一种用于非人智能体的智能度量方法与流程
本发明涉及一种用于非人智能体的智能度量方法。
背景技术:
随着智能时代的到来,越来越多的独立实体开始拥有智能,它们能够思考并能同环境交互,这类实体在人工智能领域被统称为智能体(agent),本专利将智能体分为机器和服务两大类。
但人工智能的发展迅猛,非人的智能体展现出的能力越来越强,例如对机器而言,知识问答领域的ibm超级电脑沃森在智力竞赛中战胜人类选手,图像识别领域的微软deepimage系统在人脸识别测试中正确率超过人类,围棋领域的alphago战胜李世石;对服务而言,智能语音服务助手siri可以与人流畅对话甚至合理预测球赛得分,智能客服助手已经渗透到金融、电商、o2o以及旅游等行业,智能服务机器人(血管清理/口腔修复/智能轮椅)的功能也越来越强大。人们开始疑惑这些智能体究竟有多少智能,它们的智能是否会超过人类。然而智能体的通用智能至今没有一个明确的方法、系统、平台或者网络等可以提供这种服务,因此,需要提出一种通用智能度量方法,该方法能合理的、有效的、可计算的度量智能体的智能量。
目前的度量方法只针对智能体在单个领域的效率:例如在知识问答领域典型评价方法是em,em表示智能体的答案与正确答案完全匹配的概率,在图像识别领域的典型评价方法是topn-error,表示图像识别模型预测出的前n个最高概率的答案中有正确答案的概率,在语音服务方面典型的评价方法是准确度,表示在不同环境(嘈杂,安静等)下对问题的正确理解率或正确回答率。然而目前没有一个通用的公式可以衡量一个智能体在各个方面的智能程度,比如知识问答领域的em评价方法不适用于图像识别领域,评价方法之间的差异导致目前没有通用的公式来评价智能体的智能。
目前,学术界对此进行了一定的研究,文献“陈荣元,林立宇,王四春,等:数据同化框架下基于差分进化的遥感图像融合[j].自动化学报,2010,36(3):392-398.”借鉴气象领域中的数据同化系统能综合其模型算子和观测算子两者优点的思想,提出一个基于差分进化的遥感图像融合框架,在该框架下,用差分进化(de)算法来优化由图像定了评价指标组成的目标函数,从视觉效果和定量指标两方面验证了该框架的有效性,一定程度上解决了融合模型建立不够客观、参数选取随意性大的问题,也解决了不同融合方法的优点不易综合的问题,因此通过构造数据同化的目标函数可以用来评价建立的智能体能力模型。
文献“镡志伟,彭景,白福利:基于aic准则优选ar模型研究我国生产事故[j].工业安全与环保,2009,35(6):45-4.”提出了将基于aic准则进行ar模型优选的方法应用到生产事故的预测中,避免了繁琐的模型统计检验,方便建模,因此应用aic准则进行ar模型优选适用多变量评估领域。
技术实现要素:
为了解决上述技术问题,本发明的目的是提供一种合理的、有效的、可计算的通用的度量智能体智能的方法,适用于包括机器、服务在内的所有具有思考并能同环境进行交互的非人智能体。该方法包括以下步骤:
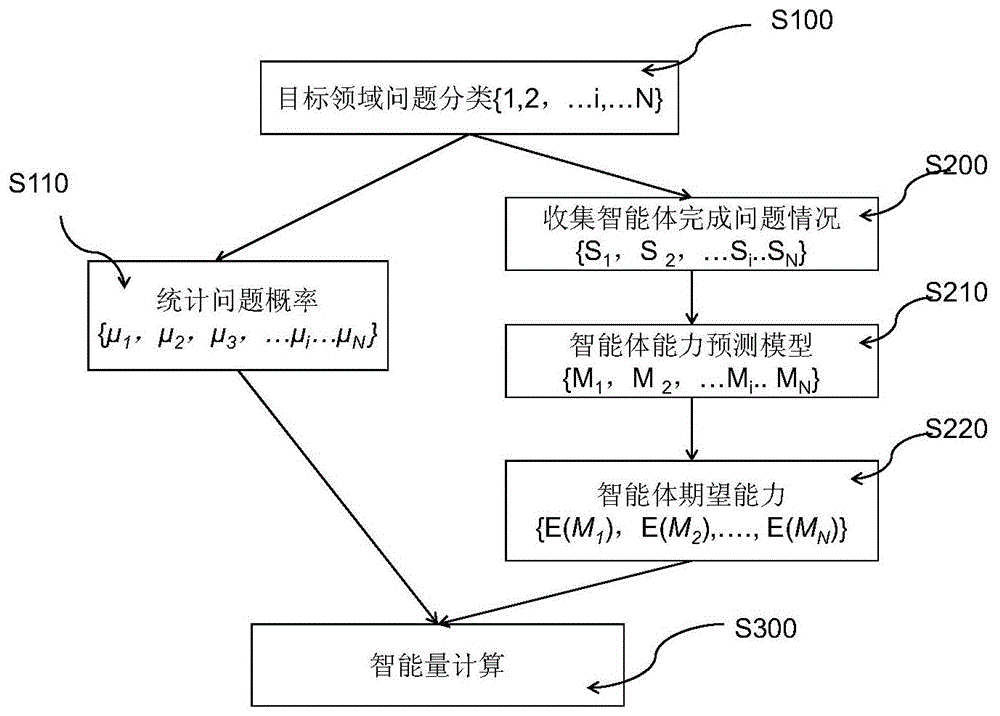
步骤1:统计目标问题领域下各问题的类型{1,2,...i...n}和概率{μ1,μ2,μ3,...μi...μn};
步骤2:建立智能体能力模型{m1,m2,.....mn},在数据同化框架下优化这些模型,使用m预测智能体的期望完成程度{e(m1),e(m2),...,e(mi),....,e(mn)}(mi表示第i类问题的模型,模型的值是问题回答/评测结果/目标得分/服务质量等);
