一种基于深度学习的风控建模方法与流程
本发明涉及风控计算领域,尤其涉及一种基于深度学习的风控建模方法。
背景技术:
在互联网金融快速发展的今天,用户的数据更加复杂,既包含高维的结构化数据也会包含文本、图像等非结构化数据,所以在这样的情况下,更加凸显了对互联网海量数据进行风控建模的重要性。
目前在互联网金融行业,逻辑回归算法是主流的风控建模技术,该技术简单易用,具有较好的可解释性且效果不错。张保强(张保强.互联网小贷违约风险评估与风控模型改进策略研究[d].浙江大学,2018.)使用逻辑回归方法进行风控建模来对现金贷数据进行风险评估。刘哲(刘哲.逻辑回归模型在小额信贷企业中风控环节的应用研究[d].首都经济贸易大学,2018.)也是运用逻辑回归模型测度小额信贷中的信用风险。喻光丽(喻光丽.基于logistic回归模型的p2p网络借贷平台借款人信用风险评估研究[d].兰州大学,2017.)分析了p2p网络借贷平台借款人信用风险的成因,然后选择逻辑模型进行p2p网络借贷平台借款人信用风险评估。刘冰清等人(刘冰清,卢子芳,朱卫未,尹相菊.基于logistic-dea的互联网金融贷款产品有效客户识别[j].管理现代化,2018,38(04):1-4.)提出一种改进的逻辑回归方法,并使用该方法来识别互联网贷款产品的潜在客户,使得客户的短信回应率得到了显著的提高。熊正德等人(熊正德,刘臻煊,熊一鹏.基于有序logistic模型的互联网金融客户违约风险研究[j].系统工程,2017,35(08):29-38.)将客户由"违约"与"不违约"两类细分为"提前结清"、"当前正常"、"可疑"、"损失"四类,然后利用有序多分类逻辑模型进行客户违约风险研究,得出了更好的效果。
以目前市场上存在的产品fico评分为例,该评分是fairisaac公司开发的信用评分系统,也是目前美国应用得最广泛的一种(https://www.cnblogs.com/nxld/p/6364341.html)。该评分通过分析客户的人口统计学信息、历史贷款还款信息、历史金融交易信息和银行征信信息,最终使用逻辑回归模型构建最终的分数。
除了逻辑回归算法,基于机器学习的风控建模方法的研究应用也越来越多。赵静娴(赵静娴.基于决策树的信用风险评估方法研究[d].天津大学,2009.)分析了不同信用风险评估方法的特点,提出了基于决策树的信用风险评估方法。李进(李进.基于随机森林算法的绿色信贷信用风险评估研究[j].金融理论与实践,2015(11):14-18.)认为传统评估方法很难适用绿色信贷信用风险评估中所面临的复杂性、非线性及不确定性等问题,所以提出了基于随机森林算法的信用风险评估,发现基于随机森林算法的评估,速度更快,效果更好。王梦雪(王梦雪.基于机器学习技术的p2p风控模型研究[d].哈尔滨工业大学,2017.)讨论了在p2p场景下使用机器学习技术(随机森林、gbdt等算法)进行风控建模的研究,并得到了不错的效果。
目前支付宝上的芝麻信用分就是通过比较复杂的机器学习技术来构建的(http://www.chinacpda.org/anlifenxi/5443.html)。目前比较前沿的一些算法,如决策树、随机森林、支持向量机、神经网络等,芝麻信用都在研究尝试。
