基于深度多重解析网络的缺失CT投影数据估计方法与流程
本发明涉及医学图像重建技术领域,具体涉及一种基于深度多重解析网络的缺失ct投影数据估计方法。
背景技术:
作为目前一种常规有效的临床医学诊断工具,x射线计算机断层摄影术为临床医生的诊断提供了丰富的人体器官组织信息。但是由相关研究表明:一次完全的ct扫描通常伴随着较高程度的电离辐射,而高剂量电离辐射可诱发人体新陈代谢异常乃至癌症、白血病等疾病。
临床上减少病患辐射量的重要方法之一就是减小ct扫描范围,即将探测器的旋转角度范围限制在某个小于标准的区间内,从而在总体上大幅减少了患者所受x射线辐射量。虽然限制ct设备扫描范围能够降低患者所受x射线辐射量,但同时会造成所获ct投影数据部分缺失,即获得的是不完全投影数据,使重建ct图像质量明显下降,以至于无法满足临床诊断的需要。同样在多排ct成像中,x射线辐射量的降低会造成重建图像质量的明显下降。随着扫描范围的减小,虽然患者受到的辐射剂量大幅降低,但是重建图像出现大量星条状伪影和噪声,严重影响了对特征点的分辨。因此,如何在减小扫描范围,即投影数据不完全条件下重建出符合临床诊断要求、高质量的ct图像具有重要的科学意义和临床实用价值,也引起了国内外学者越来越多的重视。
2014年美国北卡罗来纳大学教堂山分校idea研究团队利用随机森林、卷积神经网络等算法,结合自动上下文模型从mri和低剂量pet图像中估计正常剂量pet图像或ct图像。boublil等人提出了使用人工神经网络来提升常用ct图像重建算法性能的理论框架,并将其成功应用于低剂量医学图像重建。dosovitskiy等人证明了可以通过通过解码器网络反转深度卷积网络特征来重建目标图像。kingma等人提出变分自动编码器(vae),其通过在潜在单元上施加先验来使编码器正规化,使得可以通过从潜在单元采样或插入潜在单元来生成图像。然而,由于其基于像素方式高斯似然的训练目标,vae生成的图像通常是模糊的。wright等人将图像完成作为从输入中恢复稀疏信号的任务,通过求解稀疏线性系统,可以从一些损坏的输入中恢复图像。然而,该算法要求图像高度结构化(即,假设数据点位于低维子空间中),例如:良好对齐的面部图像。pathak等人提出用上下文编码器模型来对图像进行重建,但仍存在生成图像缺失边界的像素值不一致性的问题。
技术实现要素:
本发明的目的在于克服现有技术中的不足,弥补生成图像缺失部分边界的像素值不一致的问题,提出了一种基于深度多重解析网络的缺失ct投影数据估计方法,提高生成的完全ct图像质量。
为解决上述技术问题,本发明提供了一种基于深度多重解析网络的缺失ct投影数据估计方法,其特征是,包括以下步骤:
s1,获取一定数量的完全ct投影数据图像,对每个图像进行部分遮挡,得到缺失部分的ct投影数据原图和具有缺失区域的缺失ct投影数据图像;
s2,将缺失部分的ct投影数据原图和具有缺失区域的缺失ct投影数据图像作为训练数据,输入预设的深度多重解析网络模型,以训练该模型预测缺失部分ct投影数据图像;
s3,对待测的缺失ct投影数据图像,利用s2中已训练的深度多重解析网络模型进行预测得到缺失部分的ct投影数据图像;
s4,根据预测的缺失部分ct投影数据图像,重建出ct投影数据图像。
进一步的,深度多重解析网络模型包括生成器、局部鉴别器和全局鉴别器。
进一步的,深度多重解析网络模型的训练过程为:
将缺失ct投影数据图像作为生成器输入,生成器输出缺失部分的ct投影数据图像;
将生成器输出的缺失部分的ct投影数据图像与缺失部分的ct投影数据原图输入到局部鉴别器中,判断生成器输出的缺失部分的ct投影数据图像是真实或是合成;
将生成器输出的缺失部分的ct投影数据图像与完全ct投影数据图像拼接成新的完全投影数据图像,和完全ct投影数据原图均作为全局鉴别器的输入,判断生成器输出的缺失部分的ct投影数据图像是真实或是合成。
进一步的,生成器网络中包含五层卷积层、两层全连接层和五层反卷积层;卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(3,2)、(3,4)、(4,4)、(2,2),填充采用补零填充,5层卷积核数量分别为32,32,64,128,256;5层反卷积层,卷积核尺寸均为4×4,步长分别为(2,2)、(2,2)、(3,4)、(3,4)、(2,2),填充采用补零填充,5层卷积核数量分别为256,128,64,32,32,每一层均进行批量归一化,激活函数采用修正线性单元函数,最后一层激活函数采用双曲正切函数。
