一种面向计算资源局限平台部署的实时目标检测的方法与流程
本发明涉及一种面向计算资源局限平台部署的实时目标检测的方法,属于深度学习和图像处理领域。
背景技术:
物体检测是许多新兴领域的重要任务,如机器人导航,自动驾驶等。在这些复杂场景中,基于深度学习方法的对象检测方法比传统方法具有更大的优势,基于深度学习的目标检测算法不断兴起,如r-cnn、sppnet、fast-r-cnn、faster-r-cnn、r-fcn和fpn。虽然这些物体检测算法达到了前所未有的准确度,但检测速度并不快,远远不能满足在低计算能力设备上的实时性的要求。同时,深度学习模型大小通常占用大量存储空间并且需要强大的gpu计算能力,然而在大多数的实际应用场景中,无法在设备上放置功能强大的gpu工作站。
因此,需要寻找一种同时具有出色的实时性能和更小的模型尺寸的物体检测算法。yolo是具有实时性能和高精度的最快的物体检测方法之一,youonlylookonce(yolo)自引入以来一直在不断优化,yolo-v1有两个全连接层和24个卷积层,其规模达到1gb,占用存储空间非常大,对运行平台的性能要求非常高。在此基础上,yolo-v2删除完全连接的图层并使用锚框来预测边界框,yolo-v3利用残差结构进一步加深网络层,实现精度的突破,与此同时,yolo的tiny版本占用的存储空间更少,tiny-yolo-v3只有34mb,达到了前所未有的轻量级,但移动终端的存储容量仍然不小。
但是,目前所有版本的yolo都无法在嵌入式和移动设备上实现实时性能。yolo仍然需要在轻量级和实时性方面进行大量改进。根据yolo的发展趋势和当前的实际应用场景,减少模型参数、减少存储空间和提高精度是当前的发展趋势。如何实现yolo在嵌入式和移动设备上实现实时和精确的性能,实现多个物体的实时监测,仍是一个重大的挑战。
highway和resnet结构中均提出了一种数据旁路(skip-layer)的技术来使得信号可以在输入层和输出层之间高速流通,核心思想都是创建了一个跨层连接来连通网路中前后层,之后由康奈尔大学、清华大学、facebookfair实验室合著的《denselyconnectedconvolutionalnetworks》对其进行了详细的阐述,为了最大化网络中所有层之间的信息流,作者将网络中的所有层两两都进行了连接,使得网络中每一层都接受它前面所有层的特征作为输入。由于网络中存在着大量密集的连接,作者将这种网络结构称为dense连接。dense连接具有能够减轻梯度弥散的问题,使模型不容易过拟合;能够增强特征在各个层之间的流动,大大减少参数个数,提高了训练效率等优点。
squeezenet是在利用现有的基于卷积神经网络(convolutionalneuralnetworks,cnn)模型并以有损的方式压缩的一种小型模型的网络结构。利用少量的参数训练网络模型,实现模型的压缩。它采用firemodle模型结构,分为压缩部分和扩展部分,利用压缩部分和扩展部分相连接形成一种fire模块中组织卷积过滤器。通常的squeezenet开始于一个独立的卷积层(conv1),然后是8个fire模块,最后是一个最终的转换层(conv10)。
技术实现要素:
为了解决上述问题,本发明提供了一种可用于多目标实时检测的方法,本发明方法能够在嵌入式设备如jetsontx1、jetsontx2和移动设备上运行进行目标检测,准确率和实时性均高于yolo的tiny版本。
具体的,本发明的技术方案为:一种基于图像处理的目标检测的方法,所述方法包括以下步骤:
(1)在含有gpu的平台部署tinier-yolo,通过摄像头采集画面;
(2)tinier-yolo读取摄像头采集到的图像;
(3)tinier-yolo检测识别目标信息;
(4)将目标检测的结果信息实时输出到设备屏幕或摄像头自带的屏幕上;
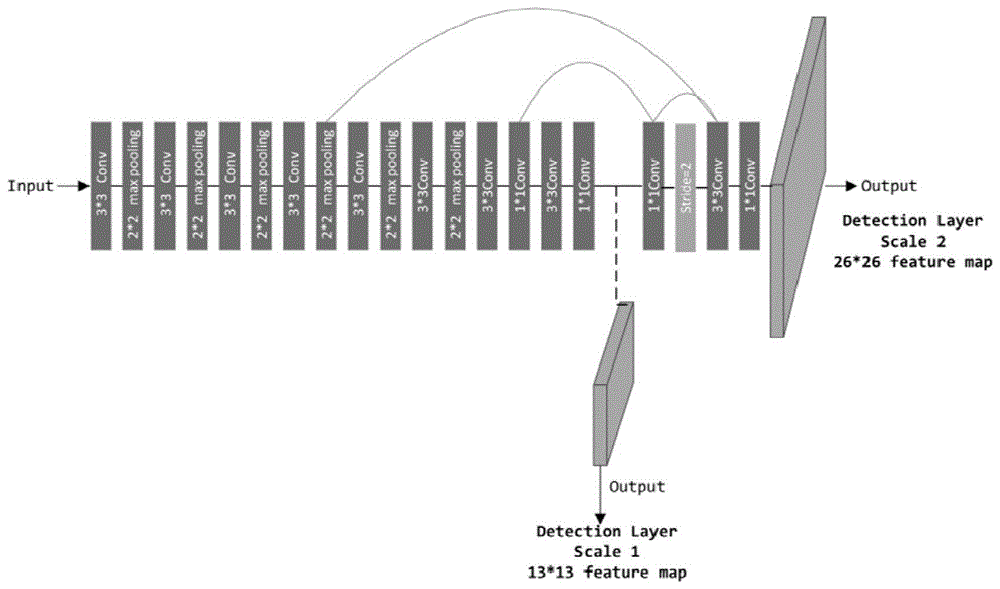
