基于无监督交叉视角度量学习的行人再识别方法及系统与流程
本发明属于信息处理技术领域,特别涉及一种监控场景下的行人再识别技术,可用于公共安全智能监控、交通管制以及刑侦辅助等领域。
背景技术:
随着监控技术的发展,越来越多的摄像机被用于安防系统中。行人再识别就是要从空间不重叠的监控摄像机中找出同一个行人的技术。在大尺度的监控网络中,行人再识别技术对于目标追踪和行为分析都是非常重要的。由于成像条件的差异,不同摄像机下行人的表观特性差异很大,比如亮度、姿态、遮挡情况等,这给行人再识别带来了巨大的挑战。
目前,研究者们已提出许多基于度量学习的行人再识别技术。这些技术学习一个度量矩阵,将不同摄像机下的行人特征投影到一个潜在的子空间中,在该子空间中使得同一个行人的表达更相似,不同行人的表达更不同。
由于成像条件和成像时间上的不一致,摄像机间的行人特征具有较大的差异。为了解决这些差异带来的挑战,研究者们提出交叉视角的行人再识别方法。该类方法为每一个摄像机学习一个投影矩阵,从而校正摄像机之间的差异。chen等人在文献“y.chen,w.zheng,j.lai,andp.yuen,anasymmetricdistancemodelforcross-viewfeaturemappinginpersonreidentification,ieeetransactionsoncircuitsandsystemsforvideotechnology,vol.27,no.8,pp.1661-1675,2017”中提出一种非对称度量学习方法,为每个摄像机学习不同的投影矩阵。然而,这类方法在建模过程中忽略了摄像机之间的共性,难以对行人进行精确建模。
此外,已有的度量学习方法大都需要利用标注的样本进行训练,标注过程需要耗费大量的人力物力、在标注过程也会引入精度不一致的干扰,这对于持续发展的监控网络来说是一项巨大的负担。
技术实现要素:
为了解决现有技术中难以对行人进行精确建模及建模过程费时费力的问题,本发明提供一种基于无监督交叉视角度量学习的行人再识别方法,利用海量无标签的行人数据,学习摄像机之间的共性和特性,进而挖掘行人之间的潜在关系。
本发明的技术解决方案是提供一种基于无监督交叉视角度量学习的行人再识别方法,包括以下步骤:
s1、获取行人图像,构建训练集;
获取多个空间不重叠的摄像机中的图像数据,构建训练集;
s2、行人图像特征提取:
s21、利用训练集以外的已标注好的行人数据训练卷积神经网络;
s22、利用步骤s21训练好的卷积神经网络对训练集中的每幅图像分别提取行人特征表达
s3、构建交叉视角下的最终投影矩阵及行人特征表达模型;
交叉视角下的最终投影矩阵为:wv=u0+uv,wv为第v个摄像机交叉视角下的最终投影矩阵,u0为共性投影矩阵,用于提取所有摄像机之间的共同特性;uv为特性投影矩阵,用于提取每个摄像机独有的特性;
交叉视角下的最终行人特征表达为
s4、构建目标函数及其约束项,所述目标函数包括聚类目标函数与行人特征分布一致性函数;
s41、聚类目标函数:
其中,k为聚类的类别数,v是摄像机的总数,ck为第k个聚类的类中心,ck为聚类中心的集合;
s42、构建目标函数的约束项:
约束共性和特性行人特征之间正交,彼此没有交集,即
s43、行人特征分布一致性函数:
其中,mp和mq分别为第p和第q个摄像机下行人的特征表达均值,np和nq分别为对应摄像机下行人样本的数量;wp为第p个摄像机的交叉视角下的最终的投影矩阵;
s5、解算最终目标函数,获得优化矩阵;
s51、根据步骤s4构建的目标函数及其约束项,获取最终目标函数:
其中,
s52、更新ck:
利用k-means算法对
s53、更新共性投影矩阵u0与特性投影矩阵uv:
基于步骤s52更新后的ck,利用拉格朗日乘子法对公式(4)进行优化求解,得到更新后共性投影矩阵u0与特性投影矩阵uv;
s54、再次更新ck:
基于步骤s53得到的共性投影矩阵u0与特性投影矩阵uv,利用k-means算法对投影空间中的行人特征表达
s55、再次更新共性投影矩阵u0与特性投影矩阵uv:
基于s54更新后的ck,利用拉格朗日乘子法对公式(4)进行优化求解,得到再次更新后的共性投影矩阵u0与特性投影矩阵uv;
s56、迭代更新:
重复步骤s54和s55的操作,直到模型收敛或达到最大迭代次数;
s6、利用步骤s5获得的矩阵,将测试集投影到潜在特征空间,对比特征距离,得到查询结果,识别行人。
进一步地,上述步骤s6具体为:
s61、提取多个待测试摄像机图像数据,构建测试集,所述测试集包括查询样本与图片库;
s62、利用步骤s21中得到的卷积神经网络,对查询样本及图片库中的每幅图像进行行人特征提取;
s63、利用步骤s5中学习的最终投影矩阵对测试集中的行人样本进行投影;获得最终测试集中的行人特征表达;
s64、计算查询样本与图片库中行人特征表达之间的距离,确定图片库中的行人与查询样本是否属于同一个行人。
本发明还提供一种基于无监督交叉视角度量学习的行人再识别系统,包括处理器及存储器,其特殊之处在于:所述存储器中存储计算机程序,计算机程序在处理器中运行时,执行上述基于无监督交叉视角度量学习的行人再识别方法的过程。
本发明还提供一种计算机可读存储介质,其特征在于:储存有计算机程序,计算机程序被执行时实现基于无监督交叉视角度量学习的行人再识别方法的方步骤。
本发明的有益效果是:
1)、本发明利用无标签的行人数据进行学习,省去了标注样本的过程,节省人力物力,同时也不会引入标注过程中的精度干扰,同时对摄像机间的共性和特性进行建模,有效地提取了同一行人相同的属性,并减小了相机间视角、姿态、亮度等差异带来的干扰提高了模型的判别能力;
2)在投影空间中,构建行人特征分布一致性函数,使不同摄像机间的样本分布保持一致,提升了度量的精度。
附图说明
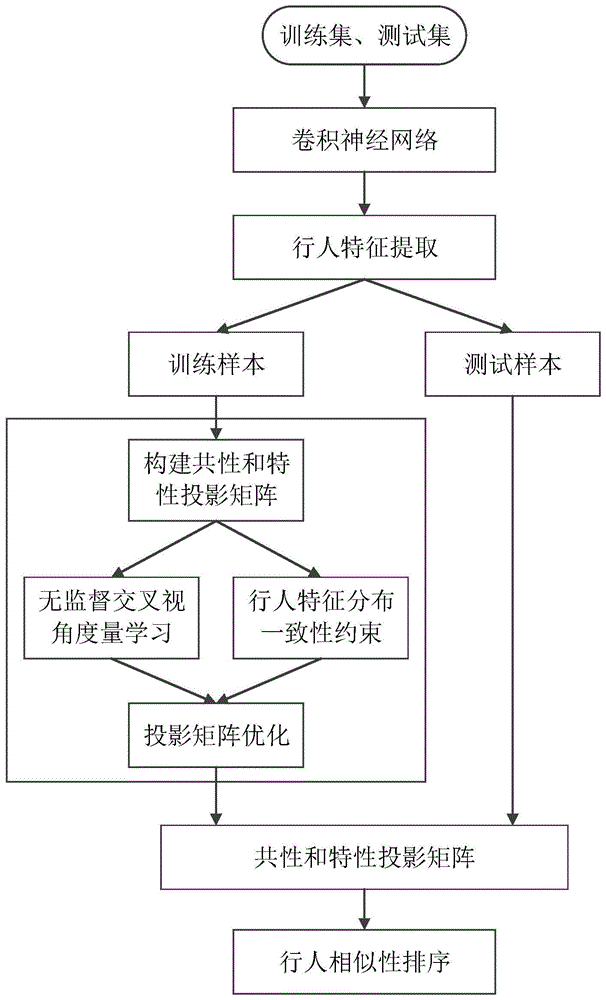
图1为本发明基于无监督交叉视角度量学习的行人再识别方法流程图。
具体实施方式
下面结合附图及具体实施例对本发明实现的步骤作进一步地详细描述:
参照图1,本发明实现的步骤如下:
步骤1、获取多个空间不重叠的摄像机中的图像数据,构建训练集。
步骤2、训练集中行人图像特征提取;
(2a)、利用训练集以外的已标注好的行人数据训练卷积神经网络。
(2b)、在训练集上,利用训练好的卷积神经网络对每幅图像分别提取行人特征表达。
步骤3、构建共性和特性投影矩阵,获得最终行人特征表达;
(3a)、共性投影矩阵u0:共性投影矩阵用于提取所有摄像机之间的共同特性。对于第v个摄像机下的第i幅行人图像,共性特征可以表示为
(3b)、特性投影矩阵uv:特性投影矩阵用于提取每个摄像机独有的特性。对于第v个摄像机下的第i幅行人图像,特性特征可以表示为
(3c)、最终行人特征表达:最终投影矩阵为wv=u0+uv,最终行人
步骤4、无监督交叉视角度量学习及行人特征一致约束。
(4a)、基于聚类的伪标签学习:
基于投影矩阵wv,所有摄像机下的行人样本均被投影到了同一个子空间中。为了挖掘样本间的关系,采用k-means算法对行人特征表达进行聚类。聚类的目标函数记作:
其中,k为聚类的类别数,v是摄像机的总数,ck为第k个聚类的类中心。
(4b)、共性和特性表达正交:为了减弱共性和特性特征之间的干扰,提高模型的表达能力,约束共性和特性特征之间正交,彼此没有交集,即
(4c)、行人特征分布一致性约束:
为了提升度量模型的精度,约束在潜在特征空间中,不同摄像机下的行人特征分布一致。本发明采用最大均值差异(maximummeandiscrepancy,简称mmd)准则来度量不同分布的距离,即
其中,mp和mq分别为第p和第q个摄像机下行人特征的均值,np和nq分别为对应摄像机下行人样本的数量。
步骤5、投影矩阵优化。
(5a)、最终目标函数定义:综合以上步骤,最终的目标函数可以写作
其中,
(5b)、更新伪标签ck:利用k-means算法对原始数据
(5c)、更新投影矩阵:固定步骤(5b)跟新后的伪标签,利用拉格朗日乘子法对公式(4)进行优化求解,得到更新后共性投影矩阵u0与特性投影矩阵uv;
(5d)、再次更新伪标签:固定投影矩阵,利用k-means算法对投影空间中的行人特征表达进行聚类,得到再次更新后的伪标签ck。
(5e)、再次更新投影矩阵:固定伪标签,利用拉格朗日乘子法对公式(4)进行优化求解。
(5f)、迭代更新:重复(5d)和(5e)操作,直到模型收敛或达到最大迭代次数。
步骤6、行人相似性排序。
(6a)、提取多个待测试摄像机图像数据,构建测试集,所述测试集包括查询样本与图片库;
(6b)利用步骤(2a)中得到的卷积神经网络,对测试集中的查询样本和图片库进行行人特征提取。上述步骤(6a)与(6b)步骤,也可以在步骤2中执行,即将测试集与训练集进行行人特征提取过程。
(6c)利用步骤5中学习的投影矩阵将不同摄像机下的行人样本投影到潜在特征空间中。
(6d)计算查询样本与测试集的特征之间的距离,并根据该距离对测试集样本进行排序。测试集中,距离越小的样本越有可能与查询样本属于同一个行人。
