一种基于深度学习BERT--CNN的主观题评分模型及评分方法与流程
本发明涉及一种主观题评分模型及评分方法,具体涉及一种基于深度学习bert--cnn的主观题评分模型及评分方法,属于人工智能领域。
背景技术:
目前,仅仅依靠关键词的匹配对主观题进行评分,也就是通过提取参考答案与考生答案中关键词的方法,然后将参考答案中的关键词与考生答案中关键词进行匹配,若匹配率高,则得分高,否则得分低或不得分。
该技术虽然能提取到关键词,但往往会忽略词义或语义,以及词与词之间的关系所隐藏了大量的语义信息,基于关键词的匹配会导致这一部分信息丢失,导致评分结果不准确。
技术实现要素:
为了克服现有技术的不足,本发明的目的之一在于提供了一种基于深度学习bert--cnn的主观题评分模型,通过该模型对主观题进行评分,以解决现有人工评分中人力、财力的浪费及评分结构不合理的问题。
一种基于深度学习bert--cnn的主观题评分模型,包括bert转换词向量矩阵模块、cnn语义特征提取模块、相似度计算模块、评分模块,其中bert转换词向量矩阵模块,用于将所述答案文本转换为词向量矩阵,然后将各答案的词向量矩阵传至cnn语义特征提取模块,cnn语义特征提取模块用于获取所述答案文本的语义特征向量,包括卷积层和池化层,将所述答案文本映射矩阵输入到cnn卷积层,得到部分或所有隐含层的输出,得到各答案文本语义特征矩阵,然后将答案文本语义特征矩阵进行池化运算,获得各答案文本语义特征向量,并将其输送到相似度计算模块,计算出各答案文本语义特征向量之间的相似度值,然后将相似度值输送到评分模块,用于确定答案文本的得分。
本发明的目的之二提供一种基于深度学习bert--cnn的主观题评分模型进行评分的方法,具体步骤如下:
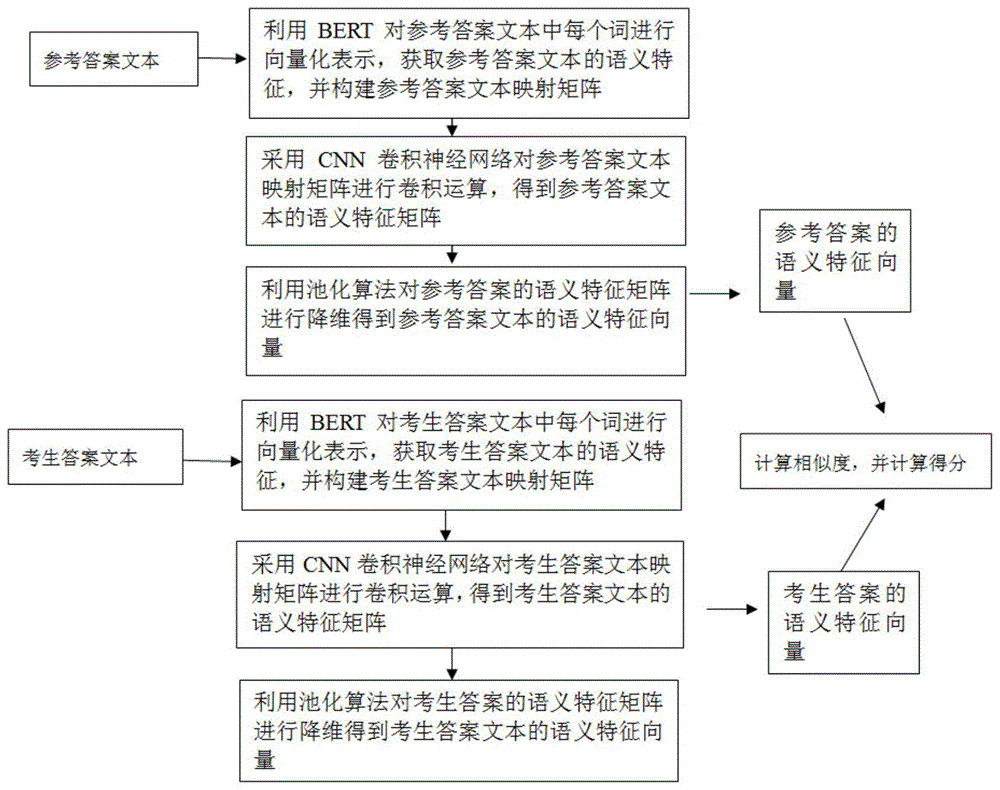
步骤(1):利用bert对主观题的参考答案文本中每个词进行向量化表示,获取参考答案文本的语义特征,并构建参考答案文本映射矩阵,采用cnn卷积神经网络对参考答案文本映射矩阵进行卷积运算,获取所有或部分隐含层的输出,得到参考答案文本的语义特征矩阵,利用池化算法对参考答案的语义特征矩阵进行降维得到参考答案文本的语义特征向量;
步骤(2):利用bert对主观题的考生答案文本中每个词进行向量化表示,获取考生答案文本的语义特征,并构建考生答案文本映射矩阵,采用cnn卷积神经网络对考生答案文本映射矩阵进行卷积运算,获取所有或部分隐含层的输出,得到考生答案文本的语义特征矩阵,利用池化算法对考生答案的语义特征矩阵进行降维得到考生答案文本的语义特征向量;
步骤(3):将步骤(1)得到的参考答案文本的语义特征向量和步骤(2)得到的考生答案文本的语义特征向量进行余弦相似度计算,得到两个语义特征向量的相似度值;
步骤(4):将所述相似度值代入计算得分模型中,计算最终得分。
步骤(4)中的计算得分模型为:最终得分=相似度*本题分值。
步骤(3)中相似度计算公式为:
其中,similarity表示相似度,a为答案文本的语义特征向量,b为考生答案文本的语义特征向量,θ表示a、b两个向量的夹角,ai表示a向量的各分向量,bi表示b向量的各分向量,n表示分向量总数。
所述步骤(1)、步骤(2)中的池化算法为最大池化法、最小池化法或平均池化法。
所述参考答案文本的语义特征向量和考生答案文本的语义特征向量均包含词义信息、语义信息、词语与文本语义之间的关联信息。
bert是一种预训练语言表示(languagerepresentations)的方法,在一个大型文本语料库(比如维基百科)上训练一个通用的“语言理解”模型,然后将这个模型用于下游nlp任务(比如问题回答)。bert优于以前的方法,因为它是第一个用于预训练nlp的无监督、深度双向的系统。
本发明的有益效果是:
(1)本发明根据bert分别从参考答案和考生答案文本中自动学习语义特征,将主观题自动评分问题转化为了依据文本语义进行评分问题。