其中,所述tinier-yolo为改进的yolo-v3-tiny网络结构:保留yolo-v3-tiny网络结构的前五个卷积层和池化层的交替运算,其后依次连接五个squeezenet中的fire模块,输出至第一个直通层,之后所述直通层连接第六个squeezenet中的fire模块,并使用dense连接将五个fire模块的输出特征图和第六个fire模块的输入相连,第六个fire模块的数据输出至第二个直通层和一个1*1瓶颈层,之后的数据再经过上采样层放大图像得到特征图大小为26*26的第三个直通层,之后再依次连接第七个和第八个squeezenet中的fire模块进行数据压缩,之后数据输出至1*1瓶颈层,连接输出端,输出的特征图大小为26*26,此外,第一个直通层和第三个直通层分别与第五个卷积层连接,获取第五个卷积层的输出特征;第六个squeezenet中的fire模块处也连接有输出端,输出的特征图大小为13*13;重新训练网络,即可得到tinier-yolo。
在本发明的一种实施方式中,所述直通层是自yolo-v2算法中引入的。
在本发明的一种实施方式中,所述使用dense连接将五个fire模块的输出特征图和第六个fire模块的输入相连是指:第一个到第五个fire模块的输出同时作为第六个fire模块的输入。
在本发明的一种实施方式中,所述第三个直通层将放大后的图像与第五个卷积层的特征图的输出进行了特征融合。
在本发明的一种实施方式中,所述画面为图片或者视频中的画面。
在本发明的一种实施方式中,所述目标为人、移动物体或者静止物体。
在本发明的一种实施方式中,所述目标优选为人或移动物体。
在本发明的一种实施方式中,所述移动物体为交通工具或动物。
在本发明的一种实施方式中,所述交通工具为飞机、船舶、火车、公共汽车、汽车、摩托车或自行车等。
在本发明的一种实施方式中,所述动物为猫、狗、羊、马、牛、鸟等。
在本发明的一种实施方式中,所述含有gpu的平台为任一存储空间不小于10mb的设备,例如jetsontx1、jetsontx2、ipone、华为等智能手机;尤其的,本发明方法能够适用于计算资源局限的平台,即具有gpu处理性能的嵌入式平台或移动设备。
在本发明的一种实施方式中,所述具有gpu处理性能的嵌入式平台为jetsontx1或jetsontx2等性能相当的嵌入式设备。
本发明还提供了一种基于图像处理的目标检测的装置,所述装置包括采集装置、计算模块和输出模块,其中,计算模块包括计算网络和硬件设备,所述图像采集模块用于采集数据,计算网络在硬件设备上运行以读取采集得到的图像并对行目标进行检测,之后将检测信息通过硬件设备或图像采集装置输出;
其中,所述tinier-yolo为改进的yolo-v3-tiny网络结构:保留yolo-v3-tiny网络结构的前五个卷积层和池化层的交替运算,其后依次连接五个squeezenet中的fire模块,输出至第一个直通层,之后所述直通层连接第六个squeezenet中的fire模块,并使用dense连接将五个fire模块的输出特征图和第六个fire模块的输入相连,第六个fire模块的数据输出至第二个直通层和一个1*1瓶颈层,之后的数据再经过上采样层放大图像得到特征图大小为26*26的第三个直通层,之后再依次连接第七个和第八个squeezenet中的fire模块进行数据压缩,之后数据输出至1*1瓶颈层,连接输出端,输出的特征图大小为26*26,此外,第一个直通层和第三个直通层分别与第五个卷积层连接,获取第五个卷积层的输出特征;第六个squeezenet中的fire模块处也连接有输出端,输出的特征图大小为13*13;重新训练网络,即可得到tinier-yolo。
在本发明的一种实施方式中,所述直通层是自yolo-v2算法中引入的。
在本发明的一种实施方式中,所述使用dense连接将五个fire模块的输出特征图和第六个fire模块的输入相连是指:第一个到第五个fire模块的输出同时作为第六个fire模块的输入。
在本发明的一种实施方式中,第三个直通层将放大后的图像与第五个卷积层的特征图的输出进行了特征融合。
在本发明的一种实施方式中,所述硬件设备所述含有gpu的平台,所述含有gpu的平台为任一存储空间不小于10mb的设备,例如jetsontx1、jetsontx2、ipone、华为等智能手机;尤其的,本发明方法能够适用于计算资源局限的平台,即具有gpu处理性能的嵌入式平台或移动设备。
在本发明的一种实施方式中,所述有gpu处理性能的嵌入式平台或移动设备优选为jetsontx1或jetsontx2。
本发明取得的有益技术效果:
(1)本发明的tinier-yolo的模型尺寸仅为7.9mb,仅为yolo-v3-tiny的34.9mb的1/4,为yolo-v2-tiny的1/8;其模型尺寸的减小并未影响其实时性和准确度,与之相反,本发明的tinier-yolo的实时性能与yolo-v3-tiny相比提高了21.8%,与yolo-v2-tiny相比提高了70.8%;准确度与yolo-v3-tiny相比,tinier-yolo的map平均精度均值提高了10.1%,与yolo-v2-tiny相比提高了近18.2%;可见,本发明的tinier-yolo能够实现在计算资源有限的平台上仍然可以进行实时检测的目的,且效果更好。
(2)本发明在计算网络中引入火层,减少了模型参数的数量,增加了整个网络的深度和宽度,保证了模型检测的准确性;此外,本发明利用dense连接提高准确率,本发明通过合适的dense连接使得本发明的tinier-yolo在提高准确率的基础上,保证实时性不受损失。
(3)本发明的tinier-yolo实现了在嵌入式平台上的安装和实时监测,对服务器通信需求较小,经过训练,能够准确的检测出80余种物体,克服了现有技术中的计算网络无法在嵌入式平台上进行时实运算的问题。
附图说明
图1yolo-v3-tiny的网络结构示意图。
图2本发明的tinier-yolo的网络结构示意图,其中,(1)为第一个fire模块,(2)为第二个fire模块,(3)为第三个fire模块,(4)为第四个fire模块,(5)为第五个fire模块,(6)为第六个fire模块,(7)为第七个fire模块,(8)为第八个fire模块,(9)为第一个直通层,(10)为第二个直通层,(11)为第三个直通层。
具体实施方式
ap:即averageprecision,平均精度,其计算公式如下:
其中,p(i)是指给定阈值i的时的精度,δr(i)是指k和k-1之间的recall变化值。
训练和测试的数据集来源于pascalvoc(thepatternanalysis,statisticalmodellingandcomputationallearningvisualobjectclassesproject),分为voc2007和voc2012两部分,本发明可以根据需要训练不同物体的类别,使用voc2007数据集的5011张图片和voc2012数据集的11540张图片做训练数据,训练数据共16551张,测试集为voc2007测试集,共4952张测试图片。
实施例1
本发明的技术方案为:一种基于图像处理的物体检测的方法,所述方法包括以下步骤:
(1)在jetsontx1部署tinier-yolo,通过摄像头采集画面;
(2)tinier-yolo读取摄像头采集到的图像,其中,
所述tinier-yolo为改进的yolo-v3-tiny网络结构:保留yolo-v3-tiny网络结构的前五个卷积层和池化层的交替运算,其后依次连接五个squeezenet中的fire模块,输出至第一个直通层,之后所述直通层连接第六个squeezenet中的fire模块,并使用dense连接将五个fire模块的输出特征图和第六个fire模块的输入相连,第六个fire模块的数据输出至第二个直通层和一个1*1瓶颈层,之后的数据再经过上采样层放大图像得到特征图大小为26*26的第三个直通层,之后再依次连接第七个和第八个squeezenet中的fire模块进行数据压缩,之后数据输出至1*1瓶颈层,连接输出端,输出的特征图大小为26*26,此外,第一个直通层和第三个直通层分别与第五个卷积层连接,获取第五个卷积层的输出特征;第六个squeezenet中的fire模块处也连接有输出端,输出的特征图大小为13*13;重新训练网络,即可得到tinier-yolo;所述直通层是自yolo-v2算法中引入的;所述使用dense连接将五个fire模块的输出特征图和第六个fire模块的输入相连是指:第一个到第五个fire模块的输出同时作为第六个fire模块的输入;第三个直通层将放大后的图像与第五个卷积层的特征图的输出进行了特征融合。
(3)tinier-yolo检测识别物体信息;
(4)通过jetsontx1将物体检测的结果信息实时输出到电脑上或者显示屏上。
按照同样的方法利用yolo-v2-tiny和yolo-v3-tiny神经网络进行同样的物体检测,并对三种不同神经网络以及检测的结果数据进行比较。
