一种单目深度估计方法及系统与流程
本发明涉及计算机视觉技术领域,特别是涉及一种单目深度估计方法及系统。
背景技术:
单目深度估计是计算机视觉领域中的一个基本任务,对其他许多领域都有帮助,例如,目标追踪、机器人导航和自动驾驶等领域。为了解决这个问题,目前大部分方法及采用其他方式获取的深度数据来有监督地训练深度神经网络模型,从而在测试阶段对一个单视角彩色图像进行深度估计。
但是,这种方法需要大量的深度数据作为监督数据,而现实场景中深度相机并不普及,很难获得大量的场景图像对应的深度标签,使得对单视角彩色图像进行深度估计较为困难且准确度较低。
技术实现要素:
针对于上述问题,本发明提供一种单目深度估计方法及系统,实现了无需任何额外数据作为监督,使得对单视角彩色图像的深度估计更为简便和准确。
为了实现上述目的,本发明提供了如下技术方案:
一种单目深度估计方法,该方法包括:
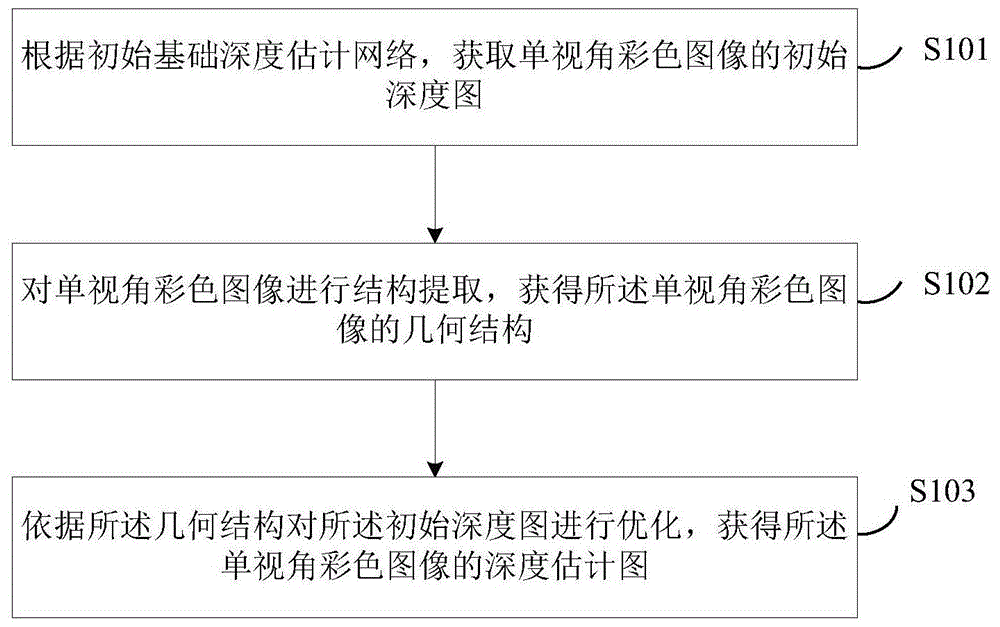
根据初始基础深度估计网络,获取单视角彩色图像的初始深度图;
对所述单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构;
依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。
可选地,所述初始基础深度估计网络包括深度估计网络和姿态估计网络,其中,所述根据初始基础深度估计网络,获取单视角彩色图像的初始深度图,包括:
通过所述深度估计网络对所述单视角彩色图像在任一视频帧对应的视频帧图像进行深度估计,获得视频帧深度图;
通过所述姿态估计网络对所述单视角彩色图像的连续两个视频帧进行测试,获得相机姿态矩阵;
基于所述相机姿态矩阵,生成所述视频帧图像至目的视图图片的映射关系,其中,所述目的视图图片为所述视频帧图像根据所述相机姿态矩阵和所述视频帧深度图形变获得的图片;
基于所述映射关系和所述目的视图图片的惩罚项,生成惩罚项公式;
基于所述惩罚项公式和所述深度估计网络对网络参数进行训练,获得初始深度图。
可选地,所述对所述单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构,包括:
依据所述预设基础深度估计网络,在所述单视角彩色图像数据集上进行训练,获得卷积层;
将所述卷积层中最后三层卷积层进行处理,获得特征图;
对所述特征图进行卷积和激活处理,获得所述单视角彩色图像的几何结构。
可选地,该方法还包括:
获取所述几何结构的结构特征信息,其中,所述依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图,包括:
依据所述结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。
可选地,所述依据所述结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图,包括:
获取所述几何结构对应的图像的像素值,并依据所述像素值计算获得域变换系数;
依据所述域变换系数与预设系数阈值,确定所述几何结构中的结构特征信息;
确定与所述结构特征信息对应的惩罚项,并基于所述惩罚项对所述结构特征信息进行训练;
依据训练后的结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。
可选地,该方法还包括:
基于所述域变换系数,对原始域变换滤波器进行优化,获得改进后的域变换公式,使得依据所述域变换公式对所述结构特征信息进行图像滤波处理。
一种单目深度估计系统,该系统包括:
初始化单元,用于根据初始基础深度估计网络,获取单视角彩色图像的初始深度图;
提取单元,用于对所述单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构;