进一步的,局部鉴别器网络具有五层卷积层,包括卷积、批量归一化和激活函数操作,以及一个输出层;卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(2,2)、(3,4)、(3,4)、(2,2),填充采用补零填充,5层卷积核数量分别为32,64,128,128,256;每一层均进行批量归一化,激活函数采用带泄露线性整流函数。
进一步的,全局鉴别器网络具有五层卷积层,包括卷积、批量归一化和激活函数操作,以及一个输出层;卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(2,2)、(3,4)、(4,4)、(3,2),填充采用补零填充,5层卷积核数量分别为32,64,128,128,256;每一层均进行批量归一化,激活函数采用带泄露线性整流函数。
进一步的,采用卷积滤波反投影方法从预测的缺失部分ct投影数据图像中重建出ct投影数据图像。
与现有技术相比,本发明所达到的有益效果是:本发明的方法使得生成的ct投影数据图像的缺失区域边界更具连贯性,psnr(peaksingnaltonoise,峰值信噪比)值和ssim(structuresimilarityindex,结构相似性)值均体现了本发明方法的优越性。
附图说明
图1是本发明方法的流程示意图;
图2是深度多重解析网络模型。
具体实施方式
下面结合附图对本发明作进一步描述。以下实施例仅用于更加清楚地说明本发明的技术方案,而不能以此来限制本发明的保护范围。
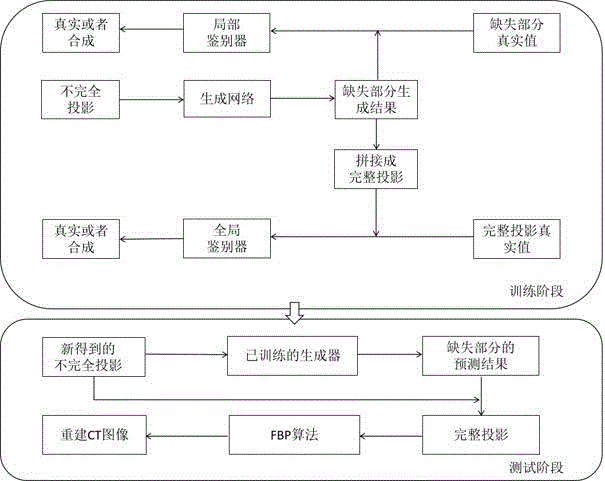
本发明的一种基于深度多重解析网络的缺失ct投影数据估计方法,参见图1所示,包括以下过程:
步骤(1),将一定数量的完全ct投影数据图像作为训练数据,对每个图像进行部分遮挡,得到缺失(遮挡)部分的ct投影数据原图和具有缺失区域的缺失ct投影数据图像。
本发明中训练数据图像数量是124张,图像尺寸是720×1024像素。
步骤(2),构建深度多重解析网络模型,如图2所示,该模型包括生成器、局部鉴别器和全局鉴别器。其中生成器网络,将缺失ct投影数据图像作为生成器输入,输出缺失部分的ct投影数据图像。
生成器网络中包含五层卷积层(编码器)、两层全连接层和五层反卷积层(解码器)。卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(3,2)、(3,4)、(4,4)、(2,2),填充采用补零填充,5层卷积核数量分别为32,32,64,128,256;5层反卷积层,卷积核尺寸均为4×4,步长分别为(2,2)、(2,2)、(3,4)、(3,4)、(2,2),填充采用补零填充,5层卷积核数量分别为256,128,64,32,32,每一层均进行批量归一化,激活函数采用修正线性单元函数,最后一层激活函数采用双曲正切函数。
步骤(3),将生成器的输出与缺失部分的ct投影数据原图输入到局部鉴别器中,判断生成器输出的投影数据图像是真实或是合成。
局部鉴别器网络具有五层卷积层,包括卷积、批量归一化和激活函数操作,以及一个输出层。卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(2,2)、(3,4)、(3,4)、(2,2),填充采用补零填充,5层卷积核数量分别为32,64,128,128,256;每一层均进行批量归一化,激活函数采用带泄露线性整流函数。
步骤(4),将生成器的输出与完全ct投影数据图像拼接成新的完全投影,和完全ct投影数据原图均作为全局鉴别器的输入,判断生成器输出的投影数据图像是真实或是合成,训练该网络预测缺失部分的ct投影数据。
全局鉴别器网络具有与局部鉴别器的卷积层类似的架构,具有五层卷积层,包括卷积、批量归一化和激活函数操作,以及一个输出层。卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(2,2)、(3,4)、(4,4)、(3,2),填充采用补零填充,5层卷积核数量分别为32,64,128,128,256;每一层均进行批量归一化,激活函数采用带泄露线性整流函数。
