一种基于双通道卷积神经网络的重复缺陷报告检测方法与流程
本发明涉及软件测试
技术领域:
,特别涉及一种基于双通道卷积神经网络的重复缺陷报告检测方法。
背景技术:
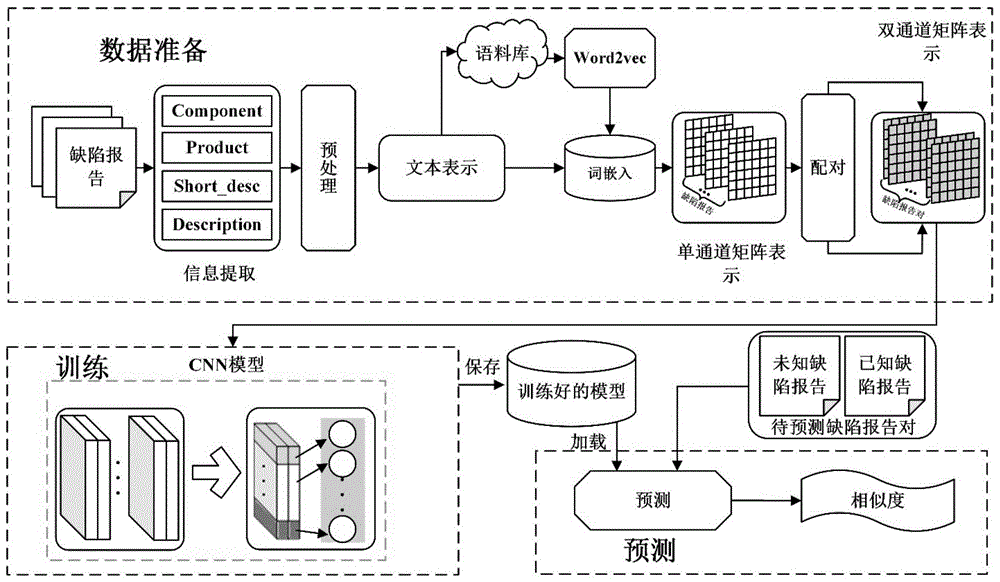
:现代软件项目使用如bugzilla[17]的缺陷跟踪系统来存储和管理缺陷报告。软件开发人员,软件测试人员和终端用户在遇到软件问题时,提交缺陷报告来描述这些问题。缺陷报告可以帮助指导软件维护和修复工作。随着软件系统的发展,每天都会有数百个缺陷报告被提交。当超过一个人提交缺陷报告来描述一个相同的bug时,重复缺陷报告就产生了。因为缺陷报告总是用自然语言描述,因此同一个bug也很可能以不同的形式描述。因为缺陷报告数量庞大,手动检测重复缺陷报告是一个艰难的工作。此外,因为缺陷报告以自然语言描述,提供一个标准模版也是不实际的。因此,重复缺陷报告的自动检测是一件有意义的工作,它可以避免多次修复同一个bug。今年来,许多重复缺陷报告自动检测技术被提出来以解决这个问题。这些方法可以被粗略地分为信息检索和机器学习两个方向。信息检索方法,它通常计算两个缺陷报告在文本上的相似度,即专注于根据文本描述来计算相似度。例如hiew使用vsm(vectorspacemodel)建立了一个模型,它将一个报告计算为一个具有tf-idf(termfrequency-inversedocumentfrequency)术语加权方案的向量。基于vsm,runeson等人首次运用自然语言处理技术来检测重复缺陷报告。wang等人认为仅仅考虑自然语言信息不能很好地解决这个问题,因此他们还将执行信息作为一个特征来进行重复报告检测。然而,仅仅只有一小部分报告具有执行信息,所以这种方法具有很大的局限性。sun等人提出了rep,这种方法不仅仅使用了summary和description,还使用了product,component,version等结构化信息。为了得到更高的文本相似度,他们扩展了bm25f,一种在信息检索领域有效的相似度计算方法。除了文本相似度和结构化相似度,alipour等人还考虑了上下文信息对重复报告检测的影响。他们将lda运用到这些特征上,取得了更好的结果。基于信息减速的方法在准确率和时间效率上都表现得很好,但是当一个问题以不同的术语描述时,结果就不令人满意了。机器学习方法通过自学习的算法来提取报告的潜在特征,但是传统的机器学习方法无法很好地学习输入的深度特征。svm是机器学习一个经典的方法。jalbert等人用它建立了一个可以过滤重复报告的分类系统。同时,他们认为先前的方法没有充分利用缺陷报告中的各种特征,因此他们在模型中使用了表面特征,文本语义和图聚类。在jalbert等人工作的基础上,tian等人考虑了一些新的特征并建立了一个线性模型。从特征和不平衡数据的角度出发,他们提高了重复报告检测的准确率。sun等人运用svm建立了一个解释模型,他们也首次把缺陷报告分为重复和非重复两类。l2r是另外一个非常有用的机器学习方法。基于此,zhou等人考虑了文本和统计特征,并对他们使用了随机梯度下降算法。这个方法比传统的信息检索方法,例如vsm和bm25f具有更好的效果。随着词嵌入技术[在自然语言处理领域的应用,越来越多的研究人员用它来检测重复报告。budhiraja等人用词嵌入技术将缺陷报告转化为向量然后计算它们的相似度。实验结果表明,这种方法具有提高重复报告检测准确率的潜力。技术实现要素:本发明要解决的技术问题是重复报告自动检测问题,这个问题可以进一步分解为判断两个缺陷报告之间的关系,即,一个由两个报告组成的缺陷报告对是重复的还是不重复的。