日志信息处理方法、边缘节点、中心节点和系统与流程
本公开实施例涉及信息处理领域,尤其涉及一种日志信息处理方法、边缘节点、中心节点和日志信息处理系统。
背景技术:
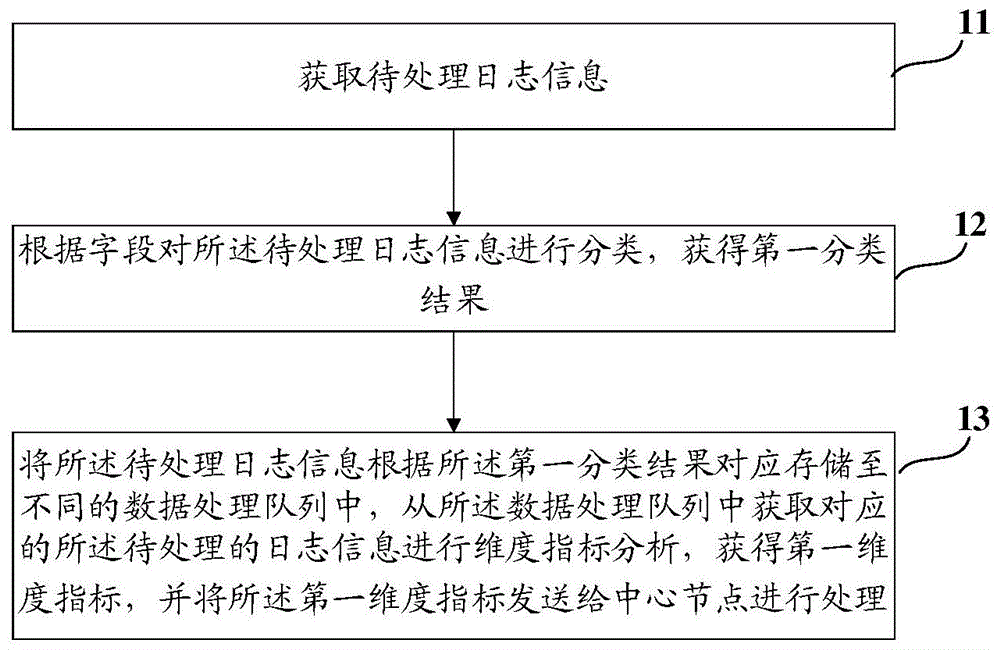
:日常生活中的打电话、手机上网,背后承载的都是电信的路由器、交换机等设备的数据交换。通过探针对接收到的数据进行解析、关联等处理,生成xdr。xdr是tdr(transactiondetailrecord,事务详细单据)、cdr(calldetailrecord,呼叫详细单据)的合称。将xdr上报给分析系统,可以对电信业务数据进行多维度分析。目前对xdr进行多维度分析,一般来说,可通过以下方式:1、通过数据库进行分析将xdr写入数据库后,通过结构化查询语言,即sql,进行指标的查询分析。2、通过流式处理sparkstreaming进行分析,即通过sparkstreaming接入实时数据后,对每个微批数据,进行分析。但是,采用结构化查询语言分析方式和流式处理分析方式进行xdr的多维度分析,由于数据量大,导致节点负荷非常重且数据处理非常耗时,效率低,不能很好地满足当前xdr的多维度分析时的高效要求。技术实现要素:为解决现有存在的技术问题,本公开实施例提供一种高效的日志信息处理方法、边缘节点、中心节点和日志处理处理系统。为达到上述目的,本公开实施例的技术方案是这样实现的:第一方面,本公开实施例提供一种日志信息处理方法,包括:获取待处理日志信息;根据字段对所述待处理日志信息进行分类,获得第一分类结果;将所述待处理日志信息根据所述第一分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,获得第一维度指标,并将所述第一维度指标发送给中心节点进行处理。其中,所述将所述第一维度指标发送给中心节点进行处理,还包括:中心节点获取第一维度指标,根据字段对所述第一维度指标进行分类,获得第二分类结果;将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。其中,在将所述第一维度指标发送给中心节点进行处理之前,还包括:将所述第一维度指标以键值对形式存储至关系型数据库中;从所述关系型数据库中获取所述第一维度指标并对所述待分析日志中的每条日志信息对应的第一维度指标进行累加,获得每条日志信息累加后的所述第一维度指标。其中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,获得第一维度指标,包括:从所述数据处理队列中获取对应的所述待处理的日志信息;根据所述待处理的日志信息携带的字段确定所述待处理日志信息的指标名及与所述指标名对应的指标值;基于指定的第一维度分析需求,从已建立的第一算法索引表中获取所述第一维度分析需求对应的目标算法;其中,所述第一算法索引表包括所述第一维度分析需求与至少一所述指标名对应的指标值之间的对应关系;基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。其中,基于指定的第一维度分析需求,从已建立的第一算法索引表中获取所述第一维度分析需求对应的目标算法,包括:以第一维度分析需求为索引遍历已建立的第一算法索引表,从所述第一算法索引表中获取所述第一维度分析需求对应的目标算法。其中,所述基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标,包括:根据所述第一维度分析需求确定分析时间段信息;根据所述待处理的日志信息的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述待处理的日志信息;根据分析时间段内的所述待处理的日志信息中的指标名与指标值,基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。第二方面,本公开实施例还提供一种日志信息处理方法,应用于中心节点,包括:获取边缘节点发送的第一维度指标,根据字段对所述第一维度指标进行分类,获得第二分类结果;将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。其中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标,包括:从所述数据处理队列中获取对应的第一维度指标;根据所述第一维度指标携带的字段确定所述第一维度指标的指标名及与所述指标名对应的指标值;基于指定的第二维度分析需求,从已建立的第二算法索引表中获取所述第二维度分析需求对应的目标算法;其中,所述第二算法索引表包括所述第二维度分析需求与至少一所述指标名对应的指标值之间的对应关系;基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。