提高相关性的神经问题生成方法与流程
本发明涉及问题生成领域,具体涉及一种提高相关性的神经问题生成方法。
背景技术:
问题生成(Question Generation,QG)是自然语言处理中一个非常重要的问题,是考验计算机是否真正理解文本的一项重要途径,并广泛应用于各个领域。QG可以为问答系统(Question Answering,QA)创建大量的QA对,为相关任务提供数据集。同时,QG本身也可以为医疗诊断系统、家庭教育系统等提供服务。QG任务的输入通常包含文档(或句子)和答案,输出是在给定文档和目标答案的情况下,生成最有可能的问题。
一般来说,QG模型是一个序列到序列的结构(Sequence to sequence,seq2seq),由一个编码器(encoder)和解码器(decoder)组成,encoder将输入的文档和目标答案编码成向量(也称为源端),然后decoder根据这个向量逐字生成一个完整的问题(也称为目标端)。为了增强模型的性能,通常还会有注意力(attention)机制和拷贝(copy)机制。
相关技术:
(1)Leveraging Context Information for Natural Question Generation。文章构造一个seq2seq的模型,将文档和目标答案作为输入,旨在生成一个合理的问题。这个模型带有attention机制和copy机制。
传统技术存在以下技术问题:
QG模型是个seq2seq的结构,并且通常会加入copy机制来保证生成问题的可靠性。
实际上,由于生成模型的特性,QG模型往往会趋向于生成一些较为通用的问题,比如“他叫什么名字?”、“他是谁?”、“它是什么?”。这种问题具有极强的一般性,针对于不同的输入都可以提出类似的问题,因此非常受到QG模型的青睐。但实际上,这种通用性问题并不是我们想要的好的问题,它们和输入文档/答案不具有较高的相关性,也会让回答者难以回答。
技术实现要素:
本发明要解决的技术问题是提供一种提高相关性的神经问题生成方法,针对于QG模型中“生成的问题通用性强、相关性低”的问题,我们提出了两种改善的方法:一种是使用基于字符重叠的部分copy机制,通过字符重叠度来优先考虑原文中出现的词或是其变形词,另一种是基于QA模型的重排序机制,通过QA模型来评价生成问题的质量并以此为依据进行重排序。这两种方法可以让我们的QG模型可以生成与输入文档/答案具有更高相关性的问题。
为了解决上述技术问题,本发明提供了一种提高相关性的神经问题生成方法,包括:基于seq2seq的QG模型,由encoder层和decoder组成,并加入了attention机制和copy机制;
基于字符重叠的部分copy机制:
考虑使用最长公共子序列(Longest common subsequence,LCS)来定义单词w1和w2的重叠度C:
这里使用一个阈值来对C进行过滤:
具体在decoder生成一个单词时,考虑输入文档中与当前生成词attention分数最大的那个单词,并考虑该词和词表中每个单词的重叠度,然后利用这个重叠度来重新调整decoder最后输出的概率分布:
Padj=P*(1+λ1*C)。
一种提高相关性的神经问题生成方法,其特征在于,包括:基于seq2seq的QG模型,由encoder层和decoder组成,并加入了attention机制和copy机制;
基于QA模型的重排序技术:因为集束搜索(beam search)的存在,QG系统往往会生成多个候选问题,一般选择分数最高的问题作为模型最后的输出问题;但事实上,并不总是质量好的问题排在前面,有时候一些真正质量好的问题可能只有较低的分数;通常而言,QG模型所需要得到的是P(q|p,a),而QA模型所需要得到的是P(a|p,q);因此我们将这两者结合起来对beam search的结果进行重排序;
将QG模型的log分数作为作为score1,将QA模型的F1分数作为score2,由此我们将score1和score2进行线性组合,可以得到一个新的分数,并利用这个分数来对beam search得到的候选问题进行重排序:
