一种基于深度学习的三维模型到二维图像的渲染方法与流程
本发明属于计算机视觉和深度学习两大领域,具体是一种基于深度学习的三维模型到二维图像的渲染方法。
背景技术:
卡通作为一种以绘画等造型艺术为主要表现手段的艺术形式,属于非真实感渲染。在传统卡通动画的制作过程中,大量枯燥的卡通绘制工作集中在助理动画师身上,因而一个自然的想法就是借助计算机来减轻助理动画师的工作,从而提高卡通动画的制作效率。在以二维卡通动画设计为主的动画制作系统中,通常是利用形状插值和区域自动填色来完成全部或部分助理动画师的工作,从而提高卡通动画制作的效率。但这种方法还是需要画师来处理大部分工作。所以我们需要让计算机来完成大部分工作,而非真实感图像渲染正是这样一个领域。
在三维场景的非真实感绘制中,轮廓线扮演着重要的角色,是npr不可或缺的存在。轮廓线刻画了几何模型大致的轮廓和形状,展现了三维模型的基本外观。艺术家因此经常通过显式地加强绘制轮廓线,或通过简化某些不是非常关键的局部细节来表达各自的设计意图,于是在图形交流中起到巨大作用。因此这一技术在科学可视化、三维场景的快速绘制等领域有着广阔的应用前景。
对于非真实感绘制来说,不需要像真实感绘制中一样,物体的形状需要三角面片或者高次曲面再加上场景中的光照等等外部信息等来描述。非真实感绘制仅仅需要一组曲线就可以表达出物体的形状信息,一个仅仅在非真实感领域才需要绘制出来的物体信息。正是由于轮廓线对于npr绘制的重要性和其在非真实感各种风格之间的通用性,因此对轮廓线检测和绘制算法的研究不可否认的被当成了整个npr领域的重点。
非真实感渲染中还存在着一个较为严重的问题:线条过度不如画师手绘稿自然有韵味。在传统的手工绘画中,画师的一笔一划轻重缓急都有讲究,人手在绘画过程中会产生随机抖动,使线条粗细不一,正是这种随机产生的‘错误’赋予了一幅画面生动感。然而由计算机渲染出来的轮廓线粗细一致,极为精确,但这也使画面缺少了其应该具有的韵味。所以如何模仿出手绘的效果一直是非真实感渲染领域关注的热点话题。该问题可以被归结于图像风格迁移,近年深度学习在图像风格迁移方面取得了巨大的进展,利用深度学习来实现轮廓风格化是一种高效的解决方案。
公开号为cn107977414a的中国专利公开了一种基于深度学习的图像风格迁移方法及其系统,使用vgg网络计算训练图、风格图和生成图之间的代价,然后使用adam优化器根据计算出的代价对图像转换网络进行修正,直到图像转换网络收敛,保存训练好的模型文件,最后将需要迁移风格的图片输入该模型文件中得到风格迁移后的效果图。该方法及系统能够将普通的图片转换为优美的艺术风格作品,试验表明该方法对艺术图像的纹理有着良好的学习能力,系统能够在云平台下实现,且具有很高的负载能力。
技术实现要素:
本发明的目的是针对现有技术存在的问题,提供一种基于深度学习的三维模型到二维图像的渲染方法,用以解决三维模型到二维动画非真实感图像渲染(npr)过程中的系列问题。
为实现上述目的,本发明采用的技术方案是:
一种基于深度学习的三维模型到二维图像的渲染方法,包括:基于深度学习的轮廓渲染及其风格化方法;基于深度学习的光影渲染及其风格化方法;
所述基于深度学习的轮廓渲染及其风格化方法包括以下步骤:
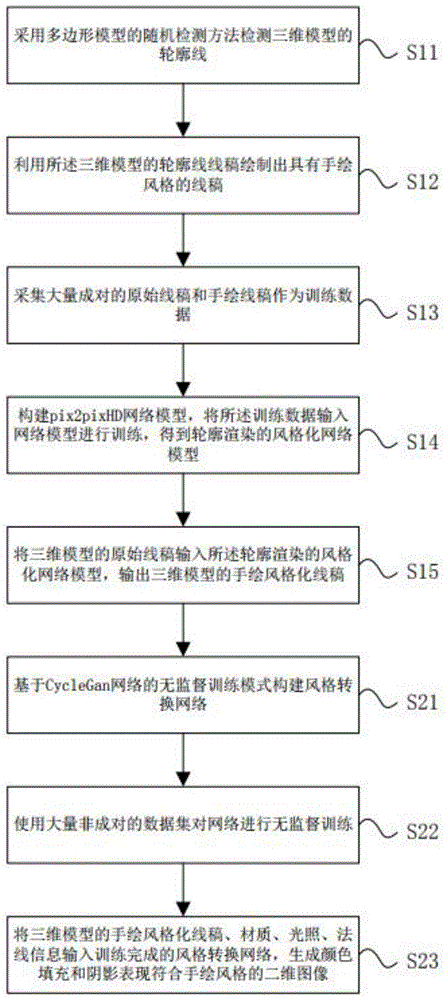
s11,采用多边形模型的随机检测方法检测三维模型的轮廓线;
s12,利用所述三维模型的轮廓线线稿绘制出具有手绘风格的线稿;