其中,基于指定的第二维度分析需求,从已建立的第二算法索引表中获取所述第二维度分析需求对应的目标算法,包括:以第二维度分析需求为索引遍历已建立的第二算法索引表,从所述第二算法索引表中获取所述第二维度分析需求对应的目标算法。其中,所述基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标,包括:根据所述第二维度分析需求确定分析时间段信息;根据所述第一维度指标的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述第一维度指标;根据分析时间段内的所述第一维度指标中的指标名与指标值,基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。其中,所述方法还包括:将所述第二维度指标存储至目标数据库,和/或,将所述第二维度指标输出并显示第三方面,本公开实施例还提供一种边缘节点,包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器;其中,所述处理器用于运行所述计算机程序时,实现如本公开任一实施例所述的应用于边缘节点的日志信息处理方法。第四方面,本公开实施例还提供一种中心节点,包括:处理器和用于存储能够在处理器上运行的计算机程序的存储器;其中,所述处理器用于运行所述计算机程序时,实现如本公开任一实施例所述的应用于中心节点的日志信息处理方法。第五方面,本公开实施例还提供一种日志信息处理系统,包括本公开任一实施例所述的边缘节点和本公开任一实施例所述的中心节点。在本公开实施例中,所述方法通过获取待处理日志信息;根据字段对所述待处理日志信息进行分类,获得第一分类结果,这里,对所述待处理日志信息进行分类,分类后的日志信息的处理会更加高效;将所述待处理日志信息根据所述第一分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,这里,基于数据处理队列存储和获取数据,能够有效减小数据存储以及查询的复杂度,提升查询和分析处理效率;获得第一维度指标,并将所述第一维度指标发送给中心节点进行处理,这里,对所述待处理日志信息进行处理后获得第一维度指标,再将所述第一维度指标发送给中心节点进行处理,能够减轻中心节点的负荷,减小处理的耗时,提升日志信息处理的效率,满足日志信息的多维度分析时的高效要求。附图说明图1为本公开一实施例提供的一种日志信息处理方法的流程示意图;图1a为本公开一实施例提供的边缘节点与中心节点配合工作的示意图;图2为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图3为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图4为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图5为本公开另一实施例提供的键值对处理流程示意图;图6为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图7为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图8为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图9为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图10为本公开另一实施例提供的一种日志信息处理方法的流程示意图;图11为本公开另一实施例提供的一种日志信息处理装置的流程示意图;图12为本公开另一实施例提供的一种日志信息处理装置的流程示意图;图13为本公开一实施例提供的一种边缘节点的结构示意图;图14为本公开一实施例提供的一种中心节点的结构示意图;图15为本公开一实施例提供的一种日志信息处理系统的结构示意图;图16为本公开另一实施例提供的一种日志信息处理方法的流程示意图。具体实施方式为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例中的附图,对本公开实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本公开一部分实施例,而不是全部的实施例。基于本公开中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。