一种基于分组向量的哈希多表连接实现方法与流程
本发明涉及一种基于分组向量的哈希多表连接实现方法,特别是关于一种面向OLAP应用中数据分布特征而优化设计的多表连接方法。
背景技术:
分析型SQL查询中主要包括选择、投影、连接、分组、聚集操作,在OLAP应用中,查询通常表示为在维表上按给定的选择条件投影出GROUP-BY属性,与事实表外键连接后对事实表度量列的指定属性执行分组聚集计算。传统关系数据库的查询树中选择和投影操作被下推到底层表节点,然后按查询树路径依次执行连接操作,迭代生成连接结果记录,并对连接结果记录进行哈希分组聚集计算。例如下面SQL查询命令执行过程如图1所示:
select sum(lo_revenue),C_nation,S_nation from lineorder,customer,supplier
where l_CK=C_custkey
and l_SK=S_suppkey
and C_region=’AMERICA’
and S_region=’ASIA’
group by C_nation,S_nation;
SQL命令中的where子句在customer和supplier表中选择出满足条件的记录并投影出GROUP-BY属性和相应的连接属性,然后创建相应的哈希表用于连接操作。SQL命令中事实表投影出相应的属性并依次与customer表和supplier表执行连接操作,生成带有GROUP-BY分组属性和聚集属性的连接记录,最后通过哈希分组操作进行聚集计算。
传统的迭代流水查询处理模型在OLAP查询处理时存在的主要缺点如下:
1.事实表记录依次执行与customer表产生的哈希表的连接操作,满足第一个连接条件的记录再与supplier表产生的哈希表连接,满足全部连接条件的记录才参与最终的哈希分组聚集计算。在连接阶段只有事实表外键属性参与计算,分组和度量属性在查询树之间传输但在不满足连接条件时记录被抛弃产生无效的数据传输代价。连接表的数量越多、选择率越低则所产生的无效数据传输代价越大。
2.在哈希分组聚集计算阶段,由于维表与事实表记录之间的一对多关系,GROUP-BY属性上的哈希分组产生大量重复的哈希计算代价,当GROUP-BY属性为较长的字符型数据时哈希计算代价较高。
3.在异构存储与计算平台,维表、事实表外键列、事实表度量列由于数据量存在较大的差异可能存储在不同的平台上,基于查询树的流水处理模型需要访问三个不同数据集的数据才能完成完整的查询处理任务,异构平台之间的数据通道传输延迟增加了流水处理各阶段之间的处理延迟。
技术实现要素:
针对上述问题,本发明的目的是提供一种基于分组向量的哈希多表连接实现方法,通过基于向量索引的后物化技术将连接与聚集计算划分为两个独立的计算阶段,在聚集计算阶段采用最优的、基于GROUP-BY属性的分组向量聚集计算技术,在连接阶段创建支持分组向量聚集计算的向量索引,通过向量索引实现基于大粒度连接和聚集计算负载之间的异步流水处理。
为实现上述目的,本发明采取以下技术方案:一种基于分组向量的哈希多表连接实现方法,其包括以下步骤:
1)对SQL查询命令进行改写,将一个完整的SQL查询命令划分为选择-投影-分组-连接操作和聚集操作两个子任务;
2)选择-投影-分组-连接操作子任务用于创建生成SQL查询命令中GROUP-BY语句对应的分组向量,并创建向量索引作为选择-投影-分组-连接操作子任务的输出结果;
3)聚集操作子任务执行基于向量索引的聚集计算,并将聚集计算结果存储在与分组向量等长的分组向量聚集器对应的单元中;