s13,采集大量成对的原始线稿和手绘线稿作为训练数据;
s14,构建pix2pixhd网络模型,将所述训练数据输入网络模型进行训练,得到轮廓渲染的风格化网络模型;
s15,将三维模型的原始线稿输入所述轮廓渲染的风格化网络模型,输出三维模型的手绘风格化线稿;
所述基于深度学习的光影渲染及其风格化方法包括以下步骤:
s21,基于cyclegan网络的无监督训练模式构建风格转换网络;
s22,使用大量非成对的数据集对网络进行无监督训练;
s23,将三维模型的手绘风格化线稿、材质、光照、法线信息输入训练完成的风格转换网络,生成颜色填充和阴影表现符合手绘风格的二维图像。
具体地,步骤s11中,所述多边形模型的随机检测方法有两条重要的理论依据:其一是一条轮廓线的相邻边存在很大几率是另一条轮廓边;其二是视点小范围内移动时,上下帧的轮廓线大部分相同;该检测方法避免了现有轮廓提取算法在实时交互系统中的局限性,并且也不需要输入相邻信息作为已知数据,由于其的时空一致性和每两点间线段为一条边的特性,所以在满足实时效率之外还同时可以方便的进行线条的风格化绘制。同时相比其他基于图像空间的算法,易于实现。
具体地,步骤s12中,绘制具有手绘风格的线稿具体为:改变原始线稿中的线型粗细和笔画模拟的风格,使绘制出的线稿具有手绘的风格;所述原始线稿为通过多边形模型的随机检测方法检测得到的三维模型轮廓线线稿。
具体地,步骤s14中,所述pix2pixhd网络模型包括生成器和判别器,传统pix2pix网络模型中给定语义标签图和对应的真实照片集(si,xi);所述生成器用于从语义标签图生成出真实图像,所述判别器用于区分真实图像和生成的图像;所述pix2pixhd网络模型对应的优化问题如下:
其中,
lgan(g,d)=e(s,x)[logd(s,x)]+es[log(1-d(s,g(s)))]
所述pix2pixhd网络模型将生成器拆分成两个子网络:全局生成器网络g1和局部增强网络g2;所述全局生成器网络g1的输入和输出的图像分辨率保持一致;所述局部增强网络g2的输出图像分辨率为输入图像分辨率的4倍(长宽各2倍);依此类推,若想得到更高分辨率的图像,只需要增加更多的局部增强网络即可(如g={g1,g2,g3})。
进一步地,所述全局生成器网络g1由一个卷积前端
进一步地,为了解决高分辨率所需的鉴别器大感受野以及所带来的网络深度增加、过拟合问题以及所需现存过大的问题,所述pix2pixhd网络模型采用3个判别器来处理不同尺度的图像,该3个判别器具有相同的网络结构;为使训练更加稳定,引入特征匹配损失函数:
其中,
引入特征匹配损失函数后,所述pix2pixhd网络模型的优化问题(目标函数)转化为:
其中,λ是特征匹配损失函数在优化问题中所占权重。
具体地,步骤s21中,所述风格转换网络包括生成器和判别器,所述生成器用于生成风格化的图像,所述判别器用于将生成的风格化图像与真实手绘图像做对比,并将对比结果作为损失函数训练生成器;该损失函数为:
lgan(f,dy,x,y)=ey~pdata(y)[logdy(y)]+ex~pdata(x)[log(1-dy(f(x)))]
其中,x、y分别为两种不同风格的图片集;f为从x风格到y风格的映射,用于将x中的图片x转换为y中的图片f(x);dy为f映射的判别器;
为了避免将所有x中的图片都转换为y中的同一张图片,引入另一个映射g,用于将y中的图片y转换为x中的图片g(y);其中,f(g(y))≈y,g(f(x))≈x;所述风格转换网络同时学习f和g两个映射;定义循环一致性损失函数为:
lcyc(f,g,x,y)=ex~pdata(x)[||g(f(x))-x||1]+ey~pdata(y)[||f(g(y))-y||1]
同时,为g映射引入一个判别器dx,定义损失函数lgan(g,dx,x,y),故所述风格转换网络最终的损失函数为:
l=lgan(f,dy,x,y)+lgan(f,dx,x,y)+λlcyc(f,g,x,y)。
与现有技术相比,本发明的有益效果是:(1)本发明采用多边形模型的随机检测方法检测三维模型的轮廓线,避免了现有轮廓提取算法在实时交互系统中的局限性,并且也不需要输入相邻信息作为已知数据,由于其的时空一致性和每两点间线段为一条边的特性,所以在满足实时效率之外还同时可以方便的进行线条的风格化绘制;同时相比其他基于图像空间的算法,易于实现;(2)本发明的pix2pixhd网络模型将生成器拆分成一个全局生成器网络和多个局部增强网络,可以通过增加更多的局部增强网络来提高生成图像的分辨率;(3)本发明的pix2pixhd网络模型采用3个判别器{d1,d2,d3}来处理不同尺度的图像,解决高分辨率所需的鉴别器大感受野以及所带来的网络深度增加、过拟合问题以及所需现存过大的问题。
附图说明
图1为本发明一种基于深度学习的三维模型到二维图像的渲染方法的流程示意框图;
图2为本发明中pix2pixhd网络模型的结构示意图;
图3为本发明中光影渲染及其风格化方法的流程示意图;
图4为本发明中cyclegan网络的结构示意图。
具体实施方式
下面将结合本发明中的附图,对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动条件下所获得的所有其它实施例,都属于本发明保护的范围。
如图1所示,本实施例提供了一种基于深度学习的三维模型到二维图像的渲染方法,用以解决三维模型到二维动画非真实感图像渲染(npr)过程中的系列问题;该方法具体包括:基于深度学习的轮廓渲染及其风格化方法;基于深度学习的光影渲染及其风格化方法;
所述基于深度学习的轮廓渲染及其风格化方法包括以下步骤:
s11,采用多边形模型的随机检测方法检测三维模型的轮廓线;
s12,利用所述三维模型的轮廓线线稿绘制出具有手绘风格的线稿;
s13,采集大量成对的原始线稿和手绘线稿作为训练数据;
s14,构建pix2pixhd网络模型,将所述训练数据输入网络模型进行训练,得到轮廓渲染的风格化网络模型;
s15,将三维模型的原始线稿输入所述轮廓渲染的风格化网络模型,输出三维模型的手绘风格化线稿;
所述基于深度学习的光影渲染及其风格化方法包括以下步骤:
s21,基于cyclegan网络的无监督训练模式构建风格转换网络;
s22,使用大量非成对的数据集对网络进行无监督训练;
s23,将三维模型的手绘风格化线稿、材质、光照、法线信息输入训练完成的风格转换网络,生成颜色填充和阴影表现符合手绘风格的二维图像。
具体地,步骤s11中,所述多边形模型的随机检测方法有两条重要的理论依据:其一是一条轮廓线的相邻边存在很大几率是另一条轮廓边;其二是视点小范围内移动时,上下帧的轮廓线大部分相同;该检测方法避免了现有轮廓提取算法在实时交互系统中的局限性,并且也不需要输入相邻信息作为已知数据,由于其的时空一致性和每两点间线段为一条边的特性,所以在满足实时效率之外还同时可以方便的进行线条的风格化绘制。同时相比其他基于图像空间的算法,易于实现;图形空间检测的算法检测出的轮廓线不同于图像空间的像素表示,是基于几何表述的,因此用户可以极方便的就对其施加需要的风格化绘制,包括改变线型粗细和笔划模拟的风格。
