一种基于注意力的深度加速强化学习的目标定位方法与流程
本发明涉及目标定位任务技术领域,具体为一种基于注意力的深度加速强化学习的目标定位方法。
背景技术:
目标定位任务一般分解为位置和分类两个子问题,当前的主要模型是基于监督学习的模式下的,在深度学习网络技术的应用下,目标的特征描述性能上取得了重大突破,但在目标的位置的确定上仍然被当作回归问题进行处理。深度强化学习将目标的位置定位作为一个行为控制问题来进行处理,即操控被观察区域与目标区域进行重合来确定目标位置。与其它遵循某种原则来进行位置定位的方法相比,基于深度强化学习技术的目标定位方法具有更高的灵活性和高效性,其原理由于类人性更具可解释性。在样本分布复杂的情况下,基于深度强化学习技术的目标定位模型具有更好的泛化能力。
但深度强化学习技术自身的特性在目标定位应用的稳定性上存在缺陷,所需的训练时间也较长,因此设计一种基于注意力的深度加速强化学习的目标定位方法是十分有必要的。
技术实现要素:
本发明的目的在于提供一种基于注意力的深度加速强化学习的目标定位方法,以解决上述背景技术中提出的问题。
为了解决上述技术问题,本发明提供如下技术方案:一种基于注意力的深度加速强化学习的目标定位方法,包括以下步骤:
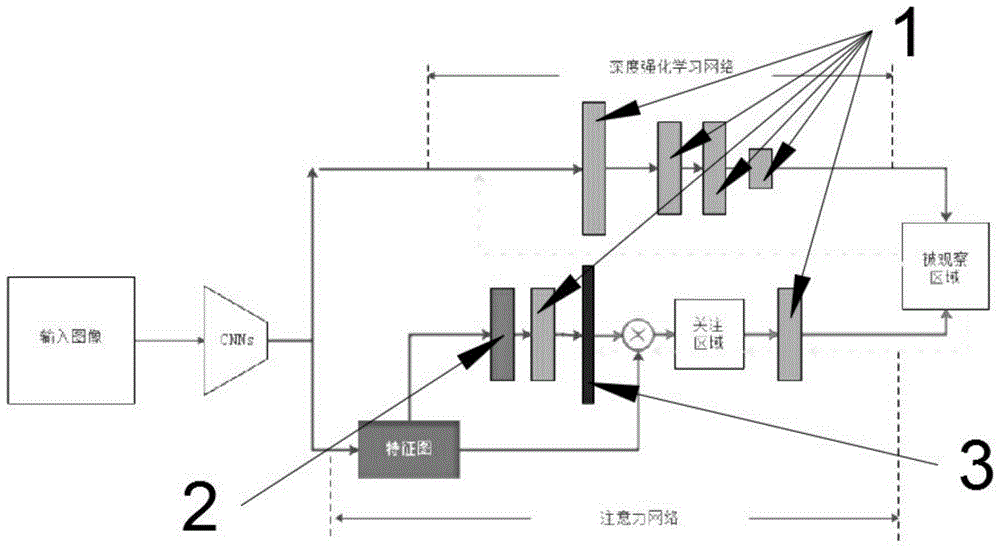
步骤一,向模型内输入图像,所述模型分为两个子网络,分别是深度强化学习网络和注意力网络;
步骤二,模型处理图像,分为四个阶段:
1)第一阶段,是深度强化学习的训练阶段,在强化学习框架下,目标定位任务会被对应到三个要素中去,即状态state、动作action、收益reward,深度强化学习所需学习训练的就是控制行为的策略参数π;
状态state由深度卷积神经网络cnns对被观察区域进行编码生成向量o;
动作action包括了水平移动、垂直移动、缩放变化、横宽比例变化、位置确定;
收益reward用来衡量被观察区域b与目标实际区域g之间的相对关系;
iou(b,g)=area(b∩g)/area(b∪g),
reward被表示为ra(s,s1)=sign(iou(b1,g)-iou(b,g));
2)第二阶段,被观察区域反向传播到注意力网络,以训练注意力向量层的参数;
3)第三阶段,通过reward中满足阈值所训练后的注意力网络在测试图像中截取关注区域;
4)第四阶段,关注区域被传送给深度强化学习网络以迅速锁定目标区域提升效率。
根据上述技术方案,所述步骤一中,深度强化学习网络dqn是指在强化学习框架下,利用深度卷积神经网络对图像这种高维数据进行编码降维,提取图像特征。
根据上述技术方案,所述步骤二1)中,在目标定位任务中,state代表了所观察区域的图像特征,action代表了对所观察区域的形变的各种控制动作,reward代表了观察区域与目标真实位置之间的相互关系。
根据上述技术方案,所述步骤二1)中,控制策略π即对搜索行为进行控制的是两个全连接层的神经网络。
根据上述技术方案,所述步骤二1)中,第一阶段采用有监督模式。
根据上述技术方案,所述步骤二2)中,
1)注意力网络首先利用深度卷积神经网络技术将图像转化为h×w×c尺寸的特征图;
2)接着我们用通道描述子p来编码特征图中的空间信息,表达式为
3)接下来为了我们利用这些描述信息组建注意力网络中的权重ai=σ(w2f(w1p));
4)我们接下来将不同通道的注意力权重组建为注意力图
