一种基于中医古籍文献的短语挖掘方法和系统与流程
本发明属于信息处理及中医文献检索领域,具体涉及一种基于中医古籍文献的短语挖掘方法和系统。
背景技术:
中医是有着数千年历史的医学技术,中医文献是一种传承中医科学与技术的重要媒介。中医文献的历史决定了中医文献不同于现代其他文献的独特性。中医文献卷帙浩繁,其中,中医古籍文献涉及的专有名词数量巨大,有众多的生僻字,如何更加有效、全面的利用和阅读中医古籍文献,影响着中医的发展和传承。
计算机与互联网技术的发展,改变了人们阅读文献的方式和速度。为了更快的学习和掌握中医理论,在治疗中更好的应用中医技术,也需要以更加高效的方式阅读、整理、存储中医文献。如何利用计算机与互联网技术进行中医古籍文献的挖掘,是知识工程中医领域中的重要内容。
现有技术中,一般通过现有的数据挖掘技术对中医文献进行挖掘。专利号为cn201611174644.8的中国专利,公开了一种基于数据挖掘的中医医学文献分类及存储方法,通过数据挖掘技术,对中医文献中的信息进行相应编码、标识和组合。但是,该技术并没有区分中医古籍文献与其他科技文献的不同之处,不能有针对性的对具有自己特点的中医古籍文献进行数据分析与处理,无法应用于古籍文献利用和检索。
技术实现要素:
本发明要解决的技术问题是提供一种基于中医古籍文献的短语挖掘方法及系统,通过短语挖掘与古籍分词及中医古文语言知识库的结合,充分利用现有的公共知识库,对中医古籍文献进行高效、智能的短语挖掘。
为解决上述技术问题,本发明实施例提供一种基于中医古籍文献的短语挖掘方法,所述方法包括如下步骤:
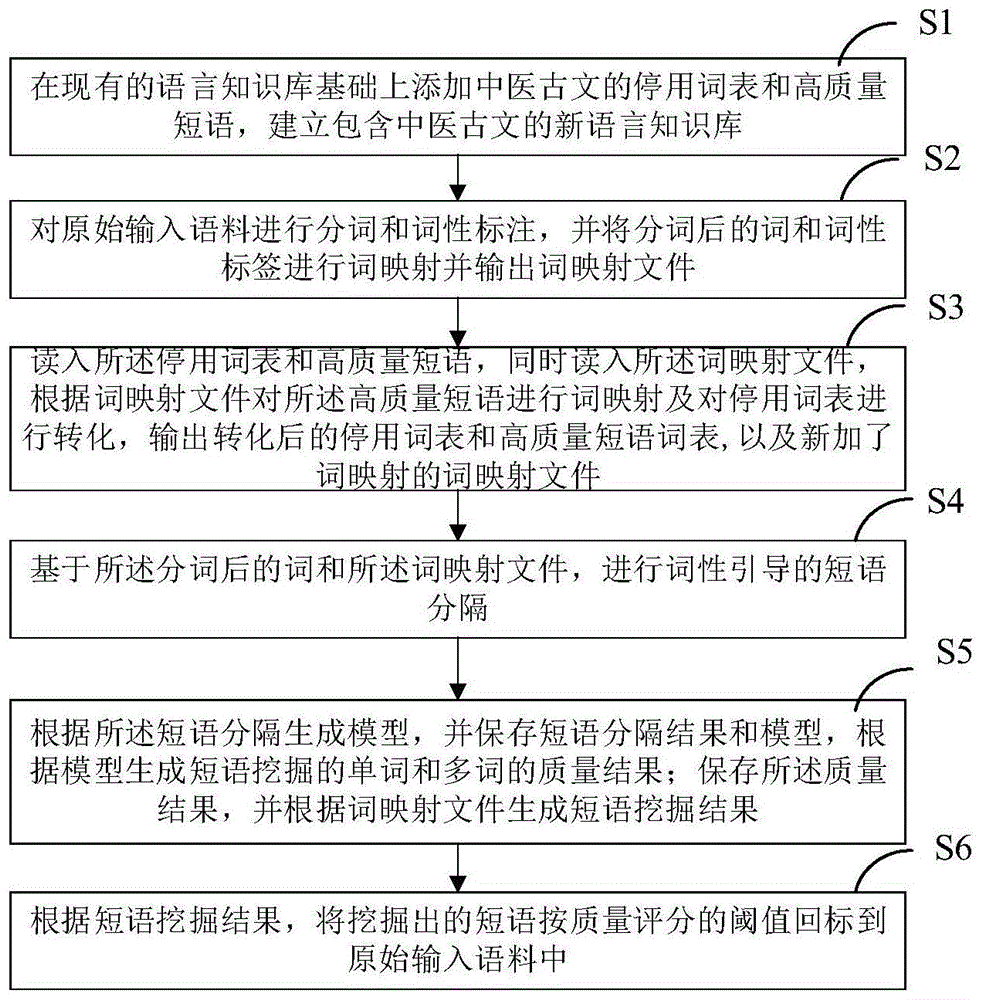
步骤s1,在现有的语言知识库基础上添加中医古文的停用词表和高质量短语,建立包含中医古文的新语言知识库;
步骤s2,对中医古籍文献原始输入语料进行分词和词性标注,并将分词后的词和词性标签进行词映射并输出词映射文件;
步骤s3,读入所述停用词表和高质量短语,同时读入所述词映射文件,根据词映射文件对所述高质量短语进行词映射及对停用词表进行转化,输出转化后的停用词表和高质量短语词表,以及新加了词映射的词映射文件;
步骤s4,基于所述分词后的词和所述词映射文件,进行两次词性引导的短语分隔;
步骤s5,根据所述短语分隔生成模型,并保存短语分隔结果和模型,根据模型生成短语挖掘的单词和多词的质量结果;保存所述质量结果,并根据词映射文件生成短语挖掘结果;
步骤s6,根据短语挖掘结果,将挖掘出的短语按质量评分的阈值回标到原始输入语料中。
上述方案中,所述步骤s2中分词和词性标注,使用面向中医古籍文献的分词方法。
上述方案中,所述步骤s2进一步包括:对分词后的词进行映射后,将中医古籍文献的原始输入语料转化为词映射后的语料,使原始中文古文语料转化为计算机能够识别的输入。
上述方案中,所述步骤s4中词性引导的短语分隔,包括以下步骤:
步骤s401,加载原始输入语料、停用词表、新语言知识库的质量短语;
步骤s402,根据短语出现的频率挖掘出常用短语;
步骤s403,将所述常用短语作为短语候选者,根据预设标准抽取特征;
步骤s404,对所述短语候选者,在新语言知识库中进行匹配,若匹配成功,到则放入正样本池;否则,放入负样本池;
步骤s405,根据所抽取的所述特征、正样本池和负样本池,进行第一次短语质量评估;
步骤s406,将所述短语候选者返回原始输入语料中,进行短语分隔;
步骤s407,根据所述词性标签和所述预设标准对进行了第一次短语质量评估的短语进行特征的改正;