score=(1-λ2)*score1+λ2*score2。
一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现任一项所述方法的步骤。
一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现任一项所述方法的步骤。
一种处理器,所述处理器用于运行程序,其中,所述程序运行时执行任一项所述的方法。
本发明的有益效果:
通过基于字符重叠度的部分copy机制,我们可以使得生成问题中在单词级别和输入文档具有更高的重叠度和相关性。
通过基于QA模型的重排序机制,我们可以为生成的那些质量较好的候选问题赋予更高的分数,而过滤掉那些较为通用的、难以回答的问题。
附图说明
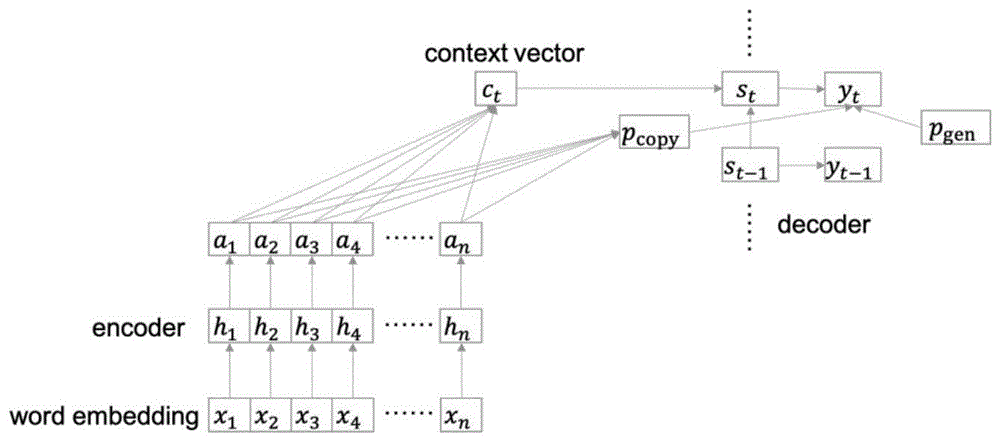
图1是本发明中基于seq2seq的QG模型的示意图。
图2是本发明提高相关性的神经问题生成方法的所用模型与基于seq2seq的QG模型的关系示意图。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
背景:基于seq2seq的QG模型
如图1所示,在问题生成系统中,一般采用seq2seq框架来实现问题生成,由encoder层和decoder组成,并加入了attention机制和copy机制。
Embedding层:我们将训练语料中的每一个词初始化为一个词向量,这种向量数据可以让模型更好地处理。词向量通常是预先训练好的,维度也是预先确定的。以我们使用的glove词向量为例,每个单词都可以对应于一个300维度的词向量。
Encoder层:encoder通常而言是一个双向LSTM,将输入的word embedding编码成包含上下文信息的隐向量表示,最后用这个固定维度的隐向量作为decoder的初始状态。在我们的模型中,对于文档和答案分别通过embedding层和encoder层,然后利用一些匹配策略将两者的隐向量表示进行结合。
Decoder层:decoder通常而言是一个单向LSTM,每个时间步在目标端按序生成(generate)一个单词,并以特殊符号<EOS>作为结束的标识。在每个时间步,会根据目标端隐层st和context向量得到一个基于词典的概率分布,其中概率最大的词就作为该时刻的生成词,公式如下:
Pvocab=softmax(w[st;ct]+b)
Attention机制:与机器翻译中的attention类似,本质是一种对齐手段,做法是对源端隐层和目标端隐层计算attention分数,正则化以后与源端隐层加权求和得到context向量,带入到目标端单词的生成中,公式如下:
et,i=vTtanh(W1st+W2hi+b)
at,i=softmax(et,i)
Copy机制:用于处理生成词不在词典中的情况,通常而言,词典只包含数据集中出现一定频率的词,而不收录那些低频词(例如只出现一次),因此如果没有copy机制通常会造成某个输出词是<UNK>的情况。为了处理这种情况,copy机制用来去从输入文档中选择单词作为目标端的输出单词,为了合理控制copy和generate的平衡,通常会采用门控机制。门控机制的计算和包含copy机制的最终概率分布计算公式如下:
gt=sigmoid(w1ct+w2st+w3xt-1+b)
Pfinal=gtPvocab+(1-gt)Patt
模型训练:一般采用最小化负对数似然为损失函数,采用Adam优化器为训练方法来进行迭代训练。模型训练目标函数如下:
一种提高相关性的神经问题生成方法、模型及装置介绍:
为了使得QG模型生成更相关的问题,我们提出了两种方法:基于字符重叠的部分copy机制(partial copy)和基于QA模型的重排序机制(reranking)。我们的方法与原模型的关系如图2所示:
第一个方法是基于字符重叠的部分copy机制,目的是优先考虑那些与输入文档中的词形态上相同或是相近的词,比如一个简单的例子:
Passage:Teaching started in 1794.
