一种针对盲人辅助阅读的文本检测与识别方法与流程
本发明属于计算机视觉的应用领域,特别涉及一种针对盲人辅助阅读的文本检测与识别方法。
背景技术:
现今全世界范围内患有眼部疾病的已达3.14亿。其中2.69亿人患有低视力,盲人人数为0.45亿人。在中国目前视力残疾人口达877万人,约占全球盲人总数的19.5%,约占我国总人口的0.7%。根据有关权威机构的分析,六年以后,我国的盲人数量将突破七千五百万。因此,如何帮助盲人克服日常学习生活的困难,特别是最基本的阅读问题,具有极大的研究价值和社会意义,也具有广阔的应用前景。
目前市面上出现了多款盲人辅助阅读产品,例如一款戴在手指头上的盲人阅读器(touchreader)。该产品内置的扫描仪会自动将掠过的文字进行扫描识别,然后通过一个点阵将这些文字转换为凸起、凹下的盲文。由于点阵分布在指套的里层,所以手指头能感应到它的形状变化,从而让盲人朋友识别出这些盲文。与之类似,另一款触摸式盲人阅读器的底部可以将普通的文字读取经内部柱状阵列输出盲文信息,随后在顶部的面板上出现突出的柱状体,形成可以触摸识别的盲文。eyering指环由内嵌的微型图像扫描采集器采集书本中的文字内容,借助采集器背部靠近手指地方所设置的“盲文点显示器”实时变换盲点组合,达到让盲人朋友通过手指识别文本的效果。但上述这些产品对于没有学习过盲文的人难以使用这些装置。此外,其它产品如orcam这一可穿戴设备由绑在眼镜上的小型摄像头和一套处理系统组成。该产品可以通过运行计算机视觉算法、对看到的东西进行解析,然后通过骨导语音告诉盲人、弱视群体等所看到的内容及信息。但该产品造价昂贵,且盲人不一定能正确将扫描眼镜对准读物,因此使用起来较为不便。由此可见,上述已有产品或者需要用户学习过盲文,或者价格昂贵且使用不便。
在面向盲人阅读方法专利方面,邱洪等人(专利公开号为cn108492682a)提供了一种盲人阅读器,此阅读器将摄像头获取的图片信息发送到图像识别处理器进行识别,并将识别结果以电平信号的方式反馈到驱动电路中以驱动盲文点阵组件输出对应的盲文字符。王璐(专利公开号为cn106601081a)所发明的一种盲人指环式阅读器能够通过设置于指环上的摄像头识别正常书籍上的印刷字体同时转成成盲文。但上述这些专利方法的主要问题在于其仍然需要用户会用盲文。此外,李重周等人(专利公开号为cn103077625a)提出了一种盲用电子阅读器和助盲阅读方法。该助盲阅读方法首先通过扫描或者拍照将纸质文字转化为电子图片格式数据,然后通过ocr识别技术将其识别为电子文本文档,最后采用tts语音合成技术将电子文本文档转换为语音数据播放。但这一专利方法是将整幅图像中的文本一次性朗读出来,而未能提供用户指哪读哪这一便捷的个性化功能。
在此背景下,研究一种鲁棒性强,准确性高、成本低且能够对盲人或低视用户手指所指文本进行自动检测与识别的方法就显得尤为重要
技术实现要素:
本发明所要解决的技术问题是,提供一种针对盲人辅助阅读的文本检测与识别方法,使得盲人朋友或低视人群也能阅读普通书籍,解决了盲人朋友或低视力人群阅读困难的问题。
本发明所采用的技术方案如下:
一种针对盲人辅助阅读的文本检测与识别方法,包括以下步骤:
步骤1:对于相机拍摄的图像序列,判断当前图像中的场景是否为手指放在阅读文本上,若是则进行步骤2,否则跳过该帧图像,将下一帧图像作为当前图像,进行上述判断和处理;
步骤2:在当前图像中定位用户指尖;
步骤3:根据用户指尖的位置,确定用户指示的文本行;
步骤4:提取用户指示的文本行上的单词,将其转换为语音输出。
进一步地,所述步骤1中判断当前图像中的场景是否为手指放在阅读文本上的方法如下:
步骤11、通过相机预先拍摄一些典型的包含用户手指及其所在的文本区域的图像,保存于数据库中;
步骤12、将当前图像以及在该图像前面拍摄的多张图像作为样本图像;
步骤13、对数据库中的图像和样本图像的rgb色彩空间分别进行归一化处理;
步骤14、对于每个样本,分别计算其归一化处理后的红色通道图像与数据库中各张图像归一化处理后的红色通道图像的欧式距离,将结果中的最小值作为该样本的匹配分数;求取所有样本匹配分数的均值μim与方差σim,若μim+σim<th,则认定当前图像中的场景为手指放在阅读文本上,其中th为阈值,为经验参数。
进一步地,所述步骤14中,将所有图像都缩小到设定尺寸,再计算欧式距离。
进一步地,所述步骤2包括以下步骤:
步骤21、使用k-means找到用户指尖的候选区域;
首先,使用高斯滤波器对当前图像进行滤波;
然后,根据滤波后的图像中三个通道的图像生成三个二维矩阵,每个二维矩阵中的元素值为相应通道的图像上相应点的像素值;
