一种基于大数据分析的石墨烯指纹峰分析方法与流程
本发明涉及大数据分析技术领域,更具体地说,本发明涉及一种基于大数据分析的石墨烯指纹峰分析方法。
背景技术:
作为单独存在的只有一个原子厚度的二维晶体,石墨烯具有非常独特的电性能、导热性能和光学性质,已开始在整流、光探测器、触摸屏等电子和光电子器件中作为透明电极获得广泛地应用。目前,大面积石墨烯的制备技术日臻成熟,特别是采用化学气相沉积(cvd)技术制备的12吋石墨烯薄膜已经见诸报道。在此背景下,石墨烯薄膜质量成为人们关注的重要问题。不同层数的石墨烯电子能级的分布有很大的差异,缺陷造成的散射也会使石墨烯中原本很高的载流子迁移率大大降低。而目前大面积生长的石墨烯很难做到全部是单层且无缺陷,因此对石墨烯质量——包括缺陷的分布和层数(特别是是否为单层)的分布——进行快速准确的测量和分析成为一个迫切的需求。
拉曼光谱是一种有效的对石墨烯质量进行测量的方法。将一束激光照在石墨烯薄膜上,收集其产生的拉曼光谱,通过g峰和2d峰的强度的对比关系可以反映石墨烯的层数——2d峰强于g峰则为单层,反之为多层。此外,通过观察有无d峰可以反映被测区域有无缺陷。尤其是近年来共聚焦拉曼光谱技术的飞速发展,可以通过直径在微米量级的共焦光斑在样品表面扫描,逐点采集完整的拉曼光谱,从而获得上述信息在样品中的分布。随着光学效率的提高,采集一条拉曼光谱的甚至已经可以做到毫秒量级,在有限时间内可以采集成千上万个点的拉曼光谱数据,使得对石墨烯薄膜的层数和缺陷分布进行大面积分析成为可能。
在此背景下,对于这些大量的光谱数据的自动分析成为了一个很大的挑战。人工处理已经变得不可能,而传统的非智能算法则由于样品衬底的荧光背景起伏、背景辐射粒子造成的噪点以及光谱信号整体强度的波动等这些近似随即出现的干扰现象的制约,在处理这些巨量数据时也面临很大困难。针对这一挑战,本发明提出一种在大数据背景下,对石墨烯拉曼特征光谱进行自动识别,完成对石墨烯薄膜质量的自动判别。
技术实现要素:
本发明的一个目的是解决至少上述问题,并提供至少后面将说明的优点。
本发明还有一个目的是提供一种基于大数据分析的石墨烯指纹峰分析方法,首先,基于一定量的石墨烯拉曼光谱的特征峰邻域进行复轨迹分析,并提取特征集,训练用于自动识别的智能算法模型;对新采集的石墨烯拉曼光谱数据,对特征峰邻域进行特征提取,输入智能算法模型中进行自动识别。也就是对大数据背景下,根据石墨烯的拉曼特征光谱进行石墨烯单层/多层,或有无缺陷进行自动识别,提高识别准确率和效率。
为了实现根据本发明的这些目的和其它优点,提供了一种基于大数据分析的石墨烯指纹峰分析方法,包括:
步骤一、采集由石墨烯上产生的拉曼光谱,对其中一条石墨烯拉曼光谱上的q个特征峰邻域中的任意区域进行重新采样m个点;
步骤二、对重采样后的m个点特征峰邻域特征光谱做p个点快速傅立叶变换,以获得光滑曲线,经傅立叶变换得到特征峰邻域复轨迹;
步骤三、对所获得的每一条复轨迹的幅度根据其最大幅度进行归一化,并进行相位调整,强制轨迹起点处相位为0;
步骤四、根据复轨迹的收敛规律,将所述复轨迹从外向内划分为若干周,根据所述复轨迹上划分的周数定义标识特征集,用于后续的大数据分析算法;
步骤五、根据一定数量的已知特征峰样本提取步骤四中定义的识别特征集,并将提取得到的特征作为输入数据,训练智能算法,建立基于大数据的石墨烯拉曼光谱自动识别模型;
