一种基于FPGA的NVMe设备存储速度提升方法与流程
本发明涉及数据存储技术领域,具体为一种基于fpga的nvme设备存储速度提升方法。
背景技术:
随着相控阵雷达的性能不断提升,其产生的数据量也越来越大。在雷达测试领域,需要高速存储设备来存储雷达接收的原始回波信号,以便于后续的数据分析及整机功能验证。高性能的雷达对存储设备的速度、容量等性能提出了挑战,同时外场、机载的应用场景对存储设备的体积和功耗也提出了要求。
nvmessd是近几年来出现的新一代存储设备,借助pcie总线的高传输速度,可以实现1gb/s以上的数据存储速度。利用fpga配合nvmessd可以构建适用于雷达测试领域的便携式高速数据存储设备。fpga控制nvmessd的核心技术是nvme控制软件的编写,包括流程控制、数据传输等,其中数据传输模块的设计直接关系到设备的数据存储速度。
当前存储设备的速度主要受限于数据包发送的耗时,因此提升数据包的发送速度已被越来越多的人们所关注。
技术实现要素:
本发明是为了解决现有技术中由于数据包发送时耗时较长,导致nvme存储设备存储速度慢的问题,提供一种基于fpga的nvme设备存储速度提升方法。
本发明为了解决上述技术问题采取的技术方案是:一种基于fpga的nvme设备存储速度提升方法,包括以下步骤:
步骤一:nvmessd向fpga发送读内存请求;
步骤二:nvmessd获取fpga回复的完成报文:
步骤二一:流程控制模块向数据发送模块发送传输信号;
步骤二二:数据发送模块根据接收到的数据包类型进行数据包封装和发送;
步骤二三:数据包通过axi-stream总线传输给pcie硬核,最终数据传输给nvmessd;
步骤三:nvmessd从完成报文中提取待存储数据。
进一步的,所述数据发送模块为数据包发送状态机。
进一步的,所述数据包发送状态机的状态包含:空闲状态、等待总线空闲状态、判断tlp传输数量状态和发送状态。
进一步的,所述数据包发送状态机的状态之间的转换关系为:
当状态机处于空闲状态时,判断是否接收到开始发送信号,若是,跳转至等待总线空闲状态,若否,停留在当前状态;
当状态机处于等待总线空闲状态时,获取要发送的数据载荷,同时判断axi-stream总线是否空闲,若是,跳转至判断tlp传输数量状态,若否,停留在当前状态;
当状态机处于判断tlp传输数量状态时,判断要发送的tlp是否为完成报文且包含待存储的数据,若是,tlp传输数量为2,若否,tlp传输数量为1,然后跳转至发送状态;
当状态机处于发送状态时,通过axi-stream总线向pcie硬核连续发送相应数量的tlp,并判断发送是否完成,若是,跳转至空闲状态,若否,停留在当前状态。
进一步的,所述数据包发送状态机内还设有数据包发送子状态机。
进一步的,所述数据包发送子状态机的状态包含:空闲状态、发送tlp包头状态、发送数据包的数据载荷状态、判断当前发送tlp数量状态和发送完成状态。
进一步的,所述数据包发送子状态机的状态之间的转换关系为:
当子状态机处于空闲状态时,判断数据包发送状态机是否处于发送状态,若是,跳转至发送tlp包头状态,若不是,停留在当前状态;
当子状态机处于发送tlp包头状态时,数据发送模块通过axi-stream总线将tlp的包头发送给pcie硬核,同时记录当前发送的tlp数量,跳转至发送数据包的数据载荷状态;
当子状态机处于发送数据包的数据载荷状态时,数据发送模块通过axi-stream总线将数据包的数据载荷发送给pcie硬核,并判断当前数据包的数据载荷是否即将发送完成,若是,跳转至判断当前发送tlp数量状态,若不是,停留在当前状态继续发送数据载荷;