对每个二维矩阵,将其所有列求和再取平均值,得到一个row×1的列向量mc_ave;将其所有行求和再取平均值,得到一个1×col的行向量mr_ave;由此,把当前图像转化成三个列向量和三个的行向量,其中col表示二维矩阵的总列数,row表示二维矩阵的总行数;
将列向量的每个维度作为一个纵向数据点,把三个列向量相同维度的分量作为相应的纵向数据点的三个特征,构成该纵向数据点的特征向量,纵向数据点的个数等于列向量的维度,即row;将行向量的每个维度作为一个横向数据点,把三个行向量相同维度的分量作为相应的横向数据点的三个特征,构成该横向数据点的特征向量,横向数据点的个数等于行向量的维度,即col;
其次,使用k-means分别对纵向数据点和横向数据点进行聚类,聚类数目均为2;
再次,将纵向数据点的聚类的结果表示为一个纵向标签向量,其为一个row×1的列向量,其各维度的分量表示为相应维度的纵向数据点的标签,取值为0或1;将横向数据点的聚类的结果表示为一个横向标签向量,其为一个1×col的行向量,其各维度的分量表示为相应维度的横向数据点的标签,取值为0或1;
分别对纵向标签向量和横向标签向量先进行均值滤波,再进行阈值处理,若某维度元素值大于或等于设定阈值,则将其设置为1,否则将其设置0,得到最终的纵向标签向量和横向标签向量;
将纵向标签向量中元素值0和1的分界点在当前图像中的对应的水平线与横向标签向量中元素值0和1的左侧分界点在当前图像中的对应的竖直线的交点为左上顶点,划定一个矩形区域作为用户指尖的候选区域;
步骤22、通过计算曲率定位指尖;
首先,采用canny算子求取用户指尖的候选区域中的边缘,连接边缘得到轮廓;若得到多个轮廓,则只保留包含像素点个数不小于设定阈值的轮廓;
然后,对保留下来的轮廓进行平滑处理;
最后,对平滑处理后的轮廓,计算轮廓上每个像素点的曲率,曲率为零的点即为用户指尖位置。
进一步地,使用k-means对纵向数据点/横向数据点进行聚类的过程中,随机初始化两组聚类中心,进行两次聚类,评估两次聚类结果的紧凑度,选取紧凑度好的聚类结果作为最终的聚类结果。
进一步地,所述步骤3包括以下步骤:
步骤31、文本区域的提取;
首先,当前图像转换成灰度图像;
然后,对灰度图像进行二值化处理,得到图像的前景区域和后景区域;
再排除后景区域中的非文本区域,方法如下:
先提取出后景区域中所有的连通区域,构成集合cr;然后对集合cr中的每个连通区域求取其旋转矩形,记为ζ(ο,θ,w,h),其中o代表旋转矩形的中心,θ代表旋转矩形所偏转的角度,是水平轴逆时针旋转,与碰到的旋转矩形的第一条边的夹角,w和h分别代表旋转矩形相邻的两条边;再过滤掉cr中旋转矩形的面积和所偏转的角度不符合约束条件的连通区域,对于剩下的连通区域,基于文本区域之间的关系进行进一步过滤,具体实现包括以下步骤:
3.1)以当前图像的左上顶点为原点o,当前图像长度方向为y轴,取右方向为正,当前图像宽度方向为x轴,取下方向为正;将每个连通区域r的旋转矩形中心作为一个关注点,将当前图像中的每条过关注点的直线,表示为如下形式:
xcosθsl+ysinθsl=ρsl;
其中,θsl为直线与x轴的夹角,ρsl为原点o到直线的距离,θsl的取值范围(-π/2,π/2),ρsl的取值范围为(-d,d),d为相机拍摄的原始图像对角线的长;
3.2)把(ρsl,θsl)参数空间细分为多个累加器单元,将坐标(ρk,θk)处的累加器单元的值记为a(ρk,θk);首先将全部累计器单元都设置为零,然后分别计算每个关注点(xi,yi)到直线xcosθk+ysinθk=ρk的距离d:
d=|xicosθk+yisinθk-ρk|;
对所有关注点到直线xcosθk+ysinθk=ρk的距离依次进行判断,每有一个关注点对应的距离小于阈值,则a(ρk,θk)值加1,判断完之后,得到最终的a(ρk,θk)值;若a(ρk,θk)值高于该阈值就认为相应直线为参考直线,记得到的参考直线条数为n;
3.3)通过无监督线聚类的方法找到文本区域,具体过程为:
3.31)输入关注点集合,初始化基准直线集合cl,其中包括n条基准直线,分别为步骤3.2)求得的n条参考直线;
3.32)计算关注点集合中的所有关注点到集合cl中每条基准直线的距离;对于每个关注点,取最小距离值;筛选出最小距离值小于设定阈值的点;对筛选出的关注点标记类别,将最小距离值对应同一条基准直线的关注点归于同一类;
