一种基于负载预测的Hadoop计算任务推测执行方法与流程
本发明涉及本发明涉及分布式、大数据、云计算领域,具体涉及一种基于负载预测的hadoop计算任务推测执行方法。
背景技术:
计算任务推测执行是指在分布式集群环境下,因为程序bug,负载不均衡或者资源分布不均,造成同一个作业的多个计算任务运行速度不一致,有的计算任务运行速度明显慢于其他计算任务,这些计算任务拖慢了作业的整体执行进度,为了避免这种情况发生,hadoop利用以空间换时间的思想,会为该计算任务启动备份任务,让该备份与原始任务同时运行,哪个先运行完,则使用它的结果。当appmaster检测到map计算任务或reduce计算任务中运行最慢的任务的剩余完成时间大于已完成任务的平均执行时间,则会为该任务启动备份任务。
当前的hadoop平台下,为了加速用户作业的完成,hadoop平台会采用以时间换空间的策略,对迟滞任务开启备份来加速作业的完成进度。当前hadoop中任务推测执行机制并没有考虑计算节点负载变化对任务执行进度的影响,以恒定的速率来反映任务的执行情况,也没有考虑当集群计算资源紧缺时,任务推测执行机制对其他做作业带来的影响。在hadoop平台中,任务推测执行对作业完成时间有着重要影响,如何优化任务推测执行是优化hadoop平台的关键步骤之一。
技术实现要素:
基于以上技术问题,本发明所述的一种基于负载预测的hadoop计算任务推测执行方法,具体包括三部分:备份任务数自适应调整算法部分,执行任务完成时间预测算法部分,备份任务完成时间预测算法部分。备份任务数自适应调整算法,appmaster感知当前的集群负载状态,对备份任务的总数量做出调整,减少备份任务对其他作业的干扰,避免过多的备份任务产生资源抢占。执行任务完成时间预测算法,通过历史数据建立起任务完成时间与计算节点负载,任务进度的xgboost模型,每个运行的任务根据xgboost模型实时计算出任务的完成时间,并且将信息发送给appmaster。备份任务完成时间预测算法,利用计算节点的负载通过xgboost模型预测备份任务的完成时间,选择合理的节点来开启备份任务,减少作业的完成时间。
一种基于负载预测的hadoop计算任务推测执行方法,具体包括如下步骤:
步骤1:在作业提交后计算总任务数,且资源管理器对备份任务数自适应调整,得到最大备份任务数,具体包括步骤1.1~步骤1.3:
步骤1.1:针对最近一段时间t,将空闲计算节点向资源管理器申请计算资源的时间点保存到链表中;
步骤1.2:通过集群空闲度感知方法计算集群空闲度ρ,具体包括:
步骤1.2.1:判断链表长度list.sise是否大于阈值lmax。
步骤1.2.1.1:当list.sise>lmax时,判断链表尾节点和头节点的时间差t是否大于阈值tmax。
步骤1.2.1.1.1:当t>tmax时,移除头节点,返回步骤1.2.1。
步骤1.2.1.1.2:当t≤tmax时,跳到步骤1.2.2。
步骤1.2.1.2:当list.sise≤lmax时,继续存储计算节点向资源管理器申请计算资源的时间点,返回步骤1.2.1。
步骤1.2.2:根据公式(1)算集群空闲度ρ。
其中,ρ代表集群空闲度,list.size代表链表长度,t代表链表尾节点和头节点的时间差。
步骤1.3:根据公式(2)和公式(3)算集群最大备份任务数totalbackup。
其中,ts代表一个计算周期,totalbackup代表整个集群能开启的最大备份任务数,τ代表中间变量,n代表任务总数。
步骤2:预测执行任务完成时间,具体包括:
步骤2.1:构建权值xgboost模型wxg(weightxgboost)和剩余完成时间的xgboost模型txg(timexgboost)。
步骤2.2:map执行任务由map和sort两个阶段组成,预测map执行任务完成时间方法,具体包括:
步骤2.2.1:输入矩阵x1[各阶段的负载信息]和x2[节点负载预测信息,当前阶段剩余的数据量]。
