一种面向深度行人重识别系统的反侦察伪装“隐形衣”生成方法与流程
本发明设计人工智能安全领域,具体地指一种面向深度行人重识别系统的反侦察伪装“隐形衣”生成方法。
背景技术:
随着移动互联网的飞速发展,硬件设备的持续升级、海量数据的生产和算法的更新,人工智能(AI)的发展已势不可挡,正在逐渐渗透并深刻改变人类的生活。目前,基于机器学习和深度学习的人工智能技术被广泛应用在人机交互、视觉处理系统、推荐系统、安全诊断与防护等各个领域,其应用场景包括无人驾驶、图像识别、恶意软件检测、恶意邮件过滤等等。可以说,人工智能时代的到来与数据计算和存储能力的发展促进了各个领域变革。行人重识别是一项匹配跨摄像头下感兴趣人物的任务,在视频监控和安全领域有广泛的应用,例如嫌疑犯和失踪人员搜索、跨摄像头行人跟踪、行人活动分析等。近年来,随着深度学习技术发展迅速,基于深度神经网络的行人重识别系统取得了接近人类的行人匹配水平,并逐渐成为主流方法。
然而,近期研究表明深度神经网络对于特定的攻击十分脆弱:将输入图像加上精心构建的人类难以察觉的噪声,会引诱深度神经网络以异常方式工作,这对基于深度神经网络的各类应用构成潜在威胁,如人脸识别、无人驾驶、恶意软件检测等。由于行人重识别系统在安全系统中的广泛部署和应用,研究深度行人重识别系统是否容易受到攻击至关重要。一旦深度行人重识别系统对特定攻击脆弱,将带来严重后果和安全威胁,例如,犯罪分子可以逃避执法部门的搜索和定位,或者间谍可以侵入受监控的机密区域。
技术实现要素:
本发明的目的是为了克服现有技术的局限,提供一种面向深度行人重识别系统的反侦察伪装“隐形衣”生成方法。
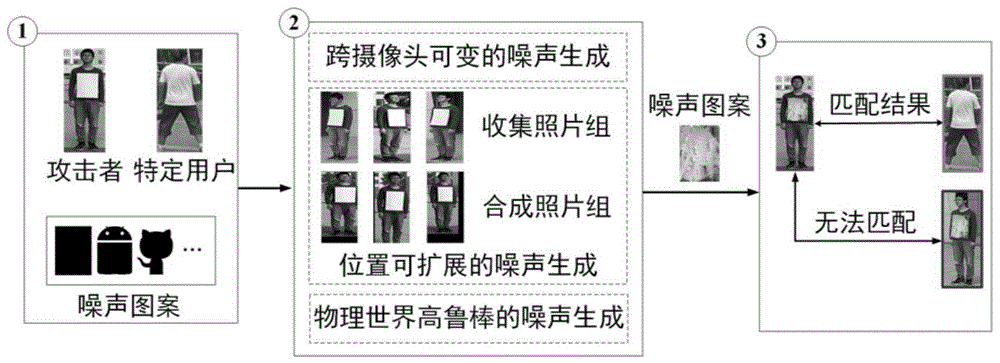
本发明所设计的一种面向深度行人重识别系统的反侦察伪装“隐形衣”生成方法,其特殊之处在于,包含如下步骤:
1)对给定的具有白盒访问权限的行人重识别系统,设定攻击者想要匹配到的特定用户;
2)构建攻击者在各摄像头下的照片组,设计基于多位置采样的噪声图案生成方法,生成位置可扩展的噪声图案;
3)基于匹配差异最小化的跨摄像头可变的噪声图案生成方法,使跨摄像头下的攻击者图像相互远离无法被行人重识别系统匹配,并使加噪声的图像与特定用户被错误匹配;
4)将物理环境因素融入噪声图案生成过程,打印噪声图案并贴在衣服上,以实现在现实场景下攻击行人重识别系统。
进一步地,构建攻击者在各摄像头下的照片组具体过程为:
收集大量攻击者在监控摄像头下不同位置被拍摄的照片,以及将每张拍摄的照片进行基本图像变换得到的合成照片,以上照片共同构成噪声生成集。
更进一步地,所述步骤3)的具体过程如下:
通过解决跨摄像头拍摄下攻击者照片匹配相似度的最小化的优化问题来迭代地寻找跨摄像头的可变的噪声图案;具体地,对于来自m组摄像头拍摄的照片,以及来自特定用户的被拍摄的照片It,解决如下优化问题:
其中,目标行人重识别系统表示为fθ(x,y)=sc,x为系统需要查询的图像,y为其他摄像头收集的行人照片,θ为模型参数;x′i是将将噪声δ通过和被拍摄者i一致的图像变换加到上xi上得到的;
其中,每次迭代从噪声生成集以及特定用户照片集It中随机挑选照片构成四元组为攻击者在同摄像头下的两张照片,为攻击者在其他摄像头的一张照片,It为所述特定用户别拍摄的照片组中的一张照片,基于匹配差异最小化的跨摄像头可变的噪声图案生成方法解决如下优化问题:
生成的噪声有能力将同摄像头照片提取的特征之间的差距越来越小,同时使跨摄像头照片提取的特征之间的差距越来越大,并均与特定用户照片特征接近。
再进一步地,所述迭代次数设定为750次,或者小于750内收敛即完成迭代。
进一步地,所述步骤4)中加入平滑正则项:
TV(δ)=∑i,j((δi,j-δi+1,j)2+(δi,j-δi,j+1)2)。
进一步地,所述步骤4)中将噪声的取值转换到打印机颜色取值范围内进行打印。
进一步地,所述步骤4)中加入随机图像退化函数使噪声在对信息丢失具有高鲁棒性。
本发明和现有技术相比,具有的有益效果是:
1)提出了新型的面向深度行人重识别系统的伪装反制方法,通过生成“隐形衣”完成对目标行人重识别系统的反侦察伪装。
2)提出基于匹配差异最小化的优化方法,生成跨摄像头可变的噪声图案,使其在不同摄像头的拍摄下无法互相匹配,并均与特定用户匹配。
3)在噪声图案生成过程中考虑多位置采样策略,生成的噪声在监控区域的任意位置均能达到攻击效果。
4)为了提高噪声图案的物理世界的鲁棒性,本方法将物理环境因素融入噪声图案生成过程,使其在打印和拍摄过程信息丢失后仍然有效。
附图说明
图1为面向深度行人重识别系统的反侦察伪装“隐形衣”生成方法框架
图2为面向深度行人重识别系统的伪装攻击示意图
图3为面向深度行人重识别系统的伪装攻击示例
具体实施方式
本发明认为深度行人重识别的安全性问题仍然没有受到关注,在被广泛应用时会带来潜在的安全威胁,因此急需一种面向深度行人重识别系统的反侦察伪装“隐形衣”生成方法。
本发明所设计的面向深度行人重识别系统的反侦察伪装“隐形衣”生成方法包含如下步骤:
1)给定一个行人重识别系统,输入查询图像,该系统输出其他摄像头下拍摄的图像与查询图像的相似度以及相似度排名。攻击者能够访问目标模型的参数和权重,并设定攻击者想要匹配到的特定用户。
目标行人重识别系统可以表示为fθ(x,y)=sc,其中x为系统需要查询的图像,y为其他摄像头收集的行人照片,θ为模型参数,sc为系统的输出,即对进行匹配的一组照片(x,y)的相似度分数。被查询的照片和系统在其他摄像头下收集的照片组G一一匹配,输出相似度最高的照片作为最终匹配结果,即:
Y={y1,y2,…,yK}s.tψ(fθ(x,yi))<K
其中K为系统设定的输出匹配分数最高的照片个数,ψ(·)将收集的照片组按照匹配分数从高到低进行排序。攻击者以一个训练好的基于神经网络的行人重识别系统为攻击目标,对目标模型具有白盒访问权限,即能够访问目标模型的参数和权重,并设定系统中的特定用户,使攻击者被查询时被系统误匹配成该特定用户。
2)构建攻击者收集照片组和合成照片组,设计基于多位置采样的噪声图案生成方法,生成位置可扩展的噪声图案,在监控区域的任意位置均能达到攻击效果。
构成噪声生成集Xc具体为:收集大量攻击者在监控摄像头下不同位置被拍摄的照片,以及将每张拍摄的照片进行基本图像变换得到的合成照片。合成照片包括通过图像的平移、缩放和亮度变换等变换所得。
本实施例中,构件噪声生成集具体为,在每个摄像头下设置不同距离和角度50个采样点,分别在每个采样点收集10张拍摄的照片;对于每张采集的照片,随机选取5种基本图像变换生成5张合成照片。对于一次攻击,构建总数为3000张照片的合成集。