3.33)对相同类别的关注点进行直线拟合,并判断新拟合出的直线与该类别对应的基准直线的斜率和截距的差值是否小于设定阈值,若小于,则集合cl中该类别对应的基准直线保持不变,否则,将集合cl中该类别对应的基准直线更新为将新拟合出的直线;若此步骤中集合cl中所有的基准直线均保持不变,则输出带有类别标记的关注点集合cs,这些关注点对应的旋转矩形所包含的区域即为提取出的文本区域,否则返回步骤3.31);
步骤32、确定文本行;
根据步骤2得到的指尖位置,确定一个矩形的感兴趣区域,指尖位于在感兴趣区域的底边上;
对步骤31提取出的文本区域,求取其中每个字符的最外层轮廓;选取每个轮廓的最底端的点作为基准点,筛选出位于感兴趣区域中的基准点;
对于筛选出的基准点,每次选取三个相邻的基准点,进行直线拟合,得到多条直线;
对于所有拟合出来的直线,分别进行评分,评分公式如下:
其中,d(i)为筛选出的第i个基准点到直线的距离,n为筛选出的基准点总数,μscore为得分;
选取分数最低的直线作为判定线;过滤掉筛选出的基准点中到判定线的距离小于设定阈值的基准点,再基于剩下的所有基准点,进行直线拟合,拟合出的直线即为用户指示的文本行。
进一步地,所述步骤4的具体处理过程如下:
步骤41、识别首个单词;
对于步骤31提取出的文本区域,提取出其位于感兴趣区域中的部分,作为目标文本区域;分别求取目标文本区域中每个字符的最小外接矩形,作为一个字母框;根据单词内的两个相邻字母框中心的距离与单词间两个相邻字母框中心的距离的差异,对字母框进行聚类,合成单词;求取属于一个单词中的所有字母框的最小外接矩形作为单词框;
根据图像中用户指示的文本行与水平方向所呈角度,对图像进行角度补偿,使其中文本行旋转至水平方向;
选取沿着文本行的第一个单词框,然后使用ocr识别技术进行识别,识别所返回的结果包括:单词、单词置信度和单词框;当返回的单词置信度大于阈值时,则认为单词被正确识别,对正确识别的单词进行语音输出;
步骤42、采用模板匹配方法跟踪正确识别的单词的单词框在后续图像帧上的位置,以确定后续图像帧上的新单词区域,在新单词区域中识别新的单词;
vi.对各帧图像进行二值化处理;
初始化s=1,初始化指尖速度vfingertip;将第l帧图像中识别出的第j个单词对应的单词框及其包含的所有字母框作为需要跟踪的单词框和字母框;将第m帧图像中的感兴趣区域作为搜索区域;初始化m=l+1;
vii.对需要跟踪的单词框/字母框,采用模板匹配的方法跟踪其在搜索区域中的位置;
若当前需要跟踪的单词框跟踪成功,则进入步骤iii;否则判断之前是否有跟踪成功的单词框,若有,则先在第m帧图像上与在最新跟踪成功单词框的匹配位置右方确定一条截止线,截止线与匹配位置右边重合;再判断截止线距离图像左边的宽度是否小于设定阈值,若是则将截止线右边的目标文本区域作为新单词区域,继续在新单词区域中识别新的单词;否则结束新单词识别;若之前没有跟踪成功的单词框,则将第m帧图像作为当前图像,对其执行步骤1~步骤41,进行首个单词的识别;
viii.更新指尖速度vfingertip:
其中,vword,j代表跟踪成功的第j个单词框在第l帧图像和第m帧图像中的位置的水平距离差,vletter,k代表跟踪成功的第k个字母框在在第l帧图像和第m帧图像中的位置的水平距离差,n1代表匹配成功的单词框数目,n2代表匹配成功的字母框数目;
ix.令s=s+1;
对第l帧图像中识别出第s个单词对应的单词框及其包含的每个字母框,根据指尖速度判断该单词框和各个字母框是否会移出第m帧图像,若第l帧图像上单词框/字母框的左上顶点的横坐标减去vfingertip×(m-l)小于零则判定该单词框/字母框会移出第m帧图像;
将判断不会移出当前桢图像的单词框/字母框作为需要跟踪的单词框/字母框;并划定一个矩形区域作为新的搜索区域,该矩形区域的左上角横坐标=上一个进行跟踪的单词框的左上角横坐标-指尖速度-设定偏移值,矩形区域的长=上一个进行跟踪的单词框的长+指尖速度,矩形区域的宽=上一个进行跟踪的单词框的宽+设定偏移值;
计算新的搜索区域中黑色像素与白色像素的比例,若此比例小于设定阈值,则丢弃该帧图像,并令m=m+1,重新进行前述判断和处理直到新的搜索区域中黑色像素与白色像素的比不小于设定阈值,则进入步骤v;否则直接进入步骤v;
x.返回步骤ii。
有益效果:
本发明公开了针对盲人辅助阅读的文本检测与识别方法,该方法包含以下步骤:步骤1:场景检测,该步骤主要检测相机所拍图像是否为手指放在阅读文本上的场景;步骤2:手指定位,该步骤实现对指尖的定位,并以此指尖作为后续文本检测的光标;步骤3:文本提取,该步骤主要包括文本行的提取及文本行中各单词的提取操作;步骤4:单词跟踪,该步骤主要对正确识别的单词,采用模板匹配方法对其单词框进行跟踪。利用此方法,同时结合语音输出,可运用于相关盲人辅助阅读产品,从而使用户即便不懂盲文也能方便快捷地获知所指处的文本内容。
