一种可回溯的快速裂变式构建用户画像的方法与流程
本发明属于电子商务领域,具体涉及一种可回溯的快速裂变式构建用户画像的方法。
背景技术:
用户画像,是一种用于勾画目标用户、联系用户诉求与设计方向的有效工具,其在各领域均得到了广泛的应用。用户画像的提出,根本上是源于企业对用户认知的渴求,在营销决策的过程中,企业关注的重心不外乎两类,“如何做出用户更喜欢的产品”,“如何把产品卖给对的人”,解决这两个问题离不开对用户需求的洞察,因此决策者不可避免的要考虑两类人:现有用户、潜在客户。为了寻找客户,企业必须通过各种方式不断的收集用户信息,最初可能只是通过问卷调查、用户访谈等少量、定性分析的方式进行,当样本的数量逐步提升,这些用户的信息将会以更加标准化、更简单的方式描述出来,形成一个一个“标签”,这也就形成了用户画像的雏形。因此,用户画像并不是大数据时代的“专利”,大数据技术的应用,拓展了企业获取数据的来源和处理数据的方法,让企业有机会得到更多的用户样本,从海量数据中找到那些真正对自己有价值的数据,从更多维度描述自己的用户画像。
中国目前互联网网购用户已经达到8.29亿人群,经统计2018年双十一网购消费费高达2135亿元,大量的消费群体涌集,电商平台如何更有效率的对其进行处理,通过用户画像来进行预测,从而快速的给用户群体推荐其想要购买的商品,从而提高自身竞争力和效率,是所需要解决的技术问题。
技术实现要素:
本发明的目的是针对现有的问题,提供了一种可回溯的快速裂变式构建用户画像的方法。
本发明是通过以下技术方案实现的:
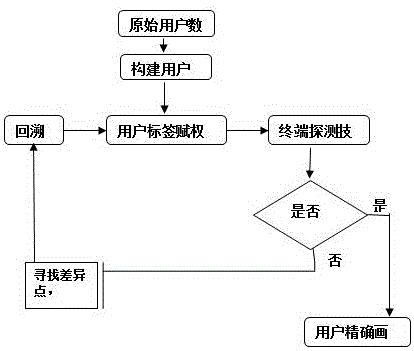
一种可回溯的快速裂变式构建用户画像的方法,包括以下步骤:
步骤s1:构建原始用户数据群集;
步骤s2:构建用户标签,得到用户模糊画像;
步骤s3:对用户标签进行赋权;
步骤s4:根据赋权将得到的用户画像置于实际应用中检验,通过终端探测技术,对比当前用户模糊画像与实际用户状态之间的精度,如果当前用户模糊画像与实际用户状态之间达到目标精度,则执行步骤s7,如果当前用户模糊画像与实际用户状态之间没有达到目标精度,则执行步骤s5;
步骤s5:对比实际用户行为和当前用户画像的差异点,寻找重点权重标签,并关注重点权重标签的赋权;
步骤s6:根据步骤s5的回溯反馈结果,执行步骤s3调整建立新赋权,对用户画像进行进一步精细化处理,得到进一步精化用户画像,然后继续执行步骤s4;
步骤s7:得到用户精确画像。
作为进一步的技术方案是,所述步骤s1中构建原始用户数据群集从用户访问的网站获取用户账户信息和用户行为信息,建立用户数据群集。
作为进一步的技术方案是,所述用户数据群集包括:静态信息数据和动态信息数据。
作为进一步的技术方案是,所述步骤s2中构建用户标签为根据用户数据群集进行构建,通过静态信息数据构建包括人口属性、商业属性等方面属性标签,通过动态信息数据,互联网上的用户行为,构建行为特征标签。
作为进一步的技术方案是,所述步骤s3中对用户标签进行赋权为:标签权重=时间权重×网址权重×行为权重。
作为进一步的技术方案是,所述时间权重为随着用户在电子商务行为中的行为频率、行为次序、行为特征,以时间为坐标系,延展形成以时间延续为特征单序列的时间衰减函数,具体表现为在某种特征权重中间的商品购物中,用户在以时间衰减函数为特征的进程中,该具有特征权重的商品出现的概率,出现率低说明遗忘率高,出现率高说明遗忘率低。