当子状态机处于判断当前发送tlp数量状态时,发送当前tlp的最后一个时钟周期对应的数据载荷,同时判断当前发送的tlp数量与应发送的tlp数量是否相等,若是,跳转至发送完成状态,若不是,跳转至发送tlp包头状态,继续发送tlp。
当子状态机处于发送完成状态时,向数据包发送状态机发送完成信号,然后跳转至空闲状态。
进一步的,所述步骤二三中数据包在pcie硬核中经过数据链路层和物理层的处理。
本发明的有益效果是:
1、本发明数据发送模块在保证数据包长度最大的情况下,利用半背靠背的tlp发送策略,提高pcie总线的利用效率,以满足存储设备的数据写入速度需求,同时为设备后续升级留有速度余量。本发明中的半背靠背发送策略与普通发送策略相比可以提升22%的数据传输速度。
2、本发明采用不同读请求对应的完成报文之间保留5个时钟周期的发送间隔,用于执行判断、赋值、读取缓存等步骤,为流程中的其他步骤留出足够的执行时间,为设备后续升级留有足够的速度余量,提高了设计的可靠性,降低了开发难度。
附图说明
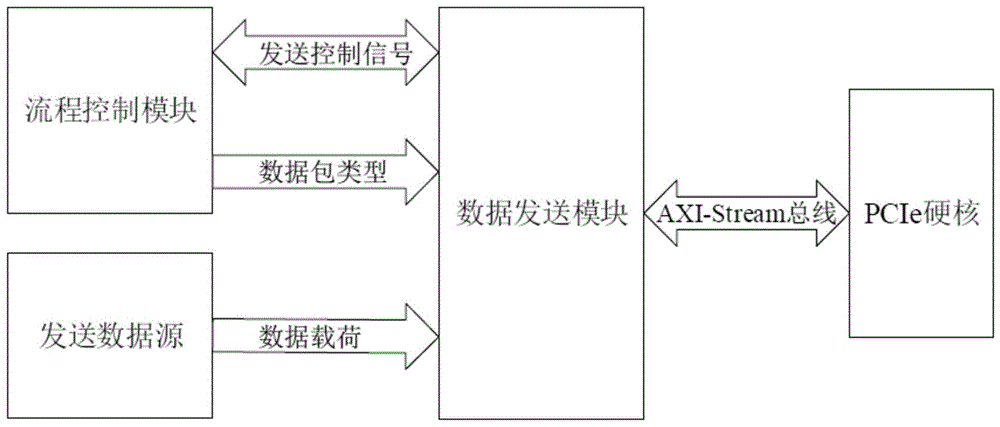
图1为本发明pcie数据包发送模块的接口互联框图。
图2为本发明的数据发送状态转换图。
图3为本发明的fpga发送数据时axi-stream接口波形图。
图4为本发明的数据发送子状态机的状态转换图。
具体实施方式
具体实施方式一:下面具体说明本实施方式,本实施方式,一种基于fpga的nvme设备存储速度提升方法,包括以下步骤:
步骤一:nvmessd向fpga发送读内存请求;
步骤二:nvmessd获取fpga回复的完成报文;
步骤二一:流程控制模块向数据发送模块发送传输信号;
步骤二二:数据发送模块根据接收到的数据包类型进行数据包封装和发送;
步骤二三:数据包通过axi-stream总线传输给pcie硬核,最终数据传输给nvmessd;
步骤三:nvmessd从完成报文中提取待存储数据。
fpga-nvme存储设备由光纤数据接口模块、fpga和nvmessd组成,其中fpga实现接口互联和对nvmessd的控制(包括生成读写命令、进行数据传输等)。利用fpga控制nvmessd的核心技术是nvme控制软件的编写,包括流程控制、数据传输等,其中数据传输模块的设计直接关系到设备的数据存储速度。
fpga与nvmessd借助pcie总线进行数据传输,其数据包由物理层、数据链路层和事务层三部分组成。xilinxfpga集成的pcie硬核提供现成的物理层和数据链路层实现功能,并通过axi-stream接口与用户逻辑进行数据交互。用户逻辑按照固定的时序和格式,通过axi-stream接口向pcie硬核发送pcie事务层数据包(tlp)即可实现pcie数据包的发送。
与发送tlp相关的模块包括流程控制模块、发送数据源、数据发送模块和pcie硬核,这些模块的接口互联框图如图1所示。数据发送模块接收流程控制模块的开始发送信号后,根据接收到的数据包类型进行数据包封装和发送,数据包通过axi-stream总线传输给pcie硬核,在pcie硬核中经过数据链路层和物理层的处理,最终将数据传输给nvmessd。
nvmessd获取来自fpga的待存储数据的过程如下:
(1)nvmessd向fpga发送读内存请求,
(2)nvmessd获取fpga回复的完成报文(completiontlp),
(3)nvmessd从完成报文中提取待存储数据。