相比于其它的助盲阅读方法,较多的采用的是将所拍图像文本转换为盲人朋友可感知的盲文形式,这就要求使用者必须学会盲文。而相对来说本方案,采用的是直接将用户手指所指单词进行语音输出的方式。因此,即便用户不懂盲文,也能随时随地方便快捷地享受到阅读的乐趣。同时,本方案方法运行速度快,效果好,不仅能够很准确地识别到用户指尖所指的单词,而且成本代价低,具有很强的通用性,可广泛应用于穿戴式盲人辅助阅读戒指等智能产品。
附图说明
图1为本发明方法的总体实施流程示意图;
图2为本发明方法的场景检测过程;其中图2(a)为提前建立的手指数据库图像,图2(b)为手指图像的归一化,图2(c)为摄像头所拍摄的图像与手指数据库图像模板匹配过程的示意图;
图3为本发明方法的指尖检测过程;其中图3(a)为相机的原始输入图片,图3(b)为输入图片的rgb通道,图3(c)为rgb通道转换而成的列向量,图3(d)为指尖可能存在的区域,图3(e)为放大的指尖可能存在的区域,图3(f)为找到的指尖位置;
图4为本发明方法的旋转矩形定义的示意图;
图5为本发明方法的文本提取过程;其中图5(a)为将指尖位置彩色图像进行灰度化后得到的灰度图像,图5(b)为对图5(a)所示的灰度图像进行二值化处理后得到的二值图像,图5(c)为根据面积条件对图5(b)过滤后的结果,图5(d)为依据角度条件进一步对图5(c)过滤后的结果;
图6为本发明方法的文本区域提取过程;其中图6(a)为经过角度过滤所得到的图像,图6(b)为所有ζ(o)的坐标表示,图6(c)为(ρsl,θsl)矩阵的三维表示,z轴为矩阵的值,图6(d)为所求取的初始化直线,图6(e)为经过线聚类所得到的文本区域;
图7为本发明方法的文本行确定过程;图7(a)为经过线聚类所得到的文本区域和指尖位置,图7(b)为由指尖位置所确定关键区域的示意图;图7(c)为提取出来的关注区域,并在其上标注文本行和异常直线示意图。
图8为本发明方法的单词识别过程;其中图8(a)为确定单词框的示意图;图8(b)为根据文本行确定旋转角度;图8(c)为对图像进行角度补偿后的结果;
图9为本发明方法的单词跟踪示意图;图9(a)为跟踪阅读时的;图9(b)为模糊块检测示意图。
图10为本发明方法在运行时的实际效果图。
具体实施方式
下面结合附图说明对本发明做进一步说明:
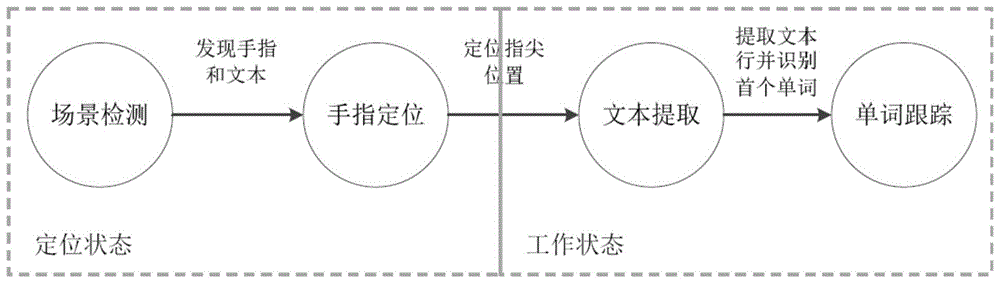
本实施例是针对助盲阅读这一特定应用,其对所拍图像中文本的检测与识别按如下步骤进行,整体实施流程如图1所示。由该图可知,详细实施流程主要包括以下主要步骤:
步骤1:通过场景检测判断当前图像中的场景是否为手指放在阅读文本上,若是则进行步骤2,否则不进行后续步骤;此步骤的具体处理过程如下:
步骤11、通过相机预先拍摄一些典型的包含用户手指及其所在的文本区域的图像,保存于数据库中,见图2(a);
步骤12、将当前图像以及在该图像前面拍摄的19张图像(即相机最近连续拍摄的20张图像)作为样本;
步骤13、颜色归一化;如图2(b)所示,对数据库中的图像和样本图像的rgb色彩空间分别进行归一化处理,以便减少光照和阴影的影响:
其中,(r,g,b)代表原图像中某点的像素值,(r,g,b)表示归一化处理后的图像中该点的像素值;
由于手指颜色为肤色,因此提取归一化处理后的各图像的红色通道图像,进行后续的图像匹配处理;
步骤14、图像匹配;为了减少匹配时间,先将所有图像尺寸都缩小到50×50像素的大小;对于每个样本,分别计算其对应的红色通道图像与数据库中各张图像对应的红色通道图像的欧式距离,将结果中的最小值作为该样本的匹配分数;求取20个样本匹配分数的均值μim与方差σim,本实施例中计算得到两者分别为35.08和10.01;若μim+σim<th,则认定当前图像中的场景为手指放在阅读文本上,可进行后续的指尖定位操作,其中th为阈值,本实施例中设置为150。
步骤2:在当前图像中定位用户指尖,如图2,作为后续文本检测的光标;具体处理过程如下:
步骤21、使用k-means找到用户指尖的候选区域;
首先,使用高斯滤波器对当前图像(如图3(a)所示)进行滤波,以减少异常点的干扰,提高聚类的准确程度。高斯滤波所采用的高斯核矩阵h的大小为(2kg+1)×(2kg+1),高斯核矩阵h的计算公式为:
上式中,h(i,j)为高斯核矩阵h第i行第j列的元素值,i,j=1,2,…,2kg+1;σg为高斯核函数的宽度参数,控制了函数的径向作用范围,本实施例中设置为3;kg为控制高斯核大小的参数,本实施例中设置为15;