3)基于匹配差异最小化的跨摄像头可变的噪声图案生成方法,使跨摄像头下的攻击者图像相互远离无法被行人重识别系统匹配,并使加噪声的图像与特定用户被错误匹配。
通过解决跨摄像头拍摄下攻击者照片匹配相似度的最小化的优化问题来迭代地寻找跨摄像头的可变的噪声图案。具体地,对于来自m组摄像头拍摄的照片,以及来自特定用户的被拍摄的照片It,解决如下优化问题:
其中x′i是将将噪声δ通过和被拍摄者i一致的图像变换加到上xi上得到的。在优化过程中噪声图案学习跨摄像头下的被拍摄者的形态以及照片风格的区别来提高自己的攻击能力,使攻击者在跨摄像头下拍摄的照片提取的特征之间的差距越来越大,直到无法正确相互匹配,并都与特定用户的照片匹配。
每次在生成集中随机选取同摄像头下的两张照片以及其他摄像头的一张照片并在设定的系统特定用户被拍摄的照片组It随机挑选一张照片ti来构成一个四元组Qi,本方法基于多位置采样策略,通过多组不同的Qi来迭代地优化对噪声图案进行优化,对多组不同位置拍摄以及合成的照片进行优化生成的噪声δ能够在监控区域的任意位置被拍摄都能完成反侦察伪装攻击。Xc将用于解决生成噪声图案的优化问题,每次迭代从Xc以及特定用户照片集It中随机挑选照片构成四元组通过不同的四元组使生成的噪声图案能够在监控区域的任意位置有效。将基于多位置采样策略与该优化问题结合,即可生成满足多位置可扩展的跨摄像头可变的噪声图案:
其中,λ1和λ2为超参数,用来控制不同优化项对最终结果影响程度,具体实验中我们取λ1=0.25,λ1=0.2生成噪声图案。生成的噪声有能力将同摄像头照片提取的特征之间的差距越来越小,同时使跨摄像头照片提取的特征之间的差距越来越大,并均与特定用户照片特征接近。通过选取生成集中不同位置以及不同合成方法的照片,使得噪声图案能够对没有“见过”的位置拍摄的照片同样有效。用ADAM优化器生成噪声,其参数设置如下:学习率为0.01,β1=0.9,β2=0.999。
4)考虑物理世界中打印和拍摄误差,将物理环境因素融入噪声图案生成过程,生成高鲁棒性的噪声图案,打印并贴上“隐形衣”能够在现实场景下攻击行人重识别系统。
考虑打印和拍摄过程噪声图案活性的影响,将物理环境因素融入噪声图案生成过程,生成高鲁棒性的噪声图案,使噪声打印和贴上攻击者的衣服上能够对行人重识别系统进行反侦察伪装攻击。首先,为了使生成的噪声与衣服图案看起来同样自然平滑,本方法在优化问题中加入平滑正则项:
该正则项加入优化式中系数β=0.001。本方法通过最小化噪声图案相邻像素取值之间差异,提高噪声的平滑程度,使得攻击者穿上“隐形衣”不会引起怀疑。接下来确定可打印的颜色范围并将噪声的取值范围内来消除打印带来的误差;最后,由于拍摄过程中环境条件以及摄像头设备拍摄噪声对信息的丢失,本方法在噪声生成的过程中加入随机图像退化函数使噪声在对信息丢失具有高鲁棒性。本实施例中,
本发明的优点在于:
1)提出了新型的面向深度行人重识别系统的伪装反制方法,通过生成“隐形衣”完成对目标行人重识别系统的反侦察伪装。
2)提出基于匹配差异最小化的优化方法,生成跨摄像头可变的噪声图案,使其在不同摄像头的拍摄下无法互相匹配,并均与特定用户匹配。
3)在噪声图案生成过程中考虑多位置采样策略,生成的噪声在监控区域的任意位置均能达到攻击效果。
4)为了提高噪声图案的物理世界的鲁棒性,本方法将物理环境因素融入噪声图案生成过程,使其在打印和拍摄过程信息丢失后仍然有效。
- 还没有人留言评论。精彩留言会获得点赞!