读取存储设备中nvmessd的pcie配置寄存器中的max_payload_size(mps)字段,可知该nvmessd可以接收的tlp的最大数据载荷为128byte。由于nvmessd发送的每个读请求申请读取的数据长度为256byte,而每个完成报文的最大有效数据载荷为128byte,因此需要发送两个完成报文才能完成一个读请求的回复。考虑到tlp包头、物理层和数据链路层的开销,计算出本发明中pcie总线的最大数据传输效率为128/(128+12+8)=86%,该效率是一个理想的值。由于tlp的传输存在间隔,因此实际工程应用中的pcie数据链路传输效率低于86%。
为了满足设备1gb/s的存储速度需求,必须保证fpga发送完成报文的速度足够快,以保证发送数据载荷的速度大于1gb/s。结合数据发送模块可以看出,只要能提高axi-stream总线的利用效率就能提高fpga发送数据包的速度。本发明采用以下两种方法提高fpga发送数据包的速度:
1、保证tlp数据载荷为最大(128byte);
2、缩短fpga发送tlp的间隔。
具体实施方式二:本实施方式是对具体实施方式一所述的一种基于fpga的nvme设备存储速度提升方法的进一步改进,本实施方式与具体实施方式一的区别是所述数据发送模块为数据包发送状态机。
具体实施方式三:本实施方式是对具体实施方式二所述的一种基于fpga的nvme设备存储速度提升方法的进一步改进,本实施方式与具体实施方式二的区别是所述数据包发送状态机包含子状态:空闲状态、等待总线空闲状态、判断tlp传输数量状态和发送状态。
具体实施方式四:本实施方式是对具体实施方式三所述的一种基于fpga的nvme设备存储速度提升方法的进一步改进,本实施方式与具体实施方式三的区别是所述数据包发送状态机的状态之间的转换关系为:
当状态机处于空闲状态时,判断是否接收到开始发送信号,若是,跳转至等待总线空闲状态,若否,停留在当前状态;
当状态机处于等待总线空闲状态时,获取要发送的数据载荷,同时判断axi-stream总线是否空闲,若是,跳转至判断tlp传输数量状态,若否,停留在当前状态;
当状态机处于判断tlp传输数量状态时,判断要发送的tlp是否为完成报文且包含待存储的数据,若是,tlp传输数量为2,若否,tlp传输数量为1,然后跳转至发送状态;
当状态机处于发送状态时,通过axi-stream总线向pcie硬核连续发送相应数量的tlp,并判断发送是否完成,若是,跳转至空闲状态,若否,停留在当前状态。
如图4所示,图4中发送状态机的状态一至四分别对应空闲状态、等待总线空闲状态、判断tlp传输数量状态和发送状态。
具体实施方式五:本实施方式是对具体实施方式四所述的一种基于fpga的nvme设备存储速度提升方法的进一步改进,本实施方式与具体实施方式四的区别是所述数据包发送状态机内还设有数据包发送子状态机。
具体实施方式六:本实施方式是对具体实施方式五所述的一种基于fpga的nvme设备存储速度提升方法的进一步改进,本实施方式与具体实施方式五的区别是所述数据包发送子状态机的状态包含:空闲状态、发送tlp包头状态、发送数据包的数据载荷状态、判断当前发送tlp数量状态和发送完成状态。
具体实施方式七:本实施方式是对具体实施方式六所述的一种基于fpga的nvme设备存储速度提升方法的进一步改进,本实施方式与具体实施方式六的区别是所述数据包发送子状态机的状态之间的转换关系为:
当子状态机处于空闲状态时,判断数据包发送状态机是否处于发送状态,若是,跳转至发送tlp包头状态,若不是,停留在当前状态;
当子状态机处于发送tlp包头状态时,数据发送模块通过axi-stream总线将tlp的包头发送给pcie硬核,同时记录当前发送的tlp数量,跳转至发送数据包的数据载荷状态;