请参见图1,为本公开一实施例提供的一种日志信息处理方法的流程示意图,应用于边缘节点,包括:步骤11,获取待处理日志信息;这里,所述待处理的日志信息可以是用户在打电话或手机上网时,通信网络承载的路由器、交换机等设备产生的数据,可以是通过探针对所述数据进行解析、关联等处理后生成的日志信息xdr,xdr可以包括tdr(transactiondetailrecord,事务详细单据)和cdr(calldetailrecord,呼叫详细单据)。这里,所述边缘节点可以是与数据处理中心节点相对应的数据处理节点,请参见图1a,这里,边缘节点可以对应省a、b、c、d前置机,中心节点可以对应集团主机,通过将数据计算下放至远端边缘节点,从而减轻了中心节点的压力,同时,远端边缘节点可并行处理各自节点的数据,从而减少数据处理总耗时。这里,假设各远端数据量规模相当,那么中心节点处理所需的总时间如下:ttime=edgei+center其中,ttime表示中心节点处理数据所需的总时间,edgei表示某个边缘节点处理数据所需时间,center表示中心节点对各远端节点的结果数据,进行数据汇总分析所需时间。步骤12,根据字段对所述待处理日志信息进行分类,获得第一分类结果;这里,根据字段对所述待处理日志信息进行分类可以是根据所述待处理日志信息的来源进行分类,例如,根据dns服务器日志、http服务器日志等对应的服务器类型进行分类。还可以是根据所述待处理日志信息的产生时间、地域等进行分类。所述字段用于表针所述待处理日志信息的属性,例如,日志信息为“长沙20180818dns服务器xxxx”,所述日志信息携带长沙、20180818、dns服务器等字段,表示所述日志信息为2018年8月18日来自长沙dns服务器的信息,这样,可以基于所述字段信息进行所述待处理日志信息的分类。步骤13,将所述待处理日志信息根据所述第一分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,获得第一维度指标,并将所述第一维度指标发送给中心节点进行处理。这里,所述数据处理队列可以是一种具有先进先出存储机制的存储区域,将所述第一分类结果存储所述数据处理队列进行等待,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,相比直接在接收所述待分析日志后立即进行处理效率会更高,且具有更高的可靠性。这里,在边缘节点对所述待处理日志信息进行初步处理获得第一维度指标后再发送给中心节点进行处理,可以大幅缓解中心节点的负荷,提升数据处理效率。这里,所述第一维度指标是待分析日志经过维度指标分析之后获得的结果,例如,可以是统计多个站点的流量使用情况,例如,a站点对应的流量为10m,b站点对应的流量为110m,c站点对应的流量为20m,经过维度分析后,可以知道a、b、c站点的流量使用总量为140m,140m即为第一维度指标流量使用总量对应的流量值。这里,维度指标分析可以是针对地市维度、业务维度、网元维度、ip维度、错误码维度、小区维度进行的分析,分析后得到相应指标,即第一维度指标,如上下行流量、响应时延、请求成功次数、流量等指标;这里,一个维度,可以包含多个指标。作为一种实施例,所述将所述待处理日志信息根据所述第一分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,可以是根据所述待处理日志信息来源的不同,例如s1-u、s1-mme、http、dns,写入对应的消息系统kafkatopic内,并通过流式数据处理模块sparkstreaming的kafka组件,创建管道directstream获取所述消息系统kafkatopic中的内容进行分析。在本公开实施例中,所述方法通过获取待处理日志信息;根据字段对所述待处理日志信息进行分类,获得第一分类结果,这里,对所述待处理日志信息进行分类,分类后的日志信息的处理会更加高效;将所述待处理日志信息根据所述第一分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,这里,基于数据处理队列存储和获取数据,能够有效减小数据存储以及查询的复杂度,提升查询和分析处理效率;获得第一维度指标,并将所述第一维度指标发送给中心节点进行处理,这里,对所述待处理日志信息进行处理后获得第一维度指标,再将所述第一维度指标发送给中心节点进行处理,能够减轻中心节点的负荷,减小处理的耗时,提升日志信息处理的效率,满足日志信息的多维度分析时的高效要求。请参见图2,为本公开另一实施例提供的一种日志信息处理方法的流程示意图,所述将所述第一维度指标发送给中心节点进行处理,还包括:步骤21,中心节点获取第一维度指标,根据字段对所述第一维度指标进行分类,获得第二分类结果;这里,所述中心节点可以是国家、省、市的数据处理中心。所述第一维度指标可以为经过边缘节点进行初步处理的中间结果,例如,a站点、b站点、c站点的流量总量。步骤22,将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。