一种用于失踪人群时空定位服务的数据分析方法与流程
本发明涉及数据分析技术领域,具体涉及一种用于失踪人群时空定位服务的数据分析方法。
背景技术:
人工智能界认为机器学习是人工智能领域中最能体现智能的一个分支之一。它致力于研究如何通过计算的手段,利用经验来改善系统自身的性能。机器学习所研究的主要内容是关于计算机上从数据中产生模型的算法。将经验数据提供给它,它就能通过这些数据产生模型。在面临新的情况发生时,模型就能够提供给相应的判断。
随机森林是一类常见的机器学习方法,是一个包含了多颗多个决策树的分类器。它的优点有:对于不平衡的分类资料集来说,它可以平衡误差;对于很多种资料,它可以产生高准确度的分类器;在决定类别时,它能够评估变数的重要性等。现今,相关的理论和技术均以完善。在充足数据集的支持下,利用机器学习的随机森林方法能够较好解决各种分类问题。
在中国,失踪人口的非法收养(包括失踪和被拐卖)是一直存在影响社会稳定和家庭稳定的关键公共安全问题。前人对失踪人口的非法收养问题研究较少,最新的成果是建立了失踪人口贩卖网络,对于非法收养的节点城市和关键路径进行了识别和定位。这一研究是从宏观尺度对人口非法收养网络进行的分析,有效说明了失踪人口的转移路径的整体情况,但没有对贩卖个例可能到达的位置进行有效的评估,为寻亲家庭提供直接的建议。
技术实现要素:
本发明要解决的技术问题在于,针对上述目前缺少对失踪人口去向预测的相关方法的技术问题,提供一种用于失踪人群时空定位服务的数据分析方法解决上述技术缺陷。
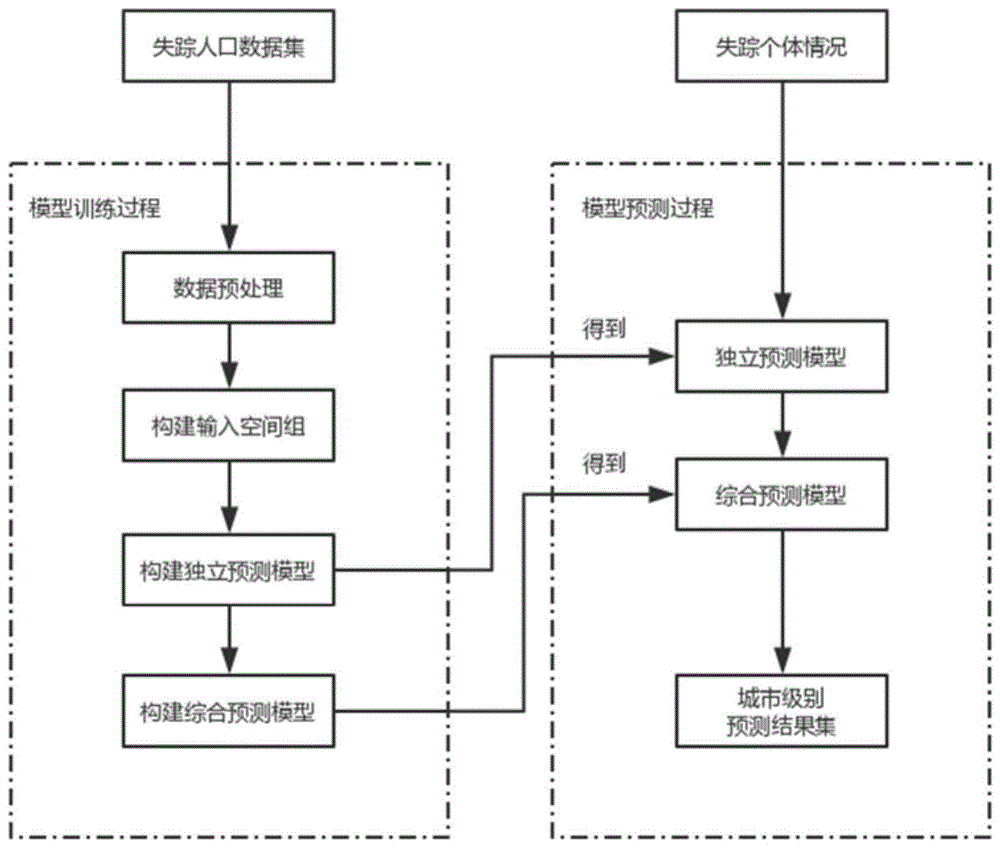
一种用于失踪人群时空定位服务的数据分析方法,包括:
s1、根据已有失踪人口数据构建初始数据集;
s2、对初始数据集中的数据进行数据筛选和预处理,提取得到用于进行分类的指标以构成样本数据集;
s3、对样本数据集中的数据进行进一步细化分类,并进行分类标号,得到用于模型构建的假设空间组;
s4、根据分别传入假设空间组中的各假设空间,来分别构建独立预测模型;
s5、按照独立预测模型的结果精度,基于统计方法创建综合预测模型,可给出失踪者可能到达的城市列表和对应城市的概率。
进一步的,s1中所述失踪人口数据,包括失踪者性别、身高、出生日期、失踪日期、失踪位置描述和到达位置描述;所述的初始数据集,包括失踪者性别、身高、出生日期、失踪日期、失踪位置描述和到达位置描述字段;所述的构建过程,是将上述失踪人口数据中的对应内容添加到初始数据集的对应字段中。
进一步的,s2中所述对初始数据集中的数据进行数据筛选和预处理过程,是将无效数据从数据集中剔除,无效数据包括缺失数据项的数据条目,以及数据内容不合法的数据条目;s2中提取得到的用于进行分类的指标包括失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达省份、到达区块、转移相对距离和转移相对方位。
进一步的,s2中提取出用于进行分类的指标的方法包括:
s21、将初始数据集中的失踪者性别、身高对应填入样本数据集中的性别、失踪时身高字段中;
s22、结合出生日期和失踪日期提取出失踪者失踪时的年龄、失踪年份和失踪月份填入样本数据集中的相应字段中;
s23、计算失踪位置和到达位置之间的相对距离和方位的关系,得到转移到达地相对于失踪地的距离和方位,填写入样本数据集中的相应字段中;
s24、根据失踪位置描述和到达位置描述信息,得到失踪区块和到达区块,填写入样本数据集中的相应字段中。
进一步的,s24中所述失踪区块与到达区块为对全国按照经纬网划分出的区块,划分的方式是:从数据集中描述的失踪位置描述和到达位置描述的经纬度中,找到最西南和最东北方向的两个点作为对角线,等分对全国划分区块并进行标号,然后按照全部数据中的失踪位置描述和到达位置描述,将其归纳入对应的区块之中。