4)将分组向量聚集器中的聚集计算结果与步骤2)创建的分组向量合并,作为SQL查询命令的结果集输出。
进一步的,所述步骤1)中,所述选择-投影-分组-连接操作子任务中,选择、投影、分组操作作用在维表上,用于创建连接操作的维表哈希表;连接操作执行事实表外键列与所述维表哈希表之间的多表连接操作,并生成向量索引作为连接操作的输出结果;所述聚集操作子任务执行事实表度量列上基于所述向量索引的聚集计算任务,得到聚集计算结果。
进一步的,所述步骤2)中,所述向量索引是一个与分组聚集计算表等长的向量数据结构,所述向量索引中空值单元表示该单元对应的表中的记录不参与分组聚集计算,非空单元则表示该单元对应的表中的记录参与分组聚集计算;所述向量索引的单元值参照所述分组向量,所述分组向量对应GROUP-BY语句产生的分组属性集合,所述分组属性集合中的每个分组属性成员对应一个分组向量单元,分组属性成员ID设置为所述分组向量的下标地址,所述向量索引的非空单元中记录对应的分组向量单元地址,通过所述向量索引的单元值直接映射到分组向量对应的单元进行聚集计算。
进一步的,所述步骤2)中,创建所述向量索引的连接操作包括三种实现方法:哈希预分组连接方法、基于多维分组映射的连接方法以及基于稀疏多维数组压缩的连接方法。
进一步的,所述哈希预分组连接方法包括以下步骤:执行哈希多表连接操作后,为生成的连接记录的GROUP-BY分组属性创建哈希表,并执行哈希分组操作;创建一个全局序列生成器,从0开始以步长为1递增,为向量索引分配唯一的分组向量ID;对每一个生成的连接记录的GROUP-BY分组属性进行哈希探测,并根据哈希探测结果创建向量索引,具体的:如果哈希表中未探测到相同的GROUP-BY分组属性值,则创建哈希记录,从全局序列生成器中获得当前序列生成器值作为当前分组属性值的ID,然后序列生成器值增加1,并将分组属性值写入当前分组属性值ID对应的分组向量相应的单元中,同时将该分组属性值ID写入向量索引中对应位置的单元中,或者将记录位置ID和分组属性值ID追加到压缩向量索引中;如果哈希表中探测到相同的GROUP-BY分组属性值时,则将该哈希记录的分组属性值ID存储于向量索引对应的单元,或者将记录位置ID和分组属性值ID追加到压缩向量索引中;其中,在获得序列生成器当前值时利用latch对序列值加锁,序列生成器值增加1后释放latch锁。
进一步的,所述基于多维分组映射的连接方法,包括以下步骤:对维表进行选择、投影、分组操作后,对投影出来的分组属性值进行动态字典表压缩,将分组属性映射为一个字典向量,字典向量下标作为该维表上的分组属性ID,当维表上有多个分组属性时,每一个分组属性组合值映射为一个向量单元,得到存储有维记录主键值和分组ID的维表哈希表;执行事实表外键列与维表哈希表之间的多表连接操作,得到多个维表分组ID组合值,将多个维表分组ID映射为一个多维数组,每个维表分组ID代表多维数组一个维上的下标,多表连接结果对应一个多维数组地址;将多维数组进一步映射为一维向量,多维数组地址转换为一维向量下标,得到向量索引,将连接结果记录在所述向量索引中。
进一步的,所述基于稀疏多维数组压缩的连接方法,包括以下步骤:对维表进行选择、投影、分组操作后,对投影出来的分组属性值进行动态字典表压缩,将分组属性映射为一个字典向量,字典向量下标作为该维表上的分组属性ID,当维表上有多个分组属性时,每一个分组属性组合值映射为一个向量单元,得到存储有维记录主键值和分组ID的维表哈希表;执行事实表外键列与维表哈希表之间的多表连接操作,得到多个维表分组ID组合值,将多个维表分组ID映射为一个多维数组,每个维表分组ID代表多维数组一个维上的下标,多表连接结果对应一个多维数组地址;将连接阶段生成的多维数组映射为一维稀疏的分组向量,并根据所述一维稀疏的分组向量创建稠密的分组向量,即在映射时使用序列生成器为每一个非空向量单元分配唯一序列;最后,基于稠密的分组向量创建向量索引,用于事实表度量数据列上的聚集计算操作。