这里,所述数据处理队列可以是一种具有先进先出存储机制的存储区域,将所述第二分类结果存储所述数据处理队列进行等待,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,相比直接在接收所述第一维度指标后立即进行处理效率会更高,且具有更高的可靠性。这里,在边缘节点对所述待处理日志信息进行初步处理获得第一维度指标后再发送给中心节点进行处理,可以大幅缓解中心节点的负荷,提升数据处理效率。这里,所述第一维度指标是待分析日志经过维度指标分析之后获得的结果,例如,可以是统计多个站点的流量使用情况,例如,a站点对应的流量为10m,b站点对应的流量为110m,c站点对应的流量为20m,经过维度分析后,可以知道a、b、c站点的流量使用总量为140m,140m即为第一维度指标流量使用总量对应的流量值。而对所述第一维度指标进行维度指标分析,获得第二维度指标,可以是将所述第一维度指标作为中间结果,对所述中间结果进行进一步处理,例如,基于a、b、c站点的流量使用总量,分析a、b、c站点的平均使用量。这里,维度指标分析可以是针对地市维度、业务维度、网元维度、ip维度、错误码维度、小区维度进行的分析,分析后得到相应指标,即第二维度指标,如上下行流量、响应时延、请求成功次数、流量等指标;这里,一个维度,可以包含多个指标。作为一种实施例,所述将所述待处理日志信息根据所述第二分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述第一维度指标进行维度指标分析,可以是根据所述第一维度指标来源的不同,例如第一边缘节点、第二边缘节点等,写入对应的消息系统kafkatopic内,并通过流式数据处理模块sparkstreaming的kafka组件,创建管道directstream获取所述消息系统kafkatopic中的内容进行分析。请参见图3,为本公开另一实施例提供的一种日志信息处理方法的流程示意图,在将所述第一维度指标发送给中心节点进行处理之前,还包括:步骤31,将所述第一维度指标以键值对形式存储至关系型数据库中;这里,所述关系型数据库可以是redis数据库,redis具有高速处理数据的缓存;所述键值对包括键和值,例如,(key,value)键值对,这里key可以为对应的属性名,value可以为所述属性名对应的值。步骤32,从所述关系型数据库中获取所述第一维度指标并对所述待分析日志中的每条日志信息对应的第一维度指标进行累加,获得每条日志信息累加后的所述第一维度指标。作为一种实施例,所述待分析日志信息包括的字段如表一:字段名索引下标说明city0城市代号time1记录产生时间field_a2字段afield_b3字段b..................请参见图4,假设需要统计时间窗口为n分钟内的指标,计算流程如下:步骤41,获取待处理日志信息;数据格式请参见图5中的a,对应格式为:010,20180903112320,field_a_1,field_b_1;010,20180903112323,field_a_2,field_b_2;步骤42,根据字段将所述待处理日志信息分类并存储在各自边缘节点的kafkatopic中;步骤43,通过spark软件的map算子,对每行日志信息中的数据,通过逗号进行分割;这里,数据格式请参见图5中的b,对应格式为:01020180903112320field_a_1field_b_1;01020180903112323field_a_2field_b_2;步骤44,通过spark软件中的flatmaptopair算子,转换成(key,value)键值对。其中key可以为“城市区号_时间_city_”,时间可以根据统计时间窗口的大小,进行取整。value为“field_a|field_b”,通过竖线连接。这里,数据格式请参见图5中的c,对应格式为:(010,20180903112000,field_a_1|field_b_1);(010,20180903112000,field_a_2|field_b_2);步骤45,通过spark软件中的reducebykey算子,对于key相同的键值对,将其value值进行相加:field_a_1+field_a_2=value_a,field_b_1+field_b_2=value_b。这里,数据格式请参见图5中的d,对应格式为:(010_20180903112000_city_,value_a|value_b);步骤46,通过spark软件中的foreachrdd算子,对数据进行遍历,并写入redis。这里,在步骤44中,在spark键值对rdd中,value格式为“field_a|field_b”。在写入redis时,进行拆分,分两个key进行写入。