一种改进MobileNet模型的人脸表情识别方法与流程
本发明涉及计算机视觉领域中的静态人脸表情识别问题,尤其是涉及一种改进的mobilenet模型的人脸表情识别方法。
背景技术:
人脸表情识别是计算机视觉领域一大热点。人脸表情作为人类情绪的直接表达,是非语言交际的一种形式。目前,人脸表情识别技术应用领域非常广,包括人机交互(hci)、安保、机器人制造、医疗、通信、汽车等。在人机交互(hci)、在线远程教育、互动游戏、智能交通等新兴应用中,自动面部表情识别系统是必要的。
人脸表情识别的重点在于人脸表情特征的提取。对于人脸表情的提取,目前为止出现了两类特征提取方法。一种是基于传统人为设计的表情特征提取方法,如局部二值模式(localbinarypattern,lbp)、定向梯度直方图(histogramoforientedgradients,hog)、尺度不变特征变换(scaleinvariantfeaturetransform,sift)等,这不仅设计困难,并且难以提取图像的高阶统计特征。另一种是基于深度学习的表情特征提取方法,目前深度神经网络已广泛应用在图像、语音、自然语言处理等各个领域,这充分证明了深度神经网络具有良好的特征提取能力。为了适应不同的应用场景,越来越多的深度神经网络模型被提出,例如alexnet、vgg-19、googlenet和resnet,这些网络模型被广泛应用于各个领域,当然这些模型也应用在人脸表情特征提取及分类上,也取得了不错的效果。
但随着深度神经网络模型的不断发展,其缺点也逐渐显现。网络模型的复杂化,模型参数的大量化的缺点,使得这些模型只能在一些特定的场合应用,移动端和嵌入式设备难以满足其需要的硬件要求。复杂网络模型需要的硬件高要求限制了其应用场景。基于此,google公司的andrewg.howard等人在2017年4月提出了一个可以应用在移动端和嵌入式设备的mobilenet轻量化网络模型。文中提出的使用深度可分离卷积层,在保证精度损失不大的情况下,大大减少了网络的计算量,从而为计算设备“减负”。2018年1月,google公司提出第二个版本的mobilenet网络模型,称之为mobilenetv2,其网络结构保持了第一版本的轻量化特点,不同的是mobilenetv2使用了倒转的残差(invertedresidual)结构,并且为了减少信息丢失,舍弃在点卷积后使用非线性激活层,而使用线性输出。
本发明根据人脸表情识别的特点,设计了一个基于输入尺寸为48*48单通道灰度图片的改进mobilenet模型,使其兼顾mobilenet两个版本网络模型的优势,保留了原有mobilenetv1的深度可分离卷积层,为了更好的保留深度卷积后输出的特征,在深度可分离卷积层输出后,去掉用于提取非线性特征的激活层,采用线性输出。大多数的深度学习方法使用softmax来进行分类。而svm分类器作为一种具有较强泛化能力的通用学习算法,且svm分类器对大数据高维特征的分类支持较好,本发明使用l2-svm方法训练深度神经网络进行分类。
技术实现要素:
本发明提出了一种改进的mobilenet模型的人脸表情识别方法,改进后的模型如表1所示。首先获取输入人脸图像的有效人脸区域部分,最后将其输入改进后的网络模型对人脸表情进行识别。
表1改进的mobilenet网络结构
本发明通过以下技术方案来实现上述目的:
(1)对输入人脸表情图像进行人脸检测,获得人脸矩形区域。
(2)对(1)中检测的矩形区域裁剪至48*48*1的单通道灰度图。
(3)将(2)中的图像送入改进后mobilenet模型进行表情特征提取。
(4)根据(3)提取到的表情特征采用svm分类器进行分类,输出人脸表情识别结果。
附图说明
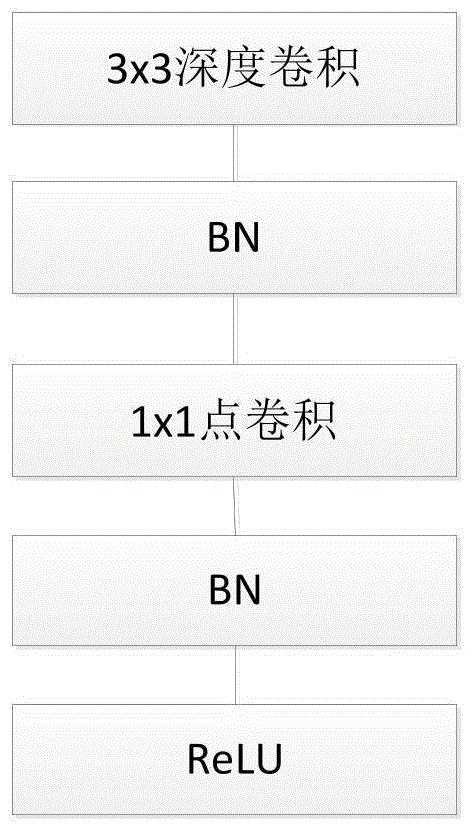
图1改进的深度可分离卷积模型;
图2人脸表情图像预处理流程图;
具体实施方式
下面结合附图对本发明作进一步说明:
改进的mobilenet模型的人脸表情识别具体方法如下:
首先按照附图2的人脸表情图像预处理流程对输入人脸表情图像进行预处理。在这个预处理流程中,首先根据输入图片类型判断是否转换成单通道灰度图,若图片已经是单通道灰度图,则直接转到一下步,反之则进行转换。然后对上一步的输出图像进行人脸检测,确定人脸区域。最后根据得到的人脸区域对图像进行裁剪,裁剪至大小为48*48的单通道灰度图,至此预处理流程完毕。