(2)本发明首次将bert--cnn应用到中文主观题自动评分方法中,是在主观题自动评分中的新应用,具有较高的评分准确率,能适用于不同学科的主观题,例如地理、政治、历史、语文、生物等。
(3)本发明利用谷歌训练好的bert模型,获取答案文本中的语义信息,有效的解决了由于多义词的歧义问题,和未能考虑上下文信息的问题,有效挖掘了上下文中的词序特征。
(4)本发明通过cnn提取答案文本的语义特征,有效挖掘答案文本中的语义信息与词语之间的关联信息,改善了文本的语义敏感性问题,提高了主观题自动评分的性能。
(5)本发明通过自定义的计算得分模型,来计算出最终得分,应用于主观题评分中,可以有效降低人力成本,且可以克服人工评分中仅仅进行关键词匹配所造成的评分结果不准确、评分不公平的问题。
附图说明
图1是本发明的评分方法的流程图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚明白,以下结合具体实施例,并参照附图,对本发明进一步详细说明。
实施例1:本基于深度学习bert--cnn的主观题评分模型,包括bert转换词向量矩阵模块、cnn语义特征提取模块、相似度计算模块、评分模块,其中bert转换词向量矩阵模块,用于将所述答案文本转换为词向量矩阵,然后将各答案的词向量矩阵传至cnn语义特征提取模块,cnn语义特征提取模块用于获取所述答案文本的语义特征向量,包括卷积层和池化层,获得各答案文本语义特征向量,并将其输送到相似度计算模块,计算出各答案文本语义特征向量之间的相似度值,然后将相似度值输送到评分模块,用于确定答案文本的得分。
利用本基于深度学习bert--cnn的主观题评分模型进行评分的方法,首先获取一个通用的“语言理解”模型,利用谷歌训练好的bert模型,获取答案文本中的语义信息,即bert模型,然后如图1所示,进行以下步骤:
步骤(1):利用bert对主观题的参考答案文本中每个词进行向量化表示,获取参考答案文本的语义特征,并构建参考答案文本映射矩阵,采用cnn卷积神经网络对参考答案文本映射矩阵进行卷积运算,获取所有或部分隐含层的输出,得到参考答案文本的语义特征矩阵,利用池化算法对参考答案的语义特征矩阵进行降维得到参考答案文本的语义特征向量,参考答案文本的语义特征向量包含词义信息、语义信息、词语与文本语义之间的关联信息;
步骤(2):利用bert对主观题的考生答案文本中每个词进行向量化表示,获取考生答案文本的语义特征,并构建考生答案文本映射矩阵,采用cnn卷积神经网络对考生答案文本映射矩阵进行卷积运算,获取所有或部分隐含层的输出,得到考生答案文本的语义特征矩阵,利用池化算法对考生答案的语义特征矩阵进行降维得到考生答案文本的语义特征向量,考生答案文本的语义特征向量包含词义信息、语义信息、词语与文本语义之间的关联信息;
步骤(3):将步骤(1)得到的参考答案文本的语义特征向量和步骤(2)得到的考生答案文本的语义特征向量进行余弦相似度计算,得到两个语义特征向量的相似度值,相似度计算公式为:
其中,similarity表示相似度,a为答案文本的语义特征向量,b为考生答案文本的语义特征向量,θ表示a、b两个向量的夹角,ai表示a向量的各分向量,bi表示b向量的各分向量,n表示分向量总数。
步骤(4):将所述相似度值代入计算得分模型中,计算最终得分。
最终得分=相似度*本题分值。
所述步骤(1)、步骤(2)中的池化算法均为最大池化法。
实施例2:本实施例方法同实施例1相同,不同之处在于,步骤(1)、步骤(2)中的池化算法均为最小池化法。
实施例3:本实施例方法同实施例1相同,不同之处在于,步骤(1)、步骤(2)中的池化算法均为平均池化法。
上面结合附图对本发明的具体实施例作了详细说明,但是本发明并不限于上述实施例,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!