这里,数据格式请参见图5中的e,对应格式为:(010_20180903112000_city_a_field_a,value_b);(010_20180903112000_city_b_field_b,value_b);(20180903112000_city,010);步骤47,对redis中key相同的数据,进行累计操作,生成结果文件,写入中心节点。这里,数据格式请参见图5中的f,对应格式为:本公开上述实施例中,减轻了redis的压力,将绝大部分的计算压力,通过边缘节点的spark进行承载,充分发挥了分布式计算的优势。请参见图6,为本公开另一实施例提供的一种日志信息处理方法的流程示意图,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,获得第一维度指标,包括:步骤61,从所述数据处理队列中获取对应的所述待处理的日志信息;根据所述待处理的日志信息携带的字段确定所述待处理日志信息的指标名及与所述指标名对应的指标值;这里,所述指标名可以为站点信息,例如指标名为a站点对应的指标值流量为10m,指标名b站点对应的指标值流量为110m,指标名c站点对应的指标值流量为20m。步骤62,基于指定的第一维度分析需求,从已建立的第一算法索引表中获取所述第一维度分析需求对应的目标算法;其中,所述第一算法索引表包括所述第一维度分析需求与至少一所述指标名对应的指标值之间的对应关系;这里,所述目标算法可以预先设置,所述第一算法索引表的形式可以如表二:指标名索引下标算法左数右数说明field_a2addadd表示累加field_b3addadd表示累加rate_11divfield_afield_bdiv表示相除,且左数除右数....................................以rate_1为例,当指定的第一维度分析需求为rate_1或索引下标为1时,通过表格可以索引到其对应的目标算法为div,其具体为field_a除以field_b。通过这种索引的方式直接找到对应的算法,相比编程获取更加简单快捷和高效。步骤63,基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。这里,基于指定的第一维度分析需求,从已建立的第一算法索引表中获取所述第一维度分析需求对应的目标算法,包括:以第一维度分析需求为索引遍历已建立的第一算法索引表,从所述第一算法索引表中获取所述第一维度分析需求对应的目标算法。请参见图7,为本公开另一实施例提供的一种日志信息处理方法的流程示意图,所述基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标,包括:步骤71,根据所述第一维度分析需求确定分析时间段信息;这里,所述分析时间段信息携带在所述第一维度分析需求字段中,例如,时间字段为“20182019xxxx”,所述时间字段用于表征获取对应时段的信息。步骤72,根据所述待处理的日志信息的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述待处理的日志信息;这里,所述获取时间字段在所述分析时间段内的所述待处理的日志信息可以是通过比较所述第一维度分析需求中的时间字段信息和所述待处理日志信息中的所述时间字段步骤73,根据分析时间段内的所述待处理的日志信息中的指标名与指标值,基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。这里,根据所述第一维度分析需求中的时间段信息确定第一维度指标,能够灵活获取不同时间段内的实时信息。第二方面,本公开实施例还提供一种日志信息处理方法,请参见图8,为本公开另一实施例提供的一种日志信息处理方法的流程示意图,应用于中心节点,包括:步骤81,获取边缘节点发送的第一维度指标;步骤82,根据字段对所述第一维度指标进行分类,获得第二分类结果;这里,所述中心节点可以是国家、省、市的数据处理中心。所述第一维度指标可以为经过边缘节点进行初步处理的中间结果,例如,a站点、b站点、c站点的流量总量。步骤83,将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。这里,所述数据处理队列可以是一种具有先进先出存储机制的存储区域,将所述第二分类结果存储所述数据处理队列进行等待,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,相比直接在接收所述第一维度指标后立即进行处理效率会更高,且具有更高的可靠性。这里,在边缘节点对所述待处理日志信息进行初步处理获得第一维度指标后再发送给中心节点进行处理,可以大幅缓解中心节点的负荷,提升数据处理效率。