优化单元,用于依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。
可选地,所述初始化单元包括:
估计子单元,用于通过所述深度估计网络对所述单视角彩色图像在任一视频帧对应的视频帧图像进行深度估计,获得视频帧深度图;
测试子单元,用于通过所述姿态估计网络对所述单视角彩色图像的连续两个视频帧进行测试,获得相机姿态矩阵;
第一生成子单元,用于基于所述相机姿态矩阵,生成所述视频帧图像至目的视图图片的映射关系,其中,所述目的视图图片为所述视频帧图像根据所述相机姿态矩阵和所述视频帧深度图形变获得的图片;
第二生成子单元,用于基于所述映射关系和所述目的视图图片的惩罚项,生成惩罚项公式;
第一训练子单元,用于基于所述惩罚项公式和所述深度估计网络对网络参数进行训练,获得初始深度图。
可选地,所述提取单元包括:
第二训练子单元,用于依据所述预设基础深度估计网络,在所述单视角彩色图像数据集上进行训练,获得卷积层;
第一处理子单元,用于将所述卷积层中最后三层卷积层进行处理,获得特征图;
第二处理子单元,用于对所述特征图进行卷积和激活处理,获得所述单视角彩色图像的几何结构。
可选地,该系统还包括:
信息获取单元,用于获取所述几何结构的结构特征信息,所述优化单元具体用于依据所述结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图,其中,所述优化单元包括:
像素获取子单元,用于获取所述几何结构对应的图像的像素值,并依据所述像素值计算获得域变换系数;
信息确定子单元,用于依据所述域变换系数与预设系数阈值,确定所述几何结构中的结构特征信息;
第四训练子单元,用于确定与所述结构特征信息对应的惩罚项,并基于所述惩罚项对所述结构特征信息进行训练;
优化子单元,用于依据训练后的结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图;
所述优化单元还包括:
滤波器优化子单元,用于基于所述域变换系数,对原始域变换滤波器进行优化,获得改进后的域变换公式,使得依据所述域变换公式对所述结构特征信息进行图像滤波处理。
相较于现有技术,本发明提供了一种单目深度估计方法及系统,根据初始基础深度估计网络,获取单视角彩色图像的初始深度图;对所述单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构;依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。由于使用了单视角彩色图像的几何结构对初始深度图进行了优化,可以增强深度估计的效果,且无需任何额外数据作为深度估计的监督数据,使得对单视角彩色图像的深度估计更为简便和准确。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
图1为本发明实施例提供的一种单目深度估计方法的流程示意图;
图2为本发明实施例提供的一种初始的基础深度网络图;
图3为本发明实施例提供的一个应用于单目深度估计的网络框架图;
图4为本发明实施例提供的一种单目深度估计系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明的说明书和权利要求书及上述附图中的术语“第一”和“第二”等是用于区别不同的对象,而不是用于描述特定的顺序。此外术语“包括”和“具有”以及他们任何变形,意图在于覆盖不排他的包含。例如包含了一系列步骤或单元的过程、方法、系统、产品或设备没有设定于已列出的步骤或单元,而是可包括没有列出的步骤或单元。
在本发明实施例中提供了一种单目深度估计方法,参见图1,该方法包括:
s101、根据初始基础深度估计网络,获取单视角彩色图像的初始深度图。