当子状态机处于发送数据包的数据载荷状态时,数据发送模块通过axi-stream总线将数据包的数据载荷发送给pcie硬核,并判断当前数据包的数据载荷是否即将发送完成,若是,跳转至判断当前发送tlp数量状态,若不是,停留在当前状态继续发送数据载荷;
当子状态机处于判断当前发送tlp数量状态时,发送当前tlp的最后一个时钟周期对应的数据载荷,同时判断当前发送的tlp数量与应发送的tlp数量是否相等,若是,跳转至发送完成状态,若不是,跳转至发送tlp包头状态,继续发送tlp。
当子状态机处于发送完成状态时,向数据包发送状态机发送完成信号,然后跳转至空闲状态。
在以上状态机中,空闲状态、发送tlp包头状态和发送数据包的数据载荷状态是简单的等待和判断状态,而判断当前发送tlp数量状态是数据包发送状态,其中包含了许多的子状态。本实施方式设计了一个发送总状态机处于判断当前发送tlp数量状态下的数据发送子状态机,如图3所示。
从发送子状态机中可以看出,这些tlp包是连续发送的,在前一个tlp发送完成后,紧接着的下一个时钟周期新的tlp包就开始发送了,这种连续的发送方式为背靠背发送。结合数据发送总状态机分析,从总状态机的空闲状态到发送状态之间间隔若干时钟周期,用于等待总线空闲和准备发送所需的数据载荷和参数,每一组tlp包的发送都是有间隔的。本发明将这种同一组数据包连续发送、不同组数据包间断发送的发送方式称为半背靠背传输。
本发明采用半背靠背的模式发送tlp,fpga发送数据时axi-stream接口波形如图3所示。
图3中每个tlp从txvalid置1时开始,至txlast为1时结束;当txlast置0且txvalid为1时,开始一个新的tlp。从图中可以看出,同一个读请求对应的两个完成报文背靠背传输,每两个背靠背的tlp发送占用18个时钟周期;不同的读请求对应的完成报文之间间隔5个时钟周期发送,这5个空闲的时钟周期用于判断、赋值以及读取数据fifo缓存等步骤的执行。
为了得到以上设计的可到达的数据传输速度,对数据发送过程中的数据链路进行分析:
(1)128比特位宽、125mhz时钟频率的axi-stream总线有效数据传输速率为2gb/s,根据图3计算出有效数据载荷传输速度为1.391gb/s;
(2)8b/10b编码的pciegen2x4总线最大有效数据速度为2gb/s;
(3)在1.391gb/s的速度下,pcie总线空闲的速度资源还有很多,pcie数据包的物理层和数据链路层开销不会影响到pcie总线的数据传输效率。
可以推断,基于pciegen2x4高速串行总线,这种半背靠背的数据传输速度在理论上可以达到1.391gb/s,设计裕量为0.391gb/s。结合nvme协议的其他开销,nvmessd的持续数据写入速度可以保证在1.2gb/s以上,能够满足存储设备的速度需求。若不使用半背靠背传输,则每个完成报文的数据包之间都会有5个时钟周期的间隔,那么数据传输速度理论上就只有1.14gb/s,设计裕量仅为0.14gb/s。考虑到nvme协议的其他开销,则实现1gb/s的数据存储速度非常勉强。
具体实施方式八:本实施方式是对具体实施方式一所述的一种基于fpga的nvme设备存储速度提升方法的进一步改进,本实施方式与具体实施方式一的区别是所述步骤二三中数据包在pcie硬核中经过数据链路层和物理层的处理。
需要注意的是,具体实施方式仅仅是对本发明技术方案的解释和说明,不能以此限定权利保护范围。凡根据本发明权利要求书和说明书所做的仅仅是局部改变的,仍应落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!