一种基于SSD和AlphaPose的安全帽佩戴检测方法及系统与流程
本发明涉及图像处理领域,尤其涉及一种基于ssd和alphapose的安全帽佩戴检测方法及系统。
背景技术:
ssd模型是一个基于前向传播的cnn网络,将输入的特征图谱据切分成相应尺寸的特征单元,在每一个单元格上构建一系列的固定大小的包围盒,如图4所示,先通过计算每一个包围盒中包含物体实例的可能性,即存在概率;最后通过非极大值抑制方法来得到包围盒中物体实例的所属类别。图5提供了ssd的拓扑结构图。
alphapose是一个实时多人姿态估计系统,它对于多人姿态估计的方法采用的是传统的自顶向下的方法,即先检测人,再识别人体姿态,检测使用的是ssd-512,识别人体姿态使用的stackedhourglass方法。如图6所示是单个hourglass的模块示例,图中每个方框对应一个residual模块(如图7所示),整个hourglass中,特征数是一致的。hourglass首先利用卷积层和池化层将特征缩放到很小的分辨率,每一个池化层都会进行网络分叉,对原来池化过的特征再进行卷积,得到最低分辨率特征后,网络开始向上采样,并逐渐结合不同尺度的特征信息。整个hourglass是对称的,即获取低分辨率特征过程中每有一个网络层,则在向上采样的过程中相应会有一个网络层。得到hourglass网络模块输出后,再采用两个连续的1*1卷积层进行处理,得到最终的网络输出。
目前基于静态图像的多目标识别的技术发展日趋完善,应用的场景亦是愈加广泛。许多研究学者提出将视频图像处理技术加入到各个施工现场领域。在已有的视频监控系统的基础上,加上智能化识别技术,提供实时报警功能,减少施工现场的潜在安全隐患。
而安全帽佩戴状态是实现智能化视频监控系统的重要环节。但由于佩戴安全帽的检测过程容易受外界环境因素、工人的行为动作以及复杂的施工现场等因素的影响。目前,安全帽的自动识别技术研究并不能够适用于各种情况。有写研究仅适用于识别红、黄、蓝等有限颜色的安全帽。并且,他们研究的前提是工人时站立的状态,并未考虑到工人在别的姿态下施工的情况,而弯腰、左倾或者右倾施工正是安全隐患最大的时候,此时,安全帽的佩戴显得尤为重要。
技术实现要素:
为了解决上述问题,本发明提供了一种基于ssd和alphapose的安全帽佩戴检测方法及系统,将深度学习的图像识别技术运用于工厂视频监控系统中,实现对整个工厂的工作人员佩戴安全帽情况实时监控和自动识别,确保工厂工作人员安全规范工作,保障工厂安全有序生产。
一种基于ssd和alphapose的安全帽佩戴检测方法,主要包括以下步骤:
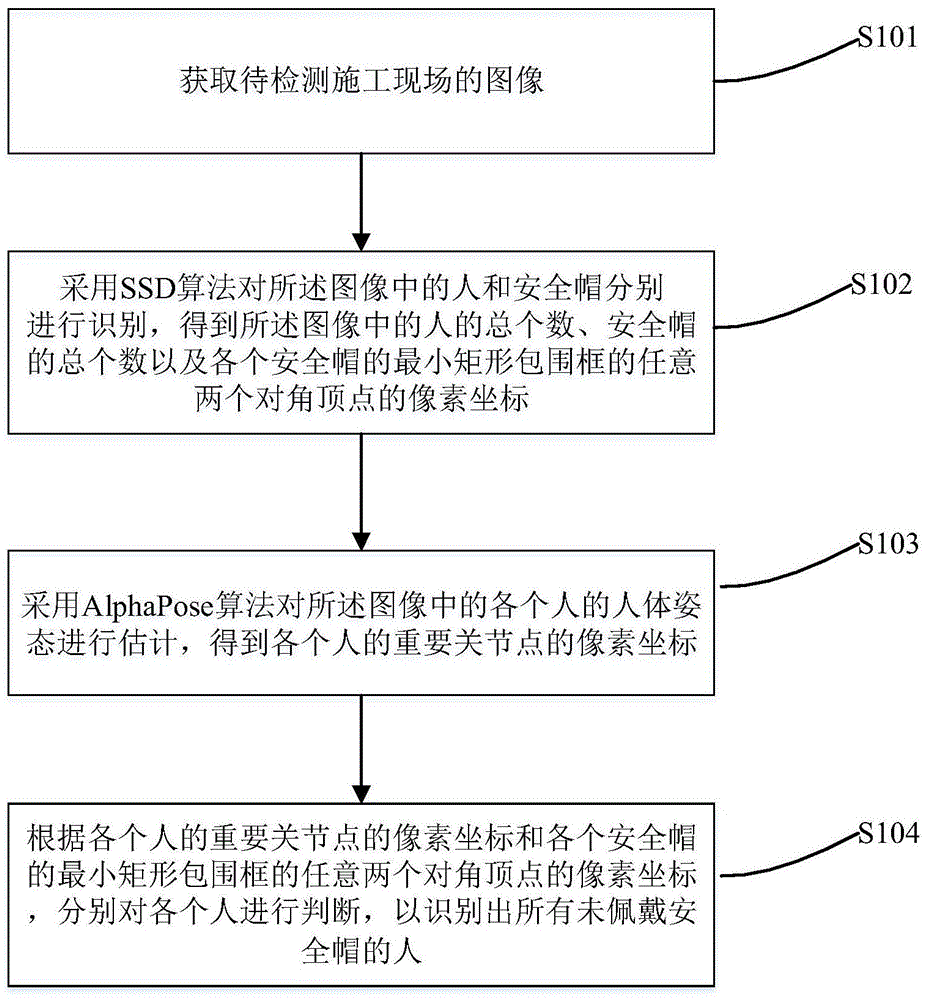
s101:获取待检测施工现场的图像;所述图像中包括多个安全帽和多个人;
s102:采用ssd算法对所述图像中的人和安全帽分别进行识别,得到所述图像中的人的总个数、安全帽的总个数以及各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标;
s103:采用alphapose算法对所述图像中的各个人的人体姿态进行估计,得到各个人的重要关节点的像素坐标;
s104:根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人。