步骤六、根据石墨烯拉曼光谱自动识别模型对待识别的石墨烯拉曼光谱进行自动识别,根据识别结果进行缺陷判决和层数判决。
优选的,所述步骤一中,定义石墨烯拉曼特征光谱的3个重点分析区域,即所述特征峰邻域为:
1)d峰邻域:波数1270~1430cm-1
2)g峰邻域:波数1520~1680cm-1
3)2d峰邻域:波数2630~2770cm-1。
优选的,所述步骤二中,30≤m≤60,512≤p≤2048,以波数为横坐标的特征光谱视为以光速进行归一化的频域表达,则其傅立叶变换可视为归一化伪时域表达。
优选的,所述m为40,所述p为1024。
优选的,所述步骤四中,所述标识特征集为:
特征1:前4周的数据点数的均值;
特征2:前4周的数据点数的标准差;
特征3:特征2与特征1的比值;
特征4~27:第1~6周半径的统计值:最大值,最小值,平均值,标准差;
特征28~30:第1周的最大值、最小值、平均值与第2周对应数值的比例;
特征31~33:第2周的最大值、最小值、平均值与第3周对应数值的比例;
特征34~39:第1~3周半径的头尾比例,一周内的不光滑拐点数量。
优选的,所述步骤五中,所述自动识别模型根据特征峰邻域位置分为4个子模型:
a)g峰子模型——区分g峰与无特征峰;
b)2d峰子模型——区分2d峰与无特征峰;
c)d峰子模型——区分d峰与无特征峰;
d)噪点子模型——区分有无噪点。
优选的,各x峰子模型的构建方法为:
步骤七、通过人工判断的方式,选取n个存在x峰的x峰邻域的样本,x峰为g峰、d峰和2d峰中的一种,n≥1000;
步骤八、在石墨烯拉曼光谱的g峰邻域、2d峰邻域、d峰邻域之外的任意位置,选取与x峰邻域宽度相等且不存在噪点的n个背景样本;
步骤九、对n个x峰邻域样本和n个背景样本分别提取各样本的标识特征集中的39个特征;
步骤十、对每个特征,对n个x峰邻域样本的特征值和n个背景样本进行线性归一化,至[0,1]区间;
步骤十一、将归一化的特征值集合作为训练集,输入到初始机器学习模型中,进行训练,得到x峰子模型。
优选的,所述步骤十一中,初始机器学习模型可以是svm,人工神经网络,knn,随机森林中的一种。
优选的,所述步骤六中,对待识别的石墨烯拉曼光谱进行自动识别方法为:
步骤十二、将待识别的每一条光谱均提取d峰邻域、g峰邻域和2d峰邻域的光谱数据,并按照步骤一中的方法进行重采样至40点;
步骤十三、对步骤十二中重采样后的数据,按照所述识别特征集提取得到39个特征;
步骤十四、将前一步所提取的特征,输入到其对应的子模型中进行识别,判断对应特征峰是否存在;
步骤十五、当需要识别去除噪点时,对待识别的每一条光谱,从波数1000cm-1起,按照宽度60cm-1的光谱窗,以每步窗移30cm-1进行扫描,每步获取的光谱片段均按照所述识别特征集提取得到39个特征,并输入到噪点子模型中进行识别,判断是否存在噪点。
优选的,所述步骤六中,根据识别结果进行缺陷判决和层数判决的方法为:
当g峰、2d峰同时存在时,判定为该位置存在石墨烯;
对存在石墨烯的位置进行如下判决:
缺陷判决:如果d峰存在,则判定为有缺陷,否则为无缺陷;
层数判决:如果g峰幅度小于2d峰,则判定为单层,否则为多层。
本发明至少包括以下有益效果:
1、本发明通过大数据分析,对石墨烯拉曼特征光谱进行自动识别,完成对石墨烯薄膜质量的自动判别,提高了识别效率;