进一步的,所述步骤3)中,采用基于向量索引的多核并行聚集计算方法,具体实现方法为:若向量索引为定长向量,则按线程数量逻辑划分向量索引分区,并按相同的位置逻辑划分事实数据分区,每个线程并行扫描向量索引分区并执行在对应事实数据分区上的向量聚集操作;若向量索引为压缩格式,则采用在压缩向量索引中均衡逻辑分区的方法,按压缩向量索引分区扫描事实表数据分区进行聚集计算,简化逻辑分区的位置计算并使各线程对应逻辑分区上的聚集计算代价均衡。
进一步的,在并行向量分组聚集操作执行时,采用两种聚集计算方法:一是每个线程使用私有分组向量完成本线程逻辑事实数据分区上的分组聚集计算操作,各线程处理完毕后执行线程间分组向量的归并计算,生成最终的全局分组向量;二是多线程共享统一的分组向量,执行基于并发控制机制的全局分组聚集计算,且当分组向量的大小超过超过最优阈值时,采用全局分组聚集计算方法,当分组向量的大小不超过最优阈值时,采用私有分组向量聚集计算方法,其中,最优阈值为CPU线程每核心最后一级cache单元大小的75%。
进一步的,所述步骤4)中,将分组向量聚集器中的聚集计算结果与连接操作子任务创建的分组向量元数据合并的方法为:当采用哈希预分组连接方法时:将分组向量聚集器单元的地址映射到连接阶段的分组向量中获取地址所映射的GROUP-BY属性值,与分组向量聚集器中存储的聚集计算结果合并,作为SQL查询命令的输出结果;
当采用基于多维分组映射的连接方法时,将分组向量聚集器单元的地址映射为多维数组地址,然后分别访问相应维表分组向量并解析出其对应的GROUP-BY属性值,合并而成SQL查询命令的输出结果;
当采用稀疏多维数组压缩的连接方法时,将分组向量非空单元根据向量地址转换为多维数组下标,将各下标值映射到各维表字典表向量,访问各GROUP-BY属性值,同时根据分组向量单元存储的分组向量聚集器地址值访问分组向量聚集器单元中的聚集计算结果,生成SQL查询命令的输出结果。
本发明由于采取以上技术方案,其具有以下优点:1、在OLAP应用中,事实表度量数据量极大,而连接外键列大小由模式决定,数据量相对较小。本发明通过向量索引将连接与聚集计算划分为两个独立的计算过程,庞大的事实表度量数据可以单独存储,并基于向量索引完成聚集计算,而在聚集计算阶段无法获得查询的具体语义,也不能对聚集计算结果进行语义解析,从而使事实表度量数据的存储(无语义的数值型数据)和计算(无语义的数值型计算)具有更高的安全性,减少企业数据信息的安全隐患。2、本发明通过连接操作与聚集计算操作的解耦合来提高聚集计算的独立性,当使用异构计算平台时可以将连接操作与聚集计算操作优化分布在不同的存储与计算平台,使操作的特性与计算的特性得到最优匹配。因此,本发明可以广泛应用于OLAP数据查询领域。
附图说明
图1是传统的迭代流水查询处理模型中SQL查询命令执行过程;
图2是向量索引的数据结构示意图;
图3是本发明哈希预分组连接方法执行案例;
图4是本发明基于多维分组映射的连接方法实例;
图5是本发明基于稀疏多维数组压缩的连接方法的应用示例;
图6是本发明采用私有分组向量方法完成全局分组聚集计算操作的示意图;
