基于深度学习的多源异构数据混合推荐模型的制作方法
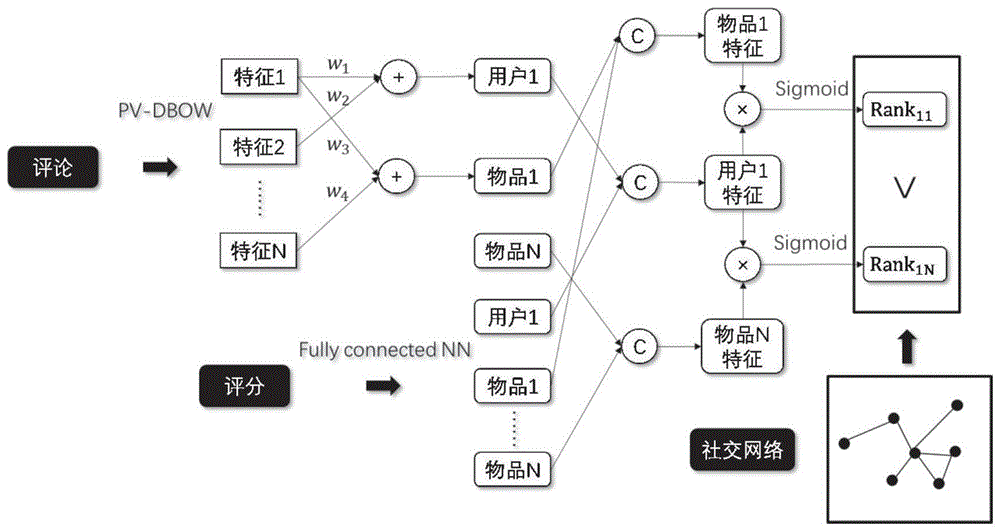
近年来深度学习被广泛应用在了图像和音频识别、文本分类和表示学习等领域,基于深度学习的推荐系统也成为学者们的研究热点。深度学习模型在图像、文本等特定数据的表示学习中都取得了极好的效果,避免了复杂的特征工程,可以得到异构数据的非线性多层次的抽象特征表示,克服了多种数据的异质性。目前,融合评分、评论和社交网络的深度学习推荐模型尚未提出。本专利基于深度学习算法,给出了一个具有较强拓展性的推荐模型。
背景技术:
目前的深度学习模型尚不能结合评分、评论和社交网络信息进行推荐。因为多源异构数据的特征表示尚存在困难,社交信息和其他用户和物品交互信息无法直接融合。若能采用深度学习方法学习不同异构数据的表示并将它们统一到一个深度学习模型中,将解决之前研究在算法融合上的需要选择不同算法的缺点,且使用深度学习学习特征表示,将显著提高推荐结果的准确度。为了充分利用这三种数据的优点,本专利融合评分、评论的特征并将社交信息加入到训练的过程中,提出了基于深度学习的多源异构数据推荐模型。
对于评论数据,传统的话题模型不能准确表示文本的特征,本专利通过PV-DBOW模型来学习评论文档的特征表示,PV-DBOW假定文档中的单词之间的独立性,并使用该文档来预测每个观察到的单词。PV-DBOW通过一个稠密向量来代表每个文档,这个向量被训练来预测文档中的单词。对于评分数据,传统的矩阵分解方法面临数据稀疏和准确率较低的困难,本专利使用神经网络训练评分,能够更好地体现用户和物品的特征。对于社交网络数据,本专利对在基于BPR的对学习方法上增加了用户的社交关系信息,使得该方法的采样更加合理,提高了推荐结果的准确度。
技术实现要素:
基于深度学习提出能够处理多源异构数据的推荐模型,模型具有准确度高、可扩展性强等优点。模型选择了基于深度学习的文本段落表示学习方法,设计了基于评分学习用户和物品特征的神经网络,并通过社交网络约束基于对的学习。由于现有的基于深度学习的文本表示学习的方法已经较为成熟,所以可以直接使用现有的网络,将其训练结果和其他特征融合一起进行训练,从而得到更加精确的融合特征表示。评分数据和文本数据不同的是,可以直接学习得到用户和物品的特征,所以不需要学习评分的向量表示,也不用学习实体特征。
基于深度学习的多源异构数据推荐模型包含三种数据:评论、评分和社交网络,每种数据都有自身的特点,从不同角度体现了用户或物品的特征。通过深度模型学习多种数据的向量表示,然后通过串联的方法得到用户或物品的融合特征。评论特征体现了用户对物品的态度,也可以用来表示物品的属性,模型通过PV-DBOW算法学习评论段落的特征表示,再加权叠加得到用户或物品的向量表示。评分特征是用户对物品的整体评价,体现了用户对物品的满意级别,使用BPR可以对用户和物品的非线性特征进行学习。社交网络体现了用户间的好友关系,间接影响了用户和物品之间的交互,利用社交网络关系可以加强对用户购买行为的约束,从而进一步提高推荐结果准确度。
上述方法包含了如下步骤:
(1)文本特征提取:使用PV-DBOW模型学习文本段落的特征向量表示。模型采用的是分布式的词袋模型(DistributedBag-of-Words),该模型使用一个段落向量来预测段落中随机采样得到的词语。