在本研究场景中,要对大量结构化数据(例如:年龄、性别等)和非结构化数据(文本)进行统一的风险建模,不论是逻辑回归还是基于机器学习的风控技术都难以提供一个统一的框架来进行建模,所以本发明提出了一种基于深度学习的风控建模方法来解决该场景下建模。
技术实现要素:
本发明旨在至少解决现有技术中存在的技术问题,特别创新地提出了一种基于深度学习的风控建模方法。
为了实现本发明的上述目的,本发明提供了一种基于深度学习的风控建模方法,包括如下步骤:
s1,通过云端数据库获取用户数据,将用户数据区分为结构化数据和非结构化数据,并将用户数据进行初步筛选;
s2,将初步筛选后的用户数据提取特征与分词,并将用户数据中的结构化数据使用随机森林算法中的重要性进行降序排序,然后筛选结构化数据变量,对非结构化数据洗净性分词操作;
s3,建立深度学习网络风控模型,然后训练深度学习网络风控模型;
s4,使用训练后的深度学习网络风控模型,计算出风控分数,该分数被部署服务接口,供客户调用使用。
优选的,所述s1包括:
s1-1,风控数据包括结构化数据和非结构化数据,对结构化数据的清洗,包括变量过滤、记录过滤、缺失值填充、字符型变量映射和数据归一化;变量过滤是指对缺失值超过一定阈值的变量进行删除,也就是数据的列删除,记录过滤与变量过滤类似,缺失值填充分两种:连续型变量缺失值填充和离散型变量缺失值填充;连续型变量的填充我们使用该变量的均值来填充,离散型变量的填充我们使用该变量的中位数来填充;进行字符型变量映射,通过模型训练的数据必须得是数值型,所以对于字符型变量进行变换,通过上面的步骤把所有的数据都处理成了数值型,然后进行用户数据归一化;
s1-2,对文本数据进行清洗,文本数据的时间戳是到秒的,对记录id分组,然后对时间戳进行升序排序,然后对每个id下的文本拼接起来,这样就生成了与时间有关的文本序列;然后基于文本序列的长度对记录进行过滤。
优选的,所述s2包括:
s2-1,将用户数据初步筛选之后,进行特征提取与分词的操作;
s2-2,特征提取是针对结构化数据操作的,特征提取为变量选择,结构化数据中变量个数在3000-4000,特征提取的目的是筛选出有用的变量,过滤掉无用或者作用非常小的变量;使用随机森林算法进行特征选择,该指标对所有变量进行降序排列,然后根据阈值选择变量,
s2-3,分词是针对文本数据来操作,使用pkuseg分词库,分词结束后,建立词表索引,然后对分词结果建立one-hot编码,这样就把文本分词向量转化为了数值向量,为建立深度学习网络模型作好准备。
优选的,所述s3包括:
s3-1,建立深度学习网络模型由两部分组成,一个是wide部分,由结构化输入所对应的左边部分,另一个是deep部分,由文本输入所对应的右边部分;wide部分就是由步骤(2)中进行特征提取得到的变量,通过deep部分包含了嵌入层、lstm层和cnn卷积层;
s3-2,首先是生成词向量的嵌入层,词嵌入其实是一个从高维到低维的映射过程,通过该操作可以极大降低计算量;从s2中得到了文本数据的one-hot编码,称为输入矩阵hnm,输出矩阵称为enl,其中n是样本数量,m是输入矩阵的维数,l是输出矩阵的维数,则输入矩阵与输出矩阵二者之间的关系如公式1所示:
hnmwml=enl(1)
s3-3,其次是lstm层;lstm算法是由rnn算法改进而来,主要的改进就是在每个细胞中引入了三个门操作:遗忘门、输入门和输出门;