这里,所述第一维度指标是待分析日志经过维度指标分析之后获得的结果,例如,可以是统计多个站点的流量使用情况,例如,a站点对应的流量为10m,b站点对应的流量为110m,c站点对应的流量为20m,经过维度分析后,可以知道a、b、c站点的流量使用总量为140m,140m即为第一维度指标流量使用总量对应的流量值。而对所述第一维度指标进行维度指标分析,获得第二维度指标,可以是将所述第一维度指标作为中间结果,对所述中间结果进行进一步处理,例如,基于a、b、c站点的流量使用总量,分析a、b、c站点的平均使用量。这里,维度指标分析可以是针对地市维度、业务维度、网元维度、ip维度、错误码维度、小区维度进行的分析,分析后得到相应指标,即第二维度指标,如上下行流量、响应时延、请求成功次数、流量等指标;这里,一个维度,可以包含多个指标。作为一种实施例,所述将所述待处理日志信息根据所述第二分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述第一维度指标进行维度指标分析,可以是根据所述第一维度指标来源的不同,例如第一边缘节点、第二边缘节点等,写入对应的消息系统kafkatopic内,并通过流式数据处理模块sparkstreaming的kafka组件,创建管道directstream获取所述消息系统kafkatopic中的内容进行分析。请参见图9,为本公开另一实施例提供的一种日志信息处理方法的流程示意图,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标,包括:步骤91,从所述数据处理队列中获取对应的第一维度指标;根据所述第一维度指标携带的字段确定所述第一维度指标的指标名及与所述指标名对应的指标值;这里,所述指标名可以为站点信息,例如指标名为a站点对应的指标值流量为10m,指标名b站点对应的指标值流量为110m,指标名c站点对应的指标值流量为20m。步骤92,基于指定的第二维度分析需求,从已建立的第二算法索引表中获取所述第二维度分析需求对应的目标算法;其中,所述第二算法索引表包括所述第二维度分析需求与至少一所述指标名对应的指标值之间的对应关系;步骤93,基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。这里,基于指定的第二维度分析需求,从已建立的第二算法索引表中获取所述第二维度分析需求对应的目标算法,包括:以第二维度分析需求为索引遍历已建立的第二算法索引表,从所述第二算法索引表中获取所述第二维度分析需求对应的目标算法。这里,基于指定的第二维度分析需求,从已建立的第二算法索引表中获取所述第二维度分析需求对应的目标算法,包括:以第二维度分析需求为索引遍历已建立的第二算法索引表,从所述第二算法索引表中获取所述第二维度分析需求对应的目标算法。请参见图10,为本公开另一实施例提供的一种日志信息处理方法的流程示意图,所述基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标,包括:步骤101,根据所述第二维度分析需求确定分析时间段信息;这里,所述分析时间段信息携带在所述第一维度分析需求字段中,例如,时间字段为“20182019xxxx,所述时间字段用于表征获取对应时段的信息。步骤102,根据所述第一维度指标的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述第一维度指标;这里,所述获取时间字段在所述分析时间段内的所述待处理的日志信息可以是通过比较所述第一维度分析需求中的时间字段信息和所述待处理日志信息中的所述时间字段步骤103,根据分析时间段内的所述第一维度指标中的指标名与指标值,基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。这里,根据所述第二维度分析需求中的时间段信息确定第二维度指标,能够灵活获取不同时间段内的实时信息。作为一种实施例,将所述第二维度指标存储至目标数据库,和/或,将所述第二维度指标输出并显示。第三方面,本公开实施例还提供一种日志信息处理装置,应用于边缘节点,请参见图11,为本公开一实施例提供的一种日志信息处理装置的结构示意图,所述装置包括第一获取模块、第一处理模块和第一发送模块,其中,所述第一获取模块111,用于获取待处理日志信息;所述第一处理模块112,用于根据字段对所述待处理日志信息进行分类,获得第一分类结果;将所述待处理日志信息根据所述第一分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,获得第一维度指标;所述第一发送模块115,用于将所述第一维度指标发送给中心节点进行处理。这里,所述第二处理模块113,用于中心节点获取第一维度指标,根据字段对所述第一维度指标进行分类,获得第二分类结果;将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。