进一步的,s3中所述对样本数据集中的数据进行进一步细化分类过程,具体的,不同字段分类指标如下:对于失踪省份和到达省份,按照我国省级行政区名称进行对应的划分,每个省级行政区归为一类;对于失踪区块和到达区块,按照s24中的区块标号进行分类;对于失踪年份,每隔5年作为一种分类类型;对于失踪月份,按照3月到5月、6月到8月、9月到11月、12月到2月分为四类;失踪者性别按照男、女分为两类;失踪者身高和失踪者年龄数据按照自然间断点分割法将年龄分为20类,而身高分为6类;相对转移距离数据按照自然间断点分割法划分为20类;相对转移方位分为北、东北、东、东南、南、西南、西、西北,共8类。
进一步的,所述转移相对方位分类中方位的确定,以失踪位置为原点,正北方向为0度,顺时针到到达方位的向量夹角进行参考,方位对应的角度值范围是:北:337.5-22.5;东北:22.5-67.5;东:67.5-112.5;东南:112.5-157.5;南:157.5-202.5;西南:202.5-247.5;西:247.5-292.5;西北:292.5-337.5。
进一步的,s4中所述模型构建的假设空间组共包含四个假设空间,每个假设空间的属性分别为:a、失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达省份;b、失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达区块;c、失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、转移相对距离;d、失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达省份、到达区块、转移相对方位。
进一步的,s4中所述分别传入假设空间组中的各假设空间,构建独立预测模型过程,共构建出了四个独立预测模型,分别为:a、通过失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高预测得到到达省份;b、通过失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高预测得到到达区块;c、通过失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高预测得到转移相对距离;d、失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达省份、到达区块预测得到转移相对方位;所述的四个独立预测模型计算得到的结果为预测内容的发生概率值,使用者可以获知在每一个预测模型的预测下,失踪者可能到达的省份、区块、转移相对距离和转移相对方位的分类编号和对应的概率。
进一步的,s5中所述基于统计方法创建综合预测模型的构建过程与方法包括:
s51、在上述独立预测模型中,预测得到失踪者到达的距离范围和方位范围,结合传入的失踪位置,得到一个固定的扇形区域,利用初始数据集中的所有数据,计算出这一扇形区域覆盖的城市;
s52、设s51中确定的扇形区域中覆盖了n个样本集中出现过的到达城市,分别标记为城市1,城市2,…,城市n,在样本集中,其在样本集出现的频数分别为
s53、类似地,根据到达省份和到达区块确定得到到达某一省份或区块后,进入某一城市的可能性,将到达某一省份后,进入某一城市i的可能性记为
s54、根据预测模型的直接独立预测结果,得到到达方位、到达距离范围、到达省份和到达区块的概率,利用到达方位和到达距离范围的概率,求解得到到达区域的概率。由于到达方位概率prdire和到达距离prdist概率是相互独立的,因此需用概率乘法法则计算并确定到达区域的概率prregion,即
prregion=prdire·prdist,
到达省份概率prprov和到达区块概率prblock能够在预测模型的结果中直接得到;
s55、在得到达区域、到达区块和到达省份的概率值后,根据独立事件下的条件概率模型,计算得到在区域预测模型下,到达某城市的概率
得到在某一独立预测模型下,到达某城市的概率;