图7是本发明采用多线程共享统一的分组向量方法完成全局分组聚集计算操作的示意图。
具体实施方式
下面结合附图和实施例对本发明进行详细的描述。
本发明经过对传统OLAP查询处理过程进行分析后发现,提高查询性能可以从以下几个方面进行优化:
1.执行后物化连接策略,即首先执行事实表外键属性列上的多表连接操作,获得最终的多表连接结果后再执行事实表度量属性上的聚集计算,一方面消除维表分组属性和事实表度量属性在查询树上的无效数据传输,另一方面也可消除事实表度量属性进行聚集计算时与其他数据之间的耦合性;
2.为GROUP-BY属性设置映射表,以分组向量数据结构存储查询GROUP-BY属性的最终分组值,以分组向量单元作为聚集计算的聚集器,以分组向量替代哈希表,以分组向量地址访问代替哈希探测,减少哈希分组计算代价;
3.连接阶段输出为满足连接条件事实表记录ID和分组向量单元地址,实现在连接阶段的预分组操作,从而在聚集计算阶段可以实现高效的按事实表记录ID位置访问事实表度量属性并直接执行基于分组向量的聚集计算;
4.通过动态字典表压缩和多维数组地址映射机制优化字符型GROUP-BY属性的哈希分组计算代价;
5.连接与聚集计算的中介是物化的向量索引,消除了传统查询处理时记录之间的强关联关系,从而支持连接与聚集计算分布在不同的计算平台,支持面向数据大小及计算特征的优化分布策略。
通过将OLAP查询处理中的分组与聚集操作解耦合的方法在多表连接阶段完成预分组,分组以向量结构存储,连接操作中预分组的结果存储在向量索引中,向量索引中非空单元为连接记录对应的分组在分组向量中的下标地址,庞大的事实表可以基于向量索引直接执行聚集计算,聚集计算结果存储在分组向量聚集器中,最后通过向量解析生成OLAP查询结果集。本发明一方面优化了OLAP查询处理性能,另一方面使多表连接操作和聚集计算成为两个独立的计算过程,使连接操作成为基于较小连接列上的计算密集型负载,而聚集计算则成为基于较大数据集上的数据密集型负载,从而使两种不同存储和计算特征的负载更易于在不同存储容量与计算能力的异构处理器进行优化配置。
综上所述,本发明提供的一种基于分组向量的哈希多表连接实现方法,其包括以下步骤:
1)对SQL查询命令进行改写,将一个完整的SQL查询命令划分为“选择-投影-分组-连接”操作(以下简称连接操作)和聚集操作两个子任务;
2)连接操作子任务用于创建生成SQL查询命令中GROUP-BY语句对应的分组向量,并创建向量索引作为连接操作子任务的输出结果;
3)聚集操作子任务执行基于向量索引的聚集计算,并将聚集计算结果存储在与分组向量等长的分组向量聚集器对应的单元中;
4)将分组向量聚集器中的聚集计算结果与连接操作子任务创建的分组向量合并,作为SQL查询命令的结果集输出。
上述步骤1)中,“选择、投影、分组”操作作用在维表上,并创建“连接”操作阶段的哈希表结构,“连接”操作执行事实表外键列与维表哈希表之间的多表连接操作,生成向量索引作为连接操作子任务的输出结果;聚集操作子任务执行事实表度量列上基于向量索引的聚集计算任务,即执行select VecInx,sum(…)from FactTable FT group by VecInx;类型的聚集计算,其中VecInx代表“选择、投影、分组、连接”操作子任务所创建的向量索引列。