然后,根据滤波后的图像(rgb图像)中三个通道的图像生成三个二维矩阵,每个二维矩阵中的元素值为相应通道的图像上相应点的像素值;
对每个二维矩阵分别根据下式进行计算,得到一个列向量和一个行向量:
其中,mc_ave为将二维矩阵的所有列求和再取平均值的得到的列向量;m(:,j)是二维矩阵的第j列,col表示二维矩阵的总列数;mr_ave为将二维矩阵的所有行求和再取平均值的得到的行向量;m(i,:)是二维矩阵的第i行,row表示二维矩阵的总行数;
由此,把当前图像转化成三个row×1列向量(如图3(b)、(c)所示)和三个1×col的行向量;将列向量的每个维度作为一个纵向数据点,把三个列向量相同维度的分量作为相应的纵向数据点的三个特征,构成该纵向数据点的特征向量,纵向数据点的个数等于列向量的维度,即row;将行向量的每个维度作为一个横向数据点,把三个行向量相同维度的分量作为相应的横向数据点的三个特征,构成该横向数据点的特征向量,横向数据点的个数等于行向量的维度,即col;
其次,使用k-means分别对纵向数据点和横向数据点进行聚类。在此过程中,为了防止得到的是局部最优解,聚类过程采用两次随机初始聚类中心,得到两次聚类的结果,评估这两次聚类结果的紧凑度,选取紧凑度好的聚类结果作为最终的聚类结果。
分别采用下式评估两次聚类结果的紧凑度:
上式中,k代表聚类数目,值为2,n代表某一类的样本数目,xi代表第j类的第i个数据点的特征向量,mj代表第j类的聚类中心。由该式得到的μscore是一次聚类结果中每个点到其相应的聚类中心的平方距离之和,能够反映该次聚类结果的紧凑度,μscore越大,紧凑性越差;选取μscore较低的聚类结果作为最终的聚类结果。
将纵向数据点的聚类的结果表示为一个纵向标签向量,其为一个row×1的列向量,其各维度的分量表示为相应维度的纵向数据点的标签,取值为0或1;由于聚类过程中与手指有关的数据点更可能分为一类,即聚类结果中0和1都是聚集在一起,又因为手指一般出现在图片的中下方,所以标签向量的元素取值一般靠上部分基本上全为0,靠下部分基本全为1;为了清除异常数据点的标签,用一维的均值滤波来对标签向量进行滤波,即在标签向量上对目标数据给一个模板,模板的大小通常为奇数,该模板包括其周围的临近数据(如模板的大小为5,则模板包括的数据为目标数据右边相邻的两个数据和左边相邻的两个数据,不包括其自身),再用模板中的全体数据的平均值来代替目标数据;对于滤波后的标签向量进行阈值处理,若某维度元素值大于或等于设定阈值,则将其设置为1,否则将其设置0(阈值根据经验设定,本实施例中设置为0.4),得到最终的标签向量。标签向量中元素值0和1的分界点在当前图像中的对应的水平线即为用户手指在图像中的纵向截止位置;
将横向数据点的聚类的结果表示为一个横向标签向量,其为一个1×col的行向量,其各维度的分量表示为相应维度的横向数据点的标签,取值为0或1;由于手指一般出现在图像的中部,所以该标签向量的元素取值分布为中间部分为1,两侧为0,因此选择该标签向量中元素值0和1的左侧分界点在当前图像中的对应的竖直线即为用户手指在图像中的横向截止位置;
大量实验结果表明:纵向截止位置和横向截止位置的交点在手指的左上方;由于对标签向量进行过均值滤波,会导致0和1的左侧分界点向0的部分进行偏移,使交点在手指的左上方,因此以交点为左上顶点,即可划定一个足够大的矩形区域(矩形区域具体大小和输入图像的大小有关,本实施例中输入图像大小为480×640,设置矩形区域长为320,宽为160)作为用户指尖的候选区域(即用户指尖可能存在的区域),如图3(d)、(e)所示。
步骤22、通过计算曲率定位指尖;
首先采用canny算子求取用户指尖的候选区域中的边缘,连接边缘得到轮廓;若得到多个轮廓,则通过设置的轮廓大小阈值(实验结果表明此阈值设置为100时效果最好),将包含像素点个数小于设定阈值的轮廓排除,以排除孤立点的干扰,将包含像素点个数不小于设定阈值的轮廓保留;
根据曲线的参数方程:
γ(t)=(x(t),y(t));
其中,t为参数,x(t)为曲线横坐标关于t的方程,y(t)为曲线纵坐标关于t的方程,γ(t)为曲线关于t的方程,则可知曲线的曲率计算公式为:
其中,
在本发明中,由于轮廓是像素点的集合,为了求取轮廓中每个像素点的曲率,按照如下方式进行计算。