进一步地,步骤s101中,所述待检测施工现场的图像可通过待检测施工现场的监控摄像头或者监控视频获取。
进一步地,步骤s102中,采用ssd算法对所述图像中的人和安全帽分别进行识别时,ssd算法的识别阈值设置为0.5,即ssd算法识别出的物体的精度大于或者等于0.5时,才确定该物体为安全帽。
进一步地,步骤s103中,所述重要关节点包括:鼻子、左眼、右眼、左耳、右耳、左肩、右肩、左臀和右臀。
进一步地,步骤s104中,根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人,具体包括如下步骤:
s201:判断
s202:判断第k个人的姿态是否左倾;具体如下:
判断条件
s203:判断
s204:判断第k个人的姿态是否右倾;具体如下:
判断条件
s205:判断
s206:i是否等于h?若是,则第k个人未佩戴安全帽,将i更新为1,并转到步骤s207;否则,将i更新为i+1,并返回步骤s201;其中,h为ssd识别出的安全帽的总个数;
s207:k是否大于k?若是,则到步骤s208;否则,将k更新为k+1,将最新配对成功的安全帽序号i从所有的安全帽序号中剔除,并对剩下的安全帽序号进行重新排序,即配对成功后的第i个安全帽不再参与剩下的循环步骤,并将安全帽的总个数h的值更新为剔除成功配对的安全帽后的剩余安全帽的总个数;并返回步骤s201;其中,k为人的总个数;
s208:结束循环,得到所述待检测施工现场的图像中所有未佩戴安全帽的人。
进一步地,一种基于ssd和alphapose的安全帽佩戴检测系统,其特征在于:包括如下模块:
图像获取模块,用于获取待检测施工现场的图像;所述图像中包括多个安全帽和多个人;
安全帽识别模块,用于采用ssd算法对所述图像中的人和安全帽分别进行识别,得到所述图像中的人的总个数、安全帽的总个数以及各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标;
关节识别模块,用于采用alphapose算法对所述图像中的各个人的人体姿态进行估计,得到各个人的重要关节点的像素坐标;
判断模块,用于根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人。
进一步地,图像获取模块中,所述待检测施工现场的图像可通过待检测施工现场的监控摄像头或者监控视频获取。
进一步地,安全帽识别模块中,采用ssd算法对所述图像中的人和安全帽进行识别时,ssd算法的识别阈值设置为0.5,即ssd算法识别出的物体的精度大于或者等于0.5时,才确定该物体为安全帽。
进一步地,关节识别模块中,所述重要关节点包括:鼻子、左眼、右眼、左耳、右耳、左肩、右肩、左臀和右臀。
进一步地,判断模块中,根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人,具体包括如下单元:
第一判断单元,用于判断
第二判断单元,用于判断第k个人的姿态是否左倾;具体如下:
判断条件
第三判断单元,用于判断
第四判断单元,用于判断第k个人的姿态是否右倾;具体如下:
判断条件
第五判断单元,用于判断
第六判断单元,用于判断i是否等于h?若是,则第k个人未佩戴安全帽,将i更新为1,并转到第七判断单元;否则,将i更新为i+1,并返回第一判断单元;其中,h为ssd识别出的安全帽的总个数;