步骤s408,根据改正后的特征进行第二次短语质量评估;
步骤s409,根据第二次短语质量评估的得分重新进行短语分隔。
上述方案中,所述步骤s402挖掘出常用短语,具体为:设定词频的阈值以及短语的长度,词频高于阈值和/或短语长度低于预定长度的短语,为常用短语。
上述方案中,所述步骤s403预设标准包括:词频、一致性、信息性、完整性。
上述方案中,所述步骤s5短语挖掘结果包括:多词、单词和总并的结果文件。
根据本发明的另一个方面,还提供了一种基于中医古籍文献的短评挖掘系统,所述系统包括:新语言知识库建立模块、分词及映射模块、转化模块、短语分隔模块、模型生成及应用模块、短语回标模块;其中,
所述新语言知识库建立模块用于在现有的语言知识库基础上添加中医古文的停用词表和高质量短语,建立包含中医古文的新语言知识库;
所述分词及映射模块用于对中医古籍文献原始输入语料进行分词和词性标注,并将分词后的词和词性标签进行词映射并输出词映射文件;
所述转化模块用于读入所述停用词表和高质量短语,同时读入所述词映射文件,根据词映射文件对所述高质量短语进行词映射及对停用词表进行转化,输出转化后的停用词表和高质量短语词表,以及新加了词映射的词映射文件;
所述短语分隔模块用于基于所述分词后的词和所述词映射文件,进行两次词性引导的短语分隔;
所述模型生成及应用模块用于根据所述短语分隔生成模型,并保存短语分隔结果和模型,根据模型生成短语挖掘的单词和多词的质量结果;还用于保存所述质量结果,并根据词映射文件生成短语挖掘结果;
所述短语回标模块用于根据短语挖掘结果,将挖掘出的短语按质量评分的阈值回标到原始输入语料中。
上述方案中,所述分词模块,使用面向中医古籍文献的分词方法,对所述输入语料进行分词和词性标注。
上述方案中,所述模型生成及应用模块的短语挖掘结果包括:多词、单词和总并的结果文件。
本发明上述技术方案的有益效果如下:
上述方案中,所提供的基于中医古籍文献的短语挖掘方法及系统,可以从大量中医古文文献中提取高质量短语,无需人工标记,只需进行有限的浅层语言分析,易操作,效率更高;同时,基于远程监督方法,不需要人工标注语料,也不需要人工设计提取特征,只需要利用现有的公共知识库,节省了人力物力,降低了文献挖掘成本;充分利用了现有的公共知识库和中医古文的现有高质量短语的结合,以有效的方式利用大量高质量的短语,更加全面的利用古籍文献,从而对中医古籍文献中的短语进行高效、智能的挖掘。
附图说明
为了更加清晰的阐述本发明的实施例和现有的技术方案,下面将本发明的技术方案说明附图做简单的介绍,显而易见的,在不付出创造性劳动的前提下,本领域普通技术人员可通过以下附图获得其他的附图。
图1为本发明实施例基于中医古籍文献的短语挖掘方法流程示意图;
图2为本发明实施例中词映射和停用词表转化结果示例图;
图3为本发明实施例中短语分隔流程图;
图4为本发明实施例的短语挖掘方法具体应用时的多词输出结果图;
图5为本发明实施例的短语挖掘方法具体应用时的单词输出结果图。
具体实施方式
为使本发明要解决的技术问题、技术方案和优点更加清楚,下面将结合附图及具体实施例进行详细描述。
本发明针对现有的中医古籍文献检索,提出了一种短语挖掘方法,通过短语挖掘技术、面向中医古籍文献的分词方法和中医古文的语言知识库的结合进行对于中医古籍文献的短语挖掘,所述方法基于远程监督,充分利用现有的公共知识库,不需要人工标注语料和人工设计提取特征,对中医古籍文献中的短语进行高效、智能的挖掘。
下面通过具体的实施例,结合附图,对本发明作进一步详细的说明。
第一实施例