步骤3:根据步骤1和2得到的结果求得智能体在目标问题领域下的智能量
所述步骤1中的所述目标领域下问题类型i的概率μi可以通过统计
所述步骤2包括:
步骤21,收集智能体对目标领域各类问题的历史完成情况序列{(i,p,s)},i表示问题的类别,p表示状态(例如p可能包括测试时间、问题产生时间、问题产生地域等),s表示智能体的完成情况(问题回答/评测结果/目标得分/服务质量等);
步骤22,根据专家知识或已有经验选定目标领域下智能体能力变化的模型m;
步骤23,基于数据同化框架,结合模型m优化方法,拟合步骤21中的数据与模型{m1,m2,.....mn},求解模型参数,得到最优模型;
步骤24,通过{m1,m2,.....mn}计算出指定时间范围内的智能体对问题的期望完成程度{e(m1),e(m2),...,e(mi),....,e(mn)};
所述步骤23包括:
步骤231,使用数据拟合模型{m1,m2,.....mn},拟合的目标可以是最小化平方误差、最大似然等,拟合的方式根据模型来选择,得到当前数据下最优的模型{m1,m2,.....mn};
步骤232,构造数据同化的目标函数,一般数据同化系统中的目标函数由背景损失和模型损失两项组成,公式表示为
其中,j(x0)是目标函数;x0是状态矢量的初始值,它是被同化或被反演变量组成的列矩阵,下标0表示同化周期的开始;x0b是环境背景矢量,也就是x0带入m得到的模拟值;b是模拟值误差的协方差矩阵;i表示时刻;yi是i时刻的观测值;xi是x0带入模型算子m运行到i时刻得到的值;ri是观测误差的协方差矩阵;求解使j(x0)达到最小值的x0为初始时刻的最优解,也就是初始时刻的x(t0)同化值;
步骤233,获取新的数据,取随机值x0,与步骤231中的m一起,带入步骤232中数据同化的目标函数j(x0),可以采用遗传算法或差分进化等优化方法优化目标函数,得到目标函数的最优值,如果最优值小于自定义的阈值,则表明模型m能准确预估且具有良好的泛化性能,进入步骤24,否则将新的数据和当前数据一起带入步骤231;
所述步骤24包括:
步骤241,给出智能体的作用时间范围[t1,t2];
步骤242,在[t1,t2]上对模型mi进行积分,得到积分值pi;
步骤243,用积分值pi除以|t2-t2|,得到期望e(mi)。
所述步骤3中计算智能体的智能量,将问题出现的概率视为权重,对问题的期望完成程度进行加权求和得到智能体的智能量
本发明还公开了一种存储介质,存储有可执行指令,该可执行指令用于执行如前述的非人智能体的智能度量方法。
本发明还公开了一种用于非人智能体的智能度量装置,包括所述的存储介质,该智能度量装置调取并执行该存储介质中的可执行指令,以完成对非人智能体的智能度量。
本发明还提出了一种服务器,包括所述的用于非人智能体的智能度量装置,该服务器可以实现对非人智能体的智能度量。例如具有非人智能体的智能度量功能的单机、联网运行的应用程序。
附图说明
图1为通用智能计算方法流程图。
图2为数据同化框架。
图3为知识问答领域的公开数据集。
具体实施方式
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
实施例1:
上述方法把现实空间中的每个任务/挑战都视为一个问题,考虑在任意问题领域下智能体处理每一类小问题的期望完成程度,通过建立问题概率、期望完成程度与智能量之间关系的模型,利用已知的问题概率和期望完成程度来求得智能体的智能量。从而提供一种任何问题领域都适用的非人智能体智能的度量方法,由此形成一种通用智能度量方法。
在求解智能体的期望完成程度时,即使在同一个问题类别中,智能体的完成程度还受多种因素的影响,例如问题产生的时间、地域等,因此,本发明拟建立一个以影响因素和智能体历史完成数据为自变量的智能体能力预测模型,以得到在影响因素改变的情况下的智能体的预期完成程度,从而得到智能体的期望完成程度。同时,对于智能体能力预测模型的优化问题,在考虑数据误差和数据时空异构性的条件下,拟采用通常用于解决气象预报模型修正问题的数据同化框架,数据同化框架旨在通过不断向模型中输入新的多源的观测数据来修正模型参数,以得到最接近真实情况的模型参数,得到最优模型。
为实现上述目的,本方法包括如下步骤:
步骤1:统计目标问题领域下各问题的类型{1,2,...i...n}(s100)和概率{μ1,μ2,μ3,...μi...μn}(s110);
步骤2:建立智能体能力模型{m1,m2,.....mn}(s210),在数据同化框架下优化这些模型,使用m预测智能体的期望完成程度{e(m1),e(m2),...,e(mi),....,e(mn)}(mi表示第i类问题的模型,模型的值是问题回答/评测结果/目标得分/服务质量等)(s220);
步骤3:根据步骤1和2得到的结果求得智能体在目标问题领域下的智能量
所述步骤1中的所述目标领域下问题类型i的概率μi可以通过统计
所述步骤2包括:
步骤21,收集智能体对目标领域各类问题的历史完成情况序列{(i,p,s)},i表示问题的类别,p表示状态(例如p可能包括测试时间、问题产生时间、问题产生地域等),s表示智能体的完成情况(问题回答/评测结果/目标得分/服务质量等);
步骤22,根据专家知识或已有经验选定目标领域下智能体能力变化的模型m;
步骤23,基于数据同化框架,结合模型m优化方法,拟合步骤21中的数据与模型{m1,m2,.....mn},求解模型参数,得到最优模型;
步骤24,通过{m1,m2,.....mn}计算出指定时间范围内的智能体对问题的期望完成程度{e(m1),e(m2),...,e(mi),....,e(mn)};
所述步骤23包括:
步骤231,使用数据拟合模型{m1,m2,.....mn},拟合的目标可以是最小化平方误差、最大似然等,拟合的方式根据模型来选择,得到当前数据下最优的模型{m1,m2,.....mn};
步骤232,构造数据同化的目标函数,一般数据同化系统中的目标函数由背景损失和模型损失两项组成,公式表示为
其中,j(x0)是目标函数;x0是状态矢量的初始值,它是被同化或被反演变量组成的列矩阵,下标0表示同化周期的开始;x0b是环境背景矢量,也就是x0带入m得到的模拟值;b是模拟值误差的协方差矩阵;i表示时刻;yi是i时刻的观测值;xi是x0带入模型算子m运行到i时刻得到的值;ri是观测误差的协方差矩阵;求解使j(x0)达到最小值的x0为初始时刻的最优解,也就是初始时刻的x(t0)同化值;