首先,为了减少噪声对曲率测量的影响,需对曲线进行平滑处理。根据一维高斯函数生成一维高斯核;定义一维高斯核的大小为m,其中m是最接近10σ的奇数中较小的数,σ为一维高斯函数的宽度参数,控制了函数的径向作用范围,在实验中值为3,m即为31,。具体操作为将轮廓上每个像素点的坐标与一维高斯核做卷积,该操作可定义如下:
其中l=(m-1)/2=15,x(npoint),y(npoint)为轮廓上第npoint个像素点的横纵坐标(坐标系建立为:原点o为图像中的左上顶点,横轴为y轴,取右方向为正,纵轴为x轴,取下方向为正),g(k,σ)为一维高斯核的第k个权重值,x(n,σ)和y(n,σ)为平滑处理后轮廓上第n个像素点的坐标值,npoint的取值由下式决定:
其中nsize为轮廓包含像素点的个数,n,npoint=1,2,…,nsize。根据卷积的性质,可以计算求得x(n,σ)和y(n,σ)的一阶和二阶导数如下:
其中,
由于轮廓在第n个像素点的曲率计算表达式如下:
因此,对于所保留下来的轮廓,可以计算出轮廓每个像素点的曲率,结果如图3(f)所示,其中指尖对应曲率为零的点,由此即可得到用户指尖位置。
步骤3:根据用户指尖的位置,确定用户指示的文本行;具体处理过程如下:
步骤31、文本区域的提取;
首先把从相机所拍的彩色图像转换成灰度图像,见图5(a),然后对此灰度图像使用ostu自适应阈值法对图像进行二值化处理,见图5(b),得到此图像的前景区域(手指)和后景区域(文本文档)。由于后景区域中可能包含非文本区域,因此需要进一步加强约束条件以排除后景区域中的非文本区域。为此,首先,提取出图像后景区域中所有的连通区域,构成集合cr;然后,对集合cr中的每个连通区域求取其旋转矩形(最小外接矩形),记为ζ(ο,θ,w,h);其中o代表旋转矩形的中心,θ代表旋转矩形所偏转的角度(旋转角度),是水平轴(x轴)逆时针旋转,与碰到的矩形的第一条边的夹角,其范围为(-π/2,0),w和h分别代表旋转矩形相邻的两条边,如图4所示。然后,依据下列约束条件过滤集合cr中的非文本区域。
1)面积过滤。通过大量实验可以发现文本区域的面积大小是在一定的范围内,即满足:
tmin<ζarea<tmax;
其中,ζarea=wh,tmin和tmax分别为文本区域的上下面积阈值,其取值是根据多次实验测量文本区域的面积所确定的,本实施例中分别设为100和1500;
而非本区域的面积是随机大小的,由此即可根据区域面积进行非文本区域的第一次过滤。即对于集合c中的每个连通区域,若其旋转矩形不满足约束条件tmin<ζarea<tmax,则该旋转矩形可认为是非文本区域,将其从集合cr中删除,集合cr中剩余连通区域构成集合cr1;结果如图5(c)所示;
2)角度过滤。由于本发明所关注的场景为纯文本和带有插图的文本(如书籍等)而不是在复杂图像中的文本(如海报等),所以,在集合cr1中,真正文本区域较非文本区域有绝对的数量优势。且注意到26个英文字母中除了o是一个例外(其旋转矩形所偏转的角度总是零),其它字母文本区域的旋转矩形所偏转的角度均相差不大,即大部分文本区域的旋转矩形所偏转的角度θ都满足如下约束条件:
|θ-μθ|<σθ;
其中μθ和σθ分别为经过步骤1)处理后的集合c中所有连通区域的旋转矩形所偏转的角度的均值与方差。
因此,对于集合c1中的每个连通区域,若其旋转矩形不满足约束条件|θ-μθ|<σθ,则该旋转矩形可认为是非文本区域,将其从集合cr1中删除,集合cr1中剩余连通区域构成集合cr2。尽管约束条件|ζ(θ)-μθ|<σθ有可能会把图像边缘的文本区域清除,但由于文本检测与识别处理主要是针对图像的中部区域,因此这一处理不会对文本最终的识别准确性造成很大的影响,结果如图5(d)所示。
3)基于文本区域之间的关系过滤。在本发明所关注的场景中,文本区域不是独立出现而是会形成文本行,因此属于同一个文本行的所有文本区域的旋转矩形中心会有线性关系,由此可根据属于同一个文本行的所有文本区域的旋转矩形中心拟合出基准直线,最终,根据非文本区域的旋转矩形中心和文本区域的旋转矩形中心距离基准直线的距离差异来确定文本区域,由此问题的关键变为如何确定图像中哪些文本区域属于同一个文本行,确定哪些文本区域属于同一个文本行后,即可根据这些文本区域的旋转矩形中心拟合得到基准直线。具体实现包括以下步骤:
3.1)将集合cr2中的每个连通区域r的旋转矩形中心作为一个关注点,将图像中的每条过关注点的直线,改写其直线方程y=kx+b为如下形式:
其中,θsl为直线与x轴的夹角,ρsl为原点o到直线的距离(原点o为图像中的左上顶点,横轴为y轴,取右方向为正,纵轴为x轴,取下方向为正),
