用于工业故障信息快速匹配的语义检索方法与流程
本发明属于自然语言处理文本相似度匹配技术领域,涉及一种工业故障信息快速匹配的语义检索方法。
背景技术:
随着数据时代的来临,各工业企业积累了大量的数据,有望提示和解决工业界面临的传统难题。其中凸显的一点问题是工业技术往往需要工人长时间的累计,师傅带学徒制的积累经验,学徒由于经验不足往往应对故障问题时不知道该如何去解决故障,并且由于人力原因,特殊情况等,可能师傅没有时间去优先解决该问题,这就造成了人力资源的损失和由于故障造成的财务损失。
由于目前搜索引擎技术大都基于词语逆向索引,及词语对应文档,通过输入词对应的文档取交集处理,这样的方式简单粗暴,适合于互联网中海量数据的对应搜索,但是在企业中,匹配文档量往往只有几万,十几万的数据量,且往往业务针对主题域进行设定,企业更关注的是如何提高匹配精准度和匹配速度。
相比之下,通过建立分词与词频数据仓,建立词袋模型和词的局部差和训练算法,然后通过矩阵距离算法进行匹配,更适合于工业企业检索领域和高精准度快速检索的要求。
技术实现要素:
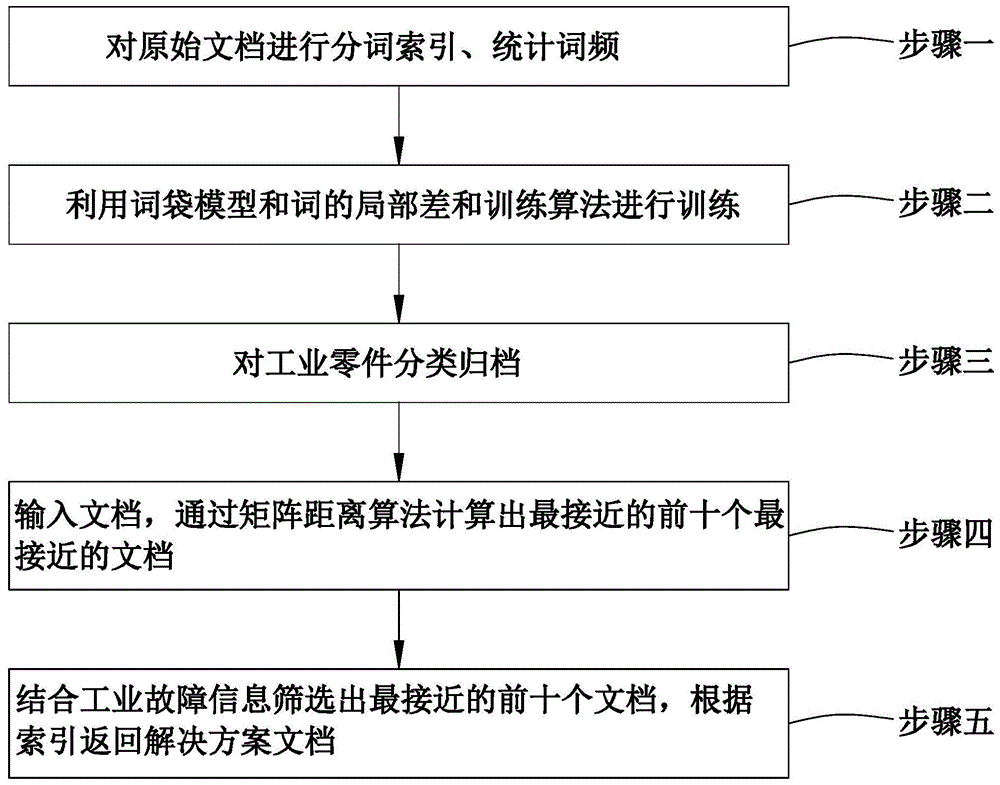
一种用于工业故障信息快速匹配的语义检索方法,包括以下步骤:
步骤一、对原始文档进行分词索引、统计词频;
步骤二、利用词袋模型和词的局部差和训练算法进行训练;
步骤三、对工业零件分类归档;
步骤四、输入待检测文档,通过矩阵距离算法计算出最接近的文档;
步骤五、结合工业故障信息筛选出最接近的前十个文档,根据索引返回解决方案文档。
进一步的,所述步骤一的分词索引,是通过把所有原始文档以单个单词为区分进行分词处理,并基于所述分词建立索引,对所有所述文档建立索引并存入数据仓,同时统计词频存入数据仓。
进一步的,所述利用词袋模型和词的局部差和训练算法具体为:基于所述数据仓的所有所述分词及所述词频进行训练,构建词出现的频率矩阵数值,设定n篇文档共有k个不同词,则构建n*k维的矩阵,矩阵i行j列内容则为第j个词在第i篇文档中出现的次数加上通过局部差和训练算法求出的表示词语位置的数值。
进一步的,所述词袋模型和词的局部差训练算法还包括位置数据的计算,所述位置数据是通过计算提取词语在文本中的位置,计算词语位置分布位置的和、差,然后两项做积,并与词频相加,实现将词语的多个位置集合为一个数字来表示,词的局部差、和是将句子位置向量压缩为一个可以逼近唯一代表其位置的一个数字,其计算公式为:
设定位置a、位置b、位置c,其中a<c,b<c,a<b,则(a/c+b/c)*(b/c-a/c)=(b2-a2)/c2<1;
由所述公式计算出的值代表词位置,当其词频不超过2时,此值必定小于1,设定每个文本分为十个位置,词语只分布在这十个位置中;当词语有n个位置时,通过所述计算公式迭代计算出第n-1个位置,重复所述计算,计算出第n-2个位置,通过重复迭代所述计算将词语的多个位置转换为2个位置,最终实现用一个数值来表示词语的多个位置的分布;所述计算采用绝对值来计算。
