基于systolic阵列的SCNN推理加速装置、处理器及计算机设备的制作方法
本发明涉及图像实时处理的脉冲卷积神经网络(scnn)硬件加速引擎技术,具体涉及一种基于systolic阵列的scnn推理加速装置、处理器及计算机设备。
背景技术:
人工神经网络是当前人工智能领域研究的热点。主流的方法是采用部分数据集对人工神经网络进行预先的训练(训练过程),而后将训练好的人工神经网络应用于实际的工作场景,利用其进行实际的图像分类、识别等操作(推理过程)。卷积神经网络(cnn)、脉冲神经网络(snn)都属于人工神经网络。脉冲神经网络(snn)主要通过模仿人脑神经元工作过程实现计算并行,减少功耗。传统的方法在训练snn时存在网络性能弱,训练收敛慢的缺点,而卷积神经网络(cnn)直接转snn的方法能够有效解决这一问题,该方法最终得到的snn称为脉冲卷积神经网络(scnn)。卷积神经网络(cnn)采用卷积核(kernel)对图像进行特征识别,通过非线性函数过滤次要信息。在实际过程中还采用稀疏化方法减少神经元数目(池化操作)来提高计算性能。脉冲神经网络则通过对神经元间脉冲影响神经元内部膜电位更新,模仿生物神经元抑制兴奋机制,完成计算处理。在实际工作中,卷积神经网络(cnn)通过导数对层间误差进行修正,采用bp算法进行训练。脉冲卷积神经网络(scnn)本身理论基于生物神经元工作原理,采用脉冲作为内部激励进行传导,本身无法求导。因此,采用拟生物训练算法进行训练。但是,该系列算法本身在训练上效率不高,收敛速度慢,最终得到的脉冲神经网络图像分类精度不高。针对这一情况,研究界有两种方案。一种是采用更加先进的拟生物的训练算法,进一步提高脉冲神经网络的训练效率,但目前进展甚微,另一种就是采用dnn转脉冲卷积神经网络(scnn)的方式,通过间接方式保证脉冲卷积神经网络的训练效率,提高脉冲卷积神经网络的性能,以便高效的获取能够实际应用的脉冲神经网络。针对第二种方案,如何实现针对脉冲卷积神经网络(scnn)进行硬件加速,尤其是采用同步电路对scnn推理过程进行硬件加速,目前仍然是一项亟待解决的关键技术问题。
技术实现要素:
本发明要解决的技术问题:针对现有技术的上述问题,提供一种基于systolic阵列的scnn推理加速装置、处理器及计算机设备,本发明采用同步电路实现,通过内部数据流共享减少片外(off-chip)数据搬移,能够支持片上膜电位更新、池化操作,具有计算密度大、并行度高、吞吐率高的特点。
为了解决上述技术问题,本发明采用的技术方案为:
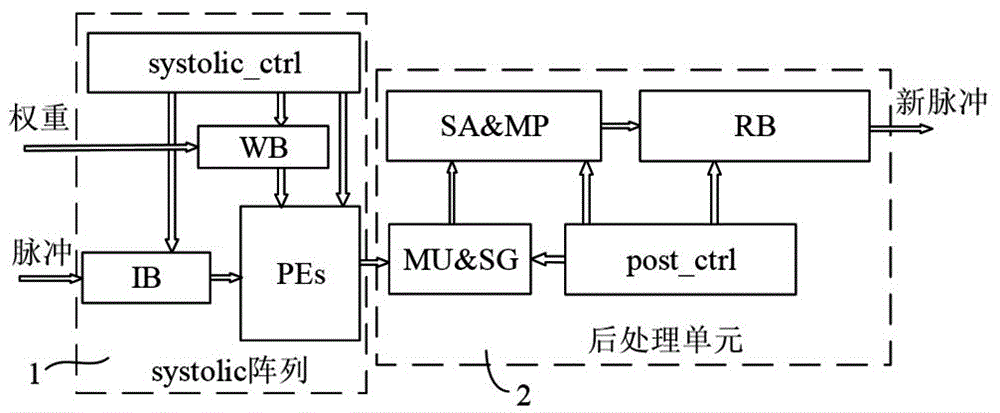
一种基于systolic阵列的scnn推理加速装置,包括systolic阵列和后处理单元,所述systolic阵列包括:
脉冲缓存ib,用于输入脉冲缓存;
权值缓存wb,用于权值缓存;
systolic控制器systolic_ctrl,用于控制systolic阵列行为;
处理单元阵列pes,用于脉冲与权值点积;
所述后处理单元包括:
膜电位更新与脉冲产生模块mu&sg,用于膜电位更新及脉冲产生;
脉冲累积与最大池化模块sa&mp,用于同一神经元的脉冲缓存以及池化操作;
结果缓存rb,用于结果脉冲缓存;
后处理机制控制器post_ctrl,用于控制后处理机制行为;
所述systolic控制器systolic_ctrl的控制输出端分别与脉冲缓存ib、权值缓存wb以及处理单元阵列pes相连,所述脉冲缓存ib、权值缓存wb的输出端分别与处理单元阵列pes的输入端相连,所述处理单元阵列pes的输出端与后处理单元2的输入端相连;所述膜电位更新与脉冲产生模块mu&sg、脉冲累积与最大池化模块sa&mp、结果缓存rb依次相连且其控制端均与后处理机制控制器post_ctrl相连,所述膜电位更新与脉冲产生模块mu&sg根据处理单元阵列pes的输出结果进行膜电位更新及脉冲产生,所述脉冲累积与最大池化模块sa&mp对膜电位更新与脉冲产生模块mu&sg输出的同一神经元的脉冲缓存以及池化操作,所述结果缓存rb用于将脉冲累积与最大池化模块sa&mp的输出缓存输出。