然后将预处理后的图像输入按表1所示搭建好的网络模型进行预测。这里每一个深度可分离卷积层采用附图1所示的方式进行处理,其他所有卷积层的输出之后需要经过bn层和relu激活层处理。其中深度卷积层部分由于提取的特征是单通道的,如果进行非线性处理,则有可能导致信息丢失,因此为了尽可能保留信息,只经过bn层处理,不加入非线性激活函数,而采用线性输出。在分类器设计方面,由于svm分类器具有较强的泛化能力以及其对大数据高维特征的分类支持较好,所以本发明舍弃了原模型中的softmax分类器,而采用svm分类器进行分类,本发明采用l2-svm对目标进行分类。
对于一个输入尺寸为48*48*1的单通道人脸表情图像,首先通过一个卷积核大小为3*3,个数为32的标准二维卷积层进行标准卷积,卷积输出尺寸为24*24*32,然后将输出经过10个深度可分离卷积层进行特征提取,每个深度可分离卷积层由一个深度卷积层和一个点卷积层组成,所有深度卷积层的卷积核大小都为3*3,点卷积的卷积核大小都为1*1,深度卷积层的卷积核个数依次为:32,64,128,128,128,128,128,128,128,256;点卷积的卷积核个数依次为:64,128,128,128,128,128,128,128,256,256,然后将经过10个深度可分离卷积层后的输出送入平均池化层,最后将池化层的输出送入全连接层;其中只有标准二维卷积层、第2个深度卷积层、第9个深度卷积层的步长为2,其他所有层的步长均为1;而在除深度卷积层以外的所有的卷积层,卷积操作后都要经过一个归一化层和relu激活层来加速网络的收敛速度和增加提取非线性特征的能力,但在深度卷积层则只经过归一化层,不经过激活层;最终形成1*1*256的特征结果。然后使用svm分类器对提取到的人脸表情特征进行分类。这里的10个深度可分离卷积层组成了本模型最核心的特征提取部分。
传统标准卷积既过滤输入又将过滤后的输出进行组合,最终形成一组新的输出。假设输入特征图大小为m*m,通道数为c,标准卷积的卷积核大小为n*n,个数为k,并且假设输出与输入大小一致,则经过标准卷积后输出大小为m*m,输出通道数为k。标准卷积过程,实际上包含了两步——特征过滤和将过滤后的结果组合。在这个过程中,首先输入特征图中的每个通道与对应的卷积核的每个通道进行卷积,卷积的结果是形成了c个m*m的单通道特征图,然后将这c个结果合并,最终形成一个m*m*1的单特征图。由于有k个卷积核,因此输入特征图与所有k个卷积核进行标准卷积后,共有k个m*m*1结果,最终结果为m*m*k的输出特征图。标准卷积的计算量为:
m×m×n×n×c×k(1)
深度可分离卷积则是将标准卷积分解为一个深度卷积和一个点卷积,深度卷积过程实际上是将输入的每个通道各自与自己对应的卷积核进行卷积,最后将得到各个通道对应的卷积结果作为最终的深度卷积结果,深度卷积的过程实际上是完成了一个输入特征图的过滤。因此深度卷积的计算量为:
m×m×n×n×c(2)
这里的点卷积则是将深度卷积的结果作为输入,卷积核大小为1*1,通道数与输入一致,卷积过程类似标准卷积,点卷积的过程实际上是对每个像素点在不同的通道上进行线性组合(信息整合),且保留了图片的原有平面结构,调控深度。相比于深度卷积,点卷积具有改变通道数的能力,可以完成升维或降维的功能。其计算量为:
m×m×1×1×c×k=m×m×c×k(3)
因此深度可分离卷积总的计算量为:
m×m×n×n×c+m×m×c×k(4)
深度可分离卷积与传统标准卷积计算量相比:
从式(5)可以看出,深度可分离卷积可有效减少计算量,若网络使用卷积核大小为3*3,则深度可分离卷积可减少8至9倍计算量。这种分解在有效提取特征的同时,精度损失也较小。表2显示了改进后的mobilenet网络模型参数及mobilenetv1、mobilenetv2的参数对比,其中m代表million。
表2本发明模型与mobilenetv1、mobilenetv2参数对比
从表2中可以看出本发明模型参数较mobilenetv1减少90%左右,较mobilenetv2减少88%左右,大大缩减了mobilenet网络参数。
表3是本发明与目前国际上在公开数据集ck+数据集(7分类)上取得领先水平的模型的对比结果,表4是本发明与目前国际上在公开数据集ck+数据集(6分类)上取得领先水平的模型的对比结果。
表3不同算法模型在ck+数据集(7类)上的准确率对比
表4不同算法模型在ck+数据集(6类)上的准确率对比
从表3和表4可以看出,本发明模型+svm可以有效提取人脸表情特征以及对表情进行分类,识别效果超过了表中所列其他所有模型。
- 还没有人留言评论。精彩留言会获得点赞!