s56、将上述得到的到达城市概率按照不同预测模型的kappa系数进行加权,能够得到不同预测模型的比重,进而得到最终的到达城市预测模型,区域、省份和区块的kappa系数分别记为kapparegion,kappaprov,kappablock,则最终到达某一城市的总概率prcity为
与现有技术相比,本发明优势在于:国内外目前对于失踪人口去向预测的相关研究较少,所存在的失踪者去向分析也仅停留在宏观尺度,没有对于失踪个例进行预测分析的方法或成果。而本发明弥补了这一方面的空白,提出了一种失踪者个例去向的预测方法,并在经验误差的检测中得到了较高精度。利用这一模型预测得到的最终结果为精确到城市级别的失踪者可能所在的位置。它能够为公共安全机构和有寻找失踪者需求的人群在地理位置方面提供更加准确和有效的参考。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1为本发明一种用于失踪人群时空定位服务的数据分析方法流程图;
图2为本发明数据预处理得到的假设空间示意图;
图3为本发明模型训练过程的流程图。
具体实施方式
为了对本发明的技术特征、目的和效果有更加清楚的理解,现对照附图详细说明本发明的具体实施方式。
一种用于失踪人群时空定位服务的数据分析方法,如图1所示,包括:
s1、根据已有失踪人口数据构建初始数据集;
失踪人口数据至少包括失踪者性别、身高、出生日期、失踪日期、失踪位置描述和到达位置描述。所述的初始数据集,至少包含失踪者性别、身高、出生日期、失踪日期、失踪位置描述和到达位置描述字段。所述的构建过程,实质为将上述失踪人口数据中的对应内容添加到初始数据集的对应字段中。对于失踪者的身高,其误差需要在10厘米之内;对于失踪者的失踪日期,其误差需要在一个月内;对于失踪者失踪位置描述和到达位置描述,其内容需要精确到县级行政区。
s2、对初始数据集中的数据进行数据筛选和预处理,提取得到用于进行分类的指标以构成样本数据集;
提取得到的用于进行分类的指标及样本数据集字段包含失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达省份、到达区块、转移相对距离和转移相对方位。
需要对失踪人口数据提取出用于进行分类的指标,其过程为:
s21、将初始数据集中的失踪者性别、身高对应填入样本数据集中的性别、失踪时身高字段中;
s22、结合出生日期和失踪日期提取出失踪者失踪时的年龄、失踪年份和失踪月份填入样本数据集中的相应字段中;
s23、计算失踪位置和到达位置之间的相对距离和方位的关系,得到转移到达地相对于失踪地的距离和方位,填写入样本数据集中的相应字段中;
s24、根据失踪位置描述和到达位置描述信息,得到失踪区块和到达区块,填写入样本数据集中的相应字段中。
为了对失踪者的位置进行补充性描述,避免在省份边界位置的预测造成误差,本发明提出了区块的概念:对全国按照经纬网划分出的区块。划分的方式为,从数据集中描述的失踪位置描述和到达位置描述的经纬度中,找到最西南和最东北方向的两个点作为对角线,等分对全国划分区块并进行标号。一般划分为16等分。然后,按照全部数据中的失踪位置描述和到达位置描述,将其归纳入对应的区块之中。
s3、对样本数据集中的数据进行进一步细化分类,并进行分类标号,得到用于模型构建的假设空间组;
对样本数据集中的数据进行进一步细化分类过程,不同字段分类指标如下:对于失踪省份和到达省份,按照我国省级行政区名称进行对应的划分,每个省级行政区归为一类;对于失踪区块和到达区块,按照权利要求7中所述的区块标号进行分类;对于失踪年份,从1980年之后,每隔5年作为一种分类类型;对于失踪月份,按照3月到5月、6月到8月、9月到11月、12月到2月分为四类;失踪者性别按照男、女分为两类;失踪者身高和失踪者年龄数据按照自然间断点分割法将年龄分为20类,而身高分为6类;相对转移距离数据按照自然间断点分割法划分为20类;相对转移方位分为北、东北、东、东南、南、西南、西、西北,共8类。转移相对方位分类中方位的确定,以失踪位置为原点,正北方向为0度,顺时针到到达方位的向量夹角进行参考,方位对应的角度值范围如下所描述:北:337.5-22.5;东北:22.5-67.5;东:67.5-112.5;东南:112.5-157.5;南:157.5-202.5;西南:202.5-247.5;西:247.5-292.5;西北:292.5-337.5。