本实施例提供了一种基于中医古籍文献的短语挖掘方法,图1所示为本实施例所述短语挖掘方法的流程示意图。如图1所示,所述短语挖掘方法包括如下步骤:
步骤s1,在现有的语言知识库基础上添加中医古文的停用词表和高质量短语,建立包含中医古文的新语言知识库。
本步骤中所述建立包含中医古文的新语言知识库,以现有的中文知识库为基础,添加中医古文的停用词表和高质量短语。中医古籍文献除了基于中文,还具有一个鲜明的特色,即含有大量古文字和停用词,其所含有的高质量短语与现在通行的中文有较大差别,为了充分利用古籍文献,就需要针对此类在文字演变过程中使用过、出现过的古代文字和词语建立集合或知识库。同时古籍文献中也含有现在通行的用语,因此在公共资源即公共语言知识库的基础上,通过添加停用词表和高质量短语,即可在原有的语言知识库的基础上建立一个新的语言知识库。
步骤s2,对中医古籍文献原始输入语料进行分词和词性标注,并将分词后的词和词性标签进行词映射并输出词映射文件。
优选地,本步骤中分词和词性标注,使用面向中医古籍文献的分词方法。
本步骤对分词后的词进行映射后,将中医古籍文献的原始输入语料转化为词映射后的语料,使原始中文古文语料转化为计算机能够识别的输入。
步骤s3,读入所述停用词表和高质量短语,同时读入所述词映射文件,根据词映射文件对所述高质量短语进行词映射及对停用词表进行转化,输出转化后的停用词表和高质量短语词表,以及新加了词映射的词映射文件。
图2所示为所述步骤s2和步骤s3中的词映射及停用词表的转化结果示例。如图2所示,所述文件的目标是将每一行右边的词映射为左边的id,该文件记录了分词后的所有词、停用词表中的所有词、高质量短语中的所有词。可以将中文词汇转化为数字,从而能够让计算机理解。
优选地,本步骤中所述停用词表中的词为词频和词长符合要求的词,通常情况下不进行挖掘的词,如‘你’、‘我’、‘的’等;高质量短语中的词是中医领域中的常见短语,如‘当归’、‘小柴胡汤’、‘谵语’等。
步骤s4,基于所述分词后的词和所述词映射文件,进行两次词性引导的短语分隔。
进一步地,本步骤所述两次词性引导的短语分隔,首先定位新语言知识库中的所有短语,再通过字符串匹配纠正所述所有短语的最初根据词频获得的短语质量评分,图3所示为本步骤的短语分隔流程图。如图3所示,所述短语分隔,具体包括以下步骤:
步骤s401,加载原始输入语料、停用词表、新语言知识库的质量短语。
步骤s402,根据短语出现的频率挖掘出常用短语。
优选地,所述挖掘出常用短语,具体为:设定词频的阈值以及短语的长度,词频高于阈值并且短语长度低于预定长度的短语,为常用短语。
步骤s403,将所述常用短语作为短语候选者,根据预设标准抽取特征。
优选地,所述预设标准包括:词频、一致性、信息性、完整性。
步骤s404,对所述短语候选者,在新语言知识库中进行匹配,若匹配成功,到则放入正样本池;否则,放入负样本池;
步骤s405,根据所抽取的所述特征、正样本池和负样本池,对所述常用短语进行第一次短语质量评估。
步骤s406,将所述短语候选者返回原始输入语料中,进行短语分隔。
步骤s407,根据所述词性标签和所述预设标准对进行了第一次短语质量评估的短语进行特征的改正。
优选地,当整个词性标签序列是“nnnnnnvbdtnn”时,通过上述短语分隔,pos序列质量估计返回t(nnnnnn)≈1和t(nnvb)≈0,其中nn指单数或质量名词(例如“database”),vb表示基本形式的动词(例如“is”),并且dt是指限定词(例如,“the”)。