为实现上述目的,本发明采用如下技术方案:一种基于双通道卷积神经网络的重复缺陷报告检测方法,包括如下步骤:s100:数据准备s101:提取软件的缺陷报告,所有缺陷报告均由结构化信息和非结构化信息组成,对于每一个缺陷报告,将所有结构化信息和非结构化信息放入一个单独的文本发明档中;s102:对于每一个缺陷报告,进行预处理步骤,包括分词、提取词干、去除停用词和大小写转化;s103:预处理后,所有缺陷报告中的词被组合成一个语料库,在语料库上使用现有的word2vec并选择cbow模型,获得每一个词的向量表示,即得到每个缺陷报告的二维矩阵表示,称为缺陷报告的二维单通道矩阵;根据提取软件的缺陷报告时,该软件缺陷跟踪系统给出的已知信息(这个配对的信息是数据集中的,是由创建数据集的人处理得到的),将两个缺陷报告组成的缺陷报告对通过二维双通道矩阵表示,所述二维双通道矩阵由所述两个缺陷报告对应的二维单通道矩阵组合而成,然后给该双通道矩阵它打上重复或者不重复的标签;将所有打上标签的双通道矩阵,分为训练集和验证集;s200:建立cnn模型s201:将训练集和验证集中的所有双通道矩阵一起输入cnn模型;s202:在第一个卷积层中,设置个卷积核其中d是卷积核的长度,kw是卷积核的宽度;在第一次卷积后,双通道矩阵的两个通道就合并成一个了,第一层卷积公式为:其中c1表示第一个卷积层的输出,i表示第一个卷积层输入i1的第i个通道,j1表示输入的第j1行,b1表示偏移量,f1表示非线性的激活函数,给定输入的长度l(l=nw),填充值p=0和步长s=1,输出的长度o1可以被计算为:第一个卷积层的输出形状为将第一个卷积层的输出形状重塑成然后再卷积,在第二个卷积层,又设置了三种大小的卷积核每种卷积核个,第二层卷积的公式为:其中c2表示第二个卷积层的输出,j2表示第二个卷积层输入i2的第j2行,b2表示偏移量,f2表示非线性的激活函数,在这次卷积之后,会得到三种形状为的特征图,其中o2可以根据l(l=o1)和不同的卷积核长度d,按照公式(2)计算;s203:对所有的特征图进行最大池化;s204:重塑并拼接所有的特征图以得到一个维的向量,它将被作为全连接层的输入;两个全连接层之后,得到一个独立的概率simpredict,它代表了两个报告被预测的相似度;在最后一层,使用sigmoid作为激活函数得到simpredict;给定第一个全连接层的输出t={x1,x2,…,x300}和权重向量w={w1,w2,…,w300},simpredict可以被计算为:其中i表示t的第i个元素,b表示偏移量;s205:遍历训练集中的所有缺陷报告对,重复s202-s204;s206:根据损失函数进行反向传播以更新模型的隐藏参数,损失函数如公式(5):其中labelreal表示预设的缺陷报告对的标签,i表示第i个缺陷报告对,n表示缺陷报告对的总数;s207:每个epoch训练结束后,使用验证集对模型进行验证;当验证集的损失在5个epoch内都不再降低时,停止更新模型参数;否则返回s201,继续训练cnn模型;s300:待预测缺陷报告预测首先采用s102中的方法对待预测缺陷报告进行预处理,然后采用s103中的方法将该待预测缺陷报告转化为预测缺陷报告的二维单通道矩阵;将预测缺陷报告的二维单通道矩阵与该软件已有的n个缺陷报告的二维单通道矩阵两两组合得到n个待预测双通道矩阵,将n对待预测双通道矩阵构成预测集,将预测集中的每个待预测双通道矩阵作为输入,输入到所述cnn模型中,得到一个概率;当n个概率中,概率大于阈值的则认为该概率所对应的缺陷报告和预测缺陷报告为重复。