一种基于约束规划的自定义指令自动识别方法与流程
本发明涉及电子设计自动化
技术领域:
,尤其涉及一种基于约束规划的自定义指令自动识别方法。
背景技术:
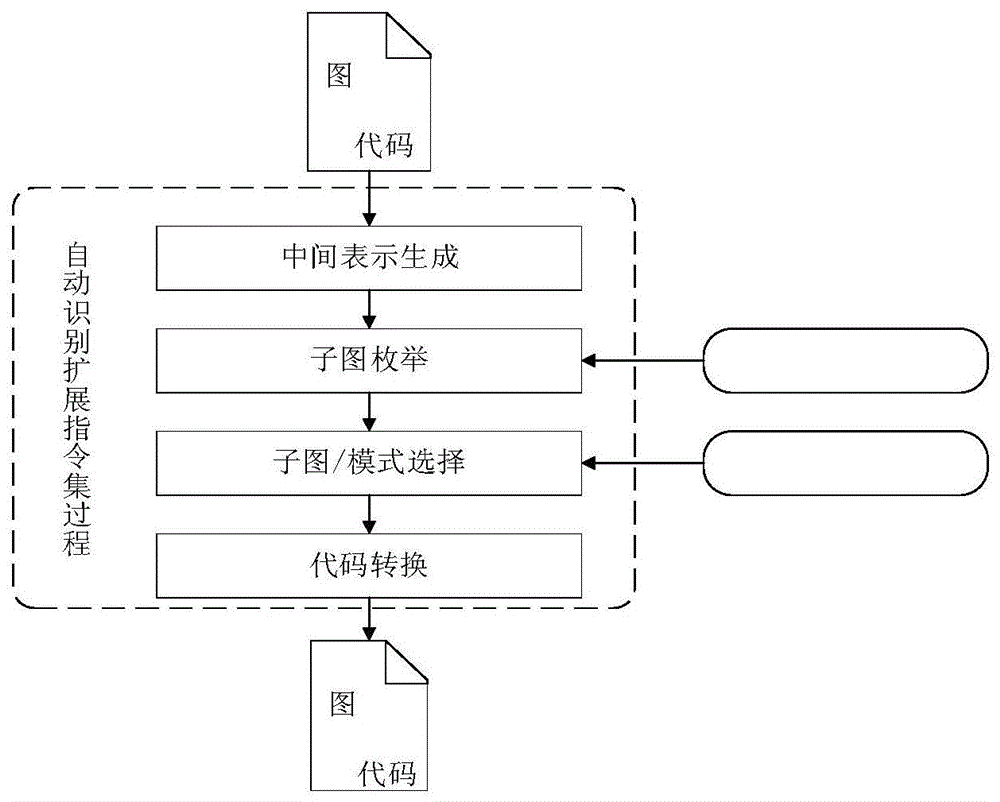
:近年来,为了满足嵌入式应用对高性能和低功耗不断增长的需求,扩展指令集广泛应用于嵌入式系统当中.例如,专用指令集处理器(applicationspecificinstructionprocessor,asip)结合了通用处理器和asic的优点,在设计周期、灵活性、性能、以及功耗等方面提供良好的折中。扩展指令集中的自定义指令是通过封装一系列基本指令,实现基本指令之间的链化和并行化,进而提高性能。面向特定应用的扩展指令集是专用指令集处理器设计的核心环节。扩展指令集通常在多媒体应用处理和信号处理等领域中使用。为了使异构多处理器能够更好地运行不同的多媒体应用程序,dammak等人将扩展指令集应用到异构多核处理器片上系统之中,使系统在性能和功耗之间进行了良好的权衡。momcilovic等人将专用指令集处理器用来执行数据自适应运动估计算法,大大节省了数据计算成本,很好的提高了视频处理的速度。sisto等人提出了一种专用于汽车应用领域传感器信号调理专用处理器设计。当前,图像处理领域发展迅速,图像处理的效果也正不断的提升。神经网络、支持向量机等学习型的机制虽然在图像处理方面有着较好的优势,但是针对于目前图像数据量庞大的特点,一些效果较好的优化算法却需要大量的时间去处理图像数据或者训练样本。此外,针对实时图像处理需要严格的时间限制。国内外最新研究发现,将扩展指令集应用于图像处理领域当中,能够显著地提升性能。mori等人提出了用于加速实时ip/cv算法的专用处理器设计.edwards等人通过应用扩展指令集到实时目标检测系统之中,处理速度提高了1.5至6.8倍。早期的研究中,是通过设计专用芯片来高效地实现应用程序,但是专用芯片的设计周期长、硬件开发难以调试,其成本也非常高。所以越来越多的研究人员也开始将研究重心转移到扩展指令上,针对特定应用自动地识别扩展指令集。自动识别扩展指令集的流程如图1所示,首先,图像处理算法源代码作为开源编译器gecos的输入,gecos将源代码转换为控制数据流图(controldataflowgraph,cdfg),控制数据流图是表示多个基本块之间的数据依赖关系的图。然后,子图枚举算法从数据流图中枚举出所有满足约束条件的子图(子图是自定义指令的图形化表示)。接着,子图选择算法从枚举出的子图当中选择部分最佳子图作为最终的自定义指令。最后,将源代码转换为包含所选自定义指令的新代码。约束编程是一种结合逻辑推理的通用搜索技术,起源于计算机科学和人工智能领域的约束满足问题(constraintsatisfactionproblem,csp)。约束满足问题是由给定的一组变量、这组变量的值域以及一组约束条件(方程、不等式以及程序等都可以作为约束条件)组合而成,对于约束满足问题的求解是在所有的组合中找出一种或几种满足约束条件的组合。通常,组合优化、调度优化问题都属于约束满足问题。应用约束编程解决问题时,其表述更加接近于实际问题,无需将约束转换为线性等式或者不等式,使公式表达简单并且易于理解。技术实现要素:本发明要解决的技术问题是针对上述现有技术的不足,提供一种基于约束规划的自定义指令自动识别方法,基于约束编程方法对自定义指令进行自动识别。