一种基于CEEMDAN的金融时间序列组合预测方法与流程
本发明属于金融风险管理领域,涉及一种金融时间序列预测方法,具体涉及一种基于适应性噪声的完全集合经验模态分解(completeensembleempiricalmodedecompositionwithadaptivenoise,ceemdan)的金融时间序列组合预测方法。
背景技术:
股票市场价格预测一直以来都是专业研究者和投资者非常感兴趣的领域。股票价格变化具有非线性和非平稳性,可靠且准确地预测价格波动非常困难。从预测研究方法来看,目前主要有基本面分析法和技术分析法。基本面分析法主要是根据宏观经济政策、行业发展潜力、企业盈利状态等方面的信息来预测价格走势,由于该方法难以定量,所以实现难度大。技术分析法主要依靠定量的技术指标、历史价格等可量化的数据来建立预测模型,本专利即采用该方法。
金融时间序列表现出混沌性,即在短期趋势上看是随机变换的,但在长期趋势上看确是稳定的。为了将金融时间序列的长短期趋势分离开,解决非线性和非稳定性数据难以直接进行预测的问题,经验模态分解(empiricalmodedecomposition,emd)被应用于金融数据分析中,它是一种信号时频分析方法,能实现对非平稳非线性数据的平稳化,对金融数据的分析起到了很大作用。然而,emd存在一些缺陷,主要是模态混叠问题和模态间不正交问题。黄锷等人于2009年提出了集合经验模态分解(ensembleempiricalmodedecomposition,eemd),将高斯白噪声加入原始信号中再进行分解,取得了不错的效果。但由于人为选择白噪声的不同,分解得到的本征模函数也有差异,这使得eemd方法不稳定,而且eemd方法难以完全消除由加入的高斯白噪声引起的重构误差。为了进一步地解决这些问题,2011年torres等人提出了eemd的改进算法:ceemdan。ceemdan能够完成更好的本征模函数分离,能够精确地重构原始信号,而且具有比eemd算法更低的运算成本。
对于金融时间序列预测,有传统的统计学方法以及神经网络方法等,传统的统计学方法需要对时间序列进行平稳性处理、参数估计、验证等,过程繁琐且由于金融时间序列本身的非平稳特性,得到的模型鲁棒性较差。之后很多研究采用传统的神经网络方法,该方法相比于传统的统计学方法准确率有所提升,但只应用了最近时刻的数据,导致更早时刻的数据所携带的信息丢失。而股票市场的价格变化不仅与当前时刻的数据相关,而且与更早时刻的数据有关。长期短期记忆(longshort-termmemory,lstm)作为rnn的改进模型,已经大量的运用于自然语言识别、时间序列预测等领域。lstm通过一种“门”的结构使信息选择性地通过,这使得神经网络在训练时能够在历史数据中提取更有用的信息。原始的金融时间序列经ceemdan分解为若干个本征模函数(intrinsicmodefunction,imf)子序列和一个余项,本专利经过实验对比不同模型(多层感知器(multi-layerperceptron,mlp)、lstm、支持向量回归(supportvectorregression,svr))对不同imf子序列和余项的预测误差,发现lstm网络对各个imf子序列预测更具优势,而svr在对余项进行预测时有更好的准确率,因为余项序列的变化较为平缓,在局部表现出线性变化的形式,svr模型在对余项进行预测时,使用的是线性核函数,能够提升其预测性能。于是本专利将这两种不同的预测算法在模型的内部进行组合,从而提升预测性能,能够很好地克服现有金融时间序列预测方法过程繁琐,难以对非线性和非稳定性金融数据进行直接预测及预测准确率低的问题。
技术实现要素:
针对上述现有金融时间序列预测方法的现状和存在的问题,本发明提出一种结合ceemdan,lstm及svr的模型来预测金融时间序列,克服现有金融时间序列预测方法过程繁琐,难以对非线性和非稳定性金融数据进行直接预测及预测准确率低的问题。
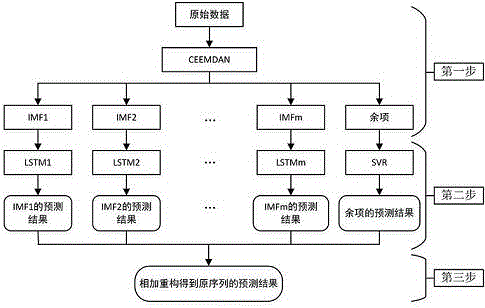
本发明提出的金融时间序列组合预测方法,该组合模型算法流程图如图1所示。其技术方案为:1)通过ceemdan算法,将原始的金融时间序列
本发明的方法采用了“分治思想”来解决金融时间序列预测问题。通过经验模态分解方法,将难以拟合的原始股票指数收盘价序列分解为多个有明显周期性且较为平滑的子序列,避免了使用lstm网络直接对非线性和非稳定性数据进行预测的难题。各个子序列由不同的lstm网络和svr网络进行训练拟合,充分发挥了深度学习算法学习能力强、适应性好的优点。组合模型单独将经验模态分解得到的余项数据用svr来进行预测,发挥了其在线性回归问题上的优势。该方法具有比传统方法以及单独的神经网络方法更准确的预测效果,在金融时间序列的短期预测中表现出更好的性能。
附图说明
图1组合模型算法流程图。
图2lstm预测模型的网络结构图。
具体实施方式
下面结合具体实施方式对本发明做进一步的详细说明。
1.通过ceemdan算法,将原始的金融时间序列
2.预测模型构建;
1)采用lstm单元来搭建一个可靠的时间序列预测网络,输入imf子序列
该网络由两层lstm单元和一层全连接网络组成,采用双层lstm网络学习时间序列中的抽象模式,是该网络的核心部分。该网络的结构如图2所示,由于lstm单元的输出是一个多维向量,因此将第二层(layer2)网络的最后一个lstm单元的输出与第三层(layer3)的全连接网络连接。在训练过程中,网络中的参数不断迭代更新,在第四层(layer4)的一个单元中将输出一个预测结果。这就是时间序列单步预测的网络结构,输入
所有全连接层神经元的激活函数均为relu函数,并且使用均方误差作为损失函数,其公式如下:
其中,
2)搭建svr模型,输入余项
模型搭建好后,分别训练得到最优的网络参数,再将测试集数据输入到训练好的网络中,保存测试集的预测结果为
3.将得到的各个imf分量和余项的预测序列相加重构,得到最终的预测结果,其重构公式如下;
其中,
为了验证本专利所提出方法的优越性,将其与其他一些方法做对比,包括lstm模型、svr模型、ceemdan-svr模型、ceemdan-mlp模型。所有模型均使用同样的数据集,原始的指数收盘价数据将直接作为lstm、svr模型的输入进行模型训练,其余模型均使用ceemdan方法分解得到的数据来训练。表1给出了本专利提出的组合模型(ceemdan-lstm-svr)与其他模型在标普500指数(standard&poor500index,s&p500)、恒生指数(thehangsengindex,hsi)、德国股票指数(thedeutscheraktienindex,dax)、上海证券交易所综合指数(theshanghaistockexchangecompositeindex,sse)的预测误差。由表1可知,本专利提出的组合模型在四种指数数据上的三项预测误差指标mae、rmse、mape均要小于其他模型,在方向统计ds上的正确率要比其他模型高。四种指数数据的测试集样本均为2017年一年的数据(有250个左右的交易日数据),实验结果表明,组合模型在四种数据集上对价格波动方向的预测准确率都在80%以上。
表1不同预测方法的预测误差对比
几种评价标准的计算公式如下:
上述评价标准中,dt代表原始数据在t时刻的真实值,yt代表模型在t时刻的预测值,n为测试集样本的个数。mae、rmse、mape的值越小,说明预测值越接近真实值,而ds的值越大,说明模型对股票价格的波动方向预测越准确。
- 还没有人留言评论。精彩留言会获得点赞!