作为改进,所述s101中结构化信息为product和component,非结构化信为summary和description。作为改进,在除了最后一个全连接层的其他层,都是用relu作为激活函数来提取更多地非线性特征。相对于现有技术,本发明至少具有如下优点:本发明提出了一个新的方法dc-cnn来进行重复缺陷报告检测。它将两个由单通道矩阵表示的缺陷报告组合成一个双通道矩阵表示的缺陷报告对。然后,这个双通道矩阵被输入到cnn模型中来提取隐含的特征。本发明在openoffice,eclipse,netbeans和它们的组合数据集combined上验证了提出的方法并与目前最先进的基于深度学习的重复报告检测方法进行了对比,本发明方法均是有效的,更重要的是性能也更好。附图说明图1为本发明方法的总体框架。图2为建立cnn模型的总体流程。图3(a)为dc-cnn和sc-cnn在openoffic数据集上的roc曲线,图3(b)为dc-cnn和sc-cnn在eclipse数据集上的roc曲线,图3(c)为dc-cnn和sc-cnn在netbeans数据集上的roc曲线,图3(d)为dc-cnn和sc-cnn在combined数据集上的roc曲线。图4为词向量维度的影响。图5为非结构化信息的影响。具体实施方式下面结合附图对本发明作进一步详细说明。图1展示了本发明方法dc-cnn的整体框架,它包含了三个阶段:数据准备、建立cnn模型和待预测缺陷报告预测。在数据准备阶段,对重复报告有用的字段,包括component、product、summary和description从缺陷报告中提取出来。对每一个报告,结构化信息和非结构化信息一起放入一个文本发明档中。经过预处理,所有缺陷报告的文本被收集起来以形成一个语料库。word2vec用来提取语料库的语义规律。每一个由文本表示的报告被转化成一个单通道矩阵。为了判断两个报告之间的关系,把表示缺陷报告的单通道矩阵组合成表示缺陷报告对的双通道矩阵。然后把一部分作为训练集,剩下的部分作为验证集。在训练阶段,以训练集为输入训练一个cnn模型。在待预测缺陷报告预测阶段,训练好的模型加载预测一个未知缺陷报告与已知缺陷报告组成的缺陷报告对的相似度,这个相似度是一个表示缺陷报告对重复可能性的概率。一种基于双通道卷积神经网络的重复缺陷报告检测方法,包括如下步骤:s100:数据准备s101:提取软件的缺陷报告,所有缺陷报告均由结构化信息和非结构化信息组成,对于每一个缺陷报告,将所有结构化信息和非结构化信息放入一个单独的文本发明档中;结构化信息通常是可选的属性,而非结构化信息通常是bug的文本描述。s102:对于每一个缺陷报告,进行预处理步骤,包括分词、提取词干、去除停用词和大小写转化;本发明使用lucene的standardanalyzer来完成上述预处理步骤。当去除停用词时,使用了一个标准的英文停用词表。此外,即使在两个毫不相关的缺陷报告中,依旧会有一些相同的词。这些词通常是一些专业词汇,例如java、com、org等。由于频繁出现,也把他们加入到停用词表中。经过以上处理,文本中遗留下一些没有意义的数字,它们也被移除。s103:预处理后,所有缺陷报告中的词被组合成一个语料库,在语料库上使用现有的word2vec并选择cbow模型,获得每一个词的向量表示,即得到每个缺陷报告的二维矩阵表示,称为缺陷报告的二维单通道矩阵;根据提取软件的缺陷报告时,该软件缺陷跟踪系统给出的已知信息(这个配对的信息是数据集中的,是由创建数据集的人处理得到的),将两个缺陷报告组成的缺陷报告对通过二维双通道矩阵表示,所述二维双通道矩阵由所述两个缺陷报告对应的二维单通道矩阵组合而成,然后给该双通道矩阵它打上重复或者不重复的标签;与单通道相比,使用缺陷报告对的双通道表示具有以下好处。