一种基于因子图的逆深度估计方法与流程
本发明属于图像处理和单目相机深度估计技术领域,具体来说是一种基于因子图的逆深度估计方法。
背景技术:
随着人工智能技术的发展,对单目视觉slam(simultaneouslocalizationandmapping,即时定位与地图构建)的研究也越来越深入,其中一种重要的研究内容是单目视觉深度信息的估计,这也是单目视觉的一个研究难点。只有深度信息估计的准确,才能保证slam定位的准确性。而将概率图模型应用到深度估计中,这也是将人工智能的方法应用到slam中。
技术实现要素:
本发明提出了一种基于因子图的逆深度估计方法,有效提高了单目相机深度估计的精度。本发明首先利用三角形方法求出图像中对应点的深度;然后利用因子图模型来优化相机的位姿,减少位姿误差对深度估计的影响;最后利用逆深度估计的方法对深度进行优化,提高其估计的精度。
本发明提供的基于因子图的逆深度估计方法,包括如下步骤:
步骤一、利用三角形方法测量空间中对应点的深度,其中利用了对极几何的基本原理;
步骤二、利用因子图模型对单目相机进行建模,利用李群-李代数之间的转换关系将位姿估计转换为无约束的优化问题求解;
步骤三、利用逆深度滤波方法来对深度进行滤波,将每次求得的逆深度进行融合,进而获得融合后的深度;
利用上述得到的深度和余弦定理,可以测量空间中物体的长度,从而验证该方法的合理性。
本发明的优点在于:
(1)本发明将因子图模型引用到逆深度的测量中,既有利于该估计方法的扩展,也提高了估计的精度。
(2)本发明利用李群-李代数之间的转换关系将位姿估计转换为无约束的优化问题,简化了求解方法。
(3)本发明提出的逆深度滤波的方法,有效的解决了远离相机中心的像素出现拖尾现象,提高了鲁棒性。
附图说明
图1:本发明中对极几何原理图;
图2:本发明中因子图模型示意图;
图3:本发明中逆深度不确定性关系分析图;
图4:本发明中相机测距原理图;
图5:本发明中室内环境实验对比图;
图6:本发明中室外环境实验对比图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的详细说明。
本发明提供一种基于因子图的逆深度估计方法,包括步骤:
步骤一、利用三角形方法测量空间中任意一空间点的深度信息,其中利用了对极几何的基本原理
(1)对极几何;
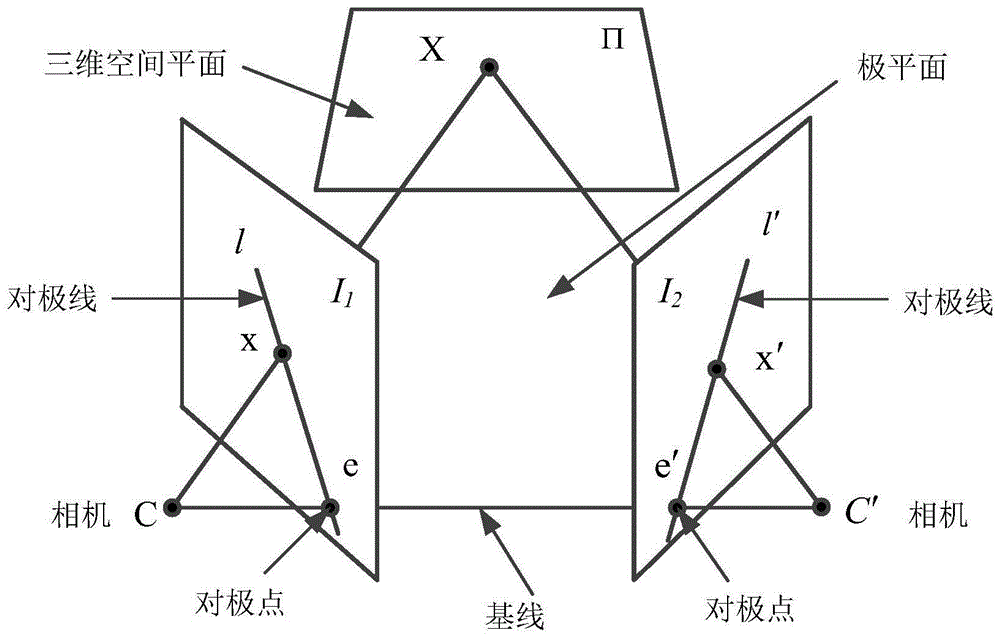
对极几何是两幅视图之间内在的射影几何。它独立于景物结构,只依赖于相机的内参数和相对姿态。对极几何的原理图如图1所示。空间平面π上的一空间点x在两个成像平面i1、i2上的投影分别为x和x′。由x、c和c′组成的平面称为对极平面,该平面包含基线,c和c′分别是两个成像平面位置处相机中心点。e和e′是对极点,它是连接两相机中心的直线cc′与两个成像平面的交点,对极点是在一幅视图中另一相机中心的像,它也是基线方向的消影点。l和l′是对极线,它是对极平面与成像平面的交线,当对极平面绕基线旋转时,每个成像平面上所有的对极线都交于对极点。
结论:对两幅图像中任何一对对应点
基本矩阵f是对极几何的代数表示。基本矩阵f具有如下两个重要性质:
a.利用基本矩阵f求对极点:fe=0,fte′=0。
b.利用基本矩阵f求对极线:l′=fx,l=ftx′。
(2)利用三角形法求空间点x的深度。
通过在两个位置处观察同一空间点x的夹角,从而确定该空间点的深度,所述深度是指空间点到相机中心的距离。
s1x=kx,s2x′=k(rx+t)(1)
其中,s1为相机在位置1的深度,s2为相机在位置2的深度,k为相机的内参数矩阵,x为空间中任意一点,公式中表示该空间点的三维位置,x和x′分别表示成像平面内两个对应点的三维位置,r为旋转矩阵,t为平移向量。令y=k-1x,y′=k-1x′,则由式(1)可以得到:
s2y′=s1ry+t(2)
s2y′×y′=s1y′×ry+y′×t=0(3)
利用(2)(3)可以求出空间点x分别在两个成像平面上测量的深度s1和s2。
步骤二、利用因子图模型对单目相机(简称相机)进行建模,利用李群-李代数之间的转换关系将位姿估计转换为无约束的优化问题来求解。
图2为因子模型的示意图,图中各个节点表示相关的随机量。其中xi表示第i个相机位姿的节点,lj为路标节点,i=1,2,…,n;j=1,2,…,m;oij为第i个相机观测第j个路标的观测节点,fi为因子函数,表示第i个相机的位姿相对于参考相机的位姿x0的关系,x0表示参考相机的位姿。在图2中,所有相机的位姿都是相对于参考相机位姿的相对位姿。假设因子函数fi满足如下形式的高斯分布:
其中,h(xi)为第i个相机的位姿的重投影函数,μi为第i个相机的位姿对应的像素坐标的均值,h(xi)-μi为重投影函数误差,σi2为第i个相机的位姿对应的像素坐标的方差;n()表示高斯分布函数,fi(xi)表示第i个相机的位姿xi相对于参考相机位姿x0的因子函数。
因此,所有因子函数变量的联合概率分布可以写成因子乘积的形式:
最大后验概率xmax推断的形式为:
对上式(6)取对数后,可以将最大后验概率xmax推断问题转化为最小化非线性最小二乘和的问题:
假设三维空间中某点的坐标为ua=[xa,ya,za]t,其投影的像素坐标为μa=[ua,va]t。通过k个空间点来计算相机的位姿r、t,[r|t]的李代数记为ξ,像素位置和空间点位置的关系如下:
其中,sa为相机第a个空间点的深度,[r|t]表示相机的外参数矩阵,t=k[r|t]表示相机参数矩阵,ξ^表示相机外参数矩阵李代数的反对称矩阵。a表示第a个空间点,a=1,2,……,k。
将式(8)写成矩阵的形式为:
saμa=kexp(ξ^)ua(9)
因此,重投影函数为:
xia为第i个相机的第a个特征点,将重投影函数进行线性化,可以得到:
h(xia)=h(xia0+δxia)=h(xia0)+jδxia(11)
其中,j为雅克比矩阵,δxia=xia-xia0,xia0为第i个相机第a个特征点的初始位姿。
因此,相机位姿的误差函数可以表示为如下的形式:
非线性最小化问题可以转化为:
对上式(13)关于δxia求导可以得到正规方程为:
(jtj)δxia=jtb(14)
为了提高算法的运行效率,采用列文伯格-马夸尔特(lm)方法对正规方程进行修正,lm方法允许多次迭代至收敛,将步长控制在执行区域内,该方法也叫做信赖区域方法。修正后的方程如下:
(jtj+λi)δxia=jtb(15)
其中,i为n阶单位矩阵,λ为实数,当λ=0时,即为高斯-牛顿法;当λ很大时
下面关键的问题是求解雅克比矩阵j,因为旋转矩阵具有正交和行列式为1的约束,利用r,t作为优化变量来优化时,会引入额外的变量约束,增加了优化问题的难度,因此,可以通过李群-李代数之间的转换关系将位姿估计转换为无约束的优化问题,便于最优问题的求解。
假设空间点变换到相机坐标系下的坐标为u′=[x′,y′,z′]t,即:
u′=exp(ξ^)ua=[x′,y′,z′]t(16)
因此相机投影模型可以转化为:
利用方程(17)的第三行消去深度信息sa后,可以得到:
fx为相机坐标系x方向的焦距,fy为相机坐标系y方向的焦距,cx为相机在像素坐标系中偏离光心x方向的像素数,cy为相机在像素坐标系中偏离光心y方向的像素数。
因此,重投影坐标相对于所测量的像素坐标的误差函数为:
eu为重投影在x方向的误差,ev为重投影在y方向的误差。
利用链式法则对位姿进行求导,可以得到:
其中,e=(eu,ev),δξ表示李代数ξ的变化量。
公式(20)中第一项是误差关于投影点的导数,对(19)式进行求导,可以得到:
公式(20)中第二项为变换后的点关于李代数的导数,空间点的变换为t=exp(ξ^),t左乘一个扰动为δt=exp(δξ^),假设扰动项的李代数为δξ=[δρ,δφ]t,其推导过程如下:
取其前三维即可得到u′关于位姿导数,即:
其中,i为n阶单位矩阵,δρ表示李代数se(3)的前三维向量的变化量,δφ表示李代数se(3)的后三维向量的变化量。在se(3)李代数中,符号“^”广泛的表达为“从向量到矩阵”。
将式(21)和式(23)相乘后,即可求出误差关于位姿的导数:
通过以上方法即可得到相机优化后的位姿,进而为逆深度的优化做好了准备工作。
步骤三、利用逆深度滤波方法来对深度进行滤波,将每次求得的逆深度进行融合,进而获得融合后的深度。
逆深度滤波器是使逆深度估计能够随着测量数据的增加,从一个不确定的逆深度值,逐渐收敛到一个稳定值,估计逆深度分布的变化情况。通常包括极线搜索和块匹配技术。对于一幅图像中的点,其逆深度是未知的,该点所对应的空间点分布在一条线段中,在另一个视角来看,这条线段的投影为图像平面的一条线,这条线就是极线。块匹配技术是在匹配点附近选取一个w×w的小块,在极线上也选取同样大小的小块进行灰度值的比较,可以在一定程度上提高分辨率。假设匹配点的小块用ae表示,极线上的小块用be表示。评价方法有三种:
第一种,sad(sumofabsolutedifference):差的绝对值之和,即取两个小块灰度值的差的绝对值之和。
其中,p=1,2…w,q=1,2,…w,a(p,q)为匹配点上的像素(p,q)的灰度值,b(p,q)为极线上的像素(p,q)的灰度值。
第二种,ssd(sumofsquareddistance):两个小块灰度值的差的平方和。
第三种,ncc(normalizedcrosscorrelation):归一化互相关。需要计算两个小块的相关性。
本文采用ncc的评价方法。