第七判断单元,用于判断k是否大于k?若是,则到结束单元;否则,将k更新为k+1,将最新配对成功的安全帽序号i从所有的安全帽序号中剔除,并对剩下的安全帽序号进行重新排序,即配对成功后的第i个安全帽不再参与剩下的循环步骤,并将安全帽的总个数h的值更新为剔除成功配对的安全帽后的剩余安全帽的总个数;并返回第一判断单元;其中,k为人的总个数;
结束单元,用于结束循环,得到所述待检测施工现场的图像中所有未佩戴安全帽的人。
本发明提供的技术方案带来的有益效果是:本发明所提出的技术方案通过ssd和alphapose两个模型的融合,在人体的多种姿态下,依然能够有效的识别人体是否佩戴了安全帽,效率高,实用性强。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例中一种基于ssd和alphapose的安全帽佩戴检测方法的流程图;
图2是本发明实施例中采用ssd算法识别安全帽的示意图;
图3是本发明实施例中一种基于ssd和alphapose的安全帽佩戴检测系统的模块组成示意图;
图4是本发明实施例中ssd算法中1:8×8的特征包围示意图;
图5是本发明实施例中ssd的拓扑结构图;
图6是本发明实施例中单个hourglass的模块示例图;
图7是本发明实施例中residual模块示例图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
本发明的实施例提供了一种一种基于ssd和alphapose的安全帽佩戴检测方法及系统。
请参考图1,图1是本发明实施例中一种基于ssd和alphapose的安全帽佩戴检测方法的流程图,具体包括如下步骤:
s101:获取待检测施工现场的图像;所述图像中包括多个安全帽和多个人;
s102:采用ssd算法对所述图像中的人和安全帽分别进行识别,得到所述图像中的人的总个数、安全帽的总个数以及各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标;
s103:采用alphapose算法对所述图像中的各个人的人体姿态进行估计,得到各个人的重要关节点的像素坐标;
s104:根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人。
步骤s101中,所述待检测施工现场的图像可通过待检测施工现场的监控摄像头或者监控视频获取。
步骤s102中,采用ssd算法对所述图像中的人和安全帽分别进行识别时,ssd算法的识别阈值设置为0.5,即ssd算法识别出的物体的精度大于或者等于0.5时,才确定该物体为安全帽;如图2所示,为本发明实施例中,对某个人佩戴的安全帽进行识别的状态示意图,从图中可以看出,对该安全帽的识别精度为94%。
步骤s103中,所述重要关节点包括:鼻子、左眼、右眼、左耳、右耳、左肩、右肩、左臀和右臀。
步骤s104中,根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人,具体包括如下步骤:
s201:判断
s202:判断第k个人的姿态是否左倾;具体如下:
判断条件
s203:判断
s204:判断第k个人的姿态是否右倾;具体如下:
判断条件
s205:判断
s206:i是否等于h?若是,则第k个人未佩戴安全帽,将i更新为1,并转到步骤s207;否则,将i更新为i+1,并返回步骤s201;其中,h为ssd识别出的安全帽的总个数;