首先,两个报告可以被cnn同时处理。因此训练速度得以加快。其次,已经被证明,使用双通道数据训练cnn可以达到较高的准确率。对于双通道cnn来说,通过卷积操作,它可以捕捉两个缺陷报告之间的关联关系。将所有打上标签的双通道矩阵,分为训练集和验证集;具体实施时,80%的打上标签的双通道矩阵分为训练集,剩下的20%打上标签的双通道矩阵为验证集。s200:建立cnn模型为了从缺陷报告对中提取特征,本发明在每一个卷积层都设置了三种不同大小的卷积核。因此,第一个卷积层具有三个分支。对于这三个分支中的每一个,在第二个卷积层依然会有三个新得分支。因为这三个分支的结构高度相似,因此图2只展示了cnn整体工作结构中第一个卷积层的一个分支。表3展示了本发明cnn模型的具体参数设置。表3s201:将训练集和验证集中的所有双通道矩阵一起输入cnn模型;s202:在第一个卷积层中,设置个卷积核其中d是卷积核的长度,kw是卷积核的宽度;因为输入矩阵的每一行代表一个词,所以卷积核宽度等于词向量维度m;在第一次卷积后,双通道矩阵的两个通道就合并成一个了,这样,就可以把两个缺陷报告看成一个整体来提取特征,第一层卷积公式为:其中c1表示第一个卷积层的输出,i表示第一个卷积层输入i1的第i个通道,j1表示输入的第j1行,b1表示偏移量,f表示非线性的激活函数,本发明采用的是relu,给定输入的长度l(l=nw),填充值p=0和步长s=1,输出的长度o1可以被计算为:第一个卷积层的输出形状为为了进一步提取两个报告的关联特征,将第一个卷积层的输出形状重塑成然后再卷积,在第二个卷积层,又设置了三种大小的卷积核每种卷积核个,第二层卷积的公式为:其中c2表示第二个卷积层的输出,j2表示第二个卷积层输入i2的第j2行,b2表示偏移量,f2表示非线性的激活函数,本发明使用的是relu,在这次卷积之后,会得到三种形状为的特征图,其中o2可以根据l(l=o1)和不同的卷积核长度d,按照公式(2)计算。s203:对所有的特征图进行最大池化;这样,每个特征图都被下采样为的形状。s204:重塑并拼接所有的特征图以得到一个维的向量,它将被作为全连接层的输入;两个全连接层之后,得到一个独立的概率simpredict,它代表了两个报告被预测的相似度;在最后一层,使用sigmoid作为激活函数得到simpredict;给定第一个全连接层的输出t={x1,x2,…,x300}和权重向量w={w1,w2,…,w300},simpredict可以被计算为:其中i表示t的第i个元素,b表示偏移量。s205:遍历训练集中的所有缺陷报告对,重复s202-s204。s206:根据损失函数进行反向传播以更新模型的隐藏参数,损失函数如公式(5):其中labelreal表示预设的缺陷报告对的标签,i表示第i个缺陷报告对,n表示缺陷报告对的总数。s207:每个epoch训练结束后,使用验证集对模型进行验证;当验证集的损失在5个epoch内都不再降低时,停止更新模型参数;否则返回s201,继续训练cnn模型。s300:待预测缺陷报告预测首先采用s102中的方法对待预测缺陷报告进行预处理,然后采用s103中的方法将该待预测缺陷报告转化为预测缺陷报告的二维单通道矩阵;将预测缺陷报告的二维单通道矩阵与该软件已有的n个缺陷报告的二维单通道矩阵两两组合得到n个待预测双通道矩阵,将n对待预测双通道矩阵构成预测集,将预测集中的每个待预测双通道矩阵作为输入,输入到所述cnn模型中,得到一个概率;当n个概率中,概率大于阈值的则认为该概率所对应的缺陷报告和预测缺陷报告为重复。