为解决上述技术问题,本发明所采取的技术方案是:一种基于约束规划的自定义指令自动识别方法,包括自定义指令的枚举和自定义指令的选择两部分;所述自定义指令的枚举通过建立自定义指令的枚举约束编程模型,从数据流图中枚举所有满足约束条件的子图实现,具体方法为:为了从数据流图g(v,e)中枚举出所有满足给定约束的自定义指令,设子图s=(vs,es)是自定义指令实例的图形化表示,i1,i2分别表示图g中的有效结点的集合和非法结点的集合,所述数据流图g=(v,e)是一个有向无环图(directedacyclicgraph,即dag),结点集v={v1,v2,...,vm}表示基本指令,m为数据流图结点的个数,边集表示指令之间数据依赖关系,m表示数据流图边的个数;所述给定的约束条件包括:自定义指令不包含非法结点的约束条件,自定义指令的连通性约束条件,自定义指令是凸的约束条件及自定义指令的输入输出约束条件;分别对约束条件建模,并针对枚举问题,采用约束编程方法求所有满足约束条件的自定义指令,完成对自定义指令的枚举;所述对自定义指令不包含非法结点的约束条件建模,如下公式所示:其中,vsel=0表示非法结点v不包含在自定义指令中;所述非法结点为:由于可扩展处理器体系结构的限制,内存操作和分支操作这两种基本指令不能包含在自定义指令中,代表这些基本指令的结点被视为非法结点;所述对自定义指令的连通性的约束条件建模,如下公式所示:其中,表示结点v和结点vk之间存在一条无向路径,当枚举分离子图时此约束可去除;所述自定义指令是凸的的约束条件为当且仅当子图s中的任意两个结点u,v之间的任何路径只经过子图s中的结点,对该约束条件建模,如下公式所示:其中,usel,vsel分别表示结点u和v是否被选择,0表示没有被选择,1表示被选择;所述自定义指令的输入输出约束条件如下公式所示:其中,inmax,outmax分别表示自定义指令的输入输出上限,inv,outv分别表示结点v的入度和出度,pred(u)={v|v∈v,(v,u)∈e},succ(u)={v|v∈v,(u,v)∈e}分别表示结点v的前驱结点集合和后续结点集合,vin、vout分别表示结点v的输入、输出数目,msel表示结点m是否被选择;所述自定义指令的选择通过建立自定义指令的选择约束编程模型,实现多目标优化,具体方法为:在自定义指令枚举阶段所枚举出的子图基础上,首先对所有子图进行图同构匹配处理:给定两个子图a和b,如果a与b同构,则创建模式ci,并且将子图a和b作为实例被记录在模式ci中;所述模式是候选自定义指令的图形化表示;为了建立自定义指令选择问题的约束编程模型,先定义一些变量:n为自定义指令枚举阶段枚举出的候选自定义指令的数目,ci表示第i个候选自定义指令,i=1,…,n;自定义指令ci在代码中有ni个实例,分别为每个自定义指令的实例的执行频率为fi,j;自定义指令带来的处理器性能提升和自定义指令在自定义功能单元中实现所需的硬件面积分别用pi和ai表示;则自定义指令带来的处理器性能提升的最大化目标函数如下公式所示:其中,si,j为二元变量,当自定义指令实例ci,j被选择的时候其值为1,否则为0;由于自定义指令是通过封装多个基本指令,减少最终取指令和数据在寄存器和处理器之间传输的次数,从而减少处理器的能耗;则自定义指令带来的处理器能耗减少的最大化目标函数如下公式所示:其中,e(ci,j)表示自定义指令实例ci,j内部边的数目,表示取指令数目的减少量,表示数据传输次数的减少量,α,β为权重参数,α+β=1;在以上建立的基于目标函数的自定义指令选择模型基础上,为了简化问题,采用基于权重的方法,将多目标优化问题转换为单目标优化问题,得到如下公式所示的自定义指令选择模型:其中,γ,ε为权重参数,γ+ε=1;针对用户给定的面积约束,每个自定义指令在自定义功能单元中对应的硬件都有面积大小,则需要对自定义指令的面积约束进行建模,如下公式所示:其中,a为可扩展处理器设计时给定的所有自定义指令对应的硬件的面积总预算,ai为第i个自定义指令所对应的硬件面积,si为二元变量;如果自定义指令ci至少有一个实例被选择,那么si的值为1,否则为0,如下公式所示:采用上述技术方案所产生的有益效果在于:本发明提供的一种基于约束规划的自定义指令自动识别方法,针对自定义指令枚举问题,将问题的建模和求解分离,可适用于多种约束条件的组合,具有较好的通用性和灵活性。针对自定义指令选择问题,通过建立多目标优化约束编程模型,可实现多目标优化;将本发明的自动识别出的自定义指令应用于图像处理类算法,可显著提升算法的性能。附图说明图1为本发明