在本发明实施例中初始基础深度估计网络包括两部分,一个是深度估计网络,一个是姿态估计网络,该姿态估计网络采取直接视觉里程计方法,通过改进的高斯-牛顿算法迭代解出相机姿态参数,不需要可学习参数。其中,所述步骤s101可以具体包括如下步骤:
s1011、通过所述深度估计网络对所述单视角彩色图像在任一视频帧对应的视频帧图像进行深度估计,获得视频帧深度图;
s1012、通过所述姿态估计网络对所述单视角彩色图像的连续两个视频帧进行测试,获得相机姿态矩阵;
s1013、基于所述相机姿态矩阵,生成所述视频帧图像至目的视图图片的映射关系,其中,所述目的视图图片为所述视频帧图像根据所述相机姿态矩阵和所述视频帧深度图形变获得的图片;
s1014、基于所述映射关系和所述目的视图图片的惩罚项,生成惩罚项公式;
s1015、基于所述惩罚项公式和所述深度估计网络对网络参数进行训练,获得初始深度图。
举例说明,参见图2,图2为本发明实施例提供的一种初始的基础深度网络图。为了进行无监督训练,利用视频中连续的三帧图像进行深度估计的验证。针对中间一个时刻的视频帧is(即第一视频帧图像),深度估计网络对其预测出深度图ds。而针对连续两帧,姿态估计器输出相机姿态矩阵pst,该相机姿态矩阵可以用来描述is到it的投影关系,其中,it为所述第一视频帧图像根据所述相机姿态矩阵和所述第一深度图形变获得的图片。
采用多尺度惩罚项lpr来训练这部分的网络,具体包括多个尺度的基于形变的l1惩罚项以及一个只作用在最大尺度的结构相似性惩罚项。具体的,对于输入的连续三帧视频帧(ii-1,ii,ii+1),具体惩罚项公式为:
其中,
s102、对单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构。
可以采用结构提取网络来获得输入的单视角彩色图像的几何结构即几何结构信息图,用g表示。具体的,该过程包括:
s1021、依据所述预设基础深度估计网络,在所述单视角彩色图像数据集上进行训练,获得卷积层;
s1022、将所述卷积层中最后三层卷积层进行处理,获得特征图;
s1023、对所述特征图进行卷积和激活处理,获得所述单视角彩色图像的几何结构。
其中,激活处理是指通过relu激活项实现的。
s103、依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。
由于生成的几何结构包括了不同的结构特征信息,主要包括三种结构信息,有平面、曲面和物体边界信息,因此可以基于这些结构特征信息对初始深度图进行优化。
在本发明的另一实施例中还包括获得结构特征信息的方法,包括:
获取所述几何结构对应的图像的像素值,并依据所述像素值计算获得域变换系数;
依据所述域变换系数与预设系数阈值,确定所述几何结构中的结构特征信息。
对于几何结构对应的图像g中的像素值表示为gij,利用负指数来归一化到[0,1]的范围,作为域变换系数,即:
并通过设置预设系数阈值τ1和τ2,来确定不同的结构特征信息,具体的:
ωij>τ1,为平面区域,在此区域深度是均匀变化的;τ2≤ωij≤τ1,为曲面区域,深度梯度不平滑;ωij<τ2,为边界区域,深度变化剧烈。本发明实施例提出的结构图和普通的边界图相比,包含了更多的曲面区域。
然后,根据结构特征信息对初始深度图进行优化,为了得到更加准确的结果。在本发明实施例中通过改进的域变换滤波器来优化基础深度网络的初始预测结果。
原始域变换滤波器公式为:
yi=(1-ωi)xi+ωiyi-1,
其中xi是一个长度为n的一维信号,yi是输出信号,i=2,…,n,并且y1=x1。ωi是控制信息传播的权重,ωi小的时候,就不进行信息传播。在分割任务中,域变换滤波被当作一个用来无监督保留边缘的滤波器,循环地平滑输出图像。但是深度估计任务和分割任务有很大不同,具体来说,分割任务在一个平面中的标签是一样的;但是深度估计中,平面上的深度值是会均匀变化的,并不会相同。所以,不能直接将原始的域变换滤波直接用在深度估计任务上。