训练的最终目标是使得局部和全局鉴别器输出为真,即生成的图像达到可以媲美真实图片的质量。
步骤(5),当获得新的待预测的缺失ct投影数据图时,将新的缺失ct投影数据图作为测试数据输入到训练好的深度多重解析网络中,生成缺失部分的ct投影数据图像。
步骤(6),使用卷积滤波反投影(filteredback-projection,fbp)方法从生成的投影数据图像中重建出ct图像。
本发明旨在训练深度多重解析网络模型来预测缺失的投影数据图像,深度多重解析网络模型使用局部鉴别器和全局鉴别器,局部鉴别器使得生成器生成具有更清晰边界的缺失内容的细节,全局鉴别器弥补了局部鉴别器沿缺失区域边界的像素值的不一致行的限制,两个鉴别器结合以提高生成结果的质量。与现有方法相比,本发明的方法使得生成的ct投影数据图像的缺失区域边界更具连贯性,psnr(peaksingnaltonoise,峰值信噪比)值和ssim(structuresimilarityindex,结构相似性)值均体现了本发明方法的优越性。
实施例
本实施例为基于深度多重解析网络的缺失ct投影数据估计方法,在实际应用中,包括以下步骤:
(1)训练图像的数量为124张,图像尺寸为720×1024像素;
(2)模型训练图像124张,每次训练124张,训练迭代250次,
使用生成器的输出和投影数据原图之间的l2距离,将重建损失定义为:
其中,x是投影数据图像原图,
将对抗性损失
其中,x是投影数据图像原图,d(x)是将数据x输入到鉴别器d中得到的输出值,g为参数函数,将像素值从噪声分布(生成的像素值)z映射到数据分布(投影数据原图像素值)
联合损失函数j(x)为(1)中的重建损失和(2)中两个对抗损失的联合函数:
其中lrec即前面描述的重建损失lrec(x),
训练优化函数使用adam优化器,学习率取值为0.0002;
(3)深度多重解析网络模型的生成器输入大小为720×1024,输出大小为缺失区域的大小。网络中所用卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(3,2)、(3,4)、(4,4)、(2,2),填充采用补零填充,5层卷积核数量分别为32,32,64,128,256;解码器由5层反卷积层,卷积核尺寸均为4×4,步长分别为(2,2)、(2,2)、(3,4)、(3,4)、(2,2),填充采用补零填充,5层卷积核数量分别为256,128,64,32,32,每一层均进行批量归一化,激活函数采用修正线性单元函数,最后一层激活函数采用双曲正切函数;
(4)深度多重解析网络模型的局部鉴别器输入大小为缺失区域的大小,卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(2,2)、(3,4)、(3,4)、(2,2),填充采用补零填充,5层卷积核数量分别为32,64,128,128,256;每一层均进行批量归一化,激活函数采用带泄露线性整流函数;
(5)深度多重解析网络模型的全局鉴别器输入大小为720×1024,卷积层共5层,卷积核尺寸均为4×4,5层步长分别为(2,2)、(2,2)、(3,4)、(4,4)、(3,2),填充采用补零填充,5层卷积核数量分别为32,64,128,128,256;每一层均进行批量归一化,激活函数采用带泄露线性整流函数;
(6)重复上述步骤(1)~(5)作为深度多重解析网络的训练阶段。
(7)利用步骤(6)已训练的深度多重解析网络模型对测试图像进行测试,生成所预测的缺失ct投影数据,测试图像的数量为31张,图像尺寸为720×1024像素;
(8)使用卷积滤波反投影(filteredback-projection,fbp)方法从补全的投影数据图像中重建出ct图像。fbp算法在反投影前将每一个采集投影角度下的投影进行卷积处理,从而改善点扩散函数引起的形状伪影。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变型,这些改进和变型也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!