这里,所述第三处理模块114,用于将所述第一维度指标以键值对形式存储至关系型数据库中;从所述关系型数据库中获取所述第一维度指标并对所述待分析日志中的每条日志信息对应的第一维度指标进行累加,获得每条日志信息累加后的所述第一维度指标。这里,所述第一处理模块112,还用于从所述数据处理队列中获取对应的所述待处理的日志信息;根据所述待处理的日志信息携带的字段确定所述待处理日志信息的指标名及与所述指标名对应的指标值;基于指定的第一维度分析需求,从已建立的第一算法索引表中获取所述第一维度分析需求对应的目标算法;其中,所述第一算法索引表包括所述第一维度分析需求与至少一所述指标名对应的指标值之间的对应关系;基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。这里,所述第一处理模块112,还用于以第一维度分析需求为索引遍历已建立的第一算法索引表,从所述第一算法索引表中获取所述第一维度分析需求对应的目标算法。这里,所述第一处理模块112,还用于根据所述第一维度分析需求确定分析时间段信息;根据所述待处理的日志信息的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述待处理的日志信息;根据分析时间段内的所述待处理的日志信息中的指标名与指标值,基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。第四方面,本公开实施例还提供一种日志信息处理装置,应用于中心节点,请参见图12,为本公开另一实施例提供的另一种日志信息处理装置的结构示意图,,包括第二获取模块和第四处理模块,其中,所述第二获取模块121,用于获取至少一边缘节点发送的第一维度指标,根据字段对所述第一维度指标进行分类,获得第二分类结果;所述第四处理模块122,用于将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。其中,所述第四处理模块122,还用于从所述数据处理队列中获取对应的第一维度指标;根据所述第一维度指标携带的字段确定所述第一维度指标的指标名及与所述指标名对应的指标值;基于指定的第二维度分析需求,从已建立的第二算法索引表中获取所述第二维度分析需求对应的目标算法;其中,所述第二算法索引表包括所述第二维度分析需求与至少一所述指标名对应的指标值之间的对应关系;基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。其中,所述第四处理模块122,还用于以第二维度分析需求为索引遍历已建立的第二算法索引表,从所述第二算法索引表中获取所述第二维度分析需求对应的目标算法。其中,所述第四处理模块122,还用于根据所述第二维度分析需求确定分析时间段信息;根据所述第一维度指标的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述第一维度指标;根据分析时间段内的所述第一维度指标中的指标名与指标值,基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。其中,还包括输出模块123,所述输出模块123,用于将所述第二维度指标存储至目标数据库,和/或,将所述第二维度指标输出并显示。第四方面,本公开实施例还提供一种边缘节点,请参见图13,为本公开一实施例提供的一种边缘节点的结构示意图,包括:处理器132和用于存储能够在处理器132上运行的计算机程序的存储器131;其中,所述处理器132用于运行所述计算机程序时执行:获取待处理日志信息;根据字段对所述待处理日志信息进行分类,获得第一分类结果;将所述待处理日志信息根据所述第一分类结果对应存储至不同的数据处理队列中,从所述数据处理队列中获取对应的所述待处理的日志信息进行维度指标分析,获得第一维度指标,并将所述第一维度指标发送给中心节点进行处理。所述处理器132还用于运行所述计算机程序时执行:中心节点获取第一维度指标,根据字段对所述第一维度指标进行分类,获得第二分类结果;将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。所述处理器132还用于运行所述计算机程序时执行:将所述第一维度指标以键值对形式存储至关系型数据库中;从所述关系型数据库中获取所述第一维度指标并对所述待分析日志中的每条日志信息对应的第一维度指标进行累加,获得每条日志信息累加后的所述第一维度指标。