3.2)把(ρsl,θsl)参数空间细分为多个累加器单元,将坐标(ρk,θk)处的累加器单元的值记为a(ρk,θk);在本实施例中,θk取为(-90,90)的整数度数;首先将全部累计器单元都设置为零,然后分别计算每个关注点(xi,yi)到直线xcosθk+ysinθk=ρk的距离d:
d=|xicosθk+yisinθk-ρk|;
对所有关注点到直线xcosθk+ysinθk=ρk的距离依次进行判断,每有一个关注点对应的距离小于阈值,则a(ρk,θk)值加1,判断完之后,得到最终的a(ρk,θk)值,本次实验最终结果如图6(c)所示。最终的a(ρk,θk)值表示以直线xcosθk+ysinθk=ρk为轴的长条状区域所包含的关注点的个数,因此a(ρk,θk)值越高,就代表这条直线是基准直线的概率越大。由此可设定一个阈值,本实施例中设置为7,一旦a(ρk,θk)值高于该阈值就认为相应直线为参考直线,记得到的参考直线条数为n;
3.3)通过无监督线聚类的方法找到最可能的文本区域,具体过程为:
3.31)输入关注点集合,初始化基准直线集合cl,其中包括n条基准直线,分别为步骤3.2求得的n条参考直线;
3.32)计算关注点集合中的所有关注点到集合cl中每条基准直线的距离;对于每个关注点,取最小距离值;筛选出最小距离值小于设定阈值的点;对筛选出的关注点标记类别,将最小距离值对应同一条基准直线的关注点归于同一类;
3.33)对相同类别的关注点进行直线拟合,并判断新拟合出的直线与该类别对应的基准直线的斜率和截距的差值是否小于设定阈值,若小于,则集合cl中该类别对应的基准直线保持不变,否则,将集合cl中该类别对应的基准直线更新为将新拟合出的直线;若此步骤中集合cl中所有的基准直线均保持不变,则输出带有类别标记的关注点集合cs,将这些关注点对应的旋转矩形所包含的区域即为最可能的文本区域,否则返回步骤3.31);聚类所得的最终基准直线如图6(d)所示,最终所得的点集如图6(e)所示。
步骤32、确定文本行;
根据步骤2得到的指尖位置,确定一个矩形的感兴趣区域,感兴趣区域的长和原始图像的长相等,感兴趣区域的宽设为固定值(设为原始图像的宽的六分之一),指尖位于在感兴趣区域底边上;
对步骤31得到的文本区域,如图8(a)所示,求取其中每个字符的最外层轮廓,轮廓之间的相邻点为8连通区域。由于对于大多数的英文字母,字母最底端的点都几乎在一条直线上,即便在有旋转时也是如此。因此,可选取每个轮廓的最底端的点作为基准点,然后根据基准点是否在感兴趣区域中,如果不在,则过滤掉这些基准点,如图7(b),后续只对感兴趣区域中的基准点进行操作。值得注意的是有一些特殊的字母,如g,q,y,j,p等字母的基准点都是在理想文本线以下,将这些字母的基准点作为异常基准点。每次选取三个相邻的基准点,以最小化这三个相邻的基准点到直线的距离之和为目标,进行直线拟合,得到多条直线。为了清除那些由异常基准点所拟合出来的直线,对于所有拟合出来的直线,分别进行评分,评分公式如下:
其中,d(i)为筛选出的第i个基准点到直线的距离,n为筛选出的基准点的总数,μscore为得分,此分数越低代表结果越好。由此可选取分数最低的直线作为判定线,然后根据筛选出的各基准点到判定线的距离是否小于设定阈值过滤掉异常基准点,再基于剩下的所有基准点,以最小化这些基准点到直线的距离之和为目标,进行直线拟合,拟合出的直线即为用户指示的文本行,如图7(c)所示。
步骤4:提取用户指示的文本行上的单词,将其转换为语音输出。具体处理过程如下:
步骤41、识别首个单词;
对于步骤31提取出的文本区域,提取出其位于感兴趣区域中的部分,作为目标文本区域;分别求取目标文本区域中每个字符的最小外接矩形(旋转矩形),作为一个字母框;根据单词内的两个相邻字母框中心的距离与单词间两个相邻字母框中心的距离的差异,对字母框进行聚类,合成单词。沿着文本行,若当前字母框与下一个字母框的距离小于阈值,则认为这两个字母框属于一个单词,本实施例中该阈值设为20像素,重复上述过程直到文本行上的所有字母框都经过此判断,求取属于一个单词中的所有字母框的最小外接矩形作为单词框;
考虑到输入的图像往往不是沿水平方向的,而由于字母旋转会对最终识别的准确率有较大影响,因此根据图像中文本行与水平方向所呈角度(根据文本行斜率确定),对图像进行角度补偿,使其中文本行旋转至水平方向后再做后续处理,如图8(b)和图(c)所示。
选取沿着文本行的第一个单词框,然后使用tesseractocr识别引擎进行识别,识别所返回的结果包括:单词、单词置信度和单词框。当返回的单词置信度大于阈值(实验中设置为80)时,则认为单词被正确识别,对正确识别的单词进行语音输出(单词会被大声的朗读出来)。