根据上述技术方案,所述bc表示在第c个通道上的特征;c代表通道数,c代表第c个通道;f(·)作为激活函数,ai为关联通道中某部分的权重;tx和ty代表了关注区域中心的横纵坐标,ts代表了关注区域的变长。
与现有技术相比,本发明所达到的有益效果是:该基于注意力的深度加速强化学习的目标定位方法,在原有的深度强化学习框架下添加了注意力网络;这个方法将利用强化学习训练过程产生的数据来对注意力网络进行训练,以此得到注意力向量,在这里将深度强化学习网络dqn黑盒问题研究转换为注意力向量的白盒问题,同时可利用注意力机制优化dqn对位置定位过程的控制。
附图说明
附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:
图1是本发明的整体流程示意图;
图中:1、全连接层;2、池化层;3、注意力向量层。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:一种基于注意力的深度加速强化学习的目标定位方法,包括以下步骤:
步骤一,向模型内输入图像,模型分为两个子网络,分别是深度强化学习网络和注意力网络;
步骤二,模型处理图像,分为四个阶段:
1)第一阶段,是深度强化学习的训练阶段,在强化学习框架下,目标定位任务会被对应到三个要素中去,即状态state、动作action、收益reward,深度强化学习所需学习训练的就是控制行为的策略参数π;
状态state由深度卷积神经网络cnns对被观察区域进行编码生成向量o;
动作action包括了水平移动、垂直移动、缩放变化、横宽比例变化、位置确定;
收益reward用来衡量被观察区域b与目标实际区域g之间的相对关系;
iou(b,g)=area(b∩g)/area(b∪g),
reward被表示为ra(s,s1)=sign(iou(b1,g)-iou(b,g));
2)第二阶段,被观察区域反向传播到注意力网络,以训练注意力向量层的参数;
3)第三阶段,通过reward中满足阈值所训练后的注意力网络在测试图像中截取关注区域;
4)第四阶段,关注区域被传送给深度强化学习网络以迅速锁定目标区域提升效率。
根据上述技术方案,步骤一中,深度强化学习网络dqn是指在强化学习框架下,利用深度卷积神经网络对图像这种高维数据进行编码降维,提取图像特征。
根据上述技术方案,步骤二1)中,在目标定位任务中,state代表了所观察区域的图像特征,action代表了对所观察区域的形变的各种控制动作,reward代表了观察区域与目标真实位置之间的相互关系。
根据上述技术方案,步骤二1)中,控制策略π即对搜索行为进行控制的是两个全连接层的神经网络。
根据上述技术方案,步骤二1)中,第一阶段采用有监督模式。
根据上述技术方案,步骤二2)中,
1)注意力网络首先利用深度卷积神经网络技术将图像转化为h×w×c尺寸的特征图;
2)接着我们用通道描述子p来编码特征图中的空间信息,表达式为
3)接下来为了我们利用这些描述信息组建注意力网络中的权重ai=σ(w2f(w1p));
4)我们接下来将不同通道的注意力权重组建为注意力图
根据上述技术方案,bc表示在第c个通道上的特征;c代表通道数,c代表第c个通道;f(·)作为激活函数,ai为关联通道中某部分的权重;tx和ty代表了关注区域中心的横纵坐标,ts代表了关注区域的变长。
需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。
最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!