波长聚类,此时再利用jm距离针对每一种聚类进行分析,选取每一聚类中jm距离较大的波长作为敏感波段特征,可有效避免相关性较高的波段特征被同时选中,去除高光谱原始波段数据中的信息冗余。
针对指数特征(指代一阶微分特征、连续统特征、植被指数特征),可采用jm距离作为每个指数特征的敏感性指标,获取jm距离最大的10项作为敏感指数特征。
3.1.利用自适应波段聚类法将原始光谱波段进行聚类,将相关性较高的波长聚类;
为了去除高光谱数据中相邻或者相近波段间的高度相关性,去除数据中冗余信息,利用自适应法波段聚类,将相邻和相近波段进行聚类,主要方法和流程如下:
波段自适应聚类是基于kmeans聚类算法,但主要有两处不同。一是与常规聚类以样本为中心进行聚类不同,本发明中自适应波段聚类则是以特征维(即本例中波段)为中心进行聚类,这样可以将有效将相似波段聚类,便于后续敏感波段选择中去除相邻相近波段中的信息冗余。二是为了提高其自适应性,在聚类过程中,增加了“合并”和“分裂”两个操作,并设定了控制算法运行的参数,解决了kmeans聚类法中分类数目固定,无法根据数据性质自适应分类数目的问题。通过参数设计,可有效合并相邻相似的数据类别和分裂存在较大差异的数据类别,将波段聚类更加灵活的应用于光谱实际应用,更好的实现波段聚类。具体步骤如下:
(1)确定预定参数,可用于决定后续分析中的聚类数目。
c,期望聚类的类别数目;
tn,每类允许最少样本数
ts,为类内各分量标准差上限。
td,两个聚类中心间的最小距离下限,若小于此数,两个聚类需进行合并;
l,在一次迭代运算中可以合并的聚类中心的最多对数
it,允许的最大迭代次数
nc,初始聚类数目,与c可相同也可不同。
(2)随机产生聚类中心。根据初始确定的聚类数目nc,产生对应数目的初始聚类中心。为防止聚类中心随机获取时集中在某一处波长附近,采用分层获取分类中心,先将波长按照初始聚类数目分为nc层,再获取聚类中心;按照分层均匀分布的随机聚类中心的获取方法如下:
其中,rc为初始聚类数目nc对应的聚类中心处波长光谱,i为第i个聚类中心,ls为波段总数,nc为初始设定聚类数目,rand为0~1间的随机数,
(3)根据距离公式(2)遍历每个波长数据x,将x分类到最近的聚类中心scj,获取聚类中心scj处的聚类scj;
dj=min{||x-sci||,i=1,2,…,j,…,nc}式(2)
x为波长光谱数据,sci为第i个聚类中心,dj表示某一波长数据与所有聚类中心距离中最小处的距离值,该中心为第j类聚类中心,将该波长光谱归类为该聚类。
(4)去除聚类中波段数目较少的类别。
当所有聚类sc中某一个聚类内波段数目sci<tn时,取消该聚类,并删除其聚类中心sci,同时判断迭代次数,若当前迭代次数达到允许的最大迭代次数it,则结束,若未达到则返回第3步。直至所有聚类的样本数目均满足sci>tn,则执行第5步,tn为每类允许最少样本数。
(5)修正聚类中心。
计算步骤4处理后每个聚类的样本平均值,并作为新的聚类中心。
sci=nsci式(4)
其中,nsci为新的聚类中心,sci为第i个聚类中的波段数目,sci为第i个聚类,x为聚类sci中的波长光谱数据,sci为更新后的第i个聚类中心。
(6)计算各聚类sc中样本与各聚类中心间的平均距离。
其中,
(7)计算全部波长数据和其对应聚类中心的总平均距离。
其中,
(8)若当前迭代次数达到最大迭代次数,结束;否则接着判定是否满足
(9)分裂。
计算每个聚类中样本距离的标准差向量;
σi=(σ1iσ2i,…,σbi…,σni)t式(7)
其中t表示向量转置,向量的各个分量为
其中,b=1,2,…n,表示第b个光谱样本,i=1,2,…k,…,nc,σi为第i个聚类中的标准差向量,σ1i,σ2i,…,σni为每个光谱样本在第i个聚类中的标准差,sci为第i个聚类中波段数目。求每一标准差向量{σi,i=1,2,…,nc}中的最大分量,以{σimax,i=1,2,…,nc}代表。在任意一个聚类集{σimax,i=1,2,…,nc}中,若存在σimax>ts,同时又满足如下两个条件之一:
1)
2)
ts为t类内各分量标准差上限,tn为每类允许最少样本数,同一聚类域中样本距离分布的标准差则将sci分裂为两个新的聚类中心,且nc加1。其中一个新的聚类中心是sci对应的σimax处分量加上k倍σimax,另一个是sci对应的σimax处分量减去k倍σimax,k为定义的倍数。
否则返回第三步。
(10)合并运算。
计算全部聚类中心两两之间的距离;
dij=||sci-scj||式(9)
其中,dij为第i个聚类中心和第j个聚类中心之间的距离。比较dij与td的值,将dij<td的值按距离递增排列,td为两个聚类中心间的最小距离下限,即
其中
