一种面向K12编程的Python程序代码快速搜索方法与流程
本发明属于计算机技术领域,具体是一种面向k12编程的python程序代码快速搜索技术。
背景技术:
随着互联网时代的发展,越来越多的人开始接触计算机技术,越来越多的人开始接受计算机基础教育,其中就包括计算机编程技术,为解决k12编程面临的快速查找相似代码、通过阅读代码进行编程学习的特殊问题,目前已有的代码检索技术大多基于字符级别的相似度匹配,忽略了代码本身的结构信息以及变量名、函数名带来的影响,故能够对代码进行高效准确的检索是一个亟待解决的研究问题。
本发明为解决k12编程面临的快速查找相似代码、通过阅读代码进行编程学习的特殊问题,提供了一种字符串、token串和语法树相结合的python代码快速搜索技术,通过对用户查询代码和库中代码进行词法分析和语法分析,将字面(字符串级)、词法和语法特征相结合,计算查询代码与库中代码的相关度,据此产生检索的排序结果。
技术实现要素:
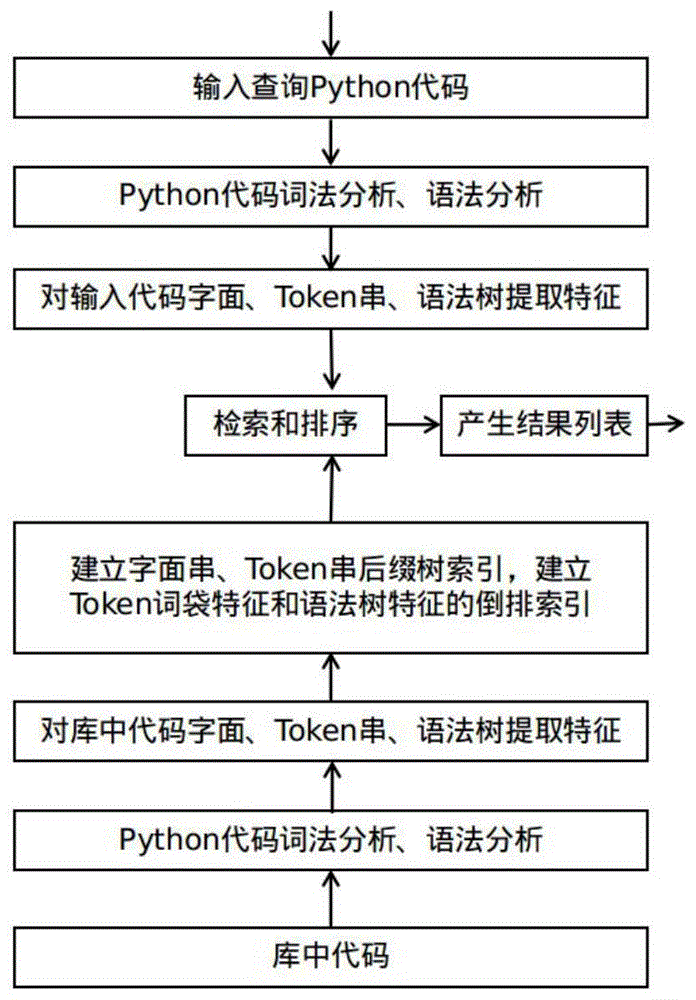
为解决k12编程面临的快速查找相似代码、通过阅读代码进行编程学习的特殊问题,提供了一种代码相似度计算方法,该方法结合了三个层面的代码相似度,即字符串级别的精确匹配、token串级别的相似度匹配、代码语法树级别的相似度匹配。为提升查询效率,需定期更新数据库里已有代码的索引,每次更新由以下几个预处理步骤得到代码的特征并依据特征构建索引:
步骤1:考虑字符串级别的精确匹配,对原始代码仅做简单的预处理,得到由代码原始字符构成的字符串。
步骤2:考虑token串级别的相似性匹配,对代码进行词法分析,得到原始代码对应的token字符串。
步骤3:考虑语法树级别的相似性匹配,对代码进行语法分析,得到每段代码对应的语法树,再对语法树进行特征提取,得到每个语法树对应的特征串。
步骤4:将代码原始字符串、token字符串、语法树特征字符串结合起来,使用elasticsearch构建索引。
所述步骤1考虑字符串级别的精确匹配,对原始代码仅做简单的预处理,得到由代码原始字符构成的字符串。该步直接对源代码进行预处理,然后进行字符串的精确匹配即可。预处理过程忽略代码中的注释语句,具体做法如下:将代码中的所有字符,根据人工定义的“符号替换词典”进行替换,并加上“punc_”前缀,所有字母组成的单词加上“char_”前缀,然后用空格隔开组成一个长字符串。
将查询代码和数据库中代码转换之后的字符串进行精确匹配,相同则返回,不同则不返回。
所述步骤2考虑token串级别的相似性匹配,对代码进行词法分析,得到原始代码对应的token字符串。该步重要的是对代码进行词法分析。词法分析(lexicalanalysis)是计算机科学中将字符序列转换为标记(token)序列的过程,对源代码进行词法分析,旨在忽略代码中变量名、数值大小这类区别。进行词法分析的程序或者函数叫作词法分析器(lexicalanalyzer,简称lexer)。使用python内置的词法分析器,直接使用指令:python3-mtokenize-e(+filename)对源代码进行词法分析,其中filename为代码文件所在路径。然后对词法分析结果进行如下处理:
(1)首先同样是将代码中的所有字符,根据人工定义的“符号替换词典”进行替换,并加上“punc_”前缀;
(2)然后将代码中的关键字统一加上“key_”前缀;
(3)然后将词法分析中得到的token标识符替换为较短的唯一标识符(根据“token替换词典”,目的是使得最终得到的字符串长度较小,例如词法分析将代码中的所有变量名标记为“name”,用“ao”缩写来进行表示);
(4)最后,将查询代码和数据库中代码转换之后的字符串进行精确匹配,相同则返回,不同则不返回。
所述步骤3考虑语法树级别的相似性匹配,对代码进行语法分析,得到每段代码对应的语法树,再对语法树进行特征提取,得到每个语法树对应的特征串。语法分析器基于特定语言的语法,将token序列(由词法分析器生成)转换成一个抽象语法树。抽象语法树(abstractsyntaxtree,ast),或简称语法树(syntaxtree),是源代码语法结构的一种抽象表示。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。在进行语法分析得到语法树之后,采用如下步骤进行语法树的特征提取,将树的表达转化成为一个字符序列:
(1)先将语法树转换成二叉树,采用左孩子右兄弟的转换方法。
(2)然后对二叉树的所有叶结点进行结点填充,使得每个叶节点都拥有其左孩子和右孩子结点,填充结点的值统一为任意值。
(3)取出转换之后二叉树中的每个两层子树,当做一个特征,将该两层子树结构中的三个结点值用下划线“_”连接起来,作为最终树的字符串表达中的一项。
(4)将该语法树中的所有特征项用空格隔开,作为最终的树的字符串表达。
所以,进一步将判断两段代码的相似性,转化为判断语法树的相似性,最后转化为判断两个字符序列之间的相似性。
所述步骤4考虑将代码原始字符串、token字符串、语法树特征字符串结合起来,使用elasticsearch构建索引。即数据库中的所有代码,都存在以上三种解析方式的索引。实际使用过程中,传来一个查询query,对该查询执行三种解析,得到三种不同的查询串,再用每一种查询串进行elasticsearch的查询,然后将三种查询串搜索的结果进行合并,采取的合并策略是:
(1)原始字符串精确匹配的结果,优先级最高,排在最前面;
(2)词法分析的token串查询的结果,优先级次之,依次排在后面;
(3)语法树的匹配结果,排在字符串结果和词法分析结果的后面。
在合并的过程中,进行去重,即字符串精确匹配的结果,可能也在词法分析串搜索中也会出现,则去除词法分析中的这些返回结果。该搜索结合方式在查询较短代码时,返回的结果中通常是很多精确匹配的结果,以及词法分析串匹配的结果;而针对查询的代码较长时,精确匹配的结果往往很少,此时返回的应该大部分是语法结构的匹配结果。
附图说明
图1为本发明的流程示意图。
图2为样例代码及其对应的抽象语法树。
图3为抽象语法树对应的二叉树。
具体实施方式
本发明为解决k12编程面临的快速查找相似代码、通过阅读代码进行编程学习的特殊问题,提供了一种字符串、token串和语法树相结合的python代码快速搜索技术,通过对用户查询代码和库中代码进行词法分析和语法分析,将字面(字符串级)、词法和语法特征相结合,计算查询代码与库中代码的相关度,据此产生检索的排序结果,整体流程如图1所示。
为解决k12编程面临的快速查找相似代码、通过阅读代码进行编程学习的特殊问题,提供了一种代码相似度计算方法,该方法结合了三个层面的代码相似度,即字符串级别的精确匹配、token串级别的相似度匹配、代码语法树级别的相似度匹配。为提升查询效率,需定期更新数据库里已有代码的索引,每次更新由以下几个预处理步骤得到代码的特征并依据特征构建索引:
步骤1:考虑字符串级别的精确匹配,对原始代码仅做简单的预处理,得到由代码原始字符构成的字符串。
步骤2:考虑token串级别的相似性匹配,对代码进行词法分析,得到原始代码对应的token字符串。
步骤3:考虑语法树级别的相似性匹配,对代码进行语法分析,得到每段代码对应的语法树,再对语法树进行特征提取,得到每个语法树对应的特征串。
步骤4:将代码原始字符串、token字符串、语法树特征字符串结合起来,使用elasticsearch构建索引。
所述步骤1考虑字符串级别的精确匹配,对原始代码做预处理,得到由代码原始字符构成的字符串。该步直接对源代码进行预处理,然后进行字符串的精确匹配即可。预处理过程忽略了代码中的注释语句,具体做法如下:将代码中的所有字符,根据人工定义的“符号替换词典”进行替换,并加上“punc_”前缀,所有字母组成的单词加上“char_”前缀,然后用空格隔开组成一个长字符串。
将查询代码和数据库中代码转换之后的字符串进行精确匹配,相同则返回,不同则不返回。
所述步骤2考虑token串级别的相似性匹配,对代码进行词法分析,得到原始代码对应的token字符串。该步重要的是对代码进行词法分析。词法分析(lexicalanalysis)是计算机科学中将字符序列转换为标记(token)序列的过程,对源代码进行词法分析,旨在忽略代码中变量名、数值大小这类区别。进行词法分析的程序或者函数叫作词法分析器(lexicalanalyzer,简称lexer)。使用python内置的词法分析器,直接使用指令:python3-mtokenize-e(+filename)对源代码进行词法分析,其中filename为代码文件所在路径。然后对词法分析结果进行一些预处理:
(1)首先将代码中的所有字符,根据人工定义的“符号替换词典”进行替换,并加上“punc_”前缀;
(2)然后将代码中的关键字统一加上“key_”前缀;
(3)然后将词法分析中得到的token标识符替换为较短的唯一标识符(根据人工定义的”token替换词典“,目的是使得最终得到的字符串长度较小,例如词法分析将代码中的所有变量名标记为“name”,用“ao”缩写来进行表示)。
(4)最后将查询代码和数据库中代码转换之后的字符串进行精确匹配,相同则返回,不同则不返回。
所述步骤3考虑语法树级别的相似性匹配,对代码进行语法分析,得到每段代码对应的语法树,再对语法树进行特征提取,得到每个语法树对应的特征串。语法分析器基于特定语言的语法,将token序列(由词法分析器生成)转换成一个抽象语法树。抽象语法树(abstractsyntaxtree,ast),或简称语法树(syntaxtree),是源代码语法结构的一种抽象表示,如图2所示,左边为源代码,右边是其对应的抽象语法树。它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。之所以说语法是“抽象”的,是因为这里的语法并不会表示出真实语法中出现的每个细节。比如,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。在进行语法分析得到语法树之后,采用如下方法进行语法树的特征提取,将树的表达转化成为一个字符序列:
(1)先将语法树转换成二叉树,采用左孩子右兄弟的转换方法。
(2)然后对二叉树的所有叶结点进行结点填充,使得每个叶节点都拥有其左孩子和右孩子结点,填充结点的值统一为任意值。
(3)取出转换之后二叉树中的每个两层子树,当做一个特征,将该两层子树结构中的三个结点值用下划线“_”连接起来,作为最终树的字符串表达中的一项。
(4)将该语法树中的所有特征项用空格隔开,作为最终的树的字符串表达。
例如下面这行简单代码:
a=a-b
利用pythonast模块进行语法分析,得到的语法树结构(已经转换为二叉树),如图3所示。
其中的0结点为叶子结点的填充结点,按照上面的特征提取过程中的第3步,进一步得到整个语法树的字符序列为:
module_assign_0assign_name_0name_store_binopstore_0_0binop_name_0name_load_subload_0_0sub_0_namename_load_0load_0_0
其中,该字符序列中的每一项为二叉树中的每个两层子树,将该两层子树结构中的三个结点值用下划线“_”连接起来得到的字符串。然后将所有子项用空格隔开,组成整个语法树的字符序列。
所以,进一步将判断两段代码的相似性,转化为判断语法树的相似性,最后转化为判断两个字符序列之间的相似性。
所述步骤4考虑将代码原始字符串、token字符串、语法树特征字符串结合起来,使用elasticsearch构建索引。即数据库中的所有代码,都存在以上三种解析方式的索引。实际使用过程中,传来一个查询query,对该查询执行三种解析,得到三种不同的查询串,再用每一种查询串进行elasticsearch的查询,然后将三种查询串搜索的结果进行合并,采取的合并策略是:
(1)原始字符串精确匹配的结果,优先级最高,排在最前面;
(2)词法分析的token串查询的结果,优先级次之,依次排在后面;
(3)语法树的匹配结果,排在字符串结果和词法分析结果的后面。
与此同时,在合并的过程中,进行去重,即字符串精确匹配的结果,可能也在词法分析串搜索中也会出现,则去除词法分析中的这些返回结果。该搜索结合方式在查询较短代码时,返回的结果中通常是很多精确匹配的结果,以及词法分析串匹配的结果;而针对查询的代码较长时,精确匹配的结果往往很少,此时返回的应该大部分是语法结构的匹配结果。
以上对本发明实施所提供的一种面向k12编程的python程序代码快速搜索技术进行了详细地介绍,本文对本发明的原理和实施方式进行了阐述,以上具体实施方式的说明只是用于辅助理解本发明的方法及其核心思想。
- 还没有人留言评论。精彩留言会获得点赞!