因此,在本发明实施例中利用二阶导数来改进原始域变换滤波器,改进后的域变换公式为:
其中δyi-1=yi-1-yi-2。对于二维信号,域滤波公式可以直接进行拓展,具体分为四步,即从左到右,从右到左,从上到下,以及从下到上,都分别采用一维的域变换对图像滤波。而对于图中每一个像素对应的ωij,定义见结构生成模块部分。该滤波器的目的是保持平面区域的平滑,并且在物体边缘处停止信号传播,保持图像边缘的细节。我们采用对图像滤波两次来得到图像远距离的依赖信息。改进的二阶域变换滤波器可以更好地融合结构和深度,比原始的域变换滤波器效果更好。
并且,因为边界和曲面部分结构复杂,深度更难预测,在本发明实施例中还提出了使用注意力机制,使得模型更关注比较难学习的区域。
其中,x是深度估计网络中的特征层。注意力机制理论上可以加在网络中每一个卷积层,但会引入更多的内存和计算消耗。为了平衡算法性能和计算存储代价,在深度估计网络中的最后一个特征层加了注意力机制,这样可以直接影响到输出结果。注意力机制能够加强网络在边界和曲面区域的特征表示,最终改善预测结果。
为了能够使得深度估计结果更准确,在本发明实施例中还包括:
确定与所述结构特征信息对应的惩罚项,并基于所述惩罚项对所述结构特征信息进行训练;
依据训练后的结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。
参见图3,为本发明实施例提供的一个应用于单目深度估计的网络框架图。为了无监督训练,输入视频中的连续三帧,输出的是经过域变换优化的深度预测图。为了更好地训练,提出了以下的惩罚函数。
首先,在使用域变换对结构和深度进行融合后,可以得到一个新的深度图
lsg=lpr+λ1lst,
其中,λ1是超参数,lst用以下公式表示:
lst是用来防止出现所有ωij≡0情况的约束项,如果没有这一项约束,网络就会倾向于将所有结构图中所有像素都预测为边缘。
总体优化时,为了更好地利用生成的结构特征信息来优化深度估计,针对图像中不同的结构,即根据其所表达的几何表征特征(平面、曲面、边界),设计了不同的惩罚项。
对于平面区域,采用如下的平滑惩罚项目:
其中1(c1)在平面处值为1,其余为0。dx(p)和dy(p)分别为深度图中像素p的水平和竖直梯度。该惩罚项使得预测深度图中平面部分更加光滑。
对于曲面区域,使用二阶平滑惩罚项,使得预测深度梯度变化更加平滑。
具体公式为:
其中1(c2)在曲面处值为1,其余为0。dxx,dyy和dxy分别是二阶导数。这个约束项可以使得曲面部分的梯度变化不要太剧烈。
对于边界区域,采取保留边界的惩罚项,使得深度图中边界更加明显:
其中1(c3)在边界处值为1,其余为0。
最后,整体网络的优化函数为:
lsc=lpr+λ2lps+λ2lcs+λ3lep,
其中λ2和λ3是控制约束项的超参数。
训练时,输入视频帧尺寸为128×416,基础深度网络先用lpr预训练,学习率lr=1×e-4。训练整体网络时,采用两步训练方法,先固定基础深度网络,不使用注意力机制,只用lsg训练结构生成模块,学习率lr=1×e-5;然后加上注意力机制,用lsc重新训练基础深度网络,lr=1×e-5。对于超参数,设定λ1=0.1,λ2=0.01,λ3=0.05,τ1=0.8,τ2=0.2。
在三个公共数据集上的结果达到了目前的无监督深度估计的最好结果,证明了方法的有效性。
本发明提供了一种单目深度估计方法,根据初始基础深度估计网络,获取单视角彩色图像的初始深度图;对所述单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构;依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。由于使用了单视角彩色图像的几何结构对初始深度图进行了优化,可以增强深度估计的效果,且无需任何额外数据作为深度估计的监督数据,使得对单视角彩色图像的深度估计更为简便和准确。