2、对石墨烯单层/多层的识别准确率高;
3、对石墨烯有无缺陷进行自动识别,识别准确性高;
4、本发明的分析方法抗干扰能力强,适用性广。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
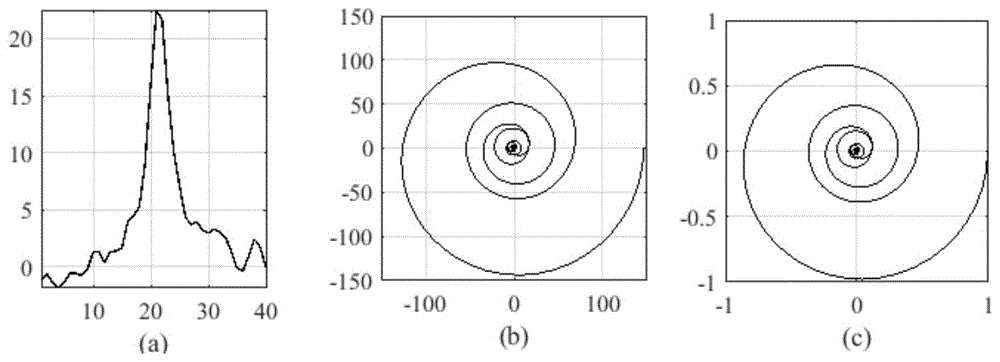
图1为一条特征光谱的g峰示例图,(a)g峰特征邻域重采样波形(b)复轨迹(c)复轨迹归一化示意图;
图2为g峰波形示意图,(a)光谱波形(b)复轨迹;
图3为2d峰波形示意图,(a)光谱波形(b)复轨迹;
图4为d峰波形示意图,(a)光谱波形(b)复轨迹;
图5为噪点波形示意图,(a)光谱波形(b)复轨迹;
图6为无特征峰情况波形示意图,(a)光谱波形(b)复轨迹;
图7为复轨迹按周分解示意图,(a)第1周(b)第2周(c)第3周(d)第4周;
图8为witec设备对层数识别结果,灰色:多层;黑色:单层;
图9为witec设备对有无缺陷的识别结果,黑色:无缺陷;灰色:有缺陷;
图10为witec设备判别出的g峰复轨迹集合;
图11为witec设备判别出的2d峰复轨迹集合;
图12为witec设备判别出的缺陷峰复轨迹集合;
图13为witec设备判别出的噪点复轨迹集合;
图14为witec设备判别出的无特征峰的情况(背景)的复轨迹集合。
具体实施方式
下面结合附图对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不配出一个或多个其它元件或其组合的存在或添加。
如图1-14所示,本发明提供了一种基于大数据分析的石墨烯指纹峰分析方法,包括以下步骤:
步骤一、定义石墨烯拉曼特征光谱的3个重点分析区域,即所述特征峰邻域为:
1)d峰邻域:波数1270~1430cm-1
2)g峰邻域:波数1520~1680cm-1
3)2d峰邻域:波数2630~2770cm-1。
采集由石墨烯上产生的拉曼光谱,对其中一条石墨烯拉曼光谱上的上述3个特征峰邻域中的任意区域进行重新采样40个点;重采样的目的为避免不同设备在光谱采集时使用的分辨率不同造成的影响。
采样成40点,是因为不同品牌、型号的设备,在不同参数设置下进行采集的时候,每个峰采出的样点数不一致,而且差别很大。规定以相同点数进行重新采样,可以避免由于设备的差异造成的问题,使训练所得的模型具有更高的通用型。采样成40点,用1024点的傅立叶变换,是经过实验找到的效果最好的参数。
步骤二、对重采样后的40个点特征峰邻域特征光谱做1024个点快速傅立叶变换,以获得光滑曲线,经傅立叶变换得到特征峰邻域复轨迹;实际上,傅立叶变换的点数明显高于采样点数就可以获得光滑复轨迹,采样点在30到60之间都可以,傅立叶变换点数512到2048也可以。以波数为横坐标的特征光谱视为以光速进行归一化的频域表达,则其傅立叶变换可视为(归一化)伪时域表达。变换结果定义为特征峰邻域复轨迹。由于复轨迹的对称性,复轨迹仅保留前一半用于分析。
步骤三、对所获得的每一条复轨迹的幅度根据其最大幅度进行归一化,并进行相位调整,强制轨迹起点处相位为0;以一条特征光谱的g峰示例,波形如图1所示,其中(a)g峰特征邻域重采样波形(b)复轨迹(c)复轨迹归一化。
各不同的特征峰,以及不存在特征峰,或存在噪点的情况下,复轨迹特性表现出明显差异,其中:
g峰:g峰为波数在1600cm-1附近的石墨烯拉曼光谱指纹峰,其典型波形与复轨迹如图2所示,g峰(a)光谱波形,(b)复轨迹。复轨迹起点位于0相位半径最大处,顺时针逐步向内收敛,最终收敛于复平面原点附近。
2d峰:2d峰为波数在2700cm-1附近的石墨烯拉曼光谱指纹峰,其典型波形与复轨迹如图3所示,2d峰(a)光谱波形,(b)复轨迹。2d峰较g峰稍宽,复轨迹起点位于0相位半径最大处,顺时针迅速收敛,一般在第2周即收敛至复平面原点附近。
d峰:d峰位于石墨烯拉曼光谱的波数1350cm-1附近,d峰的存在提示石墨烯缺陷,其光谱波形与复轨迹如图4所示,d峰(a)光谱波形,(b)复轨迹。d峰的波形形状与g峰、2d峰相比,较不规则。复轨迹起点位于0相位半径最大处,顺时针逐步收敛,收敛速度介于g峰与2d峰之间。
突发噪点:石墨烯拉曼光谱中的突发噪点表现为很窄的高脉冲,出现位置不固定,其光谱波形与复轨迹如图5所示,噪点(a)光谱波形,(b)复轨迹。噪点复轨迹起点位于0相位半径最大处,顺时针逐步收敛,收敛速度比各特征峰均慢,收敛过程较均匀,最终收敛于复平面原点附近。
无特征峰或噪点存在时:此时石墨烯拉曼光谱波形表现为类似白噪声波形,其光谱波形与复轨迹如图6所示,无特征峰的情况(a)光谱波形,(b)复轨迹。其复轨迹起点一般位于半径较大处,但不一定位于半径最大位置,以顺时针方向,整体表现为收敛趋势,但其过程中会有向外扩张的过程,曲线较有特征峰的情况更为杂乱,缺少规律性。
步骤四、根据复轨迹的收敛规律,将所述复轨迹从外向内划分为若干周,第1,2,…周,如图7所示,复轨迹按周分解(a)第1周,(b)第2周,(c)第3周,(d)第4周,根据所述复轨迹上划分的周数定义标识特征集,用于后续的大数据分析算法。
所述标识特征集为:
特征1:前4周的数据点数的均值;
特征2:前4周的数据点数的标准差;
特征3:特征2与特征1的比值;
特征4~27:第1~6周半径的统计值:最大值,最小值,平均值,标准差;
特征28~30:第1周的最大值、最小值、平均值与第2周对应数值的比例;
特征31~33:第2周的最大值、最小值、平均值与第3周对应数值的比例;
特征34~39:第1~3周半径的头尾比例,一周内的不光滑拐点数量。
确定39个特征是根据几种不同的情况(背景,特征峰等)逐个提出的、能够体现它们之间的差别的参数,具体是根据先验知识定义的特征参数集,逐个特征进行定义,例如,情感语音识别的特征,有个国际会议叫interspeech,曾经在不同年份组织的竞赛里推出过参考特征集,特征的个数2003年版本是384个,2019年在更广泛的应用的竞赛里推出的参考特征集有6373个特征。
步骤五、根据一定数量的已知特征峰样本提取步骤四中定义的识别特征集,并将提取得到的特征作为输入数据,训练智能算法,建立基于大数据的石墨烯拉曼光谱自动识别模型。
所述自动识别模型根据特征峰邻域位置分为4个子模型:
a)g峰子模型——区分g峰与无特征峰;
b)2d峰子模型——区分2d峰与无特征峰;
c)d峰子模型——区分d峰与无特征峰;
d)噪点子模型——区分有无噪点。
步骤六、根据石墨烯拉曼光谱自动识别模型对待识别的石墨烯拉曼光谱进行自动识别,根据识别结果进行缺陷判决和层数判决。
所述步骤五中,各子模型的构建方法为(以g峰子模型为例):