上述步骤2)中,向量索引是一种用于分组聚集计算的索引结构。如图2所示,向量索引是一个与分组聚集计算表(如lineorder)等长的向量数据结构,向量索引中空值单元表示该单元对应的表中的记录不参与分组聚集计算,非空单元则表示该单元对应的表中的记录参与分组聚集计算;向量索引单元值参照分组向量,分组向量对应GROUP-BY语句产生的分组属性集合,分组属性集合中的每个分组属性成员对应一个分组向量单元,分组向量单元的ID值设置为分组向量下标地址,向量索引非空单元中记录对应的分组向量单元地址(即分组向量单元的ID值),通过向量索引单元值直接映射到分组向量对应的单元进行聚集计算。优选的,当向量索引中空值单元较多时可以采用压缩向量索引结构,即,将定长的向量索引转换为变长的[FID,GID]二元组序列,FID对应分组聚集计算表的记录位置ID,GID为分组向量ID,通过压缩存储消除向量索引中过多空值单元带来的存储及访问代价。
上述步骤2)中,生成向量索引的连接操作可以采用三种实现方法:
①哈希预分组连接方法
哈希预分组连接方法中,只有事实表外键列和维表参与连接操作。
执行常规的哈希多表连接操作后,为生成的连接记录的GROUP-BY分组属性创建哈希表,执行哈希分组操作;创建一个全局序列生成器,从0开始以步长为1递增,为向量索引分配唯一的分组向量ID;对分组向量中每一个生成的连接记录的GROUP-BY分组属性进行哈希探测,如果哈希表中未探测到相同的分组属性值,则创建哈希记录,从全局序列生成器中获得当前全局序列生成器的ID值作为当前分组值的ID,序列生成器值增加1,并将分组属性值写入当前分组属性值ID对应的分组向量相应的单元中,同时将该分组属性值ID写入向量索引中对应位置的单元中,或者将事实记录位置ID和分组属性值ID追加到压缩向量索引中;当连接记录在哈希探测时找到相同的GROUP-BY分组属性时,将该哈希记录的分组属性值对应的ID存储于向量索引对应的单元或在压缩向量索引中增加一个事实记录位置ID和该分组属性值ID二元组记录;其中,在获取序列生成器当前值时需要利用latch对序列值加锁,值增加1后释放latch锁,以保证序列分配的唯一性。
连接操作执行完毕后,获得一个向量索引和一个记录GROUP-BY分组属性值和位置对应关系的分组向量。
该方法将传统的连接操作分解为连接分组和聚集计算两个阶段,在多表连接阶段为GROUP-BY属性创建分组向量,为聚集计算创建向量索引,使后续的聚集计算可以独立执行。同时,基于分组向量ID的聚集计算屏蔽了查询的分组属性语义,使事实表上执行的聚集计算消除了查询语义,有利于对用户查询语义的保护。
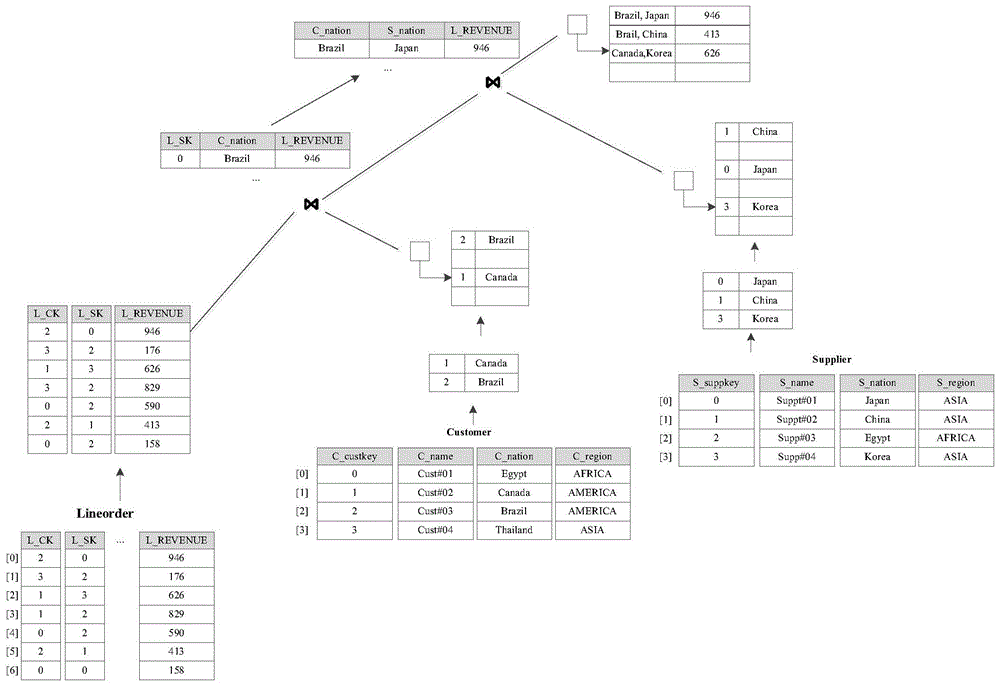
如图3所示,显示了哈希预分组连接方法执行案例。以下面SQL查询命令为例:
select sum(lo_revenue),C_nation,S_nation from lineorder,customer,supplier
where l_CK=C_custkey
and l_SK=S_suppkey
and C_region=’AMERICA’
and S_rgion=’ASIA’
group by C_nation,S_nation;
根据SQL查询命令,lineorder表投影出L_CK,L_SK列执行查询处理,记录中包含记录的位置ID,如列存储中的列下标;customer表基于条件C_region=’AMERICA’过滤后,投影出主键列c_custkey和分组属性列c_nation,并基于主键列c_custkey创建连接哈希表;supplier表基于条件S_rgion=’ASIA’过滤后,投影出主键列s_suppkey和分组属性列s_nation,并基于主键列s_suppkey创建连接哈希表。