s3-4,通过遗忘门删掉了一些旧信息,然后通过输入门来保留一些当前时刻的新信息,这里输入门的定义与遗忘门的定义类似,
s3-5,当前细胞状态下的输出结果ht由下面的公式8给出:
ht=ot*tanhct(8)
然后是cnn卷积层;卷积层的核心是对序列做卷积运算,在本发明中将卷积操作放到lstm层的后面是为了通过卷积操作继续提炼局部特征,事实证明这种结构可以达到更好的效果;在本发明中卷积操作来源于离散卷积操作,其公式如下:
其中g(n)是经过卷积运算得到的新序列,f(i)是卷积核,h(n-i)是输入数据;卷积操作之后接一个maxpooling池化操作,使用的池化核是2*2矩阵;
s3-6,形成输出层,该输出层将wide部分的变量和deep部分的输出拼接起来,通过sigmoid函数输出最终的结果。
优选的,所述3-2包括:
其中wml是权重,具体展开如下面的公式2所示:
通过上面的词嵌入操作,我们将高维稀疏矩阵转换为了低维紧密矩阵,大大降低了模型的计算量。
优选的,所述3-3包括:
遗忘门的主要作用是控制删掉哪些旧的信息,控制函数有下面的公式3来定义的;
ft=σ(wf[ht-1,xt]+bf)(3)
ft是遗忘门的当前t时刻的控制函数,该值的取值是0或者1的向量,σ是sigmoid函数,wf是遗忘门权重,ht-1是上一时刻t-1细胞的输出,xt是当前时刻t的输入,bf是遗忘门偏移量;然后ft*ct-1就是遗忘门的结果,对上个时刻t-1的细胞状态进行过滤,删除掉ft中等于0所对应的ct-1中的信息,也就是把一些旧信息遗忘掉了;这里*是点乘操作,ct-1是上个时刻t-1的细胞状态。
优选的,所述3-4包括:
公式4所示:
it=σ(wi[ht-1,xt]+bi)(4)
it是输入门的控制函数,σ是sigmoid函数,wi是输入门权重,ht-1是上一时刻t-1细胞的输出,xt是当前时刻t的输入,bi是输入门偏移量;输入门决定了当前网络的输入有多少被保留到当前的细胞状态ct中,细胞状态ct由上个时刻保留下来的状态ft*ct-1和当前网络输入下的新增候选状态
其中
计算出了当前细胞状态ct后,最后通过输出门决定了哪些信息要输出,输出门函数的定义如公式7所示:
ot=σ(wo[ht-1,xt]+bo)(7)
其中ot是输入门的控制函数,σ是sigmoid函数,wo是输入门控制权重,ht-1是上一时刻t-1细胞的输出,xt是当前时刻t的输入,bo是输入门控制偏移量;ot的目的就是为了决定ct中哪些要输出,ot中取值为1的就是需要输出的,0是不要输出。
优选的,所述3-5包括:
sigmoid函数的公式如下所示:
该函数会输出一个(0,1)的数值。然后通过如下公式计算出风控分数:
该score风控分数值是由公式10获得的结果转换而来,该值通常的取值范围为(0-1000),这个值就是我们要用到的风险信用分,该分值越小则风险越大,该分值越大说明风险越小,其中round是取整操作。
优选的,所述s4包括:
s4-1,在深度学习网络模型的模型评估中,ks值和auc值是最常用的评估指标,ks衡量的是好坏样本累计分部之间的差值;如果ks指标不符合要求,调整深度学习网络及参数,返回到数据清洗阶段重新运行数据挖掘过程,以达到好的效果;