例如某软件目前有n个缺陷报告,那么经过处理后每个缺陷报告对应一个二维单通道矩阵,将预测缺陷报告对应的待预测二维单通道矩阵与n个二维单通道矩阵任意两两组成,得到n对待预测双通道矩阵,然后将这n对待预测双通道矩阵一个一个的输入上述cnn模型中,得到n个概率。当某一个概率大于预设的阈值时,则认为该概率所对应的待预测缺陷报告和软件中已有的缺陷报告重复。试验验证:1、数据集为了进行对比,本发明采用了和deshmukh等人相同的数据集,这个数据集是由lazar收集和处理的。它包含了三个大型开源项目:openoffice,eclipse和netbeans。openoffice是和microsoftoffice类似的办公软件。eclipse和netbeans是开源集成开发环境。为了用更多的训练样本进行实验,通过合并这三个数据集得到一个更大的数据集,并给它命名为“combined”。这些数据集还提供了缺陷报告配对关系,openoffice中的一部分配对关系如表4所示。表4:缺陷报告对通过分析每个数据集中的所有配对关系,发现其中有一些问题。第一,一些配对是重复的。例如,在openoffice中,(200622,197347,duplicate)出现了5次。第二,一些配对表示的是同一个关系,例如eclipse中的(159435,164827,duplicate)和(164827,159435,duplicate)。因此,本发明将移除这些缺陷报告对。表5展示了最终得到的数据集中所有的配对数量。表5:完整数据集datasetduplicatenonduplicateopenoffice5734041751eclipse86385160917netbeans9506689988combined238791292476每个数据集被分为训练集和测试集,训练集占80%(其中10%作为验证集),测试集占20%。此外,为了让训练集和测试集模拟原始数据集分布,在分割数据集时,使训练集和测试集中重复报告对和非重复报告对比例与原始数据集相同。训练集和测试集都是随机选择的。表6展示了训练集和测试集中缺陷报告对的详细分布。表6:训练集和测试集评估标准在本发明提出的模型中,输出表示一个缺陷报告对中两个报告的相似度。因此,这个值在0到1之间。为了进一步分类,将会设置一个阈值。已经在第三节得到simpredict之后,labelpredict(表示一个缺陷报告对被预测的标签)就可以按照以下公式计算:按照labelpredict和labelreal,报告对可以被分为四类:1)tp:labelreal=1,labelpredict=12)tn:labelreal=0,labelpredict=03)fp:labelreal=0,labelpredict=14)fn:labelreal=1,labelpredict=0其中1表示报告对是重复的,0表示报告对是非重复的。tp表示被正确预测为重复的报告对数量,tn表示被正确预测为非重复的报告对数量,fp表示被错误预测为重复的报告对数量,fn表示被错误预测为非重复的报告对数量。这四个指标是以下评价标准的计算基础。accuracyaccuracy表示被正确预测的缺陷报告对与所有报告对的比值,它表示模型正确分类所有缺陷报告对的性能。因为在进行回归时使用了sigmoid函数,因此在计算accuracy,recall和precision时,阈值设置为0.5。recall:recall表示正确被预测为重复的缺陷报告对与所有实际为重复的缺陷报告对的比值。