并且在本发明实施例中提出了一个新的二阶于变换滤波器,来更好地提取结构信息,充分利用图片中像素的相关依赖关系;同时,使用注意力机制,使网络更加关注难以预测的部分,另外,针对不同的结构采用不同的惩罚项,来指导网络更好地估计深度。该网络可以无监督地训练,进行深度估计。
对应的,在本发明的另一实施例中还提供了一种单目深度估计系统,参见图4,该系统包括:
初始化单元10,用于根据初始基础深度估计网络,获取单视角彩色图像的初始深度图;
提取单元20,用于对所述单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构;
优化单元30,用于依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。
本发明提供了一种单目深度估计方法及系统,初始化单元根据初始基础深度估计网络,获取单视角彩色图像的初始深度图;提取单元对所述单视角彩色图像进行结构提取,获得所述单视角彩色图像的几何结构;优化单元依据所述几何结构对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图。由于使用了单视角彩色图像的几何结构对初始深度图进行了优化,可以增强深度估计的效果,且无需任何额外数据作为深度估计的监督数据,使得对单视角彩色图像的深度估计更为简便和准确。
在上述实施例的基础上,所述初始化单元包括:
估计子单元,用于通过所述深度估计网络对所述单视角彩色图像在任一视频帧对应的视频帧图像进行深度估计,获得视频帧深度图;
测试子单元,用于通过所述姿态估计网络对所述单视角彩色图像的连续两个视频帧进行测试,获得相机姿态矩阵;
第一生成子单元,用于基于所述相机姿态矩阵,生成所述视频帧图像至目的视图图片的映射关系,其中,所述目的视图图片为所述视频帧图像根据所述相机姿态矩阵和所述视频帧深度图形变获得的图片;
第二生成子单元,用于基于所述映射关系和所述目的视图图片的惩罚项,生成惩罚项公式;
第一训练子单元,用于基于所述惩罚项公式和所述深度估计网络对网络参数进行训练,获得初始深度图。
在上述实施例的基础上,所述提取单元包括:
第二训练子单元,用于依据所述预设基础深度估计网络,在所述单视角彩色图像数据集上进行训练,获得卷积层;
第一处理子单元,用于将所述卷积层中最后三层卷积层进行处理,获得特征图;
第二处理子单元,用于对所述特征图进行卷积和激活处理,获得所述单视角彩色图像的几何结构。
在上述实施例的基础上,该系统还包括:
信息获取单元,用于获取所述几何结构的结构特征信息,所述优化单元具体用于依据所述结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图,其中,所述优化单元包括:
像素获取子单元,用于获取所述几何结构对应的图像的像素值,并依据所述像素值计算获得域变换系数;
信息确定子单元,用于依据所述域变换系数与预设系数阈值,确定所述几何结构中的结构特征信息;
第四训练子单元,用于确定与所述结构特征信息对应的惩罚项,并基于所述惩罚项对所述结构特征信息进行训练;
优化子单元,用于依据训练后的结构特征信息对所述初始深度图进行优化,获得所述单视角彩色图像的深度估计图;
所述优化单元还包括:
滤波器优化子单元,用于基于所述域变换系数,对原始域变换滤波器进行优化,获得改进后的域变换公式,使得依据所述域变换公式对所述结构特征信息进行图像滤波处理。
本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处参见方法部分说明即可。
对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
- 还没有人留言评论。精彩留言会获得点赞!