基于改进的下逼近非负矩阵对极几何估计方法与流程
本发明涉及计算机视觉技术,尤其是涉及一种基于改进的下逼近非负矩阵对极几何估计方法。
背景技术:
随着科技的进步,计算机视觉已经融入到人类生活的方方面面。计算机视觉的研究任务是通过模拟人类的视觉功能,把自然场景信息高效地转换为数字信息。而对极几何估计是通过分析两幅图像之间的约束关系,减缓噪声和离群点对真实数据的污染,极大地提高了模型拟合的鲁棒性。模型拟合是计算机视觉的一项基础性研究任务,其在图像拼接、三维重建、运动分割、平面检测和消失点检测等方面都具有广泛的应用。
针对多结构模型拟合问题,一些基于分解的方法(nmf)(比如[1]magri,luca,andandreafusiello,"robustmultiplemodelfittingwithpreferenceanalysisandlow-rankapproximation,"britishmachinevisionconference,vol.20.no.1-20,2015;[2]cai,dengandhe,xiaofeiandwang,xuanhuiandbao,hujunandhan,jiawei,"localitypreservingnonnegativematrixfactorization,"internationaljointconferenceonartificialintelligence,2009)通过执行矩阵分解技术,使用类似m估计样本与一致策略来处理多模型拟合问题,使用鲁棒主成分分析和对称非负矩阵分解实现多模型的提取。然而,nmf难以在合理的时间内找到全局最优值,它通常应用奇异值分解(svd)来求解最优秩一的nmf。这种情况下,输入矩阵与其秩一近似之间的差异不一定是非负的,这可能导致svd因素分解出现负值。一些基于双聚类的因素分析方法(比如[3]denitto,matteoandmagri,lucaandfarinelli,alessandroandfusiello,andreaandbicego,manuele,"multiplestructurerecoveryviaprobabilisticbiclustering,"jointiaprinternationalworkshopsonstatisticaltechniquesinpatternrecognitionandstructuralandsyntacticpatternrecognition,2016;[4]tepper,mariano,andguillermosapiro,"fastl1-nmfformultipleparametricmodelestimation,"tehnicalreport,2016)常用于分离出偏好矩阵中具有一致“行为”的数据。这些方法的基本思想是将数据按层分解,每个层次对应一个不同的双集类。fabia方法(比如[4])则是在偏好矩阵上使用l1进行非负分解,然后采用偏好分析或一致性分析推导出特征向量,最后采用变分期望最大化算法来估计模型参数。虽然这种方法在性能上有较大的提升,但它们需要增加后处理步骤以获得该信息的双聚类因素。
下逼近非负矩阵(nmu)(比如[6]gillis,nicolas,and
技术实现要素:
本发明的目的在于提供伴随着离群点和模型假设修剪技术的基于改进的下逼近非负矩阵对极几何估计方法。
本发明包括以下步骤:
1)准备一组匹配对
2)使用误匹配修剪技术移除离群点;
在步骤2)中,所述误匹配修剪技术的具体步骤可为:
2.1构建x和y的增广齐次坐标矩阵
其中,x,
2.2把一个假定为正确匹配的点[α,β,1]t加入到ax和ay(其中,(α,β,1)表示齐次坐标),得到:
该点对应的匹配点
2.3.在获得一个匹配点后,利用迭代法来提取更多可靠的匹配点,匹配点的索引集
其中,i为匹配点下标,t为当前迭代次数,
2.4.使用最大重投影误差分离内点和离群点,如下所示:
其中,γt为一个阈值,θ为内点集,||·||f为f-范数操作。
3)使用模型假设修剪技术选择有意义的模型假设;
在步骤3)中,所述模型假设修剪技术的具体步骤可为:
3.1对输入数据进行随机采样,生成
其中,φ(·)和
3.2根据获得的权重分数集合
那么,ξi的先验概率ρi可由下式计算:
然后,先验概率的熵e计算如下:
其中,log(·)表示对数函数。
3.3熵e被作为一个自适应阈值,用于选择有意义的模型假设
其中,log(·)表示对数函数。
4)构建基于有意义的模型假设的偏好矩阵
其中,exp(·)为指数函数,η通常设置为2.5;
5)使用改进的下逼近非负矩阵进行模型拟合;