Lineorder表记录执行与customer表和supplier表连接哈希表上的哈希连接操作后,生成带有lineorder记录ID的连接结果,为连接结果中的GROUP-BY属性值创建分组向量,将GROUP-BY属性值映射到一个数组分组向量中。创建一个全局序列生成器,该全局序列生成器为一个步长为1增长的序列,作为查询的分组ID。初始值为0,通过latch数据结构在读取时加锁,分配当前值给申请的哈希记录,然后序列值增加1后解除锁定,以保证每个序列值唯一分配。在多表连接的最后阶段,为GROUP-BY属性创建哈希表,每个GROUP-BY属性值在哈希表中第一次创建时从全局序列生成器获得当前序列值写入哈希记录,如记录(Brazil,Japan)首次访问时获得序列生成器值0并写入哈希表,同时并将该GROUP-BY属性值(Brazil,Japan)写入当前序列值对应的分组向量单元[0]中。同时,分组向量单元地址[0]记入与事实表等长的向量索引中,向量索引下标对应事实记录ID,向量索引单元记录该GROUP-BY属性在分组向量中的下标值[0]。当连接选择率较低时,向量索引采用压缩格式,通过二元组[FID,GID]记录非空向量索引单元的事实记录ID和分组ID[0,0]。
②基于多维分组映射的连接方法
本发明进一步将预分组从连接末端下推到维表访问阶段,基于多维数组创建分组向量。
为进一步优化各连接阶段中对字符型GROUP-BY属性重复哈希计算的代价,对维表GROUP-BY属性采用压缩编码技术。
在维表处理阶段(即基于“选择、投影、分组”操作创建哈希表的阶段),将过滤后投影出来的分组属性值进行动态字典表压缩,将分组属性映射为一个字典向量,字典向量下标作为该维表上的分组属性ID,当维表上有多个分组属性时,将每一个分组属性组合值映射为一个向量单元。维表哈希表存储的是维记录主键值和分组属性ID。连接结果为多个维表分组属性ID组合值,将多个维表分组属性ID组合值映射为一个多维数组,每个维表分组属性ID代表多维数组一个维上的下标,多表连接结果对应一个多维数组地址。将多维数组进一步映射为一维向量,多维数组地址转换为一维向量下标,得到向量索引,并将连接结果记录在向量索引中。
多维数组映射机制适合于维表分组属性较小,对应的多维数组较小或多维数组单元使用率较高的情况,当映射的多维数组较大(多维数组大小高于CPU中线程私有cache大小时)且查询中实际使用的多维数组单元较少(多维数组中实际使用的单元数量低于某个阈值,如1%)时,多维数组映射的分组向量利用率较低并降低了聚集计算性能。
如图4所示,显示了基于多维分组映射的连接方法实例。Customer表中过滤出记录的主键列c_custkey和分组列c_nation,将结果集中的分组属性列c_nation进行字典表压缩,不同的分组值存储在字典向量中,使用字典向量的下标作为该分组值的压缩编码。同样地,supplier表过滤、投影出的分组属性s_nation也创建字典向量,用字典向量下标作为s_nation属性值的压缩编码。Customer表和supplier表基于分组属性压缩编码创建哈希表,执行与lineorder外键列的连接操作,连接结果为c_nation,s_nation压缩编码和lineorder记录ID,c_nation和s_nation字典向量映射为一个二维数组,连接结果中的c_nation和s_nation压缩编码值对应该二维数组两个维上的下标。将连接结果映射到二维数组中,将该二维数组转换的一维数组下标存储在向量索引中该lineorder记录对应的单元中,每个连接记录的结果存储在向量索引中,连接结果为空的记录在向量索引中相应单元置为空值。