步骤s408,根据改正后的特征进行第二次短语质量评估。
步骤s409,根据第二次短语质量评估的得分重新进行短语分隔。
以上即为所述步骤s4短语分隔的过程。
步骤s5,根据所述短语分隔生成模型,并保存短语分隔结果和模型,根据模型生成短语挖掘的单词和多词的质量结果;保存所述质量结果,并根据词映射文件生成短语挖掘结果。
优选地,所述短语挖掘结果包括:多词、单词和总并的结果文件。
步骤s6,根据短语挖掘结果,将挖掘出的短语按质量评分的阈值回标到原始输入语料中。
图4和图5所示为本实施例的短语挖掘方法的一个应用实例的输出结果,图3所示为多词输出结果,图4所示为单词输出结果。如图3和图4所示,所述多词和单词结果,每一行为一个结果,其中,第一列为序号,第二列为所在行短语的最终质量评分,满分为1,本应用实例中质量评分按分数由高到低的顺序排序,第三列为该短语。所述结果是短语挖掘得到的结果。通过本实施例的挖掘方法所得到的短语,短语质量高,多词均在0.83分以上,单词均在0.79分以上,可有效针对具有自己特点的中医古籍文献进行数据分析与处理,短语质量较高,挖掘效率有保证。
第二实施例
本实施例提供了一种基于中医古籍文献的短语挖掘系统,本实施例的系统与第一实施例的方法技术方案是相对应的,第一实施例中的相应描述及技术特征的限定,同样适用于本实施例的所述短语挖掘系统。
所述短语挖掘系统包括:新语言知识库建立模块、分词及映射模块、转化模块、短语分隔模块、模型生成及应用模块、短语回标模块;其中,
所述新语言知识库建立模块用于在现有的语言知识库基础上添加中医古文的停用词表和高质量短语,建立包含中医古文的新语言知识库;
所述分词及映射模块用于对中医古籍文献原始输入语料进行分词和词性标注,并将分词后的词和词性标签进行词映射并输出词映射文件;
所述转化模块用于读入所述停用词表和高质量短语,同时读入所述词映射文件,根据词映射文件对所述高质量短语进行词映射及对停用词表进行转化,输出转化后的停用词表和高质量短语词表,以及新加了词映射的词映射文件;
所述短语分隔模块用于基于所述分词后的词和所述词映射文件,进行两次词性引导的短语分隔;
所述模型生成及应用模块用于根据所述短语分隔生成模型,并保存短语分隔结果和模型,根据模型生成短语挖掘的单词和多词的质量结果;还用于保存所述质量结果,并根据词映射文件生成短语挖掘结果;
所述短语回标模块用于根据短语挖掘结果,将挖掘出的短语按质量评分的阈值回标到原始输入语料中。
进一步地,所述分词模块,使用面向中医古籍文献的分词方法,对所述输入语料进行分词和词性标注。
进一步地,所述模型生成及应用模块的短语挖掘结果包括:多词、单词和总并的结果文件。
由以上技术方案可以看出,本发明基于中医古籍文献的短语挖掘方法和系统,充分利用了中医古籍文献的自身特性,将现有的公共知识库和中医古文的现有高质量短语相结合,输入语料库可以是各种中医古文文献,输出是按短语质量排序的短语词表以及回标至原始语料的结果,以有效的方式利用大量高质量的短语,与有限的人类标记短语相比,更加全面的利用古籍文献,实现更好的性能;可以从大量中医古文文档中提取高质量短语,而无需人工标记,并且只进行有限的浅层语言分析,易操作,效率更高。
以上所述是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明所述原理的前提下,还可以做出若干改进和润饰、修改和替换,这些改进和润饰、修改和替换也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!