在步骤5)中,所述改进的下逼近非负矩阵进行模型拟合方法的具体步骤可为:
5.1首先,下逼近非负矩阵(nmu)可以被定义为:
其中,
其中,ψ为一个满足下逼近约束拉格朗日乘子法的矩阵;
5.2将空间约束项φ||ωu||1和稀疏约束项ψ||u||1融入到下逼近非负矩阵中:
其中,ut(m-ψ)v为最小二乘残差,φ和ψ分别为空间约束项和稀疏约束项的惩罚系数;ω为数据点的邻居矩阵,这种融合方法能提取到更多局部信息和一致特征,提升模型拟合的鲁棒性。
6)应用交替迭代法求解u和v。u的每一行和列分别表示数据点和模型假设;
7)从u中提取模型实例,输出多结构模型。
本发明提出一种基于改进的下逼近非负矩阵对极几何估计方法。首先,该方法使用误匹配修剪技术分析匹配对之间的关系剔除离群点(误匹配点)的影响。接着,使用模型假设修剪技术来选择有意义的模型假设。然后,引入空间约束项(空间上相邻的数据点更可能属于相同的模型假设)和稀疏约束项(稀疏非负元素更能体现数据点对模型的一致特征)到下逼近非负矩阵。最后,使用交替迭代法求解下逼近非负矩阵的u和v,从u中提取多结构模型。
附图说明
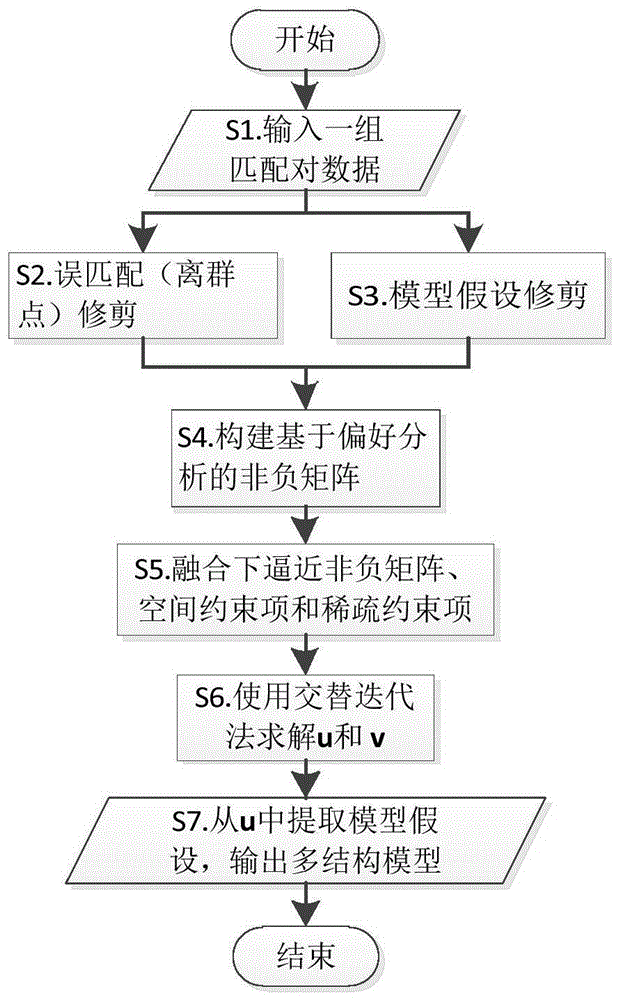
图1为本发明实施例的流程示意图。
图2为基于改进后的下逼近非负矩阵对二进制数值图像进行重构的示意图。
图3为本发明在合成数据上的直线、圆和平面的拟合结果。在图3中,(a)为合成数据上的直线,(b)为合成数据上的圆,(c)为合成数据上的平面。
图4为本发明在adelaidermf数据集上的单应性估计结果。在图4中,(a)为hartley,(b)为sene,(c)elderhalla。
图5为本发明在adelaidermf数据集上的基础矩阵分割结果。在图5中,(a)为biscuitbook,(b)为breadcube,(c)为carchipscube。
图6为本发明在yorkurban数据集上的消失点估计结果。在图6中,(a)为p1040822,(b)为p1020861,(c)为p1040812。
具体实施方式
下面结合附图和实施例对本发明的方法作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了实施方式和具体操作过程,但本发明的保护范围不限于下述的实施例。
参见图1,本发明实施例包括以下步骤:
s1.准备一组匹配对
s2.使用误匹配修剪技术移除离群点具体包括:
s2-1.构建x和y的增广齐次坐标矩阵
s2-2.把一个假定为正确匹配的点[α,β,1]t加入到ax和ay(其中,(α,β,1)表示齐次坐标),可得到:
该点对应的匹配点
s2-3.在获得一个匹配点后,利用迭代法来提取更多可靠的匹配点,匹配点的索引集
其中,i为匹配点下标,t为当前迭代次数,
s2-4.使用最大重投影误差分离内点和离群点,如下所示:
其中,γt为一个阈值,θ为内点集,||·||f为f-范数操作。
s3.使用模型假设修剪技术选择有意义的模型假设具体包括:
s3-1.对输入数据进行随机采样,生成
其中,φ(·)和
s3-2.根据获得的权重分数
那么,ξi的先验概率ρi可由下式计算:
然后,先验概率的熵e计算如下:
其中,log(·)表示对数函数。
s3-3.熵e被作为一个自适应阈值,用于选择有意义的模型假设
其中,log(·)表示对数函数。
s4.构建基于有意义的模型假设的偏好矩阵
其中,exp(·)为指数函数,η通常设置为2.5。
s5.使用改进的下逼近非负矩阵进行模型拟合方法具体包括:
s5-1.首先,下逼近非负矩阵(nmu)可以被定义为:
其中,
其中,ψ为一个满足下逼近约束拉格朗日乘子法的矩阵。
s5-2.将空间约束项φ||ωu||1和稀疏约束项ψ||u||1融入到下逼近非负矩阵中:
其中,ut(m-ψ)v为最小二乘残差,φ和ψ分别为空间约束项和稀疏约束项的惩罚系数,ω为数据点的邻居矩阵。这种融合方法能提取到更多局部信息和一致特征,提升模型拟合的鲁棒性。
基于改进后的下逼近非负矩阵对二进制数值图像进行重构的示意图参见图2。
s6.应用交替迭代法求解u和v。u的每一行和列分别表示数据点和模型假设。
s7.从u中提取模型实例,输出多结构模型。
本发明在合成数据集、adelaidermf数据集(包含19个单应性结构和19个基础矩阵结构)和yorkurban数据集(包含102个室内和室外场景)进行多结构数据估计的部分结果如图3~6所示。图3为直线、圆形和平面拟合结果,图4为单应性估计结果,图5为基础矩阵分割结果,图6为消失点估计结果。
由实验结果所示,本发明所提出的对极几何估计方法获得了较准确的拟合结果。
- 还没有人留言评论。精彩留言会获得点赞!