数据分发入库处理方法及系统与流程
本发明涉及计算机技术领域,尤其涉及一种数据分发入库处理方法及系统。
背景技术:
计算机数据处理系统将实时数据写入不同的数据库时,通常是直接将数据分发至不同的数据库,并发写入数据库时,需要一个强大的数据源接口处理大量的并发请求。
技术实现要素:
本发明实施例提供一种数据分发入库处理方法及系统,可以支持大量数据的并发请求,实现数据分发统计的功能。
本发明实施例第一方面提供了一种数据分发入库处理方法,可包括:
根据待入库数据的业务需求确定待入库数据是否需要持久化;
为需要持久化的待入库数据设置入库配置;
根据入库配置将待入库数据存储至对应的数据库。
进一步的,上述方法还包括:
根据所获取的数据入库请求确定待入库数据对应的业务需求。
进一步的,上述方法还包括:
将不需要持久化的待入库数据存储至分布式消息队列kafka中。
进一步的,上述方法还包括:
监控待入库数据的数据量;
当数据量的变化异常时,输出异常提示信息,异常提示信息指示异常发生的时刻和异常数据所处的位置。
进一步的,上述方法还包括:
基于用户需求对待入库数据进行数据过滤。
本发明实施例第二方面提供了一种数据分发入库处理系统,可包括:
入库数据检测模块,用于根据待入库数据的业务需求确定待入库数据是否需要持久化;
入库配置设置模块,用于为需要持久化的待入库数据设置入库配置;
第一数据存储模块,用于根据入库配置将待入库数据存储至对应的数据库。
进一步的,上述系统还包括:
业务需求确定模块,用于根据所获取的数据入库请求确定待入库数据对应的业务需求。
进一步的,上述系统还包括:
第二数据存储模块,用于将不需要持久化的待入库数据存储至分布式消息队列kafka中。
进一步的,上述系统还包括:
数据监控模块,用于监控待入库数据的数据量;
异常提示模块,用于当数据量的变化异常时,输出异常提示信息,异常提示信息指示异常发生的时刻和异常数据所处的位置。
进一步的,上述系统还包括:
数据过滤模块,用于基于用户需求对待入库数据进行数据过滤。
在本发明实施例中,通过待入库数据的业务需求确定入库数据是否需要持久化,为需要持久化的待入库数据设置入库配置,根据入库配置将待入库数据存储至对应的数据库。支持大量数据的并发请求和数据的分发统计,通过预先设定的配置做相应的处理,提高了对数据库操作的灵活性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍。
图1是本发明实施例提供的一种数据分发入库处理方法的流程示意图;
图2是本发明实施例提供的一种数据分发入库处理系统的结构示意图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述。
本发明实施例提供的数据分发入库处理方法可以应用于处理海量数据并发请求的应用场景。
下面将结合附图1,对本发明实施例提供的数据分发入库处理方法进行详细介绍。
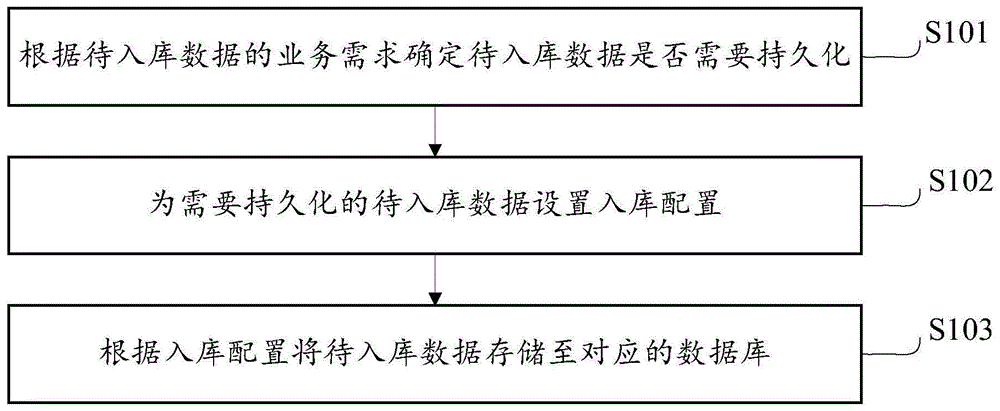
请参见图1,为本发明实施例提供了一种数据分发入库处理法的流程示意图。如图1所示,本发明实施例的所述方法可以包括以下步骤S101-步骤S103。
S101,根据待入库数据的业务需求确定待入库数据是否需要持久化。
需要说明的是,上述系统可以获取数据入库请求,并可以根据该请求确定待入库数据对应的业务需求,所谓的业务需求可以指示待入库数据数据对应的业务进程。
具体实现中,上述系统可以对所有的待入库的数据提供统一的入口,可以根据待入库数据的业务需求确定该数据是否需要持久化。可以理解的是,需要持久化的数据可以是对后续的数据分析有用的,需要永久保存的数据,不需要持久化的数据可以是只对当前操作有用的数据。
在本发明实施例的具体实现方式中,常见的业务需求有离线统计和实时统计,对于离线的统计不关注数据的及时性,但是比较关注以后的分析,需要将这样数据持久化下来,比如常见的每天有多少用户使用了系统提供的产品,用户在该产品上面花费了多少时间,这些都是需要长期分析的数据,那么都需要持久化下来。有些业务是只需要关注当前状态,比如检查产品有没有宕机,像这样的需求只关注当前的状态,那么就不需要把这些数据持久化下来。
在可选实施例中,对于不需要持久化的数据,上述系统可以将待入库数据存储至分布式消息队列kafka中,也可以存储至其他存储临时数据的数据缓存模块,供其他服务直接使用。
S102,为需要持久化的待入库数据设置入库配置。
需要说明的是,对于需要持久化的待入库数据,上述系统可以为其设置入库配置,该配置可以是开发人员根据需要对数据库进行的操作预先设置的配置,例如,可以预先配置config。通过预先进行入库配置,使得根据需求对数据库的操作更加灵活化。
S103,根据入库配置将待入库数据存储至对应的数据库。
具体的,上述系统可以根据上述入库配置将待入库数据存储至对应的数据库。可选的,在存入数据库之前,上述系统也可以接受用户输入的用户需求,并可以基于该需求对待入库数据进行数据过滤,过滤掉用户不需要的数据。
