一种面向能谱CT的投影域数据噪声去除方法与流程
本发明涉及能谱ct领域,尤其是针对低剂量条件下,用于能谱ct图像重建的投影域数据存在较多噪声,利用高低能信息互补去除投影域噪声的方法。
背景技术:
目前,ct成像是最广泛应用的医学影像技术之一,ct以它高分辨率、高灵敏度、多层次等优势,发挥了有别于传统x线检查的巨大作用。ct成像技术己成为现代医学和工业重要的检测与诊断手段,且起着越来越重要的作用。随着ct采样技术的日益发展,能谱ct成像的概念于1975年被提出。相较于传统的单能ct能够提供病人的解剖结构信息以及组织的化学成分信息。因为物体对x射线的衰减取决于射线的能量大小,不同能量的采样会提供更多的物体内部信息。然而,ct检查过程中高的辐射剂量会导致相关癌症风险增大这一事实越来越受到关注。降低辐射剂量的同时保证最终重建得到高质量的ct图像已经成为医学成像领域的重点和难点。由于剂量的降低会导致获得的数据当中噪声加重,目前提出了许多方法来改善低剂量ct图像的质量。这些方法通常分为三类:对投影域数据滤波,迭代重建和图像后处理。例如采用双边滤波的方式处理投影域数据,之后采用滤波反投影进行重建;通过在目标图像的先验信息辅助下,基于字典学习的迭代去噪方法以及使用深度学习技术对低剂量条件下重建的图像进行后处理实现去噪等方法,本发明属于对投影域数据又称正弦图数据进行处理这一类。
为了在低剂量条件下重建出高质量的ct图像,对能谱ct在不同能量段下提供的信息进行融合已经成为趋势,尤其是对于投影直接获得的正弦数据进行处理,可以避免在之后重建过程中所带来的解析误差,从而重建出更加真实的图像。
技术实现要素:
本发明的目的是为了克服现有技术中的不足,提供一种采用交替迭代方式进行低剂量能谱ct投影域数据噪声去除的方法,采用高低能投影数据信息融合去噪可以避免单纯进行正弦图滤波所造成的有效信息丢失问题,进而为之后图像重建提供更准确的输入数据,实现低剂量条件下的高质量ct图像重建,推动精准医疗的进一步发展。本发明将高能和低能条件下的投影域数据通过基于交替迭代方式构建的神经网络进行信息互补,实现低剂量条件下生成高质量的投影域数据。
本发明的目的是通过以下技术方案实现的:
一种面向能谱ct的投影域数据噪声去除方法,包括以下步骤:
(1)构建用于表示投影域数据噪声分布的加权最小二乘法噪声模型矩阵p;
(2)使用交替迭代法构建去除投影域噪声的去噪模型;
(3)采用梯度下降法搭建神经网络并制作数据集对去噪模型进行优化。
进一步的,步骤(1)具体包括:
参照公式(1),其中,x1代表能谱ct获得的含噪声的投影域数据低能分量矩阵,x2代表能谱ct获得的含噪声的投影域数据高能分量矩阵,y代表无噪声的投影域数据高能分量矩阵,σ-1表示对矩阵元素进行方差运算的计算法则;
由于ct的投影域图像数据可进行稀疏表示,因此采用离散的小波变换构建正则化矩阵,令dl、hk代表离散小波变换系数,l和k表示滤波次数,取值由x1矩阵和x2矩阵的阶数决定;l、k表示变量,最小值为1,最大值分别为l和k;g为正则化法则,使用但不限于
进一步的,步骤(2)具体包括:
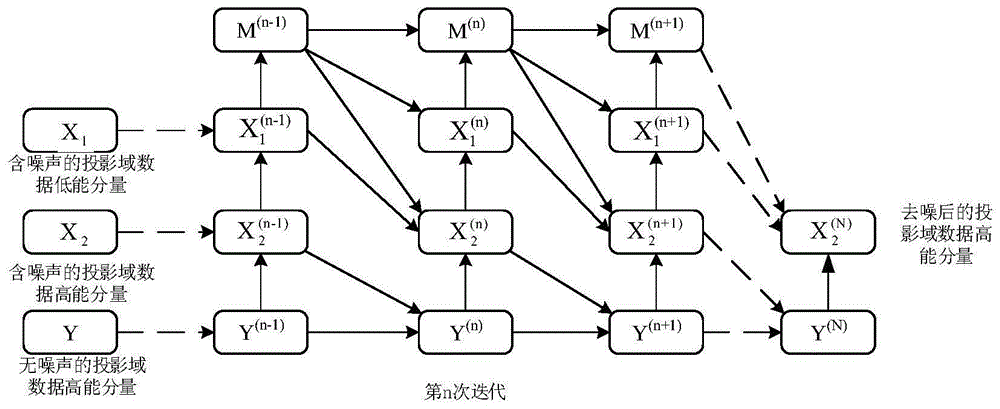
采用增广拉格朗日优化方程实现投影域数据高能分量矩阵和投影域数据低能分量矩阵的交替迭代,整个迭代的过程如公式(3)所示,其中m(n)表示第n次迭代过程中高能投影域数据矩阵和低能投影域数据矩阵的交互矩阵;
进一步的,步骤(3)具体包括以下步骤:
(301)对于神经网络的输入层,y(n)使用无噪声的投影域数据高能分量矩阵作为输入,x1(n)的初始输入为含噪声的投影域数据低能分量矩阵,