作为进一步的技术方案是,所述网址权重表明了用户在不同网址上的需求差异,网址的内容反映了标签信息,网址本身则表征了标签的权重,其中网址包括了不同的电商平台,各电商平台内的店铺。
作为进一步的技术方案是,所述行为权重表明用户的行为类型,包括浏览、搜索、评论、点赞、收藏等。
作为进一步的技术方案是,步骤s4中所述目标精度:通过建立坐标系,以时间为x轴,用户行为为y轴,以最近时间对应的用户行为作为参照点,进行演绎和相关的运算,得到最近用户行为属性,如果相比较,模糊画像与最近用户行为属性相吻合,以吻合的精度作为下一个精度标准,用在后续迭代的用户画像对比中。
有益效果:本发明一种可回溯的快速裂变式构建用户画像的方法,首先建立了原始用户数据群集,构建了初步的用户标签,从多个维度对用户特征进行刻画,包括用户静态信息数据和动态信息数据,使用户标签更加丰富全面,通过在初次构建的用户模糊画像的基础上,进行反复裂变迭代,逐渐逼近用户精准化的画像。
附图说明
图1为一种可回溯的快速裂变式构建用户画像的方法流程图。
具体实施方式
一种可回溯的快速裂变式构建用户画像的方法,包括以下步骤:
步骤s1:构建原始用户数据群集;
步骤s2:构建用户标签,得到用户模糊画像;
步骤s3:对用户标签进行赋权;
步骤s4:根据赋权将得到的用户画像置于实际应用中检验,通过终端探测技术,对比当前用户模糊画像与实际用户状态之间的精度,如果当前用户模糊画像与实际用户状态之间达到目标精度,则执行步骤s7,如果当前用户模糊画像与实际用户状态之间没有达到目标精度,则执行步骤s5;
步骤s5:对比实际用户行为和当前用户画像的差异点,寻找重点权重标签,并关注重点权重标签的赋权;
步骤s6:根据步骤s5的回溯反馈结果,执行步骤s3调整建立新赋权,对用户画像进行进一步精细化处理,得到进一步精化用户画像,然后继续执行步骤s4;
步骤s7:得到用户精确画像。
作为进一步的技术方案是,所述步骤s1中构建原始用户数据群集从用户访问的网站获取用户账户信息和用户行为信息,建立用户数据群集。
作为进一步的技术方案是,所述用户数据群集包括:静态信息数据和动态信息数据。
作为进一步的技术方案是,所述步骤s2中构建用户标签为根据用户数据群集进行构建,通过静态信息数据构建包括人口属性、商业属性等方面属性标签,通过动态信息数据,互联网上的用户行为,构建行为特征标签。
作为进一步的技术方案是,所述步骤s3中对用户标签进行赋权为:标签权重=时间权重×网址权重×行为权重。
作为进一步的技术方案是,所述时间权重为随着用户在电子商务行为中的行为频率、行为次序、行为特征,以时间为坐标系,延展形成以时间延续为特征单序列的时间衰减函数,具体表现为在某种特征权重中间的商品购物中,用户在以时间衰减函数为特征的进程中,该具有特征权重的商品出现的概率,出现率低说明遗忘率高,出现率高说明遗忘率低。
作为进一步的技术方案是,所述网址权重表明了用户在不同网址上的需求差异,网址的内容反映了标签信息,网址本身则表征了标签的权重。
作为进一步的技术方案是,所述行为权重表明用户的行为类型,包括浏览、搜索、评论、点赞、收藏等。
步骤s4中所述目标精度:通过建立坐标系,以时间为x轴,用户行为为y轴,以最近时间对应的用户行为作为参照点,进行演绎和相关的运算,得到最近用户行为属性,如果相比较,模糊画像与最近用户行为属性相吻合,以吻合的精度作为下一个精度标准,用在后续迭代的用户画像对比中。
1)关于数据的认知