s4-2,深度学习网络模型部署与监控,模型通过评估之后,最后要把模型部署上线,先部署到测试环境,然后进行压力测试、负载均衡测试及其他技术测试;这里我们进行压力测试使用的是jmeter软件进行的,负载均衡通过ha来配置的;接着把模型调用封装成http接口供测试调用,并把调用的相关信息写到日志中记录下来做监控使用,如果出现异常问题可以及时处理。
综上所述,由于采用了上述技术方案,本发明的有益效果是:
该方法的核心是深度学习网络的构建,我们称之为wide+(lstm+cnn)的结构,是wide+deep网络的一种改进。
1)本发明使用wide层解决了高维结构化数据入模问题,这些自变量与目标变量的关系都比较弱,这是逻辑回归算法不能适应的。
2)本发明使用词向量技术解决了非结构化数据(文本)所要进行的繁复的特征工程,用词向量做为lstm+cnn层的输入,该层可以学习文本的上下文信息,这就解决了基于机器学习技术的风控方法在文本数据建模上的缺点。
3)本发明解决了针对结构化数据与非结构化数据(文本)使用统一的框架来进行数据建模,并提炼特征词进行输出展示。
4)提出的基于深度学习的风控数据建模方法,从技术上来看,首先深度学习在处理非结构化数据时具有优势,其次深度学习具有更强的学习能力,最后我们所提出的方法来自于wide+deep这样的网络结构,该结构为统一处理结构化数据与非结构化数据提供了一个非常好的框架。
5)从经济上来看,目前与人工智能相关的产业发展迅猛,机器人、自动驾驶、智能语音、人脸识别等开始越来越深入的影响到人们的生活,人工智能相关产业未来会有更多的公司参与,而人工智能的技术核心之一就是深度学习,毫无疑问,人工智能会成为未来的高端产业,深度学习就是高端产业中的核心技术。
本发明的附加方面和优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
附图说明
本发明的上述和/或附加的方面和优点从结合下面附图对实施例的描述中将变得明显和容易理解,其中:
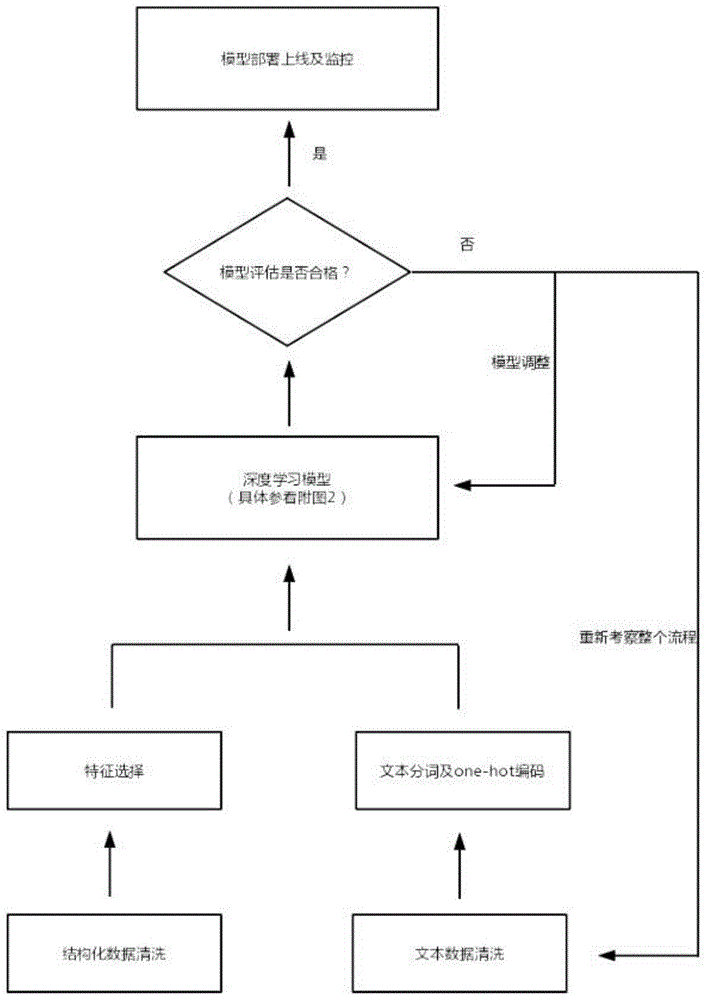
图1是本发明工作流程图;
图2是本发明实施效果图。
具体实施方式
下面详细描述本发明的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本发明,而不能理解为对本发明的限制。
如图1所示,本发明提出了一种基于深度学习的风控建模方法,所采用的具体技术方案包括如下步骤:
1)数据清洗。对结构化数据进行缺失值填充和数据归一化处理。对文本数据进行文本拼接和去除停用词的处理。数据清洗的主要目的是去除无意义或无效数据,并整理成统一格式,为后面建模做准备。
2)特征提取与分词。对结构化数据使用随机森林算法中的重要性进行降序排序,然后筛选变量,这就是特征提取的步骤。对文本数据进行分词并建立one-hot编码。这步是进入模型前的准备工作。