(302)进行数据集准备,在仿真环境下采用高能量的x射线对人体模型进行照射,由于理想环境不存在噪声,所以在探测器产生的投影域数据矩阵即为无噪声的投影域数据高能分量矩阵y,将其作为网络训练的标签。将无噪声的矩阵通过软件加入高斯噪声,从而生成含噪声的投影域数据高能分量矩阵x2;同样的方法采用能量较低的x射线对体模进行照射并通过软件加噪声后得到含噪声的投影域数据低能分量矩阵x1。
(303)进行数据集标定,包括含噪声的投影域数据低能分量矩阵x1、含噪声的投影域数据高能分量矩阵x2、以及无噪声的投影域数据高能分量矩阵y;将同一体模断层含噪声的投影域高低能分量矩阵及无噪声的数据高能分量矩阵进行匹配,作为一组数据;通过对体模进行不同位置的切片来生成至少150组数据集;其中100组用来训练,剩下的50组进行测试。
(304)对神经网络进行训练,随机选择步骤(303)中标定好的用于训练的100组数据集对神经网络进行训练,依照公式(3)的迭代方案,对x1(n)、
(305)测试神经网络训练效果;利用步骤(303)中用作测试的50组数据集进行测试,将含噪声的投影域数据高能分量矩阵和低能分量矩阵输入神经网络,利用神经网络中数据评价标准检查神经网络的训练效果,若合格则完成训练,若不合格,重复步骤(304)直到合格,完成神经网络的训练,得到优化后的去噪模型;
(306)将能谱ct探测器探测到的数据经过模数转化电路得到投影域数据的高能分量矩阵和低能分量矩阵,然后输入到优化后的去噪模型当中,在输出端得到去噪后的投影域数据高能分量矩阵。
与现有技术相比,本发明的技术方案所带来的有益效果是:
本发明方法,首先引入带惩罚项的加权最小二乘法框架对能谱ct投影域数据噪声进行了描述,由于低剂量ct投影数据的噪声特性可以近似为具有非线性信号相关方差的高斯分布,因此该框架可以更加准确提取出投影域数据当中的噪声,之后通过交替迭代的方法将能谱ct中所获得的投影域数据高能分量以及投影域数据低能分量在神经网络中进行信息互补去噪,由于迭代过程是交替方向进行的,可以很好的在投影域数据高能分量和投影域数据低能分量之间进行信息共享同时避免去噪过程中所造成有效信息丢失问题,进而保留更多的细节信息。同时使用神经网络对去噪模型进行优化,可以利用神经网络强大的特征提取功能提取投影域数据中有用信息,在速度和准确率上都有很大的提升,从而为后续的图像重建提供高质量输入数据,实现在低剂量条件下重建出高质量的ct图像。
附图说明
图1是交替迭代结构的示意图。
图2是本发明方法的流程示意图。
具体实施方式
以下结合附图和具体实施例对本发明作进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
本发明提出了一种面向低剂量能谱ct投影域数据去噪的新方法,主要利用能谱ct高低能x射线条件下投影域数据高低能分量矩阵之间的信息互补去噪。首先由于低剂量ct投影数据的噪声特性可以近似为具有非线性信号相关方差的高斯分布,而带惩罚项的加权最小二乘法框架可以很好的表示这一特性,所以对能谱ct所获得的投影域数据高能分量矩阵和投影域数据低能分量矩阵建立相应的加权最小二乘法框架,由于ct的投影域图像数据满足稀疏原理,所以采用离散的小波变换来构建正则化项,之后通过应用增广的拉格朗日方程来构建噪声去除模型,利用交替迭代的方式使投影域数据高低能分量矩阵在迭代的过程中实现信息互补,后采用梯度下降法来构建相应的神经网络对去噪模型进行优化。具体的实施方案如下:
step1:构建用于表示投影域数据噪声分布的加权最小二乘法噪声模型矩阵p。如公式(1)所示,其中,x1代表能谱ct获得的含噪声的投影域数据低能分量矩阵,矩阵的大小一般为512×512。x2代表能谱ct获得的含噪声的投影域数据高能分量矩阵,矩阵的大小一般为512×512,y代表无噪声的投影域数据高能分量矩阵,矩阵大小一般为512×512,σ-1表示对矩阵元素进行方差运算的计算法则。