步骤2.2.2:根据公式(4),通过权值xgboost模型wxg(weightxgboost)计算map阶段与sort阶段的权值wmap,wsort。
wmap,wsort=wxg(x1)(4)
其中,wmap代表map阶段权值,wsort代表sort阶段权值,x1代表各阶段负载信息,wxg(x)代表权值xgboost模型。
步骤2.2.3:根据公式(5),通过剩余完成时间的xgboost模型txg(timexgboost)计算每个阶段剩余完成时间tremain。
tremain=txg(x2)(5)
其中,tremain代表各阶段剩余完成时间,x2代表节点负载预测信息和当前阶段剩余的数据量,txg(x)代表剩余完成时间的xgboost模型。
步骤2.2.4:根据公式(6)计算每个阶段的进度progm。
其中,progm代表每个阶段的进度,runtime代表每个阶段已经运行的时间。
步骤2.2.5:根据公式(7)计算map执行任务完成进度progmap。
progmap=∑i∈{map,sort}wi*progi(7)
其中,progmap代表map执行任务完成进度,wi代表每个阶段的权值,progi代表每个阶段进度。
步骤2.2.6:根据公式(8)计算map执行任务完成时间estimatedendtime。
其中,estimatedendtime代表map执行任务完成时间,now表示当前时刻,starttime表示任务开始时刻。
步骤2.3reduce执行任务分为copy,sort,reduce三个阶段,预测reduce执行任务完成时间,具体包括:
步骤2.3.1:输入矩阵x1[各阶段的负载信息],x2[节点负载预测信息,当前阶段剩余的数据量]。
步骤2.3.2:根据公式(9),通过权值xgboost模型wxg(weightxgboost)计算copy,sort,reduce三个阶段的权值wcopy,wsort,wreduce。
wcopy,wsort,wreduce=wxg(x1)(9)
其中,wcopy代表copy阶段权值,wsort代表sort阶段权值,wreduce代表reduce阶段权值。
步骤2.3.3:根据公式(10),通过剩余完成时间的xgboost模型txg(timexgboost)计算每个阶段剩余完成时间tremain。
tremain=txg(x2)(10)
步骤2.3.4:根据公式(11)计算每个阶段的进度progm。
步骤2.3.5:根据公式(12)计算reduce执行任务完成进度progreduce。
progreduce=∑i∈{copy,sort,reduce}wi*progi(12)
其中,progreduce代表reduce执行任务完成进度。
步骤2.3.6:根据公式(13)计算reduce执行任务完成时间estimatedendtime。
步骤3:将最大备份任务数与appmaster设置的备份任务数比较,取最小值作为备份任务数阈值,并设置初始备份任务数为0,初始任务数为0;
步骤4:判断备份任务数是否小于等于备份任务数阈值,若为是,则转到步骤5;若为否,则将备份任务数返回资源管理器;
步骤5:判断任务数是否小于总任务数,若为是,则转到步骤6,若为否,则将备份任务数返回资源管理器;
步骤6:预测备份任务完成时间,具体包括:
步骤6.1:根据公式(14)计算节点map执行任务的失效率和reduce任务的失效率。
其中,failmap,failreduce分别代表计算节点运行map任务的失效率和运行reduce任务的失效率,mapfail,reducefail分别代表历史运行失败的map任务数和历史运行失败的reduce任务数,summap,sumreduce代表计算节点上历史运行的map任务总数和reduce任务总数
步骤6.2:通过权值xgboost模型wxg(weightxgboost)计算各个阶段的权值参数w。