3)建立并训练深度学习网络模型。我们提出了一种wide+(lstm+cnn)网络结构,其中wide部分用来处理结构化数据的变量,该部分相比基于逻辑回归的风控建模方法,可以训练更多与目标变量弱相关的变量。deep部分用来处理文本数据,该部分主要包括输入层、嵌入层、lstm层、卷积层和输出层。输入层就是由步骤2)生成的文本数据的one-hot编码向量,然后通过词嵌入操作生成嵌入层,词嵌入可以将稀疏的高维变量转换成紧密的低维度变量,可以极大降低计算量。lstm层是学习文本内容的核心网络层,该层中所使用的lstm算法是由rnn循环神经网络改进而来,lstm算法有三种门(或者开关)来控制信息的学习:遗忘门、输入门和输出门。遗忘门决定了上一时刻的单元状态有多少保留到当前的单元状态,所以遗忘门可以学习到重要的历史特征,输入门决定了当前时刻的网络输入有多少保留到当前的单元状态,所以输入门可以学到当前输入的重要特征,输出门决定了当前单元状态有多少需要输出。通过这三个门的操作,lstm算法不仅可以长记忆的特征,也可以学习到短记忆的特征,因此可以学习到文本数据的上下文语义信息,这是传统的基于逻辑回归的风控建模方法和基于机器学习的风控建模方法所以难以达到的。卷积层的应用是用来进一步提炼局部特征,使得模型的学习能力更加聚焦。输出层将wide的输出与deep的输出拼接到一起,然后通过sigmoid函数输出最后的结果值,最后根据一个映射关系将该结果值转换成信用分数。该部分是我们所提出的基于深度学习的风控建模方法的核心,我们使用了一个统一的框架来对结构化数据与非结构化(文本)数据进行风控建模,而且在文本数据的处理考虑了上下文语义信息,加上深度学习网络相对于逻辑回归和机器学习的方法具有更强大的学习能力,所以我们所提出的方法可以产生更好的效果。
4)模型评估。模型训练完后,我们通过交叉验证的方式对模型进行评估。评估的指标主要是ks值和auc值,这两个指标是做风控模型中最常用的指标,通常这两个值越大,说明模型的效果越好。我们也设置了下限,例如ks如果小于0.2,那么就说明该模型是不合适的,没有有效性。那么我们会返回到步骤3)中检查模型的建立过程以及各种参数的调整,如果模型调整完后再次进行评估还是不能满足要求的话,那么我们会返回到步骤1)重新检查从数据清洗开始的过程,模型评估就是这样一个循环的过程。
5)模型部署及监控。模型部署后要进行压力测试、负载均衡测试及其他测试,然后对模型的输入输出结果写入数据库,并定时查询进行监控,以便遇到异常可及时处理。
以上就是我们所提出的基于深度学习网络的风控建模方法的技术方案,该方案的流程可参看附图1,附图1描述了整个技术方案的主要步骤。技术方案的第三步骤可参看附图2,附图2比较详细的给出了深度学习网络的整个框架。
下面对本发明的基于深度学习的风控建模方法给出具体的实施步骤:
步骤(1)数据清洗。
数据包括结构化数据和非结构化数据,首先介绍下结构化数据的清洗,包括变量过滤、记录过滤、缺失值填充、字符型变量映射和数据归一化。变量过滤是指对缺失值超过一定阈值的变量进行删除,也就是数据的列删除,这里我们使用的阈值是95%,即如果该变量数据缺失超过95%,那么我们就删除该变量。记录过滤与变量过滤类似,不过记录过滤是对行所做的,即当一行记录中变量的缺失超过95%时,则删除该行记录。缺失值填充分两种:连续型变量缺失值填充和离散型变量缺失值填充。连续型变量的填充我们使用该变量的均值来填充,离散型变量的填充我们使用该变量的中位数来填充。字符型变量映射,因为我们通过模型训练的数据必须得是数值型,所以对于字符型变量我们要进行变换,例如性别变量(男,女)我们要映射成(1,0)。通过上面的步骤我们把所有的数据都处理成了数值型,最后我们还要把数据进行归一化,这里我们使用的归一化方法是minmaxscale日方法,这样就把数据统一到一个标准下,利于数据的建模。