步骤七、通过人工判断的方式,选取n个存在g峰的g峰邻域的样本,为使模型训练准确,样本数量不宜过少,应选取为n≥1000;
步骤八、在石墨烯拉曼光谱的g峰邻域、2d峰邻域、d峰邻域之外的任意位置,选取与g峰邻域宽度相等且不存在噪点的n个背景样本;
步骤九、对n个g峰邻域样本和n个背景样本分别提取各样本的39个特征;
步骤十、对每个特征,对n个g峰邻域样本的特征值和n个背景样本进行线性归一化,至[0,1]区间;
步骤十一、将归一化的特征值集合作为训练集,输入到初始机器学习模型中,进行训练,得到g峰子模型。
所述步骤十一中,任何有监督学习类的机器学习模型均可用于石墨烯拉曼光谱指纹峰的大数据自动分析,因此本发明中,初始机器学习模型选取的是svm,人工神经网络,knn,随机森林中的一种。
噪点子模型的构建方法为:
如果是训练模型用,则训练样本通过手工筛选的方法获得。如果用训练好的模型来判断实际光谱中是否含有噪点,则用扫描的方法,即从光谱的最低端开始每若干宽度选一段,提取特征之后放到训练好的模型中判断是否含有噪点,然后向后平移一段重新判断,如步骤十五中描述的过程。
上述技术方案中,所述步骤六中,对待识别的石墨烯拉曼光谱进行自动识别方法为:
步骤十二、将待识别的每一条光谱均提取d峰邻域、g峰邻域和2d峰邻域的光谱数据,并按照步骤一中的方法进行重采样至40点;
步骤十三、对步骤十二中重采样后的数据,按照所述识别特征集提取得到39个特征;
步骤十四、将前一步所提取的特征,输入到其对应的子模型中进行识别,判断对应特征峰是否存在;
步骤十五、当需要识别去除噪点时,对待识别的每一条光谱,从波数1000cm-1起,按照宽度60cm-1的光谱窗,以每步窗移30cm-1进行扫描,每步获取的光谱片段均按照所述识别特征集提取得到39个特征,并输入到噪点子模型中进行识别,判断是否存在噪点。
模型训练中使用svm方法为例时,得到各子模型的识别率为:
g峰子模型:99.96%;
2d峰子模型:100%;
d峰子模型:100%;
噪点子模型:100%。
上述技术方案中,所述步骤六中,根据识别结果进行缺陷判决和层数判决的方法为:
当g峰、2d峰同时存在时,判定为该位置存在石墨烯;
对存在石墨烯的位置进行如下判决:
缺陷判决:如果d峰存在,则判定为有缺陷,否则为无缺陷;
层数判决:如果g峰幅度小于2d峰,则判定为单层,否则为多层。
具体的,先用经过人工判断的一定数量的样本提取特征,按照步骤五中各子模型的构建方法进行模型训练,这一步骤会得到训练好的模型。然后,对待判断样本利用训练好的模型进行判断。具体做法是对未知的待判断样本提取特征,作为输入数据,输入到训练好的模型中,模型输出是各个特征峰是否存在。
选用一种特定方法svm做实验验证,准确率的来源是,把经过人工标注的样本(已知各特征峰是否存在的样本),90%作为训练样本,按照步骤五中各子模型的构建方法进行模型训练,10%假设为未知样本,按照步骤六的方法进行自动识别判断,并将判断结果与人工标注结果进行比较,得出识别准确率。实际获得的准确率是用的交叉验证,把所有的已知样本随机分成10份,每一份都充当一次验证集(假设的未知样本),用其余9份训练一个模型,一共做了10次,10次的平均准确率最为最终识别率(交叉验证是常用的成熟方法)。