步骤233,获取新的数据,取随机值x0,与步骤231中的m一起,带入步骤232中数据同化的目标函数j(x0),可以采用遗传算法或差分进化等优化方法优化目标函数,得到目标函数的最优值,如果最优值小于自定义的阈值,则表明模型m能准确预估且具有良好的泛化性能,进入步骤24,否则将新的数据和当前数据一起带入步骤231;
所述步骤24包括:
步骤241,给出智能体的作用时间范围[t1,t2];
步骤242,在[t1,t2]上对模型mi进行积分,得到积分值pi;
步骤243,用积分值pi除以|t2-t1|,得到期望e(mi)。
所述步骤3中计算智能体的智能量,将问题出现的概率视为权重,对问题的期望完成程度进行加权求和得到智能体的智能量
为了方便理解本发明的工作方式,特介绍本发明可能应用的领域之一——知识问答领域,然后详细介绍本发明应用于知识问答领域的过程。
知识问答的目标是回答人提出的自然语言问题,这对人类而言是非常简单和自然的事情,人类通过识别问题,搜索知识库,给出答案来进行问题的回答,对非人的智能体而言则通常需要涉及到自然语言处理、信息检索、数据挖掘等多个交叉领域的技术,通常这类智能体被称为问答系统(questionansweringsystem,qasystem)。为了测试问答能力,目前有许多公开的数据集,例如squad,newsqa,searchqa,race,coqa等,它们的问题包含维基百科、初高中考试、科普文章、新闻、电影、历史等多方面内容,coqa更是一种基于对话的问答数据集,可以用来辅助评测问答类服务的智能。目前问答系统也有很多,例如机器/模型类的有谷歌的bert模型,微软的nlnet模型,cmu的qanet模型,服务类的有苹果的siri,微软的cortana等,这些知识问答系统和人都可视为智能体。
本发明应用于知识问答领域的过程如下:
1.统计知识问答领域下各问题的类型和问题概率。
由于知识问答领域的数据集是按照问题进行分类(如图3所示),因此可以用数据库代表问题类型,本例中选择的问题类型列表为{1=squad,2=newsqa,3=searchqa,4=triviaqa,5=race,6=narrativeqa,7=coqa}。然后统计各个问题类型下问题的条目数,本例中为各个数据集的数据量,分别为{n1,n2,…,n7},各个问题类型的概率μi=ni/∑7i=1ni。
2.建立智能体能力模型{m1,m2,…..m7}。具体步骤如下:
2.1对各智能体进行多次实验,收集智能体对目标领域各类问题的历史完成情况{(i,p,s)},其中i为问题种类;p为状态,p包含产生问题的时间/地点、测量时间t等,在此可定义智能体第一次测量时间为t=0,其后每间隔一个单位时间(单位时间等于测量间隔时间的最小值),t自增1;对人和机器类智能体而言s表示对第i类问题在时间t下的回答的正确率(答对问题个数/问题总个数),对服务类智能体而言s表示服务的对象对第i类问题的回答的质量(w1*答对问题个数/问题总个数+w2*用户满意度,w1和w2表示自定义的权重,w1+w2=1,用户满意度取值范围为[0.0,1.0])。
2.2根据专家知识初始化知识问答领域智能体能力模型{m1,m2,…..m7}。
新西兰奥塔哥大学的教授,詹姆斯·r·弗林(jamesr.flynn),28年前发现全球人类的iq从20世纪初以来一直在持续增长。弗林调查了20多个国家的智力测试资料,发现iq得分每年增长0.3——也就是10年增长3点。这之后,将近30年的跟踪研究,证明了这一全球性变化的统计真实性(这一现象现在被称为弗林效应)。