背景技术:
提供的面向图像处理算法的自动识别扩展指令集流程图;图2为本发明实施例提供的数据流图的示意图;图3为本发明实施例提供的不同i/o约束条件下运行时间比较结果图;图4为本发明实施例提供的枚举连通子图和枚举所有子图运行时间比较结果图;图5为本发明实施例提供的性能提升比较结果图;图6为本发明实施例提供的采用不同方法选择指令数目的比较结果图。具体实施方式下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。一种基于约束规划的自定义指令自动识别方法,包括自定义指令的枚举和自定义指令的选择两部分;所述自定义指令的枚举通过建立自定义指令的枚举约束编程模型,从数据流图中枚举所有满足约束条件的子图实现,具体方法为:为了从数据流图g(v,e)中枚举出所有满足给定约束的自定义指令,设子图s=(vs,es)是自定义指令实例的图形化表示,i1,i2分别表示图g中的有效结点的集合和非法结点的集合,所述数据流图g=(v,e)是一个有向无环图(directedacyclicgraph,即dag),如图2所示,结点集v={v1,v2,...,vm}表示基本指令,m为数据流图结点的个数,边集表示指令之间数据依赖关系,m表示数据流图边的个数;所述给定的约束条件包括:自定义指令不包含非法结点的约束条件,自定义指令的连通性约束条件,自定义指令是凸的约束条件及自定义指令的输入输出约束条件;分别对约束条件建模,并针对枚举问题,采用约束编程方法求所有满足约束条件的自定义指令,完成对自定义指令的枚举;所述对自定义指令不包含非法结点的约束条件建模,如下公式所示:其中,vsel=0表示非法结点v不包含在自定义指令中;所述非法结点为:由于可扩展处理器体系结构的限制,内存操作和分支操作这两种基本指令不能包含在自定义指令中,代表这些基本指令的结点被视为非法结点;所述对自定义指令的连通性的约束条件建模,如下公式所示:其中,表示结点v和结点vk之间存在一条无向路径,当枚举分离子图时此约束可去除;所述自定义指令是凸的的约束条件为当且仅当子图s中的任意两个结点u,v之间的任何路径只经过子图s中的结点,对该约束条件建模,如下公式所示:其中,usel,vsel分别表示结点u和v是否被选择,0表示没有被选择,1表示被选择;本实施例中,对于如图2所示的数据流图,子图{1,2,3}是凸子图,而子图{2,3,5}不是凸子图。所述自定义指令的输入输出约束条件如下公式所示:其中,inmax,outmax分别表示自定义指令的输入输出上限,inv,outv分别表示结点v的入度和出度,pred(u)={v|v∈v,(v,u)∈e},succ(u)={v|v∈v,(u,v)∈e}分别表示结点v的前驱结点集合和后续结点集合,vin、vout分别表示结点v的输入、输出数目,msel表示结点m是否被选择;所述自定义指令的选择通过建立自定义指令的选择约束编程模型,实现多目标优化,具体方法为:在自定义指令枚举阶段所枚举出的子图基础上,首先对所有子图进行图同构匹配处理:给定两个子图a和b,如果a与b同构,则创建模式ci,并且将子图a和b作为实例被记录在模式ci中;所述模式是候选自定义指令的图形化表示;为了建立自定义指令选择问题的约束编程模型,先定义一些变量:n为自定义指令枚举阶段枚举出