优选地,所述处理单元阵列pes包括以systolic阵列形式组织的多个处理单元pe,每一个处理单元pe的包括脉冲寄存器spike_reg、权重寄存器weight_reg、零值判断器、控制寄存器control_reg、累积寄存器accumulate_reg、乘法器、选择器mux和输出寄存器res_reg,上一级处理单元pe的脉冲输入激励pre_spike输入脉冲寄存器spike_reg并直接作为脉冲spike输出、权重输入激励pre_weight输入权重寄存器weight_reg并直接作为权重weight输出,零值判断器对脉冲寄存器spike_reg中的值进行判断并在脉冲寄存器spike_reg中的值为0时写控制寄存器control_reg,在控制寄存器control_reg为1时乘法器将权重输入激励pre_weight、脉冲输入激励pre_spike进行乘法运算并输出至累积寄存器accumulate_reg,且选择器mux在控制信号switch_in的控制下选择将上一级处理单元pe的输出pre_res或累积寄存器accumulate_reg中的值写入输出寄存器res_reg并通过输出寄存器res_reg输出。
优选地,所述膜电位更新与脉冲产生模块mu&sg包括:
历史膜电位存储器ram1,用于存储历史膜电位,且历史膜电位存储ram每个块bank对应同一行中一个处理单元pe;
当前膜电位寄存器history_m_reg,用于缓存systolic阵列1输出的膜电位增量;
加法器,用于将systolic阵列1计算的膜电位增量与当前拍数对应的处理单元pe的历史膜电位进行累加得到加和值;
累加膜电位寄存器next_m_reg,用于存储加法器累加得到的加和值;
比较器cmp,用于将累加膜电位寄存器next_m_reg保存的加和值与膜电位阈值进行比较,若加和值大于膜电位阈值,则以膜电位复位值reset_value更新历史膜电位存储器ram1中存储的历史膜电位,并完成脉冲点火,输出脉冲“1”;若加和值小于膜电位阈值,则以加和值更新历史膜电位存储器ram1中存储的历史膜电位,输出脉冲“0”;
脉冲生成器spike_gen,用于根据比较器cmp的输出脉冲生成脉冲信号。
优选地,所述脉冲累积与最大池化模块sa&mp包括:
脉冲信号存储器ram2,用于按照指定的长度批量存储膜电位更新与脉冲产生模块mu&sg输出的脉冲信号;
最大池化层,用于将脉冲信号存储器ram2中的各批脉冲信号进行逻辑或运算输出。
此外,本发明还提供一种处理器,包括处理器本体,该处理器本体中设有所述的基于systolic阵列的scnn推理加速装置。
此外,本发明还提供一种计算机设备,该计算机设备中设有所述的基于systolic阵列的scnn推理加速装置。
和现有技术相比,本发明具有下述优点:本发明基于systolic阵列的scnn推理加速装置包括systolic阵列和后处理单元,systolic阵列包括脉冲缓存ib、权值缓存wb、systolic控制器systolic_ctrl、处理单元阵列pes,用于脉冲与权值点积,后处理单元包括膜电位更新与脉冲产生模块mu&sg、脉冲累积与最大池化模块sa&mp、结果缓存rb、后处理机制控制器post_ctrl,采用systolic阵列计算神经元膜电位更新值,通过硬件模块实现批次池化,从而高效利用片上数据、减少片外访存压力,支持人工神经元模型中的集成与点火模型(if),能够对scnn卷积层、池化层推理过程进行加速,具有计算密度大、吞吐率高、支持流水并行的特点,本发明能够减少不必要的片外(off-chip)数据搬移,最大限度的利用片上数据,实现对卷积层、池化层推理的硬件加速。
附图说明
图1为本发明实施例scnn推理加速装置的基本结构示意图。
图2为本发明实施例scnn推理加速装置的详细结构示意图。
图3为本发明实施例中处理单元的基本结构示意图。
图4为本发明实施例中膜电位更新与脉冲产生模块mu&sg的结构示意图。
图5为本发明实施例中脉冲累积与最大池化模块sa&mp的结构示意图。
具体实施方式
如图1所示,本实施例基于systolic阵列的scnn推理加速装置包括systolic阵列1和后处理单元2,systolic阵列1包括:
脉冲缓存ib,用于输入脉冲缓存;
权值缓存wb,用于权值缓存;
systolic控制器systolic_ctrl,用于控制systolic阵列行为;
处理单元阵列pes,用于脉冲与权值点积;
后处理单元2包括:
膜电位更新与脉冲产生模块mu&sg,用于膜电位更新及脉冲产生;
脉冲累积与最大池化模块sa&mp,用于同一神经元的脉冲缓存以及池化操作;
结果缓存rb,用于结果脉冲缓存;
后处理机制控制器post_ctrl,用于控制后处理机制行为;
systolic控制器systolic_ctrl的控制输出端分别与脉冲缓存ib、权值缓存wb以及处理单元阵列pes相连,脉冲缓存ib、权值缓存wb的输出端分别与处理单元阵列pes的输入端相连,处理单元阵列pes的输出端与后处理单元2的输入端相连;膜电位更新与脉冲产生模块mu&sg、脉冲累积与最大池化模块sa&mp、结果缓存rb依次相连且其控制端均与后处理机制控制器post_ctrl相连,膜电位更新与脉冲产生模块mu&sg根据处理单元阵列pes的输出结果进行膜电位更新及脉冲产生,脉冲累积与最大池化模块sa&mp对膜电位更新与脉冲产生模块mu&sg输出的同一神经元的脉冲缓存以及池化操作,结果缓存rb用于将脉冲累积与最大池化模块sa&mp的输出缓存输出。
脉冲缓存ib,权值缓存wb,结果缓存rb只是单纯的缓存,本实施例省略其详细介绍。systolic控制器systolic_ctrl与后处理机制控制器post_ctrl内部均实现计数器,但值一样,以数拍数的方式控制两大部分(systolic阵列1与后处理机制2)行为。
如图2和图3所示,处理单元阵列pes包括以systolic阵列形式组织的多个处理单元pe,每一个处理单元pe的包括脉冲寄存器spike_reg、权重寄存器weight_reg、零值判断器、控制寄存器control_reg、累积寄存器accumulate_reg、乘法器、选择器mux和输出寄存器res_reg,上一级处理单元pe的脉冲输入激励pre_spike输入脉冲寄存器spike_reg并直接作为脉冲spike输出、权重输入激励pre_weight输入权重寄存器weight_reg并直接作为权重weight输出,零值判断器对脉冲寄存器spike_reg中的值进行判断并在脉冲寄存器spike_reg中的值为0时写控制寄存器control_reg,在控制寄存器control_reg为1时乘法器将权重输入激励pre_weight、脉冲输入激励pre_spike进行乘法运算并输出至累积寄存器accumulate_reg,且选择器mux在控制信号switch_in的控制下选择将上一级处理单元pe的输出pre_res或累积寄存器accumulate_reg中的值写入输出寄存器res_reg并通过输出寄存器res_reg输出。
本实施例中,处理单元pe有4个输入,3个输出。其中“pre_”标号所示输入分别表示来自前一处理单元pe的脉冲、权值以及结果;switch_in输入用于控制累加结果传出;三个输出用于向下一处理单元pe传递脉冲、权值以及结果。注意,由于脉冲为“0”或“1”序列,脉冲与权值的点积可以通过选择器与加法器实现。具体计算过程中,使用一个处理单元pe处理一组脉冲与权值的点积。由于需要多拍才能得到最终的累加值,所有点积中间结果均通过寄存器记录在处理单元内部。通过systolic控制器systolic_ctrl内部的计数器记录拍数。当处理单元完成累加拍数后,switch_in输入控制处理单元将累加结果传出。结果传出时需要按照一拍一个处理单元的方式传出,最终在最后一列的处理单元获得最终结果。处理单元pe以systolic阵列形式组织,同行共享脉冲数据流,同列共享权值数据流。
如图4所示,膜电位更新与脉冲产生模块mu&sg包括:
历史膜电位存储器ram1,用于存储历史膜电位,且历史膜电位存储ram每个块bank对应同一行中一个处理单元pe;
当前膜电位寄存器history_m_reg,用于缓存systolic阵列1输出的膜电位增量;
加法器,用于将systolic阵列1计算的膜电位增量与当前拍数对应的处理单元pe的历史膜电位进行累加得到加和值;
累加膜电位寄存器next_m_reg,用于存储加法器累加得到的加和值;
比较器cmp,用于将累加膜电位寄存器next_m_reg保存的加和值与膜电位阈值进行比较,若加和值大于膜电位阈值,则以膜电位复位值reset_value更新历史膜电位存储器ram1中存储的历史膜电位,并完成脉冲点火,输出脉冲“1”;若加和值小于膜电位阈值,则以加和值更新历史膜电位存储器ram1中存储的历史膜电位,输出脉冲“0”;