其次对文本数据进行清洗。我们的文本数据的时间戳是到秒的,所以首先对记录id分组,然后对时间戳进行升序排序,然后对每个id下的文本拼接起来,这样就生成了与时间有关的文本序列。接着我们要基于文本序列的长度对记录进行过滤,这里我们设置的阈值是100,即该用户id至少得有100字的文本内容。最后我们对文本中无意义的字或词进行清洗,例如的、之、乃、么等词。
步骤(2)特征提取与分词。
通过步骤1)的数据清洗后,这步要进行特征提取与分词的操作。特征提取是针对结构化数据操作的,分词是针对文本数据来操作的。首先介绍下特征提取。特征提取我们可以通俗的理解为变量选择,我们结构化数据中变量个数在3000-4000,特征提取的目的是筛选出有用的变量,过滤掉无用或者作用非常小的变量。这里我们使用随机森林算法进行特征选择,随机森林算法可以提供一个变量重要性的指标,我们根据该指标对所有变量进行降序排列,然后根据阈值选择变量,我们这里设定的阈值是450,即选择重要性排前450的变量。然后介绍下分词,我们使用过jieba分词库和pkuseg分词库,我们发现pkuseg分词的效果要比jieba分词的效果好,所以最终使用了pkuseg分词库。该库是由北京大学开发的开源分词库。最后,分词结束后,我们建立了10000词的词表索引,然后对分词结果建立one-hot编码,这样就把文本分词向量转化为了数值向量,为进入模型作好了准备。
步骤(3)建立并训练深度学习网络模型。
该网络结构有两部分组成,一个是wide部分,由结构化输入所对应的左边部分(参看附图2),另一个是deep部分,由文本输入所对应的右边部分(参看附图2)。wide部分就是由步骤(2)中进行特征提取得到的变量,在经典的wide+deep算法中,wide部分的变量还做了两两交叉,本发明中不需要做这个操作,因为本发明中用到的原始数据3000-4000个变量已经做过了变量的两两交叉运算,所以本发明中的wide部分直接使用由步骤(2)所得到的变量。下面介绍下deep部分的算法,本发明deep部分包含了嵌入层、lstm层和cnn卷积层,下面一一进行说明。
首先是生成词向量的嵌入层,词嵌入其实是一个从高维到低维的映射过程,通过该操作可以极大降低计算量。从上面的步骤(2)中我们得到了文本数据的one-hot编码,我们称为输入矩阵hnm,输出矩阵我们称为enl,其中n是样本数量,m是输入矩阵的维数,l是输出矩阵的维数,则输入矩阵与输出矩阵二者之间的关系如公式1所示:
hnmwml=enl(1)
其中wml是权重,具体展开如下面的公式2所示:
通过上面的词嵌入操作,我们将高维稀疏矩阵转换为了低维紧密矩阵,大大降低了模型的计算量。
其次是lstm层。lstm算法是由rnn算法改进而来,主要的改进就是在每个细胞中引入了三个门操作:遗忘门、输入门和输出门。遗忘门的主要作用是控制删掉哪些旧的信息,控制函数有下面的公式3来定义的。
ft=σ(wf[ht-1,xt]+bf)(3)
ft是遗忘门的当前t时刻的控制函数,该值的取值是0或者1的向量,σ是sigmoid函数,wf是遗忘门权重,ht-1是上一时刻t-1细胞的输出,xt是当前时刻t的输入,bf是遗忘门偏移量。然后ft*ct-1就是遗忘门的结果,对上个时刻t-1的细胞状态进行过滤,删除掉ft中等于0所对应的ct-1中的信息,也就是把一些旧信息遗忘掉了。这里*是点乘操作,ct-1是上个时刻t-1的细胞状态。