当选择率较低时,向量索引使用压缩格式,即,将连接结果存储为[FID,GID]二元组,将非空连接结果对应的lineorder表ID和映射的二维数组地址存储在压缩向量索引中。基于向量索引,在度量列上完成聚集计算,每个非空向量索引单元对应位置的度量列单元映射到向量索引单元存储的二维数组地址对应的分组向量单元中进行聚集计算。最终的分组向量存储了查询结果,非空单元向量地址转换为二维数组下标格式,每维数组下标映射到相应维表字典向量下标对应的单元读取分组属性值,并生成最终的查询结果。如分组向量单元[2]对应多维数组地址[0,2],第一维地址0对应customer表字典向量单元[0]中的值Canada,第二维地址2对应supplier表字典向量单元[2]中的值Korea,与分组向量单[2]中存储的值626合并为连接结果Canada,Korea,626,以此类推,将分组向量中所有非空单元通过地址转换与映射生成连接结果。
③基于稀疏多维数组压缩的连接方法
当多维数组较为稀疏时,我们进一步对稀疏多维数组进行压缩以提高查询处理性能。
在②连接阶段生成多维数组,将其映射为一维稀疏的分组向量,我们进一步为稀疏的分组向量创建稠密的分组向量。具体的方法是,在映射时使用序列生成器为每一个非空映射向量单元分配唯一序列,连接操作完成后最大序列ID值即为GROUP-BY属性对应的最大分组值,创建最大分组值长度对应的分组向量聚集器。然后基于稠密的分组向量创建向量索引,用于度量数据列上的聚集计算操作。
分组向量聚集器用于事实表度量属性上的聚集计算,根据向量索引非空单元值或压缩向量索引GID列的值将度量属性映射到分组向量聚集器对应单元进行聚集计算。
执行完聚集计算任务,将分组向量非空单元根据向量地址转换为多维数组下标,将各下标值映射到各维表字典表向量,访问各GROUP-BY属性值,同时根据分组向量单元存储的分组向量聚集器地址值访问分组向量聚集器单元中的聚集计算结果,生成分组聚集结果集。
该方法在连接阶段使用多维数组映射方法,优化哈希分组方法,同时稀疏多维分组映射为最小分组向量聚集器,优化了聚集计算阶段的分组映射性能。
如图5所示,显示了基于稀疏多维数组压缩的连接方法的应用示例。连接创建了二维数组,如连接结果记录[0](1,0)对应二维数组地址[1,0],在一维分组向量中对应单元地址[3],当前分组向量单元[3]为空,从序列生成器中获取当前值0存储于分组向量单元[3]中,在向量索引单元[0]中记录分组向量[3]中的值0。类似地,当连接结果二维地址对应的一维分组向量单元中非空时,将分组向量单元中的值写入对应的向量索引单元中;即当连接对应的分组向量单元为空时,从序列生成器中获得序列值存储于分组向量单元中,并将序列值写入向量索引对应单元中。当连接选择率较低时,可以直接生成压缩向量索引,连接操作执行完毕后生成向量索引或压缩向量索引。
聚集计算时,基于向量索引或压缩向量索引通过分组向量聚集器完成聚集计算。如向量索引单元[2]中存储的值为1,访问度量列[2]单元,将度量值626映射到分组向量聚集器单元[1]进行累加计算。聚集计算完毕后,分组向量聚集器各单元通过二维地址映射访问分组属性值,生成最终的查询结果。将分组向量中非空单元地址映射为二维数组地址,如分组向量单元[2]映射为[0,2],第一维下标0映射到customer表字典向量中获得Canada,第二维下标2映射到supplier表字典向量中获得Korea,分组向量单元值1映射到分组向量聚集器单元[1]中,获得626,合并为查询结果记录Canada,Korea,626。以此类推,扫描并处理分组向量非空单元后生成最终的查询结果集。