脉冲生成器spike_gen,用于根据比较器cmp的输出脉冲生成脉冲信号。
本实施例支持人工神经元模型中的集成与点火模型(if模型)。该if模型主要包括膜电位更新、脉冲产生两个功能过程。算法1对应膜电位更新过程,算法2对应脉冲产生过程。其中m表示膜电位,t表示膜电位阈值,δm表示脉冲与权值的点积(即膜电位增量),sum表示膜电位更新值与历史膜电位的加和值。
算法1:膜电位更新过程:
首先初始化(initialization),包括:膜电位mlj(初始为0),阈值t(初始为thr),膜电位增量δmlj(初始为0),复位膜电位r(初始为reset_value),下标j表示循环变量(初始为0),上标l表示神经元层层数。
然后逐个神经元层进行遍历,针对当前的第j次循环变量:(1)将上一层的膜电位mlj-1加上膜电位增量δmlj得到膜电位累积量sum(mlj);(2)针对膜电位累积量sum(mlj)进行下述处理(workingouttheaddedresult):如果膜电位累积量sum(mlj)>=阈值t,则将本层的膜电位mlj-1复位为复位膜电位r;如果膜电位累积量sum(mlj)<阈值t,则将本层的膜电位mlj-1更新为膜电位累积量sum(mlj),上一层的膜电位mlj-1加上膜电位增量δmlj的结果;最终存储本层的膜电位mlj-1(membranepotential)至内存ram中的对应的bank中。
本实施例中,算法1以systolic阵列1计算得来的膜电位增量同对应的历史膜电位(j-1cycle的膜电位)进行加和,得到加和值;若该加和值大于阈值,则以加和值更新当前历史膜电位;若该加和值小于阈值,则以复位膜电位更新当前历史膜电位;而后循环前进一步。
算法2:脉冲产生过程:
首先初始化(initialization),包括:脉冲spikelj(初始为0),阈值t(初始为thr),下标j表示循环变量(初始为0),上标l表示神经元层层数;
然后针对来自算法1(algorithm1)的膜电位累积量sum(mlj):如果膜电位累积量sum(mlj)>=阈值t,则产生脉冲“1”(spikelj<-1);如果膜电位累积量sum(mlj)<阈值t,则产生脉冲“0”(spikelj<-0);最终将生成的脉冲传递给脉冲累积与最大池化模块sa&mp。
膜电位更新与脉冲产生模块mu&sg主要对相应的两个功能过程(膜电位更新、脉冲产生)进行支持。使用ram对历史膜电位进行存储,每个块(bank)对应同一行中一个处理单元。将systolic阵列计算的膜电位增量与当前拍数对应的处理单元的历史膜电位进行累加,得到加和值。以此加和值与膜电位阈值进行比较。若加和值大于膜电位阈值,则以膜电位复位值(reset_value)更新历史膜电位,并完成脉冲点火,输出“1”;若加和值小于膜电位阈值,则以加和值更新历史膜电位,输出脉冲“0”。
如图5所示,脉冲累积与最大池化模块sa&mp包括:
脉冲信号存储器ram2,用于按照指定的长度批量存储膜电位更新与脉冲产生模块mu&sg输出的脉冲信号;
最大池化层,用于将脉冲信号存储器ram2中的各批脉冲信号进行逻辑或运算输出。
由于snn本身理论设计,需要将同一像素点转换为多组“0”或“1”序列。在算法上,表示对同一神经元进行多次脉冲与权值的点积。若不进行同一神经元的脉冲累积直接进行池化操作,势必造成多次片外数据(同一神经元脉冲与权值)搬移。本实施例提出在片上对同一神经元的脉冲进行累积,而后批次进行池化操作。注意,由于平均池化(avg-pooling)操作涉及“0”“1”以外的数据表示,在snn中无法实现,故只设计最大池化(max-pooling)操作。此处,最大池化操作本质为逻辑或运算,即范围内有脉冲则输出“1”,否则为“0”。
此外,本实施例还提供一种处理器,包括处理器本体,该处理器本体中设有本实施例前述的基于systolic阵列的scnn推理加速装置。
此外,本实施例还提供一种计算机设备,该计算机设备中设有本实施例前述的基于systolic阵列的scnn推理加速装置。
以上所述仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!