数据是构建用户画像的核心,一般我们采用二类基础数据整合:静态信息数据(用户相对稳定的信息,主要包括人口属性、商业属性等方面数据,这类信息,构成属性标签(如果企业已有真实信息则无需过多建模预测,更多的是数据整理的工作)、动态信息数据(用户不断变化的行为信息,用户搜索了什么商品,浏览了哪个页面,赞了哪条微博消息,发布了积极或消极的评论……这些都是互联网上的用户行为,将成为用户画像中偏好特征和消费行为特征的主要依据)
同时,我们还会关注收集其它用户数据(包括用户的自然特征、社会特征、偏好特征、消费特征等)、商品数据(产品属性、产品定位)、客观商品属性(商品的功能、颜色、能耗、价格等事实数据)、主观商品定位(商品的风格、定位人群等,商品数据可以认为是商品的标签,需要和用户标签进行关联和匹配)、渠道数据(信息渠道、购买渠道)(信息渠道,指用户在信息渠道上获得资讯,如微信、微博等社交网络。购买渠道,指用户在购买渠道上进行商品采购,例如商品官网、电商平台等)。
2)关于数据建模
基于上述数据构建原始用户数据群集,我们需要根据用户数据群集构建相应的数据模型进行赋权。每一次的用户行为,可以详细描述为:什么用户,在什么时间,什么地点,发生了什么事。
什么用户:即用户识别,其目的是为了区分用户。互联网主要的用户识别的方式包括cookie,注册id,微信微博,手机号等,获取方式由易到难,不同企业的客户信息数据化程度有所不同,用户识别的方式也可按需选取。
什么时间:在用户行为中,普遍认为近期发生的行为将更反映用户当下的特征,因此过往行为将表现为在标签权重上的衰减。
什么地点:即用户的接触点,包含了两个潜在信息:网址和内容。内容决定标签,网址决定权重。例如,一瓶矿泉水,超市卖1元,景区卖3元,酒店卖5元,商品的售卖价值,不在于成本,而在于售卖地点,这里的权重可以理解为用户对矿泉水的需求程度不同,相应的也有不同的支付意愿。类似的反映到互联网,用户在天猫浏览了iphone6的信息和在苹果官网浏览也将存在权重的差异,因此,网址的内容反映了标签信息,网址本身则表征了标签的权重。
做了什么:用户的行为类型,例如浏览、搜索、评论、点赞、收藏等,同样反映的是标签的权重。
从上述建模方法中,我们可以简单勾画出一个用户行为的标签权重公式:
标签权重=时间权重(何时)×网址权重(何地)×行为权重(做什么)
举个直观的例子,“b用户今天在苹果官网购买了iphone6”反映出的用户标签可能是“果粉1”;而“a用户三天前在天猫收藏了iphone6”反映出的标签可能只是“果粉0.448”,这些不同用户的标签及相应的权重将在后续的营销决策中发挥指导作用。
3)算法
通过数据建模,本发明可以有效地为能覆盖到的用户打上标签,之后结合渠道信息和商品信息,企业可根据需求定向地选择数据挖掘的方法输出结果,在营销决策中,可能得到的结论例如“具有标签a的人集中购买了商品a”、“购买商品b的用户同样会对商品a感兴趣”、“商品a的购买人群主要集中于渠道c”等等,这些信息将直接指导我们完成画像的初始工作。在这个过程中常用的算法包括聚类和关联规则等。
4)迭代和裂变
我们把最初得到的用户模糊画像,置于实际应用中检验,置于具体的应用场景,探测用户实际和画像的差异化,寻求重要标签属性的差异点,并反馈到现有系统,通过系统再重新赋权,并关注重点权重标签的赋权,依次对差异化进行回溯调整(裂变式迭代)。在这个迭代过程中,我们在已有模糊画像的基础上,寻找焦点数据,并针对用户重要特征标签进行赋权,关注重点标签,根据回溯反馈,调整建立新赋权,迭代回原算法对用户画像进行进一步精细化处理,通过上述过程反复迭代和快速裂变,逼近精确用户画像。
- 还没有人留言评论。精彩留言会获得点赞!