值得注意的是上述识别操作的感兴趣域为图像的中部区域,识别过程中由于拍摄角度问题造成的图像与纸张之间的单应性影响由于对识别基本没有影响(由于拍摄角度并不是垂直拍摄,而是沿着指尖的方向进行拍摄,所拍摄出的图像中的文本相对于真实的文本会产生变形,但是感兴趣区域为图像的中部,产生变形小,所以对准确率基本没有影响),因此该干扰因素可被忽略。
步骤42、采用模板匹配方法跟踪正确识别的单词的单词框在后续图像帧上的位置,以确定后续图像帧上的新单词区域,在新单词区域中识别新的单词;
i.由于实际识别时图像由于运动模糊等原因造成图像清晰度不高,这会对单词的正确跟踪造成影响,因此先对各帧图像进行二值化处理;
初始化s=1,初始化指尖速度vfingertip;将第l帧图像中识别出的第j个单词对应的单词框及其包含的所有字母框作为需要跟踪的单词框和字母框;将第m帧图像中的感兴趣区域作为搜索区域;初始化m=l+1;
ii.对需要跟踪的单词框/字母框,采用模板匹配的方法跟踪其在搜索区域中的位置;
本发明采用标准平方差匹配算法,即最小化如下函数:
上式中,t(x',y')表示第l帧图像中需要跟踪的单词框/字母框上坐标(x',y')处的像素值,i(x+x',y+y')表示搜索区域中坐标(x+x',y+y')处的像素值,(x,y)代表搜索区域的左上顶点坐标。rsq_diff越小,表示匹配越成功。因此,实际运算中当此指标值小于给定阈值时,即被认为匹配成功,即单词框/字母框跟踪成功;
若当前需要跟踪的单词框跟踪成功,则进入步骤iii;否则判断之前是否有跟踪成功的单词框,若有,则先在第m帧图像上与在最新跟踪成功单词框的匹配位置右方确定一条截止线,截止线与匹配位置右边重合;再判断截止线距离图像左边的宽度是否小于设定阈值(0.6倍的图像水平宽度),若是则将截止线右边的目标文本区域作为新单词区域,继续在新单词区域中识别新的单词,以使单词阅读与手指同步;否则结束新单词识别,由此即可完成单词的跟踪与识别;若之前没有跟踪成功的单词框,则将第m帧图像作为当前图像,对其执行步骤1~步骤41,进行首个单词的识别;
若连续几帧图像都没有成功跟踪到任何单词框,则认为跟踪失败,这种情况往往是由于移动过快造成的;
iii.更新指尖速度vfingertip:
其中,vword,j代表跟踪成功的第j个单词框在第l帧图像和第m帧图像中的位置的水平距离差,vletter,k代表跟踪成功的第k个字母框在在第l帧图像和第m帧图像中的位置的水平距离差,n1代表匹配成功的单词框数目,n2代表匹配成功的字母框数目;
这里计算指尖速度的作用有两个,其一是可以据此判断单词框在哪一帧图像后会移动出图像(若第l帧图像上单词框/字母框的左上顶点的横坐标减去vfingertip×(m-l)小于零即可判断该单词框/字母框会移出第m帧图像)。当判断单词框会移出第m帧图像后,不会立即丢弃整个单词,而是会保留仍在第m帧图像中的该单词框剩余的字母,保留这些字母的字母框,因为根据指尖速度定义式可知它们会对指尖速度的计算产生影响。当判断字母框会移出第m帧图像后,则丢弃相应字母,这些字母框不参与指尖速度的计算。其二是提高跟踪的效率,即在下次进行单词跟踪时不去搜索整个图像,而是根据指尖速度划定一个矩形区域作为新的搜索区域,只在该搜索区域中进行跟踪;
iv.令s=s+1;对第l帧图像中识别出第s个单词对应的单词框及其包含的每个字母框,首先根据指尖速度判断该单词框和各个字母框是否会移出第m帧图像;将判断不会移出当前桢图像的单词框/字母框作为需要跟踪的单词框/字母框;并划定一个矩形区域作为新的搜索区域,该矩形区域的左上角横坐标=上一个进行跟踪的单词框的左上角横坐标-指尖速度-设定偏移值(本发明实施例中设定为15个像素),矩形区域的长=上一个进行跟踪的单词框的长+指尖速度,矩形区域的宽=上一个进行跟踪的单词框的宽+设定偏移值(本实施例中设定为30个像素),由于实际手指移动时不是平行移动,而是可能伴随之向下向上移动,因此加上一定的偏差值,偏差值根据实验获得;计算新的搜索区域中黑色像素与白色像素的比例,若此比例小于设定阈值(本实施例中设置为20%),则丢弃该帧图像,如图9(b)所示,即不继续在该帧图像中进行单词框的跟踪和识别,并令m=m+1,重新进行前述判断和处理直到新的搜索区域中黑色像素与白色像素的比不小于设定阈值,则进入步骤5);
v.返回步骤ii。
需要说明的是,以上公开的仅为本发明的具体实例,根据本发明提供的思想,本领域的技术人员能思及的变化,都应落入本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!