在实际应用中,逆深度具有更好的数值稳定性。
设像素点的逆深度τ服从高斯分布:
p(τ)=n(μ,σ2)(28)
其中,p(τ)、μ、σ2分别表示逆深度τ的概率密度函数、均值和方差。
新观测得到的逆深度数据也服从高斯分布:
p(τ′)=n(μ′,σ′2)(29)
其中,p(τ′)、μ′、σ′2分别表示新观测得到的逆深度τ′的概率密度函数、均值和方差。
将原来深度和观测后的数据进行融合后,仍然是高斯分布:
只考虑几何不确定性的情况下,关于融合后的均值方差μ′,σ′2的计算如下。
逆深度不确定性关系如图3所示。假设
通过三角形法可以求得深度
根据几何关系,可以得到:
对第二个相机的位姿x2扰动一个像素,将使底角β产生一个变化量δβ,由于相机的焦距为f,η为每一个像素的尺寸,于是可得:
根据几何关系可以得到:
根据正弦定理,可以得到深度
因为逆深度为深度的倒数,所以,
因此可以得到σ′2的估计为:
当不确定性σ′2小于一定的阈值后,则可认为深度数据已经收敛了。
利用深度和余弦定理来测量空间中物体的长度,从而验证该方法的合理性。图4为利用单目相机所测量的深度估计图像中两点间距离的示意图,θ为相机中心与两个目标点之间的夹角。通常可以利用深度的方向向量求出夹角:
已知两个目标点的深度向量
应用本发明提供的逆深度滤波方法测量两个目标点的距离,测量误差小于20%。
实施例
本发明采用720p的usb摄像头来进行实验,相机焦距f为3.6mm。为了保证实验的可对比性,所有的位姿优化都使用g2o的方法。将分别对深度滤波器,逆深度滤波器和混合逆深度滤波器进行对比。分别采用30幅图像进行迭代求解,将最后的迭代结果作为最终的测量结果。
(1)室内环境的估计对比实验
图5中,(a)为室内环境原始图像,其中标注真实测量距离0.4m。(b)为利用深度滤波器滤波后所得到的深度图,通过深度图测量的距离为0.27m,误差(32.5%)最大。(c)为利用高斯逆深度滤波器滤波后所得到的逆深度图像,通过图像可以清晰的看到物体的轮廓线,其测量的距离为0.33m,误差(17.5%)较小。
通过将深度滤波器和逆深度滤波器的计算结果对比可以得到,逆深度滤波器的计算更加稳定。深度滤波器假设在测量点附近像素的深度满足高斯分布,但这种假设会造成靠近相机中心的像素过于集中,而远离相机中心的像素出现拖尾现象,造成数据分布不均匀,抗干扰能力比较差。逆深度滤波器,则是对像素的深度信息取倒数后,假设其倒数满足高斯分布,该假设有效的解决了像素拖尾的现象,分散靠近相机中的像素,使像素深度的分布更加合理,因此,实验结果更加稳定,抗干扰性更好。
(2)室外环境的估计对比实验
图6中,(a)为室外环境的原始图,其中标注的两点间的真实测量距离为1m。(b)为利用深度滤波器滤波后得到的深度图,其测量的距离为0.77m,误差(23%)比较大。(c)为利用逆深度滤波器滤波后得到的逆深度图,其测量距离为0.8m,误差20%,与深度法相比精度有所提高,外形轮廓比较明显。通过对以上实验的对比结果可以看出,逆深度滤波优于深度滤波法。逆深度滤波主要解决了数据拖尾的现象,而混合逆深度滤波则主要解决了抗干扰的问题。
- 还没有人留言评论。精彩留言会获得点赞!