的候选自定义指令的数目,ci表示第i个候选自定义指令,i=1,…,n;自定义指令ci在代码中有ni个实例,分别为每个自定义指令的实例的执行频率为fi,j;自定义指令带来的处理器性能提升和自定义指令在自定义功能单元中实现所需的硬件面积分别用pi和ai表示;则自定义指令带来的处理器性能提升的最大化目标函数如下公式所示:其中,si,j为二元变量,当自定义指令实例ci,j被选择的时候其值为1,否则为0;由于自定义指令是通过封装多个基本指令,减少最终取指令和数据在寄存器和处理器之间传输的次数,从而减少处理器的能耗;则自定义指令带来的处理器能耗减少的最大化目标函数如下公式所示:其中,e(ci,j)表示自定义指令实例ci,j内部边的数目,表示取指令数目的减少量,表示数据传输次数的减少量,α,β为权重参数,α+β=1;在以上建立的基于目标函数的自定义指令选择模型基础上,为了简化问题,采用基于权重的方法,将多目标优化问题转换为单目标优化问题,得到如下公式所示的自定义指令选择模型:其中,γ,ε为权重参数,γ+ε=1;针对用户给定的面积约束,每个自定义指令在自定义功能单元中对应的硬件都有面积大小,则需要对自定义指令的面积约束进行建模,如下公式所示:其中,a为可扩展处理器设计时给定的所有自定义指令对应的硬件的面积总预算,ai为第i个自定义指令所对应的硬件面积,si为二元变量;如果自定义指令ci至少有一个实例被选择,那么si的值为1,否则为0,如下公式所示:本实施例中,运行的环境为i3-32403.4ghz处理器,4gb主存储器,操作系统为windows8.约束编程工具为jacop2.3。测试基准集来源于mediabench和mibench.本实施例中所用测试基准应用程序均是图像处理领域中或视频处理领域中常见算法。本实施例中,对于针对图像处理领域的常见算法,首先采用gecos前端编译器,将算法程序转换为对应的控制数据流图。然后,采用本发明的基于约束编程的自定义指令枚举方法从数据流图中枚举所有满足约束条件的子图。基于约束编程方法的自定义指令枚举结果如表1所示。表1中的列nodes,enumeratedsubgraphs和time分别表示所用的基准程序对应的数据流图的结点数,枚举出的满足约束条件的连通子图数目(输入输出上限分别设为6和2)以及枚举方法的运行时间。表1自定义指令枚举结果为了进一步分析不同约束条件对枚举方法的运行时间的影响,本实施例中,比较了在不同输入输出约束条件下枚举方法的运行时间。针对基准测试程序susan,jpegencode,jpegdecode和mesa,在不同i/o约束条件下,运行时间结果比较如图3所示。从图3可以看出,枚举方法的运行时间随着输入输出数目的增大而显著增加。通过进一步比较发现,增大输出数目对运行时间的影响要明显大于增大输入数目对运行时间的影响。例如,相比于输入输出上限为6/2的条件下,当输入输出上限为7/2时,枚举方法的运行时间平均增加1.5倍,而当输入输出上限设为6/3时,枚举方法的运行时间平均增加10倍。由于枚举子图的连通性是自定义指令枚举过程中一项重要的约束条件。本实施例中,将只枚举连通子图的运行时间和枚举所有子图(包括连通子图和分离子图)的运行时间进行了比较,结果如图4所示(i/o条件为6/2)。从图中可以看出,枚举所有子图的运行时间要远大于仅枚举连通子图的运行时间。本实施例中,将本发明的基于约束编程的自定义指令选择方法与kamal等人提出的自定义指令选择方法及xiao等人提出的自定义指令选择方法进行比较。其中,kamal等人提出的方法是在给定面积约束条件下,选择提升性能最大化的自定义指令。xiao等人提出的方法是在给定的面积约束条件下,通过选择较少的自定义指令数目,从而减少功耗.