将符合上述条件式(9)~(11)的聚类中心进行合并,获取新的合并中心,如下式(12):
sc*为合并后的新中心,
反之则返回第三步。
(11)如果是最后一次迭代运算(即第it次),则结束;否则,若改变输入参数,转至第一步;若输入参数不变,转至第二步。
3.2jm距离
将jm距离作为敏感波段特征和敏感指数特征选择的指标,由于jm距离为衡量两个类别样本距离的方法,面对多类别样本,本发明中对每个特征遍历其在所有每两类样本间的jm距离,并求均值作为衡量某个特征在所有类别中的敏感性。敏感波段选择中,找出自适应聚类结果中每类中jm距离较大的值作为敏感波段,指数特征则直接选择jm距离最大的10项特征作为敏感特征。jm距离代表特征的概率分布距离,该值越大,说明此特征在两类间的可分性较强。
求两个类别间的jm距离,这里的类别指两种植物种类或者状态区别的类别,与上述在波段维度聚类的类别定义不同(即聚类对象是特征维,jm距离分析对象是样本维)。类别ωi和类别ωj之间的jm距离定义为:
其中r是维数k的特征向量,p(r|ωi)和p(r|ωj)是r的两个类条件概率分布。当p(r|ωi))和p(r|ωj)是高斯分布时,jm距离可以简化为:
其中
是wi和wj之间的bhattacharyya距离。在这里,μi和μj是类内均值,∑i和∑j是类协方差矩阵。
步骤四:确定合适模型
利用基于最近邻的knn算法,基于统计数学方法和优化技术的遗传算法结合支持向量机算法(ga-svm),基于概率模型的随机森林(rf)等算法,分别对敏感波段、指数特征(包括微分特征,连续统特征和植被指数)以及全部特征(波段加指数)三类进行建模分析,获取模型精度;选取总体分类精度(oaa)和kappa系数作为精度指标,精度指标最大认定为适合模型。其中,
式中,row为混淆矩阵交叉表的行的数量;xii为沿着对角线上的类型组合的数量;xi+为行i的总的观测数;x+i为列的总的观测数量;n为单元格的总数量。
本发明采用标准化的数据采集方法收集数据,提出一套完整齐备的光谱特征提取方法、特征敏感性分析方法、模型建立方法并进行植物分类和状态监测研究,其中提出波段自适应聚类法可有效去除相邻或相近波段中的信息冗余,有效提高数据使用效率。基于上述方法,建立植物光谱光谱库,可含有植物的光谱查询和光谱匹配,植物分类和状态监测功能。
附图说明
图1为本发明流程图;
图2为波段自适应聚类流程图;
图3为经济作物冠层光谱曲线和图片;
图4为ga-svm精度图(混淆矩阵转化为准确率矩阵),(a)对应“敏感波段特征”,(b)对应“敏感指数特征”,(c)对应“敏感波段+敏感指数特征”)。
具体实施方式
以下结合附图对本发明作进一步说明。
一种植物光谱库的建立方法,如图1所示,具体是:
步骤一:获取数据
植物光谱数据采集。本研究中植物高光谱数据测量按照植物冠层高光谱测量标准,于2017年5月至9月在浙江省杭州市(lon120.34°,lat30.31°)内选择多个试验点进行,由asdfieldspec4profr(350nm~2500nm)型光谱仪采集农田植物包括豇豆,由大豆,番薯,花生,苋,茄子,芝麻,柑橘,桃,攸县油茶,银杏,柚,枇杷,茶树,水稻,小麦等16种植物,共450条光谱,植物冠层光谱曲线和图片如图3。
步骤二:光谱特征提取
asd高光谱数据提取完成特征包括去除水汽带所有原始光谱波段,9个微分特征,3个连续统特征,27个植被指数特征(具体见发明内容步骤二)。
步骤三:特征敏感性分析
采用isodata、jm距离等方法挑选光谱波段特征以及光谱微分,连续统和植被指数特征(以下简称此三类特征为指数特征)。图1为波段自适应聚类流程图。
将波段聚类获得9个类别,取每个类别中jm距离最大值处波段为特征波段,为了去除波段之间信息冗余以及jm距离较小的波段,去除相邻或相近波段中jm距离较小值处的波长特征,共获得394nm,696nm,731nm,1037nm,1505nm,1585nm,2020nm,2130nm,2224nm等9个波段和width,rmv,atsavi,pvihyp,wi,siwsi,ndii,nri,slaidi,ndwi等10个指数特征。
步骤四:选择合适的模型
根据总的分类精度(oaa)和kappa系数,可得三种分类方法分类精度如表所示(表)。由表可得ga-svm算法在经济作物中分类精度最高,混淆矩阵如图4所示(将混淆矩阵内所有分类样本频数与各预测分类类别中样本总数计算比值将矩阵转化为准确率矩阵),故将此方法作为光谱库农田场景植物分类应用方法。
表2各方法分类精度
上述实施例并非是对于本发明的限制,本发明并非仅限于上述实施例,只要符合本发明要求,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!