通过遗忘门删掉了一些旧信息,然后通过输入门来保留一些当前时刻的新信息,这里输入门的定义与遗忘门的定义类似,如公式4所示:
it=σ(wi[ht-1,xt]+bi)(4)
it是输入门的控制函数,σ是sigmoid函数,wi是输入门权重,ht-1是上一时刻t-1细胞的输出,xt是当前时刻t的输入,bi是输入门偏移量。输入门决定了当前网络的输入有多少被保留到当前的细胞状态ct中,细胞状态ct由上个时刻保留下来的状态ft*ct-1和当前网络输入下的新增候选状态
其中
计算出了当前细胞状态ct后,最后通过输出门决定了哪些信息要输出,输出门函数的定义如公式7所示:
ot=σ(wo[ht-1,xt]+bo)(7)
其中ot是输入门的控制函数,σ是sigmoid函数,wo是输入门控制权重,ht-1是上一时刻t-1细胞的输出,xt是当前时刻t的输入,bo是输入门控制偏移量。ot的目的就是为了决定ct中哪些要输出,ot中取值为1的就是需要输出的,0就是不要输出的。
最后当前细胞状态下的输出结果ht由下面的公式8给出:
ht=ot*tanhct(8)
然后是cnn卷积层。卷积层的核心是对序列做卷积运算,在本发明中将卷积操作放到lstm层的后面是为了通过卷积操作继续提炼局部特征,事实证明这种结构可以达到更好的效果。在本发明中卷积操作来源于离散卷积操作,其公式如下:
其中g(n)是经过卷积运算得到的新序列,f(i)是卷积核,h(n-i)是输入数据。卷积操作之后接一个maxpooling池化操作,使用的池化核是2*2矩阵。
最后是输出层。该层将wide部分的变量和deep部分的输出拼接起来,通过sigmoid函数输出最终的结果,sigmoid函数的公式如下所示:
该函数会输出一个(0,1)的数值。然后通过如下公式计算出风控分数:
该score风控分数值是由公式10获得的结果转换而来,该值通常的取值范围为(0-1000),这个值就是我们要用到的风险信用分,该分值越小则风险越大,该分值越大说明风险越小,其中round是取整操作。
步骤(4)模型评估。
在深度学习网络模型的模型评估中,ks值和auc值是最常用的评估指标。以ks值为例,ks衡量的是好坏样本累计分部之间的差值。ks值的范围通常在(0.2,0.7),小于0.2模型的区分能力很差,但是太大也可能有风险,有可能是数据问题导致的,也可能是模型过拟合。如果ks指标不符合要求,我们就要调整深度学习网络及参数,甚至返回到数据清洗阶段重新考察整个流程,以达到好的效果。
步骤(5)模型部署与监控。
模型通过评估之后,最后要把模型部署上线,一般先部署到测试环境,然后进行压力测试、负载均衡测试及其他技术测试。这里我们进行压力测试使用的是jmeter软件进行的,负载均衡通过ha来配置的。接着把模型调用封装成http接口供测试调用,并把调用的相关信息写到日志中记录下来做监控使用,如果出现异常问题可以及时处理。当测试没问题后,就可以正式部署到生产上,这样就可以服务到客户了。
尽管已经示出和描述了本发明的实施例,本领域的普通技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!