s207:k是否大于k?若是,则到步骤s208;否则,将k更新为k+1,将最新配对成功的安全帽序号i从所有的安全帽序号中剔除,并对剩下的安全帽序号进行重新排序,即配对成功后的第i个安全帽不再参与剩下的循环步骤,并将安全帽的总个数h的值更新为剔除成功配对的安全帽后的剩余安全帽的总个数;并返回步骤s201;其中,k为人的总个数;
s208:结束循环,得到所述待检测施工现场的图像中所有未佩戴安全帽的人。
请参阅图3,图3是本发明实施例中一种基于ssd和alphapose的安全帽佩戴检测系统的模块组成示意图,包括顺次连接的:图像获取模块11、安全帽识别模块12、关节识别模块13和判断模块14;
图像获取模块11,用于获取待检测施工现场的图像;所述图像中包括多个安全帽和多个人;
安全帽识别模块12,用于采用ssd算法对所述图像中的人和安全帽分别进行识别,得到所述图像中的人的总个数、安全帽的总个数以及各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标;
关节识别模块13,用于采用alphapose算法对所述图像中的各个人的人体姿态进行估计,得到各个人的重要关节点的像素坐标;
判断模块14,用于根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人。
图像获取模块11中,所述待检测施工现场的图像可通过待检测施工现场的监控摄像头或者监控视频获取。
安全帽识别模块12中,采用ssd算法对所述图像中的人和安全帽分别进行识别时,ssd算法的识别阈值设置为0.5,即ssd算法识别出的物体的精度大于或者等于0.5时,才确定该物体为安全帽;
关节识别模块13中,所述重要关节点包括:鼻子、左眼、右眼、左耳、右耳、左肩、右肩、左臀和右臀。
判断模块14中,根据各个人的重要关节点的像素坐标和各个安全帽的最小矩形包围框的任意两个对角顶点的像素坐标,分别对各个人进行判断,以识别出所有未佩戴安全帽的人,具体包括如下单元:
第一判断单元,用于判断
第二判断单元,用于判断第k个人的姿态是否左倾;具体如下:
判断条件
第三判断单元,用于判断
第四判断单元,用于判断第k个人的姿态是否右倾;具体如下:
判断条件
第五判断单元,用于判断
第六判断单元,用于判断i是否等于h?若是,则第k个人未佩戴安全帽,将i更新为1,并转到第七判断单元;否则,将i更新为i+1,并返回第一判断单元;其中,h为ssd识别出的安全帽的总个数;
第七判断单元,用于判断k是否大于k?若是,则到结束单元;否则,将k更新为k+1,将最新配对成功的安全帽序号i从所有的安全帽序号中剔除,并对剩下的安全帽序号进行重新排序,即配对成功后的第i个安全帽不再参与剩下的循环步骤,并将安全帽的总个数h的值更新为剔除成功配对的安全帽后的剩余安全帽的总个数;并返回第一判断单元;其中,k为人的总个数;
结束单元,用于结束循环,得到所述待检测施工现场的图像中所有未佩戴安全帽的人。
本发明的有益效果是:本发明所提出的技术方案通过ssd和alphapose两个模型的融合,在人体的多种姿态下,依然能够有效的识别人体是否佩戴了安全帽,效率高,实用性强。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!