进一步的,所述对工业零件分类归档包含工业零件、故障现象及对应的解决方案文档,同样将所述工业零件分类归档数据存入所述数据仓。
进一步的,所述矩阵距离算法具体为:将输入待检测文档执行所述分词及词频统计、以及所述位置数据的计算,得到矩阵xak,通过将所述矩阵xak与所述数据仓中的数据矩阵xnk进行所述矩阵距离计算,在计算时所述矩阵中以相同词语做计算,即xa1与xn1对应同一个词语,计算后得到对比结果值dan,所述值dan越小表示越接近,其计算公式为:
进一步的,所述工业故障信息包括工业零件数据、故障特征数据及人为定义反馈数据。
与现有技术相比,本发明通过建立分词与词频数据仓,建立词袋模型和词的局部差和训练算法,然后通过矩阵距离算法进行匹配,更适合于工业企业检索领域和高精准度快速检索的要求。
【附图说明】
图1是本发明提供的用于工业故障信息快速匹配的语义检索方法的流程图;
图2是经过通过本方法实验比较的相同词频不同词语分布句子的实例展示。
【具体实施方式】
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本发明的一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其它实施例,都属于本发明保护的范围。
一种用于工业故障信息快速匹配的语义检索方法,包括以下步骤:
步骤一、对原始文档进行分词索引、统计词频,对所有原始文档进行分词,建立索引;
具体地,请参阅表1分词索引构建矩阵数据的举例,例如:我喜欢你,你喜欢我吗,在表1中进行分词统计,构建矩阵位[2,2,2,1],将进行分词及索引的数据存入所述数据仓;
表1
步骤二、利用词袋模型和词的局部差和训练算法进行训练,基于所述数据仓的所有所述分词及所述词频进行训练,构建词出现的频率矩阵数值,设定n篇文档共有k个不同词,则构建n*k维的矩阵,矩阵i行j列内容则为第j个词在第i篇文档中出现的次数加上通过局部差和训练算法求出的表示词语位置的数值。
进一步的,所述词袋模型和词的局部差训练算法还包括位置数据的计算,所述位置数据是通过计算提取词语在文本中的位置,计算词语位置分布位置的和、差,然后两项做积,并与词频相加,实现将词语的多个位置集合为一个数字来表示,词的局部差、和是将句子位置向量压缩为一个可以逼近唯一代表其位置的一个数字,其计算公式为:
设定位置a、位置b、位置c,其中a<c,b<c,a<b,则(a/c+b/c)*(b/c-a/c)=(b2-a2)/c2<1;
由所述公式计算出的值代表词位置,当其词频不超过2时,此值必定小于1,设定每个文本分为十个位置,词语只分布在这十个位置中;当词语超过2时,将词位置按照在文档中出现的先后顺序排序,通过逐级将相邻的两个词位置两两做和,两两做差的方式转变为2个局部向量,然后再次进行计算,所述计算采用绝对值来计算。
当词语有n个位置时,通过所述计算公式迭代计算出第n-1个位置,重复所述计算,计算出第n-2个位置,通过重复迭代所述计算将词语的多个位置转换为2个位置,最终实现用一个数值来表示词语的多个位置的分布。具体如下:
设定词语有[a,b,c]三个位置,则先计算w1=(b-a)*(b+a),然后计算:w2=(c-b)*(b+c),最后计算|w1-w2|*(w1+w2),由于可能会出现w1<w1,为了保证词语向量的非负性,我们采用绝对值来计算w1-w2,但是这就导致了误差的出现,可能会有|d2-b2|=|c2-b2|,计算出的概率为约为1/90,且随着词频的增大,误差会变得变小,当为3个词时,选中3个位置的组合有10*9*8=720种,而可能出现误差的情况只有8种,同时当词量上升时概率做乘积,会变得更小,所以延伸至词语超过3时的迭代计算方法,即通过这样不断聚合的方式来计算:
当词频超过2时,通过词块两两聚合的方式,即每两个相邻词即为一个词块来进行迭代计算,如有[a,b,c,d]4个位置,则可以分为三个词块,然后3个词块再次通过这样的方式聚合为2个词块,然后计算出结果。
请参阅图2,是经过通过本方法实验比较的相同词频不同词语分布句子的实例展示,
样例1为句子:我喜欢你,你喜欢我吗
样例2位句子:你喜欢我吗,我喜欢你
样例3为句子:我我你你,喜欢喜欢吗
通过给出的文本,可以看出1,2号句子中词语分布较为相同,同时3个句子的词频完全相同。
1.0:“你”,2.0:“吗”,3.0:“喜欢”,4.0:“我”
从图2中可以清楚看出每个句子中哪些词语的分布更为接近,例如样例1与样例3在“你”这个词分布上更接近。而在“喜欢”这个词的分布上,样例2与样例1更加接近,这与我们从句子上的观察一致,因为在样例1中,分布于2,5位置,在样例2中分布于2,6位置,而在样例3中分布于5,6位置。
步骤三、对工业零件分类归档,所述对工业零件分类归档包含工业零件、故障现象及对应的解决方案文档,同样将所述工业零件分类归档数据存入所述数据仓。
具体地,请参阅表2是工业零件数据存储举例,
表2
步骤四、输入待检测文档,通过矩阵距离算法计算出最接近的文档;所述矩阵距离算法,是将输入所述待检测文档执行所述分词及词频统计,以及所述位置数据的计算,得到矩阵xak,通过将所述矩阵xak与所述数据仓中的数据矩阵xnk进行所述矩阵距离计算,在计算时所述矩阵中以相同词语做计算,即xa1与xn1对应同一个词语,计算后得到对比结果值dan,所述值dan越小表示越接近,其计算公式为:
步骤五、结合工业故障信息筛选出最接近的前十个文档,根据索引返回解决方案文档。所述工业故障信息包括工业零件数据、故障特征数据及人为定义反馈数据。
与现有技术相比,本发明提供的语义检索方法,通过建立分词与词频数据仓,建立词袋模型和词的局部差和训练算法,然后通过矩阵距离算法进行匹配,更适合于工业企业检索领域和高精准度快速检索的要求。
以上所述的仅是本发明的实施方式,在此应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出改进,但这些均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!