本发明还提供一种基于无监督交叉视角度量学习的行人再识别系统,包括处理器及存储器,所述存储器中存储计算机程序,计算机程序在处理器中运行时,执行权利基于无监督交叉视角度量学习的行人再识别方法。
本发明还提供一种计算机可读存储介质,用于存储程序,程序被执行时实现基于无监督交叉视角度量学习的行人再识别方法的步骤。在一些可能的实施方式中,本发明还可以实现为一种程序产品的形式,其包括程序代码,当所述程序产品在终端设备上运行时,所述程序代码用于使所述终端设备执行本说明书上述方法部分中描述的根据本发明各种示例性实施方式的步骤。
用于实现上述方法的程序产品,其可以采用便携式紧凑盘只读存储器(cd-rom)并包括程序代码,并可以在终端设备,例如个人电脑上运行。然而,本发明的程序产品不限于此,在本发明中,计算机可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被指令执行系统、装置或者器件使用或者与其结合使用。
程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以为但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
本发明的效果可以通过以下实验做进一步的说明。
1、仿真条件
本发明是在中央处理器为intel(r)corei3-21303.4ghz、内存16g、windows7操作系统上,运用matlab软件进行的仿真。
实验中使用的数据库是由清华大学于2015年构建并公开的market-1501数据集。该数据集采集自6个监控摄像机,其中5个为高分辨率,1个为低分辨率。数据集中共包括1501个行人的32668幅图像,图像的分辨率均被缩放为128×64。由于数据集中的行人图像都是由行人检测算法提取的行人区域,因此其中包含有许多检测结果非常差,甚至不是行人的图像。
2、仿真内容
首先,在market-1501数据集上,采用751个行人的12936幅图像完成本发明算法(基于无监督交叉视角度量学习的行人再识别方法)中投影矩阵的学习。然后,统计3368幅查询图像在19732幅测试数据集中的再识别精度。再识别结果评价指标包括rank-1精度和平均精度(meanaverageprecision,简称map)。定量的检测精度如表1所示。
表1market-1501数据集上的行人再识别精度对比结果
其中,对比算法dic的结果来自文献:
e.kodirov,t.xiang,ands.gong,“dictionarylearningwithiterativelaplacianregularisationforunsupervisedpersonre-identification,”inproceedingsofbritishmachinevisionconference,pp.1-12,2015.
对比算法sae的结果来自文献:
a.coates,a.ng,andh.lee,“ananalysisofsingle-layernetworksinunsupervisedfeaturelearning,”inproceedingsofinternationalconferenceonaquaticinvasivespecies,pp.215-223,2011.
对比算法aml的结果来自文献:
j.ye,z.zhao,andh.liu,“adaptivedistancemetriclearningforclustering,”inproceedingsofieeecomputervisionandpatternrecognition,pp.1-7,2007.
对比算法camel的结果来自文献:
h.yu,a.wu,andw.zheng,“cross-viewasymmetricmetriclearningforunsupervisedpersonre-identification,”inproceedingsofieeeinternationalconferenceoncomputervision,pp.994-1002,2017.
从表1可以看出,相比于对比方法,本发明能更好地完成无监督行人再识别任务。这是因为本发明探索了不同摄像机间的共性和特性表达,并考虑了投影空间中特征分布的一致性,实现了模型表达能力和精度上的提升。
- 还没有人留言评论。精彩留言会获得点赞!