在实际应用中,对真正的未知样本,用步骤六中的方法,输入到训练好的模型中,对每条光谱判断得到3个输出结果,即d峰、g峰、2d峰是否存在。判断完了之后,模型的用途就已经用完了,接下来就是分别判断是否有缺陷,以及层数。首先,如果g峰、2d峰模型输出结果中都是存在的,就判决为当前位置存在石墨烯,进入下一步,否则就是不存在石墨烯;第二,对于存在石墨烯的位置,如果d峰的模型输出结果是存在的,就判决为有缺陷的点;第三,对与存在石墨烯的位置,对g峰邻域和2d峰邻域内的原始光谱幅度分别提取最大值,作为两个峰的幅度数据,根据这两个峰的相对幅度大小,判断单层或者多层。这里的第二、第三两步是并列的地位。
对步骤六的的最后判决结果分成这样几种情况:
(1)不存在石墨烯
(2)存在石墨烯
(a)单层,且有缺陷
(b)单层,且无缺陷
(c)多层,且有缺陷
(d)多层,且无缺陷
验证过程:
用witec设备采集得到的一个10000点的图为例,来验证通过上述步骤六的识别判决结果,witec是用于采集拉曼光谱的设备型号,识别准确率方面,目前就是用训练样本的准确率来评价。
具体的,通过witec设备采集的10000点(100*100)石墨烯拉曼光谱的自动识别结果,把通过步骤六的判决结果进行了图示化,图8、图9中的白色部分都对应于不存在石墨烯,黑色、灰色部分对应于存在石墨烯时,单/多层或者有无缺陷。
通过witec设备采集的10000点(100*100)石墨烯拉曼光谱,自动判别出的特征峰的情况的复轨迹集合,如图10-14所示,其中图10为g峰的复轨迹集合,图11为2d峰的复轨迹集合,图12为缺陷峰的复轨迹集合,图13为噪点的复轨迹集合,图14为无特征峰的情况(背景)的复轨迹集合。
(1)准确率的判断:由于没有被测试的所有10000点的真值,以传统人工判断方法选取部分样点的方式计算准确率。通过传统的人工判断方法,选取200个单层石墨烯的样点,其中100点有缺陷,100点无缺陷,200个多层石墨烯的样点,其中100点有缺陷,100点无缺陷,200个无石墨烯的样点,对这些样点的自动识别准确率为:
·有/无石墨烯:99.96%;
·有石墨烯的情况下,单/多层识别:100%
·有石墨烯的情况下,是否有缺陷:100%
(2)在基本保证准确的情况下,本发明的另一意义在于极高的提升了对石墨烯拉曼光谱识别的速度。传统方法,通过人工观察进行判断,以每秒钟判断一个样点的谱线类型计算,判断10000个样点所需时间为10000秒,约2.78小时。自动识别方法,在matlab2018b上多次运行的平均时间为32.86±1.85秒,所需时间为传统人工判断方法的0.33%。
由上所述,本发明提供一种基于大数据分析的石墨烯指纹峰分析方法,首先,基于一定量的石墨烯拉曼光谱的特征峰邻域进行复轨迹分析,并提取特征集,训练用于自动识别的智能算法模型;对新采集的石墨烯拉曼光谱数据,对特征峰邻域进行特征提取,输入智能算法模型中进行自动识别。也就是对大数据背景下,根据石墨烯的拉曼特征光谱进行石墨烯单层/多层,或有无缺陷进行自动识别,提高识别准确率和效率,为了解决当前拉曼光谱全靠人眼判断的难题,完成对石墨烯薄膜质量的自动判别,提高了识别效率且对石墨烯单层/多层、有无缺陷的识别准确率高,且本发明的分析方法抗干扰能力强,适用性广。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例。
- 还没有人留言评论。精彩留言会获得点赞!