具体地,步骤s12中,绘制具有手绘风格的线稿具体为:改变原始线稿中的线型粗细和笔画模拟的风格,使绘制出的线稿具有手绘的风格;所述原始线稿为通过多边形模型的随机检测方法检测得到的三维模型轮廓线线稿。
具体地,步骤s14中,所述pix2pixhd网络模型包括生成器和判别器,传统pix2pix网络模型中给定语义标签图和对应的真实照片集(si,xi);所述生成器用于从语义标签图生成出真实图像,所述判别器用于区分真实图像和生成的图像;所述pix2pixhd网络模型对应的优化问题如下:
其中,
lgan(g,d)=e(s,x)[logd(s,x)]+es[log(1-d(s,g(s)))]
如图2所示,所述pix2pixhd网络模型将生成器拆分成两个子网络:全局生成器网络g1和局部增强网络g2;所述全局生成器网络g1的输入和输出的图像分辨率保持一致(如1024×512);所述局部增强网络g2的输出图像分辨率(如2048×1024)为输入图像分辨率(如1024×512)的4倍(长宽各2倍);依此类推,若想得到更高分辨率的图像,只需要增加更多的局部增强网络即可(如g={g1,g2,g3});传统的pix2pix网络模型采用u-net作为生成器,但是该网络模型在cityscapes数据集上生成的图像分辨率最高只有256×256。
进一步地,所述全局生成器网络g1由一个卷积前端
进一步地,为了解决高分辨率所需的鉴别器大感受野以及所带来的网络深度增加、过拟合问题以及所需现存过大的问题,所述pix2pixhd网络模型采用3个判别器来处理不同尺度的图像,该3个判别器具有相同的网络结构;为使训练更加稳定,引入特征匹配损失函数:
其中,
引入特征匹配损失函数后,所述pix2pixhd网络模型的优化问题转化为:
其中,λ是特征匹配损失函数在优化问题中所占权重。
具体地,如图3、4所示,步骤s21中,所述风格转换网络包括生成器和判别器,所述生成器用于生成风格化的图像,所述判别器用于将生成的风格化图像与真实手绘图像做对比,并将对比结果作为损失函数训练生成器;该损失函数为:
lgan(f,dy,x,y)=ey~pdata(y)[logdy(y)]+ex~pdata(x)[log(1-dy(f(x)))]
其中,x、y分别为两种不同风格的图片集;f为从x风格到y风格的映射,用于将x中的图片x转换为y中的图片f(x);dy为f映射的判别器;
为了避免将所有x中的图片都转换为y中的同一张图片,引入另一个映射g,用于将y中的图片y转换为x中的图片g(y);其中,f(g(y))≈y,g(f(x))≈x;所述风格转换网络同时学习f和g两个映射;定义循环一致性损失函数为:
lcyc(f,g,x,y)=ex~pdata(x)[||g(f(x))-x||1]+ey~pdata(y)[||f(g(y))-y||1]
同时,为g映射引入一个判别器dx,定义损失函数lgan(g,dx,x,y),故所述风格转换网络最终的损失函数为:
l=lgan(f,dy,x,y)+lgan(f,dx,x,y)+λlcyc(f,g,x,y)。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!