precision:precision表示正确被预测为重复的缺陷报告对与所有被预测为重复的报告对的比值。f1-score:f1-score是recall和precision的调和平均数。roc曲线:实际上,由于数据集中缺陷报告对类别分布不均衡,传统的评价标准诸如accuracy不能很好地评价分类器的性能。因此,本发明采用roc曲线来进一步评价分类器的性能。根据不同的阈值,可以得到不同的tpr和fpr,然后通过tpr和fpr就可以画出roc曲线。tpr和fpr可以按照以下公式计算:把所有的fpr值作为横轴,所有的tpr值作为纵轴,就可以得到roc曲线。曲线离坐标轴左上角越近,分类器的性能就越好。实验结果通过回答如下几个问题来展现本发明方法的技术效果。问题1:与最先进的基于深度学习的重复缺陷报告检测方法相比,本发明的dc-cnn是否有效?本发明的研究目标是提出一个更有效的基于深度学习的方法。因此,将本发明的方法与deshmukh等人的方法在相同的数据集上进行对比。表7:本发明方法与deshmukh等人方法的实验结果结果:表7展示了本发明方法和deshmukh等人方法的实验结果。使用一个相同的核心方法——孪生神经网络,他们建立了两个相似的模型,检索模型和分类模型。对于分类模型,最高的accuracy出现在openoffice数据集上,达到了0.8275,而在eclipse仅仅只有0.7268。他们的检索模型表现优于分类模型。对于检索模型,表现最好的数据集仍然是openoffice,它的正确率高达0.9455。相同地,eclipse稍逊一筹,accuracy是0.906。可以发现,跟孪生神经网络建立的分类模型相比,dc-cnn在openoffice,eclipse,netbeans,combined上的提升分别是11.54%,24.17%,17.89%和13.33%。和孪生神经网络建立的检索模型相比,dc-cnn在eclipse,netbeans,combined上的提升分别是6.25%,4.07%和3.84%。在openoffice上,dc-cnn的accuracy低了不到0.03%。影响:根据表7,dc-cnn的性能在3个数据集(eclipse,netbeans,combined)上高于deshmukh等人用孪生神经网络构建的分类模型和检索模型。在openoffice上,dc-cnn的性能高于deshmukh等人用孪生神经网络构建的分类模型并且和他们的检索模型有一个非常相似的性能。总体上来说,dc-cnn达到了一个非常好的性能并且超过了目前最先进的基于深度学习的重复报告检测方法。问题2:和sc-cnn相比,dc-cnn是否有效?为了证明本发明提出的缺陷报告对的双通道矩阵表示是有效的,还使用了缺陷报告的单通道矩阵表示来作为一个对比基线。保持cnn的结构不变,包括卷积核的数量,卷积核的大小,卷积层的数量等,并用它分别提取一个缺陷报告对中两个报告的特征,然后计算他们的相似度。这种方法被称为单通道卷积神经网络(single-channelconvolutionalneuralnetworks,sc-cnn)。表8:dc-cnn和sc-cnn实验结果结果:在accuracy,recall,precision,f1-score等指标上评价这两种方法的性能,实验结果如表8所示,其中最好的结果都被加粗了。可以观察到,在所有数据集的所有指标上,dc-cnn都超过了sc-cnn。