Question:When did teaching start?
对于一般的copy机制而言,copy机制可以使得生成“started”这个词的生成概率提高,但不能处理“start”这样的变形词,因为原文中只出现了“started”而没有出现“start”。
我们考虑使用最长公共子序列(Longest common subsequence,LCS)来定义单词w1和w2的重叠度C:
比如上面那个例子中,“start”和“started”的重叠度就是0.71,但类似的,“append”和“start”这两个毫不相关的单词之间其实也存在LCS即“a”,这样它们的重叠度就是0.18而不是0。换言之,对于一些不相关的单词间也会有不为0的重叠度,而且该重叠度没有任何实际含义,因此这里使用一个阈值来对C进行过滤:
具体在decoder生成一个单词时,我们考虑输入文档中与当前生成词attention分数最大的那个单词,并考虑该词和词表中每个单词的重叠度,然后利用这个重叠度来重新调整decoder最后输出的概率分布:
Padj=P*(1+λ1*C)
第二个方法是基于QA模型的重排序技术。因为集束搜索(beam search)的存在,QG系统往往会生成多个候选问题,一般选择分数最高的问题作为模型最后的输出问题。但事实上,并不总是质量好的问题排在前面,有时候一些真正质量好的问题可能只有较低的分数。通常而言,QG模型所需要得到的是P(q|p,a),而QA模型所需要得到的是P(a|p,q)。因此我们将这两者结合起来对beam search的结果进行重排序。
在QA模型中,我们通常使用F1分数来评价预测答案的质量。一般来说,质量较好的问题会使得QA模型更容易回答,这样就可以赋予这些问题更高的分数,使得它们在beam search的结果中脱颖而出。
我们将QG模型的log分数作为作为score1,将QA模型的F1分数作为score2,由此我们将score1和score2进行线性组合,可以得到一个新的分数,并利用这个分数来对beam search得到的候选问题进行重排序:
score=(1-λ2)*score1+λ2*score2
将上述两种方法结合起来,我们就从两个角度优化了QG模型生成的问题,使得这些问题具有与输入文档/答案更高的相关性。
我们提出一种提高相关性的神经问题生成方法,具有以下优势:
通过基于字符重叠度的部分copy机制,我们可以使得生成问题中在单词级别和输入文档具有更高的重叠度和相关性。
通过基于QA模型的重排序机制,我们可以为生成的那些质量较好的候选问题赋予更高的分数,而过滤掉那些较为通用的、难以回答的问题。
我们结合了以上两种方法,在SQuAD数据集上做了实验,在BLEU和METEOR两个经典的评价指标上都比baseline有了明显的提升,实验结果如下:
表1
我们分析了修改前后“通用性问题”生成结果的比例:
表2
表2示了使用我们的方法前后,生成的“通用性问题”数量的比例。可以看到,一些常见的通用性问题模式如“他叫什么名字?”、“它是什么?”的数量大大减少了。
对于基于字符重叠的copy机制,那些和输入文档具有较高重叠度和相关度的问题会被赋予更高的分数,而这些通用性问题由于和输入文档的重叠度往往很低,因此会被这种机制所惩罚。在这种机制下,从输入文档中copy一个词(或是其变形词)的比率更高了,从原先的75.49%提高到了78.74%。
对于基于QA模型的重排序机制,那些和输入文档更相关的问题能够被QA模型所正确地回答,而这些通用性问题由于问法不够具有针对性因此很容易对QA模型起误导作用。在这种机制下,共有2099个问题得到重排序,其中1117个问题经过重排序得到了更高的BLEU-4分数,而只有821个问题经过重排序反而使得BLEU-4分数降低了。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
- 还没有人留言评论。精彩留言会获得点赞!