由于ct的投影域图像数据可以进行稀疏表示,所以采用离散的小波变换来构建正则化矩阵,令dl、hk代表离散小波变换系数,l和k表示滤波次数,取值由x1矩阵和x2矩阵的阶数决定,均为512。g为正则化法则,使用
step2:使用交替迭代法构建去除投影域噪声的去噪模型。采用增广拉格朗日优化方程实现投影域数据高能分量矩阵和投影域数据低能分量矩阵的交替迭代,整个迭代的过程如公式(3)所示,其中m(n)表示第n次迭代过程中投影域数据高能分量矩阵和投影域数据低能分量矩阵的交互矩阵,大小为512×512。
step3:构建神经网络实现对去噪模型的优化,对于神经网络的输入层,y(n)使用理想的投影域数据高能分量矩阵作为输入,x1(n)的初始输入为含噪声的投影域数据低能分量矩阵,
step4:进行数据集准备,在使用matlab工具仿真采用高能量(120kev)的x射线对人体模型(可使用matlab自带模型)进行照射,得到x射线经过人体后在探测器产生的无噪声的投影域数据高能分量矩阵y,作为神经网络的标签。之后可以将无噪声的矩阵通过软件加入高斯噪声,从而生成含噪声的投影域数据高能分量矩阵x2。同样的方法采用能量较低(40kev)的x射线对体模进行照射并通过软件加噪声后得到含噪声的投影域数据低能分量矩阵x2。
step5:进行数据集标定,包括含噪声的投影域数据低能分量矩阵x1、含噪声的投影域数据高能分量矩阵x2、以及不含噪声的高能投影域数据矩阵y。将同一体模断层含噪声的高低能数据及不含噪声的高能数据进行匹配,作为一组数据;通过对体模进行不同位置的切片来生成至少150组数据集;其中100组用来训练,剩下的50组进行测试
step6:对神经网络模型进行训练,随机选择step5当中标定好的100组训练数据集对神经网络进行训练,依照公式(3)的迭代方案,对x1(n)、
step7:测试神经网络训练效果。利用step5中用于测试的50组训练集进行测试,将含噪声的投影域数据高能分量矩阵和投影域数据低能分量矩阵输入神经网络,利用神经网络中数据评价标准检查神经网络训练效果,若合格则完成训练,若不合格,重复step6直到合格,完成神经网络训练,得到优化后的去噪模型。
step8:将能谱ct探测器探测到的投影域数据的高能分量矩阵和低能分量矩阵输入到使用神经网络优化后的去噪模型中,在输出端得到去噪后的投影域数据高能分量矩阵。
通过上述步骤后,就可以得到一个用于能谱ct投影域数据去噪的网络模型,输入为低剂量条件下带噪声的投影域数据,输出接近无噪声的投影域数据,进而为之后的图像重建提供高质量的输入数据。
本实施例中数据集使用体模生成软件生成,首先用40kev或者更低能量的x射线进行扫描,得到但不限于150张投影域数据图代表低能投影域数据,同样用120kev或者更高能量的x射线扫描得到但不限于150张高能投影域数据图,之后在matlab中加入噪声。最后将其中100张或者更多带噪声的高低能图片分别作为输入,100张或者更多不带噪声的高能图片作为标签。用剩余的50张或者更多作为测试集测试神经网络效果,之后进行神经网络训练,将100组或者更多训练集数据随机的输入神经网络中,观察损失函数是否可以收敛到最小值,如果不收敛,则改变神经网络中的超参数λ、
本发明并不限于上文描述的实施方式。以上对具体实施方式的描述旨在描述和说明本发明的技术方案,上述的具体实施方式仅仅是示意性的,并不是限制性的。在不脱离本发明宗旨和权利要求所保护的范围情况下,本领域的普通技术人员在本发明的启示下还可做出很多形式的具体变换,这些均属于本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!