s4、根据分别传入假设空间组中的各假设空间,来分别构建独立预测模型;
在完成样本数据集的分类细化工作后,得到的结果可以进行假设空间的构建。模型构建的假设空间组共包含四个假设空间,如图2所示,每个假设空间的属性分别为:
(1)失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达省份;
(2)失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达区块;
(3)失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、转移相对距离;
(4)失踪省份、失踪区块、失踪时年龄、失踪年份、失踪月份、性别、失踪时身高、到达省份、到达区块、转移相对方位。
使用机器学习的随机森林方法,分别传入四个假设空间,构建得到四个独立预测模型。独立预测模型计算得到的结果均为预测内容的发生概率值。使用者可以获知在每一个预测模型的预测下,失踪者可能到达的省份、区块、转移相对距离和转移相对方位的分类编号和对应的概率。
s5、按照独立预测模型的结果精度,基于统计方法创建综合预测模型,可给出失踪者可能到达的城市列表和对应城市的概率。
在得到四个独立预测模型后,结合各模型经一致性检验得到的的总体精度和kappa系数,进一步构建基于统计方法创建综合预测模型。如图3所示,综合预测模型的构建过程如下:
s51、在上述独立预测模型中,预测得到失踪者到达的距离范围和方位范围,结合传入的失踪位置,可得到一个固定的扇形区域。利用初始数据集中的所有数据,可计算出这一扇形区域覆盖的城市。
s52、设s51中确定的扇形区域中覆盖了n个样本集中出现过的到达城市,分别标记为城市1,城市2,…,城市n,在样本集中,其在样本集出现的频数分别为
s53、类似地,可根据到达省份和到达区块确定得到到达某一省份或区块后,进入某一城市的可能性。将到达某一省份后,进入某一城市i的可能性记为
s54、根据预测模型的直接独立预测结果,可以获知到达方位、到达距离范围、到达省份和到达区块的概率。利用到达方位和到达距离范围的概率,可以求解得到到达区域的概率。由于到达方位概率prdire和到达距离prdist概率是相互独立的,因此需用概率乘法法则计算并确定到达区域的概率prregion,即
prregion=prdire·prdist,
而到达省份概率prprov和到达区块概率prblock能够在预测模型的结果中直接得到。
s55、在得到达区域、到达区块和到达省份的概率值后,根据独立事件下的条件概率模型,可计算得到在区域预测模型下,到达某城市的概率
由此,可以得到在某一独立预测模型下,到达某城市的概率。
s56、将上述得到的到达城市概率按照不同预测模型的kappa系数进行加权,能够得到不同预测模型的比重,进而得到最终的到达城市预测模型。区域、省份和区块的kappa系数分别记为kapparegion,kappaprov,kappablock,则最终到达某一城市的总概率prcity为
根据这一基于统计方法创建综合预测模型,可以得到的结果按照到达城市的概率值降序排序,并给出全部预测得到的对应城市和概率值。
本发明结合失踪人口志愿者数据库,利用机器学习的随机方法,构建了一种用于失踪人群时空定位服务的数据分析模型,以个体为基本尺度,将非法收养人员的信息开展进一步的时空分析,以挖掘失踪人口的转移路径、当前位置及其驱动因素。
上面结合附图对本发明的实施例进行了描述,但是本发明并不局限于上述的具体实施方式,上述的具体实施方式仅仅是示意性的,而不是限制性的,本领域的普通技术人员在本发明的启示下,在不脱离本发明宗旨和权利要求所保护的范围情况下,还可做出很多形式,这些均属于本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!