步骤6.3:根据公式(15),通过剩余完成时间的xgboost模型txg(timexgboost)计算预测完成时间。
其中,runtime代表备份任务预测完成时间;
步骤6.4:根据公式(16)计算备份任务完成时间estmiteendtime备份。
estmiteendtime备份=now+runtime(16)
其中,estmiteendtime备份代表备份任务完成时间。
步骤7:判断备份任务完成时间estmiteendtime备份和执行任务完成时间estmiteendtime大小,当estmiteendtime备份≥estmitedendtime时,不开启备份,任务数加1,转到步骤4;当estmitedendtime备份<estmitedendtime时,开启备份,备份任务数加1,任务数加1,转到步骤4。
有益技术效果:
本发明提出一种基于负载预测的hadoop计算任务推测执行方法,备份任务数自适应调整算法,根据集群的负载状态实时调整备份任务数量的开启,保证了当集群计算资源紧张的情况下,备份任务的开启不会对其他作业产生影响。执行任务的完成时间预测,利用xgboost算法分别对map执行任务和reduce执行任务的完成时间做出预测,从而更加准确的识别迟滞任务,有效避免了迟滞任务的误判导致计算资源浪费。备份任务完成时间预测算法,选择合理的节点来开启备份任务,节约计算节点的计算资源,减少作业的完成时间,提高了集群的整体性能。
附图说明
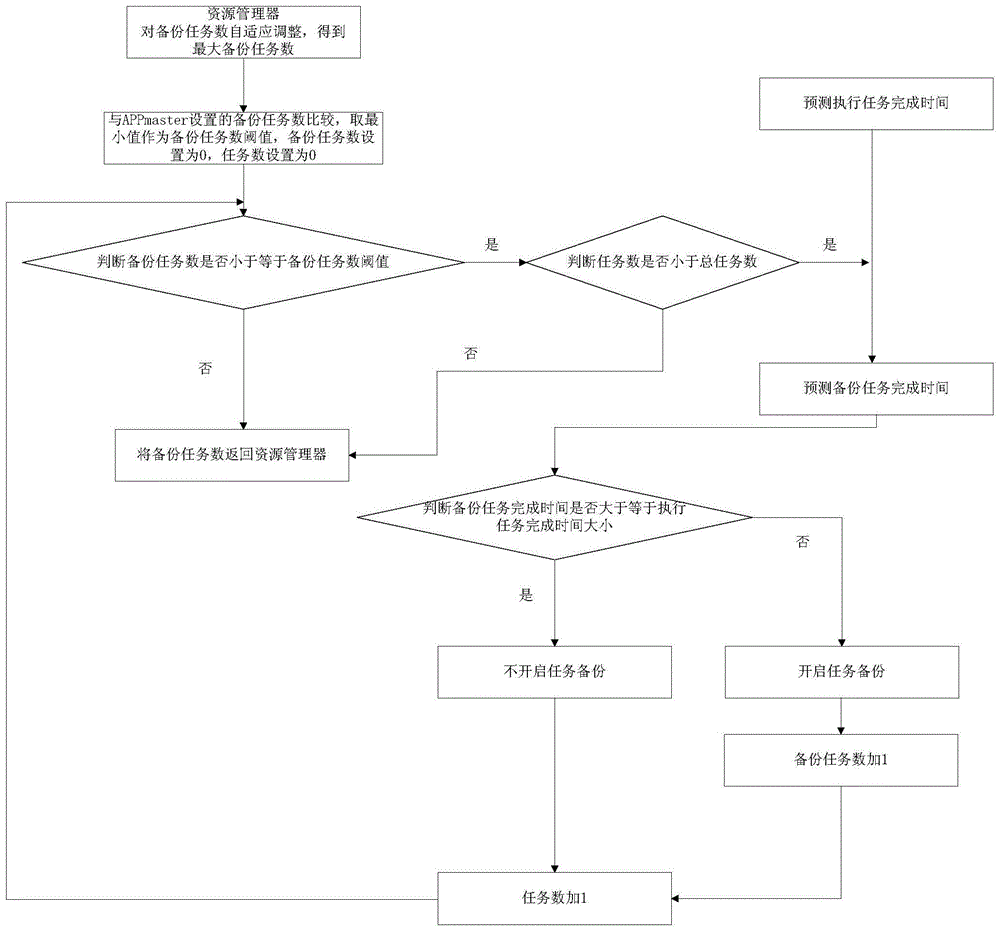
图1本发明实施例的一种基于负载预测的hadoop计算任务推测执行方法流程图;
图2本发明实施例的基于负载预测的hadoop推测执行ipo图;
图3本发明实施例的fifo作业完成时间对比图;
图4本发明实施例的capacity作业完成时间对比图;
图5本发明实施例的fair-modified作业完成时间对比图;
图6本发明实施例的fair作业完成时间对比图。
具体实施方式
下面结合附图和具体实施实例对发明做进一步说明,本发明为一种基于负载预测的hadoop计算任务推测执行方法,基于负载预测的hadoop计算任务推测执行ipo如图1所示,通过历史数据建立起任务完成时间与计算节点负载,任务进度的xgboost模型,每个运行的任务根据xgboost模型实时计算出任务的完成时间,并且将信息发送给appmaster,资源管理器根据当前的集群负载,通过自适应备份任务数调整算法实时计算当前能够进行任务推测的最大任务数量供appmaster进行备份任务开启的判断,根据预测的备份任务完成时间,判断是否对该任务开启备份,选择合理的节点来开启备份任务,减少作业的完成时间。
本系统在hadoop平台上用20台同构的机器进行试验,其中1台为master,19台为slave,配置了三个用户队列a,b,c,分别占用集群30%,30%,40%的计算资源,hadoop集群搭建的信息为hadoop版本2.6,java版本1.7,操作系统centos7,编译工具maven,开发工具intelij,节点个数为19,用户队列为root.a,root.b,root.c。
本系统实施节点配置参数:cpu核数为8核,cpu主频2.2ghz,内存类型ddr3-1333ecc,内存容量8gb,硬盘类型为15000转sas硬盘,硬盘容量300gb,带宽1000mbps。
一种基于负载预测的hadoop计算任务推测执行方法,如图1所示,具体包括如下步骤:
步骤1:在作业提交后计算总任务数,且资源管理器对备份任务数自适应调整,得到最大备份任务数,具体包括:
步骤1.1:针对最近一段时间t,将空闲计算节点向资源管理器申请计算资源的时间点保存到链表中;
步骤1.2:通过集群空闲度感知方法计算集群空闲度ρ,具体包括:
步骤1.2.1:判断链表长度list.sise是否大于阈值lmax。