所述处理器132还用于运行所述计算机程序时执行:从所述数据处理队列中获取对应的所述待处理的日志信息;根据所述待处理的日志信息携带的字段确定所述待处理日志信息的指标名及与所述指标名对应的指标值;基于指定的第一维度分析需求,从已建立的第一算法索引表中获取所述第一维度分析需求对应的目标算法;其中,所述第一算法索引表包括所述第一维度分析需求与至少一所述指标名对应的指标值之间的对应关系;基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。所述处理器132还用于运行所述计算机程序时执行:以第一维度分析需求为索引遍历已建立的第一算法索引表,从所述第一算法索引表中获取所述第一维度分析需求对应的目标算法。所述处理器132还用于运行所述计算机程序时执行:根据所述第一维度分析需求确定分析时间段信息;根据所述待处理的日志信息的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述待处理的日志信息;根据分析时间段内的所述待处理的日志信息中的指标名与指标值,基于所述目标算法计算获得所述第一维度分析需求对应的第一维度指标。第五方面,本公开实施例还提供一种中心节点,请参见图14,为本公开一实施例提供的一种中心节点的结构示意图,包括:处理器142和用于存储能够在处理器142上运行的计算机程序的存储器141;其中,所述处理器142用于运行所述计算机程序时执行:获取边缘节点发送的第一维度指标,根据字段对所述第一维度指标进行分类,获得第二分类结果;将所述第一维度指标根据所述第二分类结果存储至不同的数据处理队列中,从所述数据处理队列中获取对应的第一维度指标进行维度指标分析,获得第二维度指标。所述处理器142还用于运行所述计算机程序时执行:从所述数据处理队列中获取对应的第一维度指标;根据所述第一维度指标携带的字段确定所述第一维度指标的指标名及与所述指标名对应的指标值;基于指定的第二维度分析需求,从已建立的第二算法索引表中获取所述第二维度分析需求对应的目标算法;其中,所述第二算法索引表包括所述第二维度分析需求与至少一所述指标名对应的指标值之间的对应关系;基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。所述处理器142还用于运行所述计算机程序时执行:以第二维度分析需求为索引遍历已建立的第二算法索引表,从所述第二算法索引表中获取所述第二维度分析需求对应的目标算法。所述处理器142还用于运行所述计算机程序时执行:根据所述第二维度分析需求确定分析时间段信息;根据所述第一维度指标的所述字段中的时间字段,获取时间字段在所述分析时间段内的所述第一维度指标;根据分析时间段内的所述第一维度指标中的指标名与指标值,基于所述目标算法计算获得所述第二维度分析需求对应的第二维度指标。所述处理器142还用于运行所述计算机程序时执行:将所述第二维度指标存储至目标数据库,和/或,将所述第二维度指标输出并显示。第六方面,本公开实施例还提供一种日志信息处理系统,请参见图15,为本公开一实施例提供的一种日志信息处理系统的结构示意图,包括如本公开任一实施例所述的边缘节点151和本公开实施例任一所述的中心节点152。为了方便对本公开实施例的理解,本公开通过如下实施例进行示例性说明,请参见图14,为本公开另一实施例提供的一种日志信息处理方法的流程示意图:实施例步骤161,边缘节点获取待处理日志信息;步骤a162,边缘节点根据所述待处理日志信息的字段对所述待处理日志信息进行分类,获得第一分类结果,将所述第一分类结果写入不同的kafkatopic;步骤a163,边缘节点通过directstream建立数据管道获取所述待处理日志信息;步骤a164,边缘节点基于所述待处理日志信息的指标名和指标值,通过指标索引表进行第一维度分析,获得第一维度指标,将所述第一维度指标存储至redis进行累加处理后生成结果文件发送给中心节点的ftp;步骤a165,中心节点根据所述第一维度指标的字段对所述第一维度指标进行分类,获得第二分类结果,将所述第二分类结果写入不同的kafkatopic;步骤a166,中心节点通过directstream建立数据管道获取所述第二维度指标;步骤a167,中心节点基于所述维度指标的指标名和指标值,通过算法索引表进行第二维度分析,获得第二维度指标,将所述第二维度指标存储至目标数据库,和/或,将所述第二维度指标输出并显示。本公开实施例中,通过sparkstreaming流式数据处理和redis组合使用,并选用恰当的算子,加快了数据处理速度;通过采用算法索引表,实现自动化指标计算;中心节点通过下放部分计算任务至边缘节点,减轻网络资源使用量,边缘节点并行处理各自数据,提高数据处理效率,加快了数据处理速度。以上所述,仅为本公开的较佳实施例而已,并非用于限定本公开的保护范围。凡在本公开的精神和范围之内所作的任何修改、等同替换和改进等,均包含在本公开的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1