(2)评分特征提取:使用两层全连接的神经网络来学习用户对物品的评分。与文本特征学习模型不同的是,本方法可以直接得到用户和物品的特征向量表示,而不是直接提取评分的特征。
(3)用户物品特征融合:根据(1)求得的评论文本特征,可以将每位用户发出的评论特征向量加权求和得到用户特征,将物品收到的评论特征向量加权求和得到物品特征。最后使用融合函数将用户的文本和评分特征融合得到用户的融合特征,将物品的文本和评分特征融合得到物品的融合特征。
(4)基于BPR的优化:基于社交网络采样得到带有用户偏好的三元组,根据贝叶斯理论优化得到最佳模型参数。
(5)推荐:根据步骤(4)求得的模型参数,将用户和物品的特征向量输入到模型中为用户推荐物品。
在步骤(1)文本特征提取中,包括如下四个个步骤:
①文本预处理
将每个段落使用一个one-hot向量表示,代表段落矩阵中的一列。将评论文本中的词语进行去重,加入到词库中,每个词语使用唯一的one-hot向量表示。构建完成后,评论矩阵中每一列都能够唯一对应一个评论。
②词语采样
模型使用一个段落向量来预测段落中的词语,其中段落中的词语通过在段落中随机采样得到。每个词在段落中被看作独立的存在,且词语的顺序不影响段落向量的学习结果。
③最优化
使用步骤①中段落的向量作为输入,使用步骤②采样得到的词语作为输出,不断迭代,训练段落向量模型。该模型基于神经网络构建,采用softmax分类器,使用随机梯度下降法求得模型参数。
④评论文本的特征表示
训练完成后,段落矩阵的每一列即为每段评论的特征向量。使用步骤①定义的每段评论的one-hot向量和矩阵相乘,即可得到当前段落的特征表示。
步骤(2)评分特征提取包括如下三个步骤:
①神经网络构建
评分特征提取模型基于两层全连接的神经网络,使用ELU激活函数。神经网络的输入为用户的特征和物品的特征元素相乘的结果。神经网络输出为用户对物品的评分。
②用户物品特征优化
根据目标函数,使用随机梯度下降法不断优化用户和物品的评分特征向量,降低损失。当预测评分和实际评分较为接近时,停止训练,即可得到用户和物品的评分特征。
步骤(3)将步骤(1)和步骤(2)的特征进行融合得到新的融合特征。
评分特征代表了用户对物品的总体评价,简单明确,而评论中包含了用户的不同观点,更加详细。步骤(3)将评论和评分特征进行融合,得到更加丰富全面的用户特征表示。融合的方法采用的是将评论特征向量和评分特征向量进行串联,得到融合的特征表示向量。
步骤(4)基于BPR的优化主要包含以下步骤:
①三元组生成
因为用户的偏好往往和他们的好友具有相似性,在现实中的反映就是用户更加容易选择其好友购买或偏爱的物品。将用户之间的这种偏好的相似性应用到BPR模型的采样中来,通过给采样过程更加合理的约束,得到更加符合用户行为的三元组,从而提高后续模型训练和推荐的准确度。
②模型优化
提出统一的目标函数进行模型优化。前文已经提出了多源异构数据的融合函数,现在需要根据融合特征构建目标函数,使得学习过程中融合特征能够更加准确代表用户或物品的特征。可以使用随机梯度下降法进行求解,现有的深度学习框架都集成了随机梯度下降算法,可以通过调用方法库得到最终的用户和物品的特征向量。