相比于sc-cnn,在openoffice,eclipse,netbeans,andcombined上,dc-cnn的accuracy分别提高了2.78%,2.61%,1.36%和2.33%,dc-cnn的recall分别提高了2.73%,0.51%,1.49%和3.17%,dc-cnn的precision分别提高了2.08%,6.53%,1.20%和2.08%,dc-cnn的f1-score分别提升了2.40%,3.53%,1.35%和2.62%。图3(a)图3(d)展示了两种方法的roc曲线。可以观察到,在所有的数据集上,dc-cnn的曲线都在sc-cnn之上,这表明即使在样本分布不均衡时,dc-cnn也具有更好的分类性能。影响:所有的实验结果都表明使用双通道的cnn模型比单通道更有效。对于sc-cnn来说。每个报告都被转化为一个矩阵然后输入到cnn中以提取特征,结果被表示为特征向量。然后通过计算两个特征向量的相似度来判断两个报告是否重复。对于dc-cnn来说,两个报告的矩阵被组合成一个双通道矩阵然后输入到cnn,然后这两个报告一起被卷积,这种方法可以提取到两个报告间深层次的关系,充分利用了cnn捕捉局部特征的能力。因为dc-cnn中的cnn模型专注于提取两个报告间的关联关系,所以在检测重复报告时具有更好的性能。问题3:当改变词向量维度时,实验结果如何变化?本发明提出了一种新的缺陷报告对表示方法——双通道矩阵。因此,还探索了与之相关的参数对实验结果的影响。对于双通道矩阵来说,因为词的数量数固定的并且对于cnn来说,两个报告的位置(哪个报告在第一个通道,哪个报告在第二个通道)是无差别的,所以最可能发生改变的参数是词向量的维度。为了回答当改变词向量维度时,实验结果如何变化这个问题,逐渐将词向量维度从10改变到100并观察实验结果在openoffice数据集上的变化。结果:从图4可以看出,当逐渐增大词向量维度时,accuracy先增大然后呈现出下降趋势。当词向量维度为20时,准确率达到了最大值,94.29%。影响:当词向量维度从10增加到20时,accuracy增大了。当我们继续增大词向量维度,accuracy降低了。原因可能是,当一个词向量维度已经足够表征一个词时。继续增大维度反而使其不能很好地表示这个词。虽然当词向量维度等于20时,accuracy达到了最大值,但是它并没有比其他条件下的值高出太多。一方面,词向量维度增大会带来更大的数据存储问题;另一方面,词嵌入和cnn模型训练时的复杂度都会增大。因此,在本发明方法中,20是最合适的词向量维度。问题4:当不采用结构化信息时,本发明提出的方法是否有效?例如product,component和version等结构化信息在判断两个报告是否重复时提供了非常有用的信息。许多方法将结构化信息作为一个单独的特征来提高重复缺陷报告检测的准确性。非结构化信息通常是对bug的自然语言描述。对于重复报告检测来说,cnn主要用来处理非结构化文本,因此它在处理长文本时具有很好的性能。不同于其他方法,本发明同时把结构化信息和非结构化信息作为文本数据放入文本发明档中。然后用cnn来提取它们的特征。为了回答问题4,将结构化信息从输入中移除,并在不改变其他条件时,设置对比实验。结果:从图5可以看出,移除结构化信息后,所有数据集上的实验结果都降低了,在openoffice,eclipse,netbeans,combined上分别是1.74%,3.79%,3.38%,2.56%。影响:实验结果表明将结构化信息和非结构化信息一起输入到cnn中是有效的。注意到在移除结构化信息之后,尽管accuracy下降了,但是这种降低并不是致命的。原因是结构化信息仅仅只占了整个文本的一小部分。cnn主要处理的部分仍然是非结构化信息。最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1