本实施例中,比照kamal等人提出的方法,自定义指令实现的硬件自定义功能单元中实现的基本指令的硬件延迟和面积信息如表2所示。表2自定义功能单元中基本指令的硬件延迟和面积信息operationareadelay(ns)sub2250.5add2000.5shr/shl3260.19eqt/neq870.16grt/lks1150.21and410.04or420.05xor640.05本实施例中,假定包含多个结点的自定义指令在自定义功能单元上执行,而应用程序中未被包含进自定义指令的基本指令在基准处理器上执行.式(13)给出了使用自定义指令的应用程序的总时延的计算:lh=(∑s∈sc∑i∈c(s)hw(i)+∑s∈sct(s))+∑k∈psw(k)(13)其中,hw(i)表示自定义指令i的硬件延迟。t(s)表示传输自定义指令的输入和输出操作数所需的额外时延。式(13)中的∑s∈sc∑i∈c(s)hw(i)表示所选自定义指令累积硬件时延的总和(sc表示所选自定义指令的集合,c(s)表示是位于所选自定义指令s的关键路径上的节点);第2部分表示未包含进自定义指令的基本指令的累积软件时延,其中p表示未包含的基本指令的集合。通过使用自定义指令实现的性能提升的计算如式(14)所示:其中,是原始应用程序的源代码中所有基本指令的累积软件时延(n表示原始代码中基本指令的数量)。本实施例中,将本发明的自定义指令选择方法与kamal等人和xiao等人提出的自定义指令方法进行了比较。其中,面积约束条件分别设为参考面积的10%,30%和50%.参考面积为使用bonzini等人提出的贪婪算法所选择的最大化提升性能的自定义指令面积之和.针对表1中列举的9个基准测试程序benchmarks,三种方法所选择的指令数目(ns)及性能提升(pi)的比较结果如表3所示。表3自定义指令选择方法实验结果比较本实施例中,本发明的多目标优化模型中的参数γ,ε,α和β均设为0.5。可以观察到,随着面积约束条件的放松,三种方法获得的性能提升均呈增加的趋势。相比于xiao等人提出的方法,本发明的方法在性能提升方面的表现更好:本发明方法取得性能提升平均为3.12倍,xiao等人提出的方法获得性能提升平均为2.81倍。另一方面,本发明方法所选择的自定义指令实例的数目明显少于kamal等人提出的方法所选择的自定义指令实例的数目。本发明方法最终选择的指令数平均为58,而kamal等人提出的方法最终选择的指令数目平均为62。由于减少自定义指令实例的数目可降低最终取指令和数据在寄存器和处理器之间传输的次数,从而减少能耗。此外,通过调整多目标优化模型中的参数γ和ε,本发明方法可在性能提升方面或减少指令数目方面具有更好的表现。当参数γ和ε分别设为1和0时,相比于kamal等人提出的方法,本发明方法在性能提升效果上更有优势,结果如图5所示(面积约束为50%)。当参数γ和ε分别设为1和0时,问题模型就转化为在给定面积约束条件下,求提升性能最大化的自定义指令选择。由于本发明采用的约束编程方法可以用来寻找最优解,而kamal等人提出的方法不能保证得出的解是最优的。因此,本发明方法对性能提升效果更明显。当参数γ和ε分别设为0和1时,相比于xiao等人提出的方法,本发明方法选择的指令实例数目较少,结果如图6所示。当参数γ和ε分别设为0和1时,问题模型就转化为在给定面积约束条件下,选择最少数目的指令实例覆盖原数据流图。针对每个测试基准程序,约束编程方法可以选择最少数目的指令,而xiao等人提出的探索式方法在多数情况下,不能找到最少数目的指令。最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明权利要求所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1