步骤(5)为用户推荐感兴趣的物品。
每个用户和其他未购买或未浏览的物品的特征向量相乘即可得到该用户对该物品的偏好得分,分数越高代表用户越有可能购买或浏览该物品。将所有物品的得分降序排列取前N个就能够求得用户的Top-N推荐列表。
附图说明
图1是基于多源异构数据的混合推荐模型流程图。
具体实施方式
根据说明书中的方法介绍,实施基于多源异构数据的推荐模型需要如下步骤:
(1)文本特征提取
①文本预处理
使用duv来表示用户u对物品v的评论文本,评论文本包含的词语使用w来表示,通过用户对物品的评论学习到的用户和物品的特征向量使用u1和v1来表示,段落的特征向量使用duv来表示,词向量使用w来表示,所有评论的词语都储存在词库V中。这些特征向量的维度数都为K。
②词语采样
对于每个段落,随机选取一个文本区域,从该区域中随机采样采样一些词语,作为训练分类器的结果。文本区域的大小和在该区域中选取词语的数目人工设定。
③最优化
每段评论都会被映射到一个随机的高维语义空间中,然后对段落中包含的词进行预测,通过学习优化,得到较为精确的段落特征向量表示。根据词袋模型的假设,每个词w在文档duv中出现的概率使用softmax进行计算:
其中w’表示属于词库V的全部词语,exp表示以e为底的指数函数。通过此公式可以求得文档中任意词语出现的概率。在实际最大化出现词语概率的过程中,梯度求解的求解开销较大。为了降低计算的开销,在计算过程中往往采用负采样的方法,在未出现的词语中根据一个预定义的噪声分布来采样部分词语,作为负样本进行近似计算,而不是使用词库中所有的词语。基于负采样的策略,那么PV-DBOW的目标函数被定义为:
上式将所有的词语和文档的组合都进行了相加,其中是词w在文档duv中出现的次数,如果未出现则函数值为0。代表的是sigmoid函数,t为负样本的个数,表示的是在噪声分布PV中,的期望。
④评论文本的特征表示
根据上述的目标函数,可以得到文档的特征表示duv,和本文提出的基于传统机器学习方法的推荐模型中类似,用户和物品的特征向量可以根据评论的特征向量来表示。不过此处用户和物品的特征表示不再由评论特征向量的平均来计算,而是通过后续的模型集成优化来学习得到的。
将用户所有评论的特征向量加权相加并归一化得到用户特征因子:
其中Du表示用户u所有的评论数,p'uk表示用户在话题k上的总概率,Wuv表示用户u对于发出的第i个评论的权重,puk是其归一化的表示。用户u的特征因子为:
pu=(pu1,...,puK)
用户特征因子维数为K。物品特征因子可采用类似公式计算:
其中Dv表示物品收到的所有评论数,q'vk表示物品在话题k上的总概率,qvk是其归一化的表示,Wuv表示物品v对于收到的第u个评论的权重。物品的特征因子为:
qv=(qv1,...,qvK)
K为物品的维度数,和用户保持一致。
其中Wuv为评论duv对于用户u和物品i的权重,通过权重才能对不同评论的重要程度作出区分,从而构建合理的用户和物品特征。
(2)评分特征提取
①神经网络构建
使用两层全连接的神经网络来训练得到最终的用户对物品得分。可以直接得到用户和物品的特征向量表示。定义rui来表示用户u对物品i的评分,那么对于任意的评分rui有用户ru和对应的物品ri与之对应。则可以得到两层神经网络预测公式:
rui=φ(U2·φ(U1(ru⊙ri)+c1)+c2)
其中⊙表示元素相乘,φ(x)为ELU激活函数,U1、U2、c1和c2为需要学习的权重和偏差参数。
②用户物品特征优化
目标函数即为预测评分和真实评分相减的平方,优化参数使得目标函数最小即可得到最佳的用户和物品表示。
(3)用户物品特征融合
通过用户和物品之间的交互信息构建用户和物品的特征向量。提出一个融合特征的函数f(·),假设从评分和文本数据中学习到的特征表示为x1,x2,那么通过融合函数则可以得到融合后的特征:
x=f(x1,x2)
其中x即为融合后的特征。使用简单的串联方式进行融合,能够增强用户和物品特征的扩展性,这对于基于多源异构数据的模型具有重要的意义。那么通过函数f(·)得到的特征为
(4)基于BPR的优化
①三元组生成
根据用户的购买或浏览记录以及社交网络,对于每个用户u,将该用户购买或浏览过的物品定义为i,将用户从未接触过的物品定义为j,再将该用户好友购买过的物品定义为p。系统中所有的物品集合定义为D,那么用户u购买和浏览过的物品集合定义为Du,用户好友购买过的物品定义为Dp。最能代表用户偏好的物品首先是用户已经购买的物品Di,其次,根据好友偏好的相似性,用户很可能会购买其好友购买过但是该用户未购买的物品Dp\Du。最后,用户最不可能购买的物品即为D\(Du∪Dp)。根据社交网络信息构建用户和物品的三元组作为训练集,该训练集T可以被表示为:
T:={(u,i,j)|i∈(Du∪Dp),j∈D\(Du∪Dp)}
其中(u,i,j)为用户物品三元组,代表用户u对于物品i的偏好程度大于物品j。其中物品i属于用户购买过或者用户直接好友购买过的物品,物品j属于用户为购买过且其直接好友也未购买过的物品。这样就基于用户的直接好友关系构建了用户物品三元组,用于后续BPR模型的训练。
②模型优化
根据前面的定义已知用户u对物品i的偏好程度大于物品j。使用函数g(·)来表示结合用户和物品特征表示的损失函数,此处本文将g(·)定义为sigmoid函数来计算用户对不同物品的不同偏好程度,那么有g(u,i,j)=σ(uTi-uTj)。所以整个融合多源异构数据的推荐模型的目标函数被定义为:
其中W为每种模型的权重参数,在评论表示学习模型中用户的每条评论的权重参数都不相同,需要通过学习得到。而在评分计算的模型中,求得的直接是用户和物品的特征,也就是权重参数设置为1即可,不需要通过优化目标函数进行更新。其中Θ代表的是模型中需要学习的其他参数,Θ={Θ1,Θ2}={{w,duv},{U1,U2,c1,c2,ru,ri}}。λ为每种模型的惩罚参数,他们的取值都在[0,1]区间上。评分模型的目标函数之前添加了负号,因为评分模型的目标函数需要最小化,而总体模型的目标函数是最大化。
(5)推荐
个性化的推荐列表就可以通过用户和物品的特征向量相乘得到:
s=uTv
每个用户和其他未购买或未浏览的物品的特征向量相乘即可得到该用户对该物品的偏好得分,分数越高代表用户越有可能购买或浏览该物品。将所有物品的得分降序排列取前N个就能够求得用户的Top-N推荐列表。
- 还没有人留言评论。精彩留言会获得点赞!