上述步骤3)中,采用基于向量索引的多核并行聚集计算方法。
基于向量索引的多核并行聚集操作的基本实现方法:若向量索引为定长向量,则按线程数量逻辑划分向量索引分区,并按相同的位置逻辑划分事实数据分区,每个线程并行扫描向量索引分区并执行在对应事实数据分区上的向量聚集操作;若向量索引为压缩格式,则采用与定长向量索引相同的逻辑分区方式,一方面需要扫描压缩向量索引的FID值确定分区位置,另一方面当向量索引中非空值分布不均衡时定长逻辑分区导致不同线程中实际执行的聚集计算代价不同,负载难以均衡,本发明采用在压缩向量索引上均衡逻辑分区的策略,简化逻辑分区的位置计算并使各线程对应逻辑分区上的聚集计算代价较为均衡。
在并行向量分组聚集操作执行时,可以采用两种聚集计算方法:一是每个线程使用私有分组向量完成本线程逻辑事实数据分区上的分组聚集计算操作,各线程处理完毕后执行线程间分组向量的归并计算,生成最终的全局分组向量;二是多线程共享统一的分组向量,执行基于并发控制机制的全局分组聚集计算。
如图6所示,私有分组向量方法为每个线程保持一个私有分组向量,完成本线程数据分片上的聚集计算,最后需要将各线程分组向量进行归并计算得到全局分组聚集计算结果。当分组向量的大小比CPU线程私有cache(L1cache、L2cache、L3cacheslice)小时,分组聚集计算具有较高的数据局部性,私有分组向量提高了并行计算效率。
如图7所示,共享分组向量方法为各线程维护一个全局统一的分组向量,各线程并发访问该全局分组向量单元进行全局聚集计算,在并发更新分组向量单元累积值时需要采用并发控制机制保证并发数据更新的正确性。当分组向量的大小超过CPU线程私有cache时,最优阈值为分组向量大小不超过L3cache slice大小的75%,私有分组向量将会产生较高的cache miss,这时采用共享分组向量会具有较好的计算效率。
上述步骤4)中,分组与聚集操作的结果集分别存储于连接和聚集计算两个阶段,连接操作中创建分组元数据,如分组向量、维表分组字典向量等,记录了分组属性具体取值;聚集计算中使用没有语义的分组向量聚集器进行计算,聚集计算结果保存在分组向量聚集器中,无法解析聚集计算的语义。在查询处理的最后阶段需要将分组向量聚集器单元的地址映射到连接阶段的分组向量中获取地址所映射的GROUP-BY属性值,与分组向量聚集器中存储的聚集计算结果合并为查询输出结果。
与传统查询处理实现技术不同,本发明采用向量索引作为连接与聚集两个计算阶段的中介,向量索引支持了最优的聚集计算,而连接阶段则产生最优的向量索引结构。
本发明可以应用于异构计算平台,将计算代价较高的连接阶段部署在GPU、FPGA、Phi等高性能硬件加速平台,将庞大的事实表数据存储在高可扩展的分布式存储系统中,硬件加速器平台执行高性能的连接操作后生成向量索引,向量索引发送到分布式存储系统数据分片上基于向量索引完成本地化的聚集计算和聚集结果归并任务,最后完成全局聚集归并计算,向主节点返回聚集计算结果,由主节点将硬件加速器平台的分组向量和分布式存储系统返回的分组向量聚集器结果合并为查询输出结果集。
上述各实施例仅用于说明本发明,其中各部件的结构、连接方式和制作工艺等都是可以有所变化的,凡是在本发明技术方案的基础上进行的等同变换和改进,均不应排除在本发明的保护范围之外。
- 还没有人留言评论。精彩留言会获得点赞!