步骤1.2.1.1:当list.sise>lmax时,判断链表尾节点和头节点的时间差t是否大于阈值tmax。
步骤1.2.1.1.1:当t>tmax时,移除头节点,返回步骤1.2.1。
步骤1.2.1.1.2:当t≤tmax时,跳到步骤1.2.2。
步骤1.2.1.2:当list.sise≤lmax时,继续存储计算节点向资源管理器申请计算资源的时间点,返回步骤1.2.1。
步骤1.2.2:根据公式(1)算集群空闲度ρ。
其中,ρ代表集群空闲度,list.size代表链表长度,t代表链表尾节点和头节点的时间差。
步骤1.3:根据公式(2)和公式(3)算集群最大备份任务数totalbackup。
其中,ts代表一个计算周期,totalbackup代表整个集群能开启的最大备份任务数,τ代表中间变量,n代表任务总数。
步骤2:预测执行任务完成时间,具体包括:
步骤2.1:构建权值xgboost模型wxg(weightxgboost)和剩余完成时间的xgboost模型txg(timexgboost)。
步骤2.2:map执行任务由map和sort两个阶段组成,预测map执行任务完成时间方法,具体包括:
步骤2.2.1:输入矩阵x1[各阶段的负载信息]和x2[节点负载预测信息,当前阶段剩余的数据量]。
步骤2.2.2:根据公式(4),通过权值xgboost模型wxg(weightxgboost)计算map阶段与sort阶段的权值wmap,wsort。
wmap,wsort=wxg(x1)(4)
其中,wmap代表map阶段权值,wsort代表sort阶段权值,x1代表各阶段负载信息,wxg(x)代表权值xgboost模型。
步骤2.2.3:根据公式(5),通过剩余完成时间的xgboost模型txg(timexgboost)计算每个阶段剩余完成时间tremain。
tremain=txg(x2)(5)
其中,tremain代表各阶段剩余完成时间,x2代表节点负载预测信息和当前阶段剩余的数据量,txg(x)代表剩余完成时间的xgboost模型。
步骤2.2.4:根据公式(6)计算每个阶段的进度progm。
其中,progm代表每个阶段的进度,runtime代表每个阶段已经运行的时间。
步骤2.2.5:根据公式(7)计算map执行任务完成进度progmap。
progmap=∑i∈{map,sort}wi*progi(7)
其中,progmap代表map执行任务完成进度,wi代表每个阶段的权值,progi代表每个阶段进度。
步骤2.2.6:根据公式(8)计算map执行任务完成时间estimatedendtime。
其中,estimatedendtime代表map执行任务完成时间,now表示当前时刻,starttime表示任务开始时刻。
步骤2.3reduce执行任务分为copy,sort,reduce三个阶段,预测reduce执行任务完成时间,具体包括:
步骤2.3.1:输入矩阵x1[各阶段的负载信息],x2[节点负载预测信息,当前阶段剩余的数据量]。
步骤2.3.2:根据公式(9),通过权值xgboost模型wxg(weightxgboost)计算copy,sort,reduce三个阶段的权值wcopy,wsort,wreduce。
wcopy,wsort,wreduce=wxg(x1)(9)
其中,wcopy代表copy阶段权值,wsort代表sort阶段权值,wreduce代表reduce阶段权值。
步骤2.3.3:根据公式(10),通过剩余完成时间的xgboost模型txg(timexgboost)计算每个阶段剩余完成时间tremain。
tremain=txg(x2)(10)
步骤2.3.4:根据公式(11)计算每个阶段的进度progm。
步骤2.3.5:根据公式(12)计算reduce执行任务完成进度progreduce。