由于人类iq测试本质上也是知识问答题目,所以知识问答领域的智能体能力可能也符合随时间变化的趋势,那么基于弗林效应,每个m可定义为基于时间预测的多变量自回归模型(ar,autoregressivemodel),多变量ar模型与其他模型相比可以方便地引入除时间变量之外的多个解释变量,例如地点、问题规模等,便于模型的扩展。多变量ar模型的公式为
其中,t表示时间,st为t时刻的能力值,s表示影响st的因素列表,包括t-j时刻的能力值、问题产生时间、问题产生地点、问题规模等,p表示自回归项数,a表示ar系数,∈表示噪声,∈一般为均值为0,方差为σ2的高斯噪声。自回归方法基于假设当前时期的指标值依赖于过去时期的指标值,对过去时期的指标值进行加权平均得到当前的指标。
2.3基于如图2所示的数据同化框架,结合模型优化方法,拟合步骤21中的数据与模型{m1,m2,.....mn},求解模型参数,得到最优模型。mi为问题类型i的模型,以模型mi为例,基于数据同化框架求解模型参数的步骤为:
2.3.1取得被观测系统时间序列数据,本例中为智能体对目标领域的第i类问题的历史完成情况序列{(p,s)},将数据处理为ar模型的输入格式,一个(i,p,s)形式的列表(s201);
2.3.2代入数据对ar模型进行拟合,得到参数{a1,...ap,b1,...bq},拟合目标为aic准则或bic准则,求解参数的方式为yule-walker方法,得到当前数据下最优模型m(s202);
2.3.3构造数据同化的目标函数,在本实例中为
其中,j(x0)是目标函数;x0为待同化的初始量,意义是预测的0时刻的完成情况,可初始化为一个随机数(s203);m是模型算子,此处为ar模型;m(x0)0是背景量,也就是x0状态下模型在0时刻的模拟值;t表示时刻;t是时间窗口大小;m(x0)t是x0带入m后在时刻t的值;st是t时刻的观测值;b是模拟值误差的协方差矩阵;rt是观测误差的协方差矩阵;由于本例的目标是为了得到在j(x0)最小的情况下的x0值,由于本例中的完成程度s和预测完成程度x0都是标量,因此本例中b和r均为1;最后该实例下的数据同化目标可简单视为最小化两项的和,前一项为预测值与模型值之差的平方,后一项是时间窗口内模型值与观测值之差的平方和。目标函数为
2.3.4采样新的观测数据{(p,s)},带入2.3.3的数据同化目标函数(s205),本例的应用场景下目标函数简单,可以直接采用求导的方式取到最优的x0,令
2.4通过{m1,m2,…..,mn}计算出指定时间范围内的智能体对问题的期望完成程度{e(m1),e(m2),…,e(mi),….,e(mn)}。以第i类问题的模型mi为例,考虑一定时间范围内智能体的能力,首先给出智能体的作用时间范围[t1,t2],然后在[t1,t2]上对mi模型进行积分,最后用积分值pi除以|t2-t1|,得到期望e(mi)。
3.计算智能体的智能量,将问题出现的概率视为权重,对问题的期望完成程度进行加权求和得到智能体的智能量
前面对发明内容进行了清晰的说明,但是,本实施例应当看作为举例,而不是限制性的。本发明并不局限于前面给出的细节,而可以在所附权利要求的范围内修改。在权利要求中,不减或步骤不隐含任何特定顺序的操作。除非在权利要求中制定说明。
- 还没有人留言评论。精彩留言会获得点赞!