在可选实施例中,上述系统在检测到每一个数据入库请求的时候,可以设置任务来监控待入库数据的数据量,例如,监控拿起,放下,购买,触碰等行为数据量以及不同设备的数据量,当上述数据量的变化异常时,可以输出异常提示信息,上述异常提示信息可以指示异常发生的时刻和异常数据所处的位置。可选的,上述系统可以监控在CPU或者Memory(内存)的功能,在CPU或者Memory或者数据量异常时可以很快的反应过来并且解决这方面的问题。
在本发明实施例中,通过待入库数据的业务需求确定入库数据是否需要持久化,为需要持久化的待入库数据设置入库配置,根据入库配置将待入库数据存储至对应的数据库。支持大量数据的并发请求和数据的分发统计,通过预先设定的配置做相应的处理,提高了对数据库操作的灵活性。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
下面将结合附图2,对本发明实施例提供的数据分发入库处理系统进行详细介绍。需要说明的是,附图2所示的数据分发入库处理系统,用于执行本发明图1所示实施例的方法,为了便于说明,仅示出了与本发明实施例相关的部分,具体技术细节未揭示的,请参照本发明图1所示的实施例。
请参见图2,为本发明实施例提供了一种数据分发入库处理系统的结构示意图。如图2所示,本发明实施例的数据分发入库处理系统10可以包括:入库数据检测模块101、入库配置设置模块102、第一数据存储模块103、业务需求确定模块104、第二数据存储模块105、数据监控模块106、异常提示模块107和数据过滤模块108。
入库数据检测模块101,用于根据待入库数据的业务需求确定待入库数据是否需要持久化。
需要说明的是,上述系统10可以获取数据入库请求,业务需求确定模块104可以根据该请求确定待入库数据对应的业务需求,所谓的业务需求可以指示待入库数据数据对应的业务进程。
具体实现中,上述系统10可以对所有的待入库的数据提供统一的入口,入库数据检测模块101可以根据待入库数据的业务需求确定该数据是否需要持久化。可以理解的是,需要持久化的数据可以是对后续的数据分析有用的,需要永久保存的数据,不需要持久化的数据可以是只对当前操作有用的数据。
在本发明实施例的具体实现方式中,常见的业务需求有离线统计和实时统计,对于离线的统计不关注数据的及时性,但是比较关注以后的分析,需要将这样数据持久化下来,比如常见的每天有多少用户使用了系统提供的产品,用户在该产品上面花费了多少时间,这些都是需要长期分析的数据,那么都需要持久化下来。有些业务是只需要关注当前状态,比如检查产品有没有宕机,像这样的需求只关注当前的状态,那么就不需要把这些数据持久化下来。
在可选实施例中,对于不需要持久化的数据,第二数据存储模块105可以将待入库数据存储至分布式消息队列kafka中,也可以存储至其他存储临时数据的数据缓存模块,供其他服务直接使用。
入库配置设置模块102,用于为需要持久化的待入库数据设置入库配置。
需要说明的是,对于需要持久化的待入库数据,入库配置设置模块102可以为其设置入库配置,该配置可以是开发人员根据需要对数据库进行的操作预先设置的配置,例如,可以预先配置config。通过预先进行入库配置,使得根据需求对数据库的操作更加灵活化。
第一数据存储模块103,用于根据入库配置将待入库数据存储至对应的数据库。
具体实现中,第一数据存储模块103可以根据上述入库配置将待入库数据存储至对应的数据库。可选的,在存入数据库之前,上述系统10也可以接受用户输入的用户需求,数据过滤模块108可以基于该需求对待入库数据进行数据过滤,过滤掉用户不需要的数据。
在可选实施例中,上述系统10在检测到每一个数据入库请求的时候,数据监控模块106可以设置任务来监控待入库数据的数据量,例如,监控拿起,放下,购买,触碰等行为数据量以及不同设备的数据量,当上述数据量的变化异常时,异常提示模块107可以输出异常提示信息,上述异常提示信息可以指示异常发生的时刻和异常数据所处的位置。可选的,上述系统可以监控在CPU或者Memory(内存)的功能,在CPU或者Memory或者数据量异常时可以很快的反应过来并且解决这方面的问题。
在本发明实施例中,通过待入库数据的业务需求确定入库数据是否需要持久化,为需要持久化的待入库数据设置入库配置,根据入库配置将待入库数据存储至对应的数据库。支持大量数据的并发请求和数据的分发统计,通过预先设定的配置做相应的处理,提高了对数据库操作的灵活性。
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(Read-Only Memory,ROM)或随机存储记忆体(Random Access Memory,RAM)等。
以上所揭露的仅为本发明较佳实施例而已,当然不能以此来限定本发明之权利范围,因此依本发明权利要求所作的等同变化,仍属本发明所涵盖的范围。
- 还没有人留言评论。精彩留言会获得点赞!