(1)神经网络的模型尺寸
对yolo-v2、yolo-v2-tiny、yolo-v3-tiny和tinier-yolo这四种神经网络模型的模型尺寸和flops(每秒浮点运算次数)进行对比,结果如表1所示,可见tinier-yolo神经网络的模型尺寸仅为7.9mb,为yolo-v3-tiny的34.9mb的1/4,为yolo-v2-tiny的1/8。
flops(每秒浮点运算次数)通常用于衡量模型所需的计算能力,flops越大,对器件的要求越高,从表1可见,tinier-yolo的flops非常低,较其余算法更适合嵌入式ai环境中。
表1不同神经网络模型的存储大小和flops值
—表示暂无数据。
(2)实时性能
对不同的神经网络进行实时性能测试,可见,本发明的tinier-yolo在jetsontx1的平台上,可以检测26.3fps的物体,如表1所示,与yolo-v3-tiny相比,实时性能提高了21.8%,与yolo-v2-tiny相比提高了70.8%。可见,本发明的tinier-yolo不仅能够在嵌入式平台上使用,且能够实现实时监测的性能。
(3)平均精度map
针对三种不同的神经网络yolo-v2-tiny、yolo-v3-tiny和tinier-yolo,按照实施例1的步骤进行不同的物体进行检测,平均精度见表1和表2,可见,与yolo-v3-tiny相比,tinier-yolo的准确度提高了6.2%,对鸟类单项提升12.3%,对瓶子和盆栽植物等物体的检测平均精度也提升达到10%以上,见表2。与yolo-v2-tiny相比平均精度提高了近10.4%,对瓶子类别单项的检测平均精度提升25.8%。tinier-yolo通过直通层和多尺度预测获取了更多的细粒度特征,提升了对小目标的检测能力,表中加粗数值为tinier-yolo表现较优数值。
综上可知,本发明的tinier-yolo不仅仅模型尺寸大幅度减小,且实时性能有所提高,同时能够提高检测的准确性,可见,本发明提供了一种能够用于嵌入式平台的实时监测的方法,解决了现有技术无法在在嵌入式平台上进行实时监测的问题。
表2不同神经网络模型进行物体检测的平均精度
对比例1
当dense连接使用在保留的yolo-v3-tiny网络结构的前五个卷积层时,即第二卷积层的输入为第一卷积层的输出,第三卷积层的输入为第一和第二卷积层的输出,第四卷积层的输入为第一到第三卷积层的输出,第五卷积层的输入为第一到第四卷积层的输出,其余和本发明的tinier-yolo网络结构一致且前五个fire模块不与第六个fire模块的输入进行dense连接;训练网络,并按照实施例1的方法进行物体监测。
对其实时性能进行测试,结果见表1,可见,此改动不仅大大增加了计算量,且这极大地影响了实时性能,检测速度(实时性能)仅为13.3fps,模型也相对较大,精度提升不够。对比例1的速度性能较差是由于网络前部分的卷积层特征图尺寸较大,其所带来的计算量倍增所导致。
对比例2
当使用dense连接将5个fire模块和第五层最大池化层进行连接时,即第二个fire模块的输入是第一个fire模块的输出,第三个fire模块的输入是第一个和第二个fire模块的输出,以此类推,同时,第五层最大池化层的输出分别为第一个到第五个fire模块的输入,其余部分和本发明的tinier-yolo一致且前五个fire模块不与第六个fire模块的输入进行dense连接,训练网络,并按照实施例1的方法进行物体监测。
对其实时性能进行测试,结果见表1,可以发现,本对比例对较小的"13×13"特征图的火层模块之间进行了频繁的密集连接,检测速度已经达到实时,模型大小和map也得到了提升。但是对比本发明的tinier-yolo,对比例2中即使使用如此频繁的连接,精度并不会有所提高,反而会导致参数和计算量的增加,方式2存在冗余连接。本发明的tinier-yolo使用前五层火层的输出特征图密集连接到第六层火层的输入,较方式2具有更好的实时性能,map提高将近2%,且模型减少了1mb。
虽然本发明已以较佳实施例公开如上,但其并非用以限定本发明,任何熟悉此技术的人,在不脱离本发明的精神和范围内,都可做各种的改动与修饰,因此本发明的保护范围应该以权利要求书所界定的为准。
- 还没有人留言评论。精彩留言会获得点赞!