progreduce=∑i∈{copy,sort,reduce}wi*progi(12)
其中,progreduce代表reduce执行任务完成进度。
步骤2.3.6:根据公式(13)计算reduce执行任务完成时间estimatedendtime。
步骤3:将最大备份任务数与appmaster设置的备份任务数比较,取最小值作为备份任务数阈值,并设置初始备份任务数为0,初始任务数为0;
步骤4:判断备份任务数是否小于等于备份任务数阈值,若为是,则转到步骤5;若为否,则将备份任务数返回资源管理器;
步骤5:判断任务数是否小于总任务数,若为是,则转到步骤6,若为否,则将备份任务数返回资源管理器;
步骤6:预测备份任务完成时间,具体包括:
步骤6.1:根据公式(14)计算节点map执行任务的失效率和reduce任务的失效率。
其中,failmap,failreduce分别代表计算节点运行map任务的失效率和运行reduce任务的失效率,mapfail,reducefail分别代表历史运行失败的map任务数和历史运行失败的reduce任务数,summap,sumreduce代表计算节点上历史运行的map任务总数和reduce任务总数
步骤6.2:通过权值xgboost模型wxg(weightxgboost)计算各个阶段的权值参数w。
步骤6.3:根据公式(15),通过剩余完成时间的xgboost模型txg(timexgboost)计算预测完成时间。
其中,runtime代表备份任务预测完成时间;
步骤6.4:根据公式(16)计算备份任务完成时间estmitedendtime备份。
estmitedendtime备份=now+runtime(16)
其中,estmitedendtime备份代表备份任务完成时间。
步骤7:判断备份任务完成时间estmitedendtime备份和执行任务完成时间estmitedendtime大小,当estmitedendtime备份≥estmitedendtime时,不开启备份,任务数加1,转到步骤4;;当estmitedendtime备份<estmitedendtime时,开启备份,备份任务数加1,任务数加1,转到步骤4。
过对比各个作业在调度中不开启推测执行,开启late的推测执行,开启本发明的基于负载预测的hadoop计算任务推测执行(lps)进行对比,分别绘制了各个调度器下各个作业集的完成时间对比图,结果如图3-6所示,得出以下结论:
(1)负载的变化对任务完成时间有影响,通过图3,图4,图5,图6可知,当作业规模较小时,late推测执行和lps推测执行都能减少任务的完成时间,而当作业规模变大,任务执行速度明显受到计算节点性能的影响,lps推测执行可以实时依据负载对任务完成时间进行预测,对迟滞任务的识别准确率高于late推测执行,所以当负载变高时,lps推测执行机制仍然可以有效减少作业的完成时间。
(2)备份任务过多会降低集群性能,由图3,图4,图5,图6可知,当任务量变大时,开启late推测执行反而会增加原有的作业完成时间,但lps推测执行考虑了负载的变化带来的备份任务数变化,所以当集群负载较高时,依然可以减少作业集的完成时间。
本发明过程是在计算节点中完成的,根据计算节点的负载预测任务的完成时间,然后将完成时间传入appmaster,appmaster中有已经备份的任务数,如图2所示,然后和资源管理器自适应调整算法传来的可备份任务数进行比较,若小于,足可以继续备份。再去计算备份任务的完成时间,如果预测的完成时间大于备份任务完成时间,则开启备份。
综上所述,本章提出的基于负载预测的hadoop计算任务推测执行方法相较于hadoop原生的late推测执行方法能够更加准确的找到迟滞任务,并且能够根据集群负载调整备份任务数的开启,有效减少了作业完成时间的同时避免了备份